
成都超算使用记录
调试流程
注:这里的工作流程用于测试环境、练习使用;
准备工作
环境准备
- 给conda换源:
Reference: 修改默认Anaconda镜像源
vim ~/.condarc
# 插入以下内容
channels:
- https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
- defaults
- 加载模块
module unload compiler/rocm/2.9
module load compiler/rocm/dtk-22.10
module load apps/anaconda3/5.2.0
- 创建环境
conda create -n dtk2210 python=3.9
- 安装本地PyTorch框架
source activate dtk2210
pip install /public/public_share/apps/dl_whl_dtk2210/torch-1.10.0a0+git2040069.dtk2210-cp39-cp39-manylinux2014_x86_64.whl
开始训练
- 申请节点:
salloc -n 32 -N 1 -p normal -t 0 --gres=dcu:4
## 选项说明
-n # cpu核数
-N # 节点数
-p # 分区队列
-t # 时间,0 即无限
--gres # GPU
## 成都超算使用的
# CPU是 Hygon C86 7185 32-core Processor
# GPU是 海光 DCU (Deep Computing Unit) 16GB * 4
- 查看节点信息:
squeue

- SSH到计算节点:
ssh a16r1n04
# 如果有多个节点,例如四个节点 c10r4n[00-01],ssh到每个节点时都要后缀其编号,ssh c10r4n00
- 加载模块,激活环境
module unload compiler/rocm/2.9
module load compiler/rocm/dtk-22.10
module load apps/anaconda3/5.2.0
source activate dtk2210
- 验证DCU可用否
python
import torch
torch.cuda.is_available()
torch.__version__
torch.cuda.device_count()
- 愉快享用免费算力8️⃣
其他常用的操作
资源查看
lscpu # cpu 信息
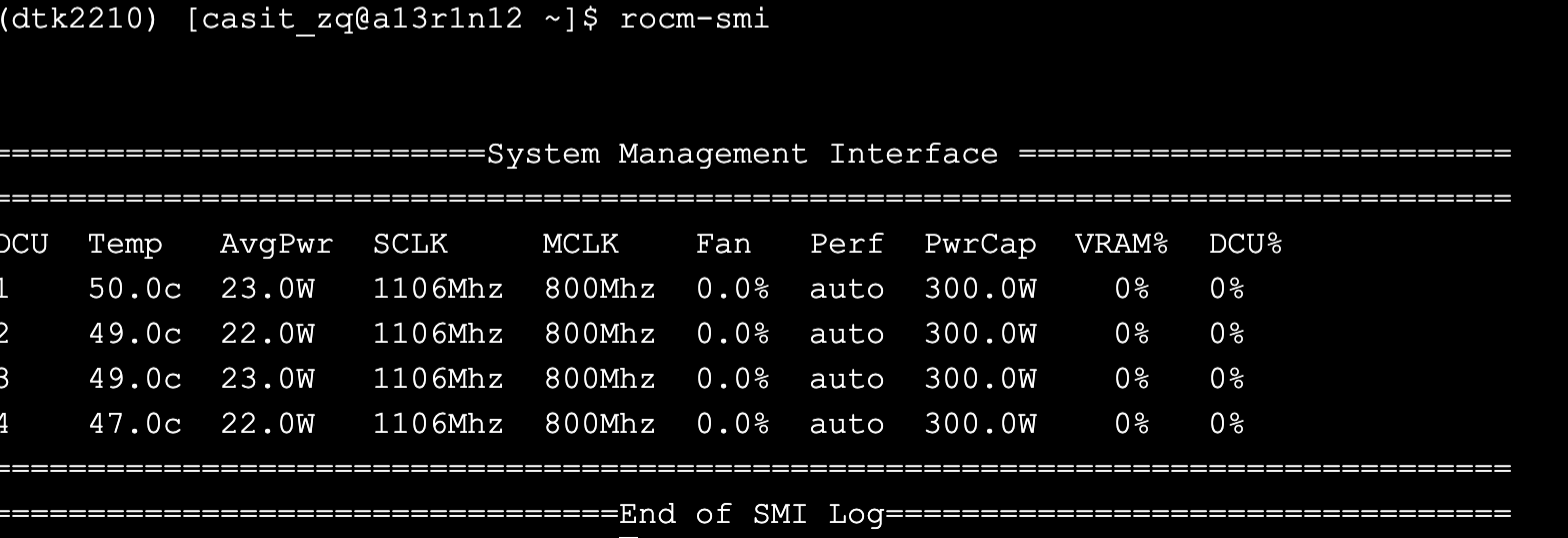
rocm-smi # DCU 状态
hy-smi # DCU 状态 conda下可用 和上面的命令差不都
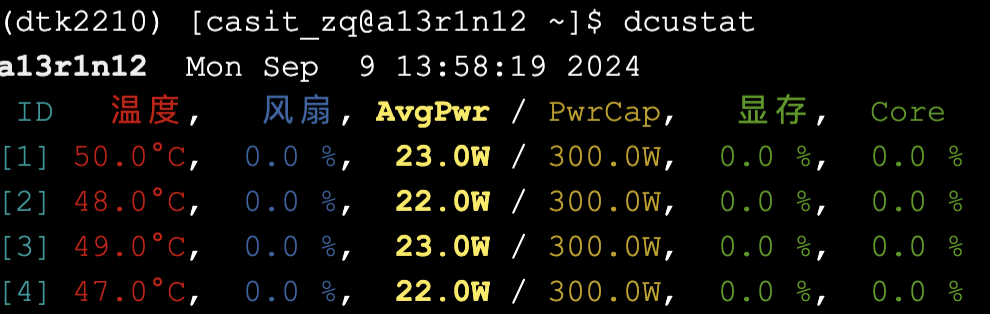
另一个DCU状态查看工具:dcustat
pip install dcustat
dcustat
dcustat --watch # 动态刷新
conda相关
conda list # 查看装了哪些框架哪些包
conda env list # 查看 conda 环境
conda activate env_name
conda deavtive
常规使用流程
环境准备
在~/pre目录下(我自定义的),
vim env.sh, 编辑环境配置脚本
#!/bin/bash
module unload compiler/rocm/2.9
module load compiler/rocm/dtk-22.10
module load apps/anaconda3/5.2.0
source activate dtk2210
运行脚本 source env.sh
vim rocm-smi.sh, 计算节点DCU状态重定向脚本
#!/bin/bash
# 无限循环
while true; do
# 执行 rocm-smi 命令并将标准输出重定向到 rocm-smi.out 文件
rocm-smi > ~/pre/rocm-smi.out
# 等待一秒
sleep 1
done
开始训练
使用salloc申请并 ssh 到的节点,需要shell保持活跃,否则可能被中断。所以salloc申请节点适用于测试,一般使用sbatch来跑任务。
- 写sbatch作业脚本
vim task.sh
#!/bin/bash
#SBATCH -p normal
#SBATCH -n 32
#SBATCH -N 1
#SBATCH --gres=dcu:4
#SBATCH -J test
#SBATCH -o ./log/%j.out
#SBATCH -e ./log/%j.err
# 配置环境 或 直接运行上面👆的 env.sh
# 要提前创建 log 哦,可以再写一个脚本run.sh创建
source ~/pre/env.sh
# nohup防止中断,&将命令放入后端执行,以避免阻塞后面的命令
nohup ~/pre/rocm-smi.sh &
# 等待一秒执行后面的命令
sleep 1
# 由于在env.sh中已经激活了环境,所以以下代码注释掉
#module unload compiler/rocm/2.9
#module load compiler/rocm/dtk-22.10
#module load apps/anaconda3/5.2.0
#source activate dtk2210
# 运行程序 切换计算节点时不改变目录
# -u 即非缓冲模式 unbuffered,此时输出没有缓冲,强制立刻发送到标准输出stdout
python3 -u main.py
- 提交sbatch作业
sbatch task.sh
- 查看作业运行情况
squeue
- 查看DCU使用情况和计算节点标准输出
tail -f ~/pre/rocm-smi.out
tail -f ./log/*.out
封装脚本
脚本假设都放在项目目录中,
pwd也是项目目录
环境脚本 env.sh
#!/bin/bash
module unload compiler/rocm/2.9
module load compiler/rocm/dtk-22.10
module load apps/anaconda3/5.2.0
source activate dtk2210
系统状态重定向脚本 systemstat.sh
#!/bin/bash
# 无限循环
while true; do
# 执行 rocm-smi 命令并将输出重定向到 rocm-smi.out 文件
rocm-smi > ./log/systemstat.stat
# 等待一秒
sleep 1
done
批作业脚本 task.sh
#!/bin/bash
#SBATCH -p normal
#SBATCH -n 32
#SBATCH -N 1
#SBATCH --gres=dcu:4
#SBATCH -J task_name
#SBATCH -o ./log/%j.out
#SBATCH -e ./log/%j.err
source ./env.sh
nohup ./rocm-smi.sh &
sleep 1
python3 -u main.py
运行作业脚本 run.sh
#!/bin/bash
rm -r log
mkdir log
sbatch task.sh
查看状态脚本之系统状态 stat.sh
#!/bin/bash
tail -f ./log/systemstat.stat
查看状态脚本之程序输出 out.sh
#!/bin/bash
tail -f ./log/*.out
查看状态脚本之系统状态 err.sh
#!/bin/bash
tail -f ./log/*.err
VNC可视化相关
sbatch 脚本
#!/bin/bash
#SBATCH -J vnc-test
#SBATCH -N 1
#SBATCH -n 32
#SBATCH -t 0
ssh $HOSTNAME "export DISPLAY=vnc会话名称:26;module load apps/vesta/gtk2;VESTA
-gui"
ssh $HOSTNAME "export DISPLAY=admin07i:26;module load apps/vesta/gtk2;VESTA -gui”
这一行会在作业启动后,在分配给作业的节点上执行。它通过SSH连接到运行作业的节点($HOSTNAME是分配给作业的节点的名称),并在那里设置环境变量DISPLAY,加载VESTA所需的模块,并启动VESTA的GUI。
salloc 申请节点
ssh a16r1n04
# 设置DISPLAY端口
export DISPLAY=vnc会话名称
# 加载 vesta 软件包
module load apps/vesta/gtk2
# 启动可视化程序
VESTA-gui
常用命令
环境加载 module
建议按照编译器、并行环境、所需库(如有需要)、应用软件的顺序加载相应环境。
module av ## 查看系统中可用的软件
module load ## 加载环境,例如 module load apps/miniconda/3
module li ## 查看当前已加载的环境
module unload ## 卸载不需要的环境,例如 module unload apps/miniconda/3
module purge ## 卸载当前所有已加载的环境
module show ## 显示环境的配置文件,例如 module show apps/miniconda/3
作业调度系统Slurm
sinfo 分区查询
用于查询队列信息
sinfo -p normal -t idle # 查看 normal 队列的空闲节点
sbatch(推荐使用)提交批处理作业
sbatch命令配合jobfile作业脚本使用,在批处理作业脚本中,第一行以#!/bin/bash开头,以指定脚本文件的解释程序。
使用sbatch是直接进入到了计算节点了。
常用选项:
| 选项 | |
|---|---|
| -J | 作业名称 |
| -n | 总cpu核数 |
| -N | 节点数 |
| -p | 指定队列 |
| -o | 指定标准输出文件 例如,-o %J.out (%J表示作业号) |
| -e | 错误输出文件 例如,-e %J.err |
| --gres= | DCU 加速 例如,--gres==dcu:4 表示使用 4 张 DCU 加速卡 |
| -t | 指定时间 (0 表示无限时) |
salloc 节点资源获取
例如,
salloc -n 32 -N 1 -p normal
squeue 作业信息查询
squeue
scancel 注销节点
scancel [JOBID]
资源查看命令
DCU 相关
hy-smi # DCU 状态查看
rocm-smi # DCU 状态查看
lscpu # cpu 信息查看
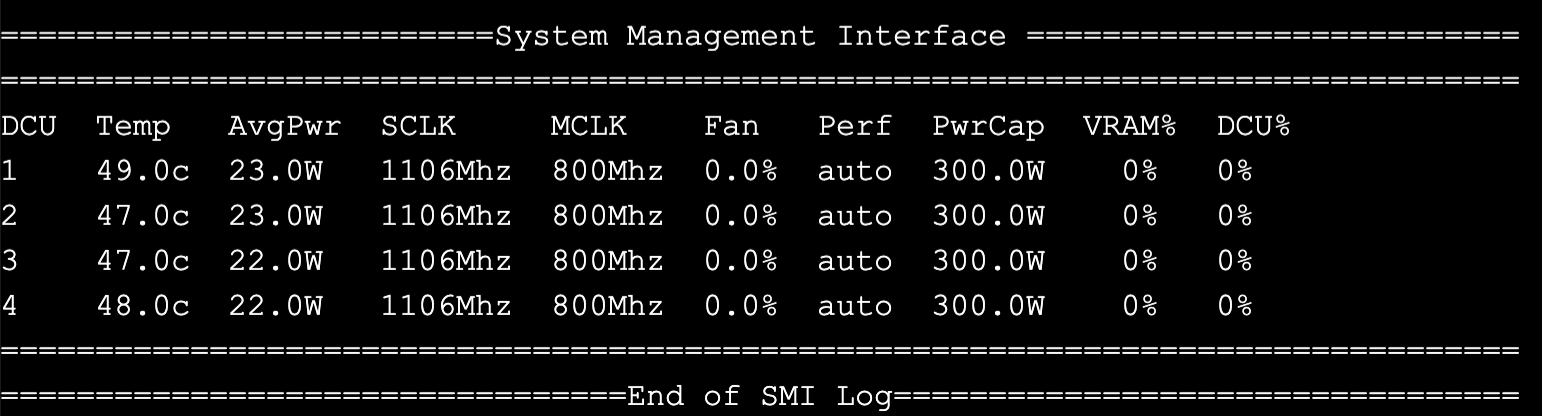
Temp, Tempurature 温度
AvgPwr, Average Power 平均功率
SCLK, 核心时钟速度,表示GPU核心的运行频率
MCLK: 内存时钟速度,表示GPU内存的运行频率
Fan: 风扇转速
Perf: 性能模式,这里显示为“auto”,意味着性能模式是自动调整的。
PwrCap: 功率上限,表示GPU的最大功耗限制
VRAM%: 显存使用率,表示GPU显存的使用百分比
DCU%: DCU利用率,表示GPU的绘图计算单元的使用百分比
dcustat 查看DCU状态
pip install dcustat
dcustat
dcustat --watch # 动态刷新
Reference
- 超算互联网-用户手册-Slurm作业调度系统 Slurm调度系统的详细手册
- 中科曙光使用记录 和成都超算有些许不同,使用记录较为完善
- 曙光超算平台如何使用以及常见问题 同上,但这个更好看
- 曙光云使用说明 这个也好看
个人理解:
在超算中,每个账户占用一定的存储空间(用户目录),在自己用户目录里可以维护自己的代码、“安装软件”、配置环境等,也可以访问其他目录(权限允许下),通过切换计算节点(cpu和gpu)来获取计算资源。
点击E-SHELL默认进入的是登录节点,登录节点只有 cpu,可以联网。如需 gpu 资源,需要先申请计算节点,然后切换到计算节点,计算节点不联网,因此需要在登录节点中将需要联网的工作做完,再进入计算节点。
本文来自博客园,作者:Zhihh,转载请注明原文链接:https://www.cnblogs.com/zhihh/p/18489338/Chengdu_HPC_Usage_Record


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现