


6.Mysql事务索引备份视图
转载:https://www.cnblogs.com/hellokuangshen/p/10262588.html
MySQL事务
- 事务就是将一组SQL语句放在同一批次内去执行
- 如果一个SQL语句出错,则该批次内的所有SQL都将被取消执行
- MySQL事务处理只支持InnoDB和BDB数据表类型
事务的ACID原则
- 原子性(Atomic)
- 整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(ROLLBACK)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性(Consist)
-
一个事务可以封装状态改变(除非它是一个只读的)。事务必须始终保持系统处于一致的状态,不管在任何给定的时间并发事务有多少。
也就是说:如果事务是并发多个,系统也必须如同串行事务一样操作。其主要特征是保护性和不变性(Preserving an Invariant),以转账案例为例,假设有五个账户,每个账户余额是100元,那么五个账户总额是500元,如果在这个5个账户之间同时发生多个转账,无论并发多少个,比如在A与B账户之间转账5元,在C与D账户之间转账10元,在B与E之间转账15元,五个账户总额也应该还是500元,这就是保护性和不变性。
-
- 隔离性(Isolated)
- 隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。如果有两个事务,运行在相同的时间内,执行相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。这种属性有时称为串行化,为了防止事务操作间的混淆,必须串行化或序列化请求,使得在同一时间仅有一个请求用于同一数据。
- 持久性(Durable)
- 在事务完成以后,该事务对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
Mysql事务实现方法
/* 使用set语句来改变自动提交模式 */ SET autocommit = 0; /*关闭*/ SET autocommit = 1; /*开启(默认的)*/ /* 注意 1.MySQL中默认是自动提交 2.使用事务时应先关闭自动提交 */
SET autocommit = 0; /*关闭*/
/*开始一个事务,标记事务的起始点*/ START TRANSACTION /*提交一个事务给数据库*/ COMMIT /*将事务回滚,数据回到本次事务的初始状态*/ ROLLBACK /*还原MySQL数据库的自动提交*/ SET autocommit =1;
-- 保存点
SAVEPOINT 保存点名称 -- 设置一个事务保存点
ROLLBACK TO SAVEPOINT 保存点名称 -- 回滚到保存点
RELEASE SAVEPOINT 保存点名称 -- 删除保存点
Mysql事务处理步骤
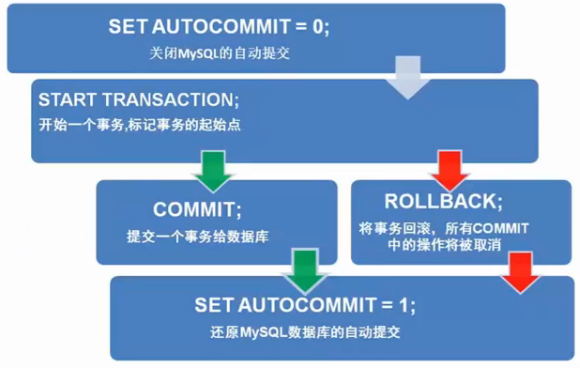
/* 课堂测试题目 A在线买一款价格为500元商品,网上银行转账. A的银行卡余额为2000,然后给商家B支付500. 商家B一开始的银行卡余额为10000 创建数据库shop和创建表account并插入2条数据 */ CREATE DATABASE `shop`CHARACTER SET utf8 COLLATE utf8_general_ci; USE `shop`; CREATE TABLE `account` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `name` VARCHAR(32) NOT NULL, `cash` DECIMAL(9,2) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=INNODB DEFAULT CHARSET=utf8 INSERT INTO account (`name`,`cash`) VALUES('A',2000.00),('B',10000.00) # 转账实现 SET autocommit = 0; -- 关闭自动提交 START TRANSACTION; -- 开启一组事务 UPDATE account SET cash=cash-500 WHERE `name`='A'; UPDATE account SET cash=cash+500 WHERE `name`='B'; COMMIT; -- 提交事务,被持久化了,回滚就没有用了 # rollback; -- 回滚 SET autocommit = 1; -- 回复默认值
数据库索引
作用 :
- 提高查询速度
- 确保数据的唯一性
- 可以加速表和表之间的连接 , 实现表与表之间的参照完整性
- 使用分组和排序子句进行数据检索时 , 可以显著减少分组和排序的时间
- 全文检索字段进行搜索优化.
分类 :
- 主键索引 (Primary Key)
- 唯一索引 (Unique)
- 常规索引 (Index)
- 全文索引 (FullText)
主键索引
主键 : 某一个属性组能唯一标识一条记录
特点 :
- 最常见的索引类型
- 确保数据记录的唯一性
- 确定特定数据记录在数据库中的位置
唯一索引
作用 : 避免同一个表中某数据列中的值重复
与主键索引的区别
- 主键索引只能有一个
- 唯一索引可能有多个

常规索引
作用 : 快速定位特定数据
注意 :
- index 和 key 关键字都可以设置常规索引
- 应加在查询找条件的字段
- 不宜添加太多常规索引,影响数据的插入,删除和修改操作

全文索引
作用 : 快速定位特定数据
注意 :
- 只能用于CHAR , VARCHAR , TEXT数据列类型
- 适合大型数据集
创建/删除索引
/* #方法一:创建表时 CREATE TABLE 表名 ( 字段名1 数据类型 [完整性约束条件…], 字段名2 数据类型 [完整性约束条件…], [UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY [索引名] (字段名[(长度)] [ASC |DESC]) ); #方法二:CREATE在已存在的表上创建索引 CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名 ON 表名 (字段名[(长度)] [ASC |DESC]) ; #方法三:ALTER TABLE在已存在的表上创建索引 ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名 (字段名[(长度)] [ASC |DESC]) ; #删除索引:DROP INDEX 索引名 ON 表名字; #删除主键索引: ALTER TABLE 表名 DROP PRIMARY KEY; #显示索引信息: SHOW INDEX FROM student; */ /*增加全文索引*/ ALTER TABLE `school`.`student` ADD FULLTEXT INDEX `studentname` (`StudentName`); /*EXPLAIN : 分析SQL语句执行性能*/ EXPLAIN SELECT * FROM student WHERE studentno='1000'; /*使用全文索引*/ EXPLAIN SELECT *FROM student WHERE MATCH(studentname) AGAINST('love');
索引的两大类型hash与btree
#我们可以在创建上述索引的时候,为其指定索引类型,分两类 hash类型的索引:查询单条快,范围查询慢 btree类型的索引:b+树,层数越多,数据量指数级增长(我们就用它,因为innodb默认支持它) #不同的存储引擎支持的索引类型也不一样 InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引; MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引; Memory 不支持事务,支持表级别锁定,支持 B-tree、Hash 等索引,不支持 Full-text 索引; NDB 支持事务,支持行级别锁定,支持 Hash 索引,不支持 B-tree、Full-text 等索引; Archive 不支持事务,支持表级别锁定,不支持 B-tree、Hash、Full-text 等索引;
索引准则
- 索引不是越多越好
- 不要对经常变动的数据加索引
- 小数据量的表建议不要加索引
- 索引一般应加在查找条件的字段
MySQL备份
- 数据库备份必要性
- 保证重要数据不丢失
- 数据转移
- MySQL数据库备份方法
- mysqldump备份工具
- 数据库管理工具,如SQLyog
- 直接拷贝数据库文件和相关配置文件
mysqldump客户端
作用 :
- 转储数据库
- 搜集数据库进行备份
- 将数据转移到另一个SQL服务器,不一定是MySQL服务器
语法 :

-- 导出 1. 导出一张表 mysqldump -u用户名 -p密码 库名 表名 > 文件名(D:/a.sql) 2. 导出多张表 mysqldump -u用户名 -p密码 库名 表1 表2 表3 > 文件名(D:/a.sql) 3. 导出所有表 mysqldump -u用户名 -p密码 库名 > 文件名(D:/a.sql) 4. 导出一个库 mysqldump -u用户名 -p密码 -B 库名 > 文件名(D:/a.sql) 可以-w携带备份条件 -- 导入 1. 在登录mysql的情况下: source 备份文件 2. 在不登录的情况下 mysql -u用户名 -p密码 库名 < 备份文件
视图
/* 视图 */ ------------------ 什么是视图: 视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。 视图具有表结构文件,但不存在数据文件。 对其中所引用的基础表来说,视图的作用类似于筛选。定义视图的筛选可以来自当前或其它数据库的一个或多个表,或者其它视图。通过视图进行查询没有任何限制,通过它们进行数据修改时的限制也很少。 视图是存储在数据库中的查询的sql语句,它主要出于两种原因:安全原因,视图可以隐藏一些数据,如:社会保险基金表,可以用视图只显示姓名,地址,而不显示社会保险号和工资数等,另一原因是可使复杂的查询易于理解和使用。 -- 创建视图 CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEW view_name [(column_list)] AS select_statement - 视图名必须唯一,同时不能与表重名。 - 视图可以使用select语句查询到的列名,也可以自己指定相应的列名。 - 可以指定视图执行的算法,通过ALGORITHM指定。 - column_list如果存在,则数目必须等于SELECT语句检索的列数 -- 查看结构 SHOW CREATE VIEW view_name -- 删除视图 - 删除视图后,数据依然存在。 - 可同时删除多个视图。 DROP VIEW [IF EXISTS] view_name ... -- 修改视图结构 - 一般不修改视图,因为不是所有的更新视图都会映射到表上。 ALTER VIEW view_name [(column_list)] AS select_statement -- 视图作用 1. 简化业务逻辑 2. 对客户端隐藏真实的表结构 -- 视图算法(ALGORITHM) MERGE 合并 将视图的查询语句,与外部查询需要先合并再执行! TEMPTABLE 临时表 将视图执行完毕后,形成临时表,再做外层查询! UNDEFINED 未定义(默认),指的是MySQL自主去选择相应的算法。
触发器
/* 锁表 */ 表锁定只用于防止其它客户端进行不正当地读取和写入 MyISAM 支持表锁,InnoDB 支持行锁 -- 锁定 LOCK TABLES tbl_name [AS alias] -- 解锁 UNLOCK TABLES /* 触发器 */ ------------------ 触发程序是与表有关的命名数据库对象,当该表出现特定事件时,将激活该对象 监听:记录的增加、修改、删除。 -- 创建触发器 CREATE TRIGGER trigger_name trigger_time trigger_event ON tbl_name FOR EACH ROW trigger_stmt 参数: trigger_time是触发程序的动作时间。它可以是 before 或 after,以指明触发程序是在激活它的语句之前或之后触发。 trigger_event指明了激活触发程序的语句的类型 INSERT:将新行插入表时激活触发程序 UPDATE:更改某一行时激活触发程序 DELETE:从表中删除某一行时激活触发程序 tbl_name:监听的表,必须是永久性的表,不能将触发程序与TEMPORARY表或视图关联起来。 trigger_stmt:当触发程序激活时执行的语句。执行多个语句,可使用BEGIN...END复合语句结构 -- 删除 DROP TRIGGER [schema_name.]trigger_name 可以使用old和new代替旧的和新的数据 更新操作,更新前是old,更新后是new. 删除操作,只有old. 增加操作,只有new. -- 注意 1. 对于具有相同触发程序动作时间和事件的给定表,不能有两个触发程序。 -- 字符连接函数 concat(str1[, str2,...]) -- 分支语句 if 条件 then 执行语句 elseif 条件 then 执行语句 else 执行语句 end if; -- 修改最外层语句结束符 delimiter 自定义结束符号 SQL语句 自定义结束符号 delimiter ; -- 修改回原来的分号 -- 语句块包裹 begin 语句块 end -- 特殊的执行 1. 只要添加记录,就会触发程序。 2. Insert into on duplicate key update 语法会触发: 如果没有重复记录,会触发 before insert, after insert; 如果有重复记录并更新,会触发 before insert, before update, after update; 如果有重复记录但是没有发生更新,则触发 before insert, before update 3. Replace 语法 如果有记录,则执行 before insert, before delete, after delete, after insert

