
第六章深入python的set和dict
1.collections中的abc
- MutableMapping是Mapping的子类
- Mapping是Collection的子类
- Collection是Sized,Iterable,Container的子类
- dict被注册到MutableMapping中拥有了MutableMapping的方法,dict是鸭子类型,相当于MutableMapping的子类。




1 from collections.abc import MutableMapping 2 3 # dict属于MutableMapping类型 4 5 a = {} 6 print(isinstance(a, MutableMapping)) # True
2.dict的常见用法
1 a = {"1":{"a":"aa"}, 2 "2":{"b":"bb"}} 3 4 # 清空字典 5 a.clear() 6 7 # 浅拷贝字典 浅拷贝虽然可以正常赋值,但是如果 my_dopy_dict 中的值进行了改变,则 a 中的值也会进行对应的改变 8 my_dopy_dict = a.copy() 9 10 # 深拷贝 深拷贝则是实实在在的在内存当中声明了一个新的变量 11 import copy 12 new_dict = copy.deepcopy(a) 13 14 # get函数 dict.get(要查找的key,如果没找到对应key的内容返回的数据) 15 print(a.get("3",{1:"3"})) # {1: '3'} 16 17 # dict.fromkeys() 函数用于创建一个新字典,以序列 seq 中元素做字典的键 seq可以是可迭代的,value 为字典所有键对应的初始值。 18 my_list = [1, 2, 3] 19 my_new_dict = dict.fromkeys(my_list, {"222":"3434"}) #{1: {'222': '3434'}, 2: {'222': '3434'}, 3: {'222': '3434'}} 20 21 # setdefault() 函数和 get()方法 类似, 22 # 如果键不存在于字典中,将会添加键并将值设为默认值。 23 # 如果存在,则将会返回该key对应的value 24 a.setdefault("3", "cc") # a= {'1': {'a': 'aa'}, '2': {'b': 'bb'}, '3': 'cc'} 25 print(a.setdefault("2", "cc")) # 返回{'b': 'bb'} 26 27 # update() 函数是合并两个字典:把字典dict2的键/值对更新到dict里。 28 # 如果字典b中有与a相同的key,则会把a中的key对应的value进行更新 29 # 如果字典b中有a中没有的key,则a会将未有的key与value添加进去 30 b = {"3": "cc", "2": "dd"} 31 a.update(b) 32 print(a) # {'1': {'a': 'aa'}, '2': 'dd', '3': 'cc'}
3.dict的子类
- 不可以去继承dict类,由于dict实现方式是C语言实现(没有重写方法的概念),所以重写dict中的方法是无效的
- 可以去继承UserDict类,UserDict类是由python语言自己实现的可以重写
- 我们也可以不去继承dict类而是去使用dict的子类defaultdict,由于defaultdict构造函数需要传入一个工厂所以我们传入dict来构造defaultdict
1 class Mydict(dict): 2 def __setitem__(self, key, value): 3 super().__setitem__(key, value * 2) 4 5 6 my_dict = Mydict(one=1) 7 print(my_dict) # {'one': 1} 不可以修改 8 my_dict["one"] = 1 9 print(my_dict) # {'one': 2} 可以像C语言一样修改
1 from collections import UserDict 2 3 4 class Mydict(UserDict): 5 def __setitem__(self, key, value): 6 super().__setitem__(key, value * 5) 7 8 9 my_dict = Mydict(one=3) 10 print(my_dict) # {'one': 15} 调用重写的__setitem__ 11 my_dict["one"] = 4 12 print(my_dict) # {'one': 20} 调用重写的__setitem__
1 from collections import defaultdict 2 3 my_dict = defaultdict(dict) # dict的子类 4 print(my_dict["bobby"]) # {},不存在则返回{} 5 pass
4.set和frozenset
- set:无序,不重复,可修改集合
- frozenset:无序,不重复,不可修改集合
1 a = set('abcdee') 2 a.add('f') 3 print(a) # {'a', 'd', 'c', 'b', 'e', 'f'} 4 another_set = set('defgh') 5 # 添加数据 6 a.update(another_set) 7 print(a) # {'a', 'd', 'c', 'b', 'e', 'g', 'f', 'h'} 8 # 集合的差集 9 re_set = a.difference(another_set) 10 # 减法实现于__ior__魔法函数 11 re_set2 = a - another_set 12 # 集合的交集& 13 re_set3 = a & another_set 14 # 集合的并集| 15 re_set4 = a | another_set 16 print(re_set) # {'c', 'a', 'b'} 17 print(re_set2) # {'c', 'a', 'b'} 18 print(re_set3) # {'d', 'e', 'g', 'f', 'h'} 19 print(re_set4) # {'a', 'd', 'c', 'b', 'e', 'g', 'f', 'h'} 20 # 也可以用if in判断(实现于__contains__魔法函数) 21 if 'a' in re_set: 22 print('a in re_set') # a in re_set
5.dict和set实现原理
- set和dict的查询性能远远好于list
- list会随数据量的增大而增大,set和dict不会
dist和set使用哈希表存储:
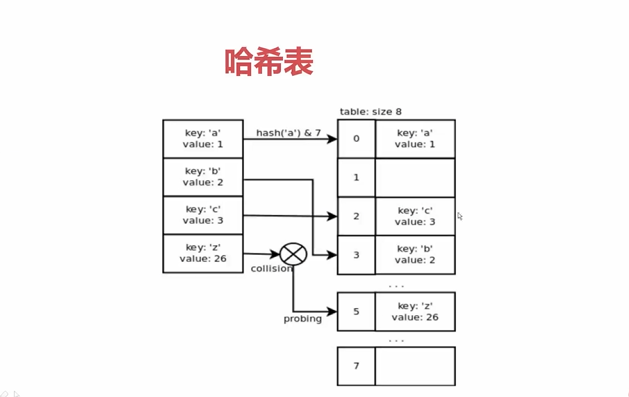
注意:
- dict的key以及set的value都必须是可以hash的
- 什么是可以hash:不可变对象:str,frozenset,tuple以及自己实现了__hash__的类
- dict的内存花销大,但查询速度快,自定义的对象或python内部的对象都是用dict包装的
- dict的存储顺序和元素添加顺序有关
- dict在添加数据时可能改变已有数据的顺序

