
第二次作业-通过Fiddle分析抓包相关数据,基于Python开发实现数据的展现批量导入本地
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzzcxy/ZhichengSoftengineeringPracticeFclass/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzzcxy/ZhichengSoftengineeringPracticeFclass/homework/12532 |
| 这个作业的目标 | 培养良好编码习惯,并通过抓包工具分析post、get协议,并模拟请取数据对进行json解析 |
| Github 地址 | https://github.com/1242239352/02task |
一、基于Pyhton+Fiddler开发的扑扑商品波动监控
-
(1)解题思路描述
-
1、安装夜神安卓模拟器.
-
2、启动Fiddler基础配置代理模拟器.
-
3、启动扑扑App对搜索栏搜索后请求到数据进行 抓包分析.
-
4、分析请求返回的数据对其进行 Json解析,并将相关内容记录在文档中,方便后续使用.
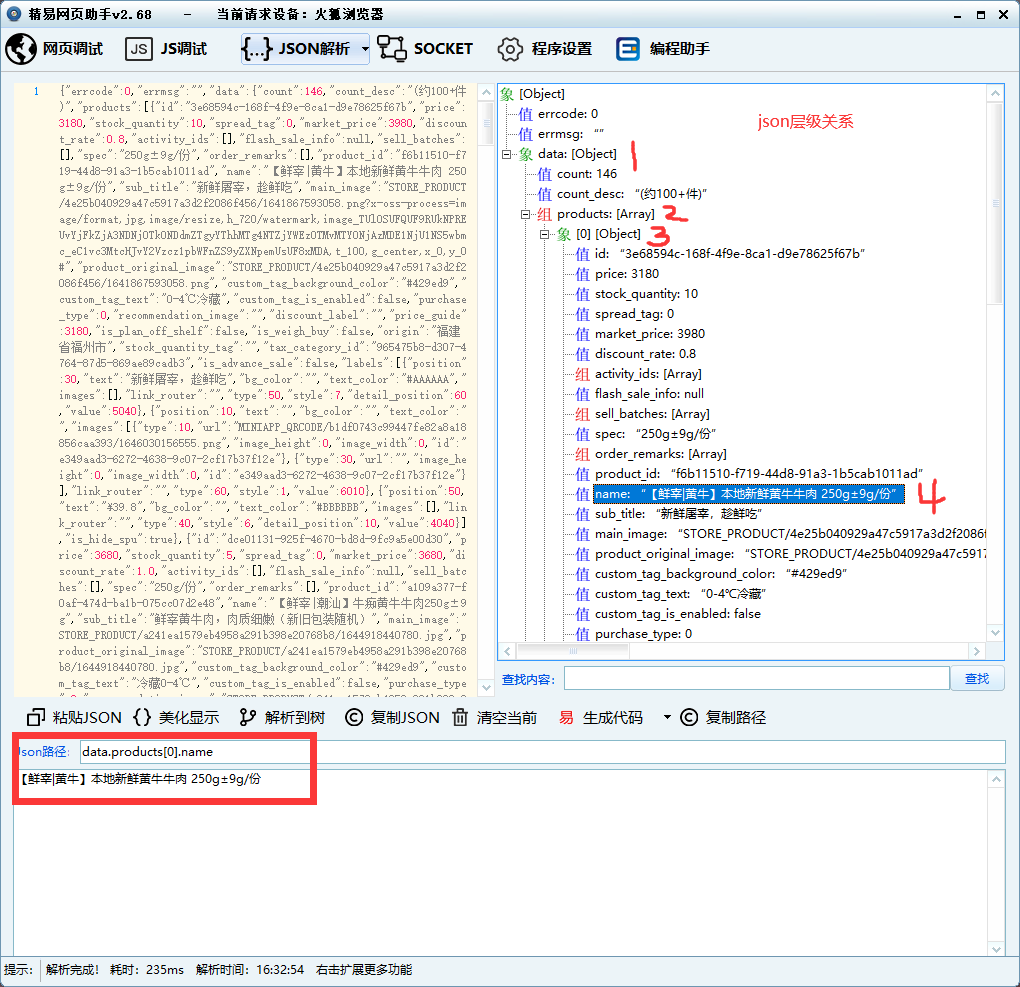
-
5、扑扑协议分析
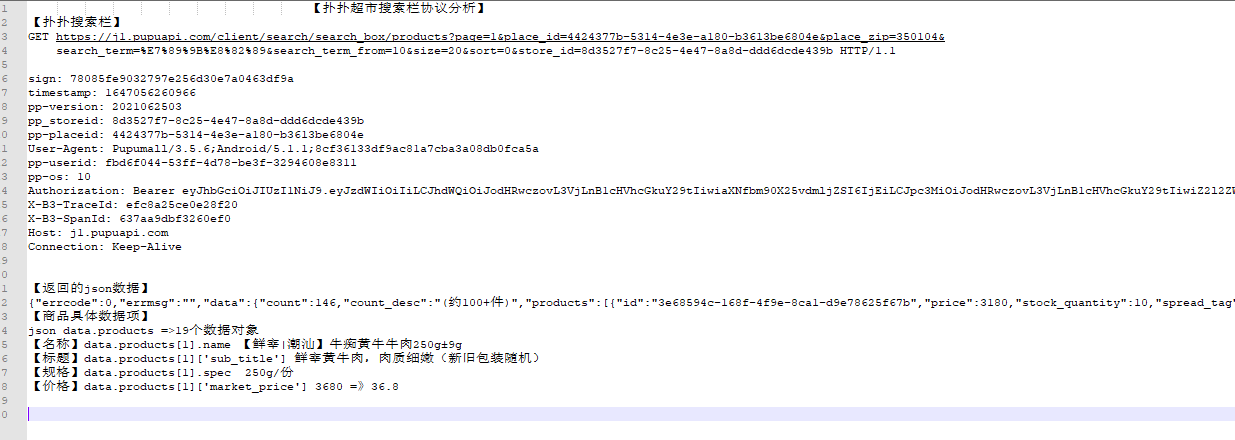
-
6、使用PyCharm编写代码.
-
-
(2)扑扑商品波动监控设计实现过程
-
1、设计类 class PPshoping:
-
2、方法设计分别是
-
#该方法主要实现模拟请求数据. def PP_collection(self,ShoppingName): #数据请求地址 url = "https://j1.pupuapi.com/client/search/search_box/products?page=1&place_id=4424377b-5314-4e3e-a180-b3613be6804e&place_zip=350104&search_term="+ShoppingName+"&search_term_from=30&size=20&sort=0&store_id=8d3527f7-8c25-4e47-8a8d-ddd6dcde439b" #请求地址对应协议头 headers={ "sign": "a274aa8faac2cc26d1cb1b8b937d197e", "timestamp": "1647085191304", "pp-version": "2021062503", "pp_storeid": "8d3527f7-8c25-4e47-8a8d-ddd6dcde439b", "pp-placeid": "4424377b-5314-4e3e-a180-b3613be6804e", "User-Agent": "Pupumall/3.5.6;Android/5.1.1;8cf36133df9ac81a7cba3a08db0fca5a", "pp-userid": "fbd6f044-53ff-4d78-be3f-3294608e8311", "pp-os": "10", "Authorization": "Bearer eyJhbGciOiJIUzI1NiJ9.eyJzdWIiOiIiLCJhdWQiOiJodHRwczovL3VjLnB1cHVhcGkuY29tIiwiaXNfbm90X25vdmljZSI6IjEiLCJpc3MiOiJodHRwczovL3VjLnB1cHVhcGkuY29tIiwiZ2l2ZW5fbmFtZSI6Ikh1Z3MgfiIsImV4cCI6MTY0NzA5MjY4MCwidmVyc2lvbiI6IjIuMCIsImp0aSI6ImZiZDZmMDQ0LTUzZmYtNGQ3OC1iZTNmLTMyOTQ2MDhlODMxMSJ9.hwBXxciOEwhpg_eXqSrYeHxa4MIKCnBpR0tRV5DRHVA", "X-B3-TraceId": "d7b0ab80c36da790", "X-B3-SpanId": "8f70235fd631bf20", "Host": "j1.pupuapi.com", "Connection": "Keep-Alive", } #get方式请求数据 response =requests.get(url=url,headers=headers,verify=False) #loads方法是把json对象转化为python对象 jsonshopping=json.loads(response.text) # 调用json数据分割方法 分别取出对应数据 Pupu_Title, Pupu_spec, Pupu_price, Pupu_market_price, Pupu_sub_name= self.PP_POST_JSON(jsonshopping,0) print("-----------------------商品:"+Pupu_Title+"-----------------------") print("规格:"+Pupu_spec) print("价格:"+str(Pupu_price)) print("原价/折扣价:"+str(Pupu_market_price)+"/"+str(Pupu_price)) print("详细信息:"+Pupu_Title+" "+Pupu_sub_name) print("--------------------监控不同商品的价格波动--------------------") i=0 while(True): Pupu_Title, Pupu_spec, Pupu_price, Pupu_market_price, Pupu_sub_name = self.PP_POST_JSON(jsonshopping, i) print("当前时间为"+str(self.GetNowTime())+" ,"+Pupu_Title+":价格为"+str(Pupu_price)) sleep(3) i=i+1 if(i==19): i=0
-
#该方法主要实现请求后的数据进行json分割. def PP_POST_JSON(self,jsonshopping,i): # 标题 Pupu_Title = jsonshopping['data']['products'][i]['name'] # 规格 Pupu_spec = jsonshopping['data']['products'][i]['spec'] # 折扣价格 Pupu_price = round(jsonshopping['data']['products'][i]['price'] / 100, 1) # 原价 Pupu_market_price = round(jsonshopping['data']['products'][i]['market_price'] / 100, 1) # 详细内容 Pupu_sub_name = jsonshopping['data']['products'][i]['sub_title'] return Pupu_Title,Pupu_spec,Pupu_price,Pupu_market_price,Pupu_sub_name
-
#返回当前时间 def GetNowTime(self): return datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
-
#运行启动 def run(self): #url(utf-8)编码 Search_goods=parse.quote("牛肉") self.PP_collection(Search_goods)
-
-
3、关键函数使用
-
#get方式请求数据 response =requests.get(url=url,headers=headers,verify=False)
-
#json.loads方法是把json对象转化为python对象 jsonshopping=json.loads(response.text)
-
#返回当前系统的时间 datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
-
-
4、设计实现思维导图
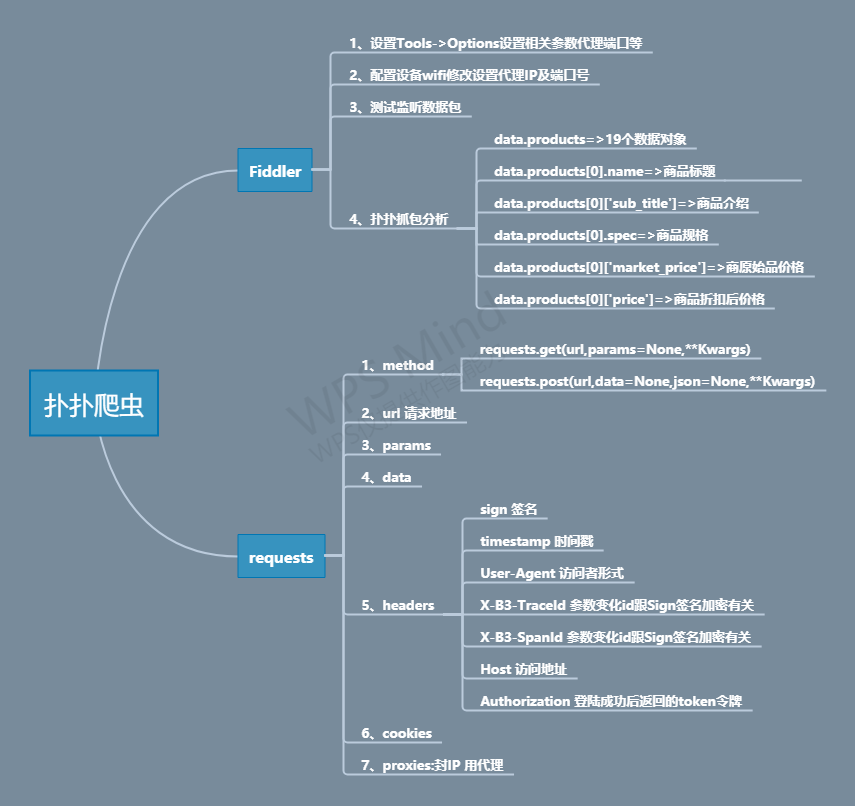
-
5、GitHub推送

-
-
(3)后期改进想法
1、针对扑扑的算法进行脱壳分析并使用逆向JS分析技术解密出Sign的MD5加密组合形式
2、实现能全局搜索不同的商品并实现不同形式的商品监控
-
(4)运行效果截图

二、基于Pyhton+Fiddler开发的知乎收藏夹的爬虫
-
(1)解题思路描述
-
1、先登陆创建文件夹.初始化相关数据收藏
-
2、配合Fiddler抓包收藏主页相关内容
-
3、模拟请求该收藏主页面数据 返回html数据
-
4、通过正则表达式分别取出收藏夹的子类地址及收藏夹名称,分别存入数组中
-
5、模拟请求收藏子类的地址 返回Json数据
-
6、分析请求返回的数据对其进行 Json解析,并将相关内容记录在文档中,方便后续使用.
-
7、判断路径下是否有该目录 或是否存在该文件夹如果没有进行创建
-
8、将Json解析后分别渠道的标题、链接、部分内容写入文档中保留
-
9、知乎协议分析过程
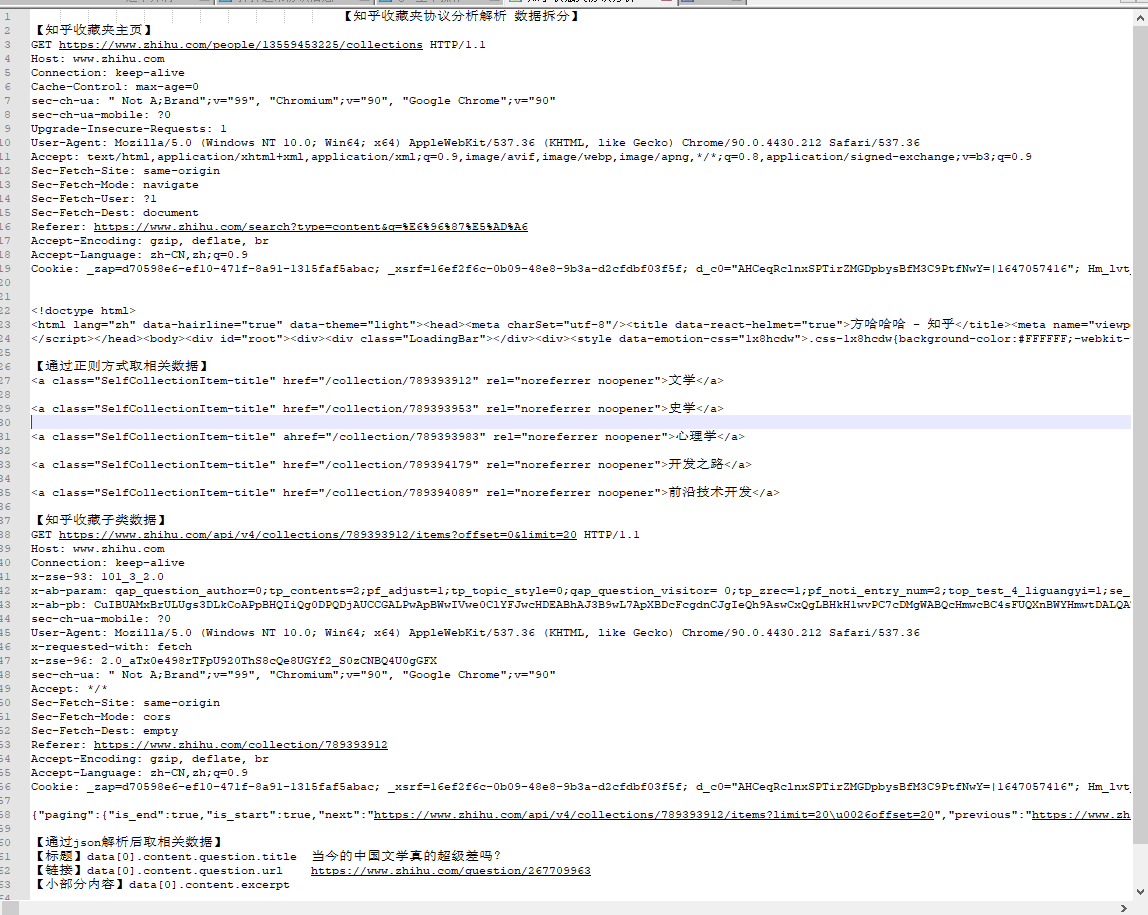
-
-
(2)知乎收藏夹文章内容提取保存开发设计实现过程
-
1、ZhihuPost 类
-
2、函数方法设计:
-
#知乎收藏夹数据采集 def Zhihu_Favorites_collection(self): #知乎主页地址 url="https://www.zhihu.com/people/13559453225/collections" headers = { "Host": "www.zhihu.com", "Connection": "keep-alive", "Cache-Control": "max-age=0", "sec-ch-ua-mobile": "?0", "Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9", "Sec-Fetch-Site": "same-origin", "Sec-Fetch-User": "?1", "Sec-Fetch-Dest": "document", "Referer": "https://www.zhihu.com/search?type=content&q=%E6%96%87%E5%AD%A6", "Accept-Language": "zh-CN,zh;q=0.9", } # get方式请求数据 response = requests.get(url=url, headers=headers, verify=False) self.FavoritesId,self.FavoritesTitle=self.Re_Favorites_IdAndTitle(response.text) for i in range(len(self.FavoritesId)): self.Zhihu_Subclass_collection(self.FavoritesId[i],self.FavoritesTitle[i]) sleep(3)
-
#知乎收藏夹子类数据采集 def Zhihu_Subclass_collection(self,urlid,title): # 知乎主页地址 url = "https://www.zhihu.com/api/v4/collections/"+urlid+"/items?offset=0&limit=20" print(url) headers = { "Host": "www.zhihu.com", "Connection": "keep-alive", "Cache-Control": "max-age=0", "x-zse-93":"101_3_2.0", "sec-ch-ua-mobile": "0", "Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36", "x-requested-with":"fetch", "x-zse-96":"2.0_aTx0e498rTFpU920ThS8cQe8UGYf2_S0zCNBQ4U0gGFX", "Sec-Fetch-Site": "same-origin", "Sec-Fetch-Mode": "cors", "Sec-Fetch-Dest": "empty", "Referer": "https://www.zhihu.com/collection/"+urlid, "Accept-Language": "zh-CN,zh;q=0.9", } # get方式请求数据 response = requests.get(url=url, headers=headers, verify=False) # loads方法是把json对象转化为python对象 jsonzhihu= json.loads(response.text) # 调用json数据分割方法 分别取出对应数据 self.Zhihu_json(jsonzhihu,title)
-
```python #正则取收藏夹的标题 及对应收藏夹链接ID 返回匹配到的数据的数组 def Re_Favorites_IdAndTitle(self,Text): #str_1="<a href='/collection/789393912' rel='noreferrer noopener'>文学</a><a href='/collection/789393111912' rel='noreferrer noopener'>文学111</a><a href='/collection/789393922212' rel='noreferrer noopener'>文学2222</a>" FavoritesTitle=[] FavoritesId=re.findall(r"<a class=\"SelfCollectionItem-title\" href=\"/collection/(.*?)\" rel",Text) for i in FavoritesId: str=re.findall(r"<a class=\"SelfCollectionItem-title\" href=\"/collection/"+i+"\" rel=\"noreferrer noopener\">(.*?)</a>",Text) FavoritesTitle.append(str[0]) return FavoritesId,FavoritesTitle ```
-
#解析json数据 取出相关内容 并写入文档中 def Zhihu_json(self,JsonText,sctitle): # 取出对象数 num = JsonText['paging']['totals'] print("对象数="+str(num)) for i in range(0,num-1,1): try: # 标题 title = JsonText['data'][i]['content']['question']['title'] # 链接 scurl = JsonText['data'][i]['content']['question']['url'] # 部分内容 BfText = JsonText['data'][i]['content']['excerpt'] except Exception: # 标题 title = JsonText['data'][i]['content']['title'] # 链接 scurl = JsonText['data'][i]['content']['url'] # 部分内容 BfText = JsonText['data'][i]['content']['excerpt_title'] # 判断目录,有则打开,没有新建 if os.path.exists(r'C:\Users\ASUS\Desktop\构建之法作业\02\知乎收藏夹内容'): os.chdir(r'C:\Users\ASUS\Desktop\构建之法作业\02\知乎收藏夹内容') else: os.mkdir(r'C:\Users\ASUS\Desktop\构建之法作业\02\知乎收藏夹内容') os.chdir(r'C:\Users\ASUS\Desktop\构建之法作业\02\知乎收藏夹内容') if os.path.exists(r'C:\Users\ASUS\Desktop\构建之法作业\02\知乎收藏夹内容\\' + sctitle): os.chdir(r'C:\Users\ASUS\Desktop\构建之法作业\02\知乎收藏夹内容\\' + sctitle) else: os.mkdir(r'C:\Users\ASUS\Desktop\构建之法作业\02\知乎收藏夹内容\\' + sctitle) os.chdir(r'C:\Users\ASUS\Desktop\构建之法作业\02\知乎收藏夹内容\\' + sctitle) # 往对应文件夹里添加内容 Mlurl = r'C:\Users\ASUS\Desktop\构建之法作业\02\知乎收藏夹内容\\' + sctitle + '\\' + title + '.txt' myfile = open(Mlurl, 'w', encoding='utf-8') myfile.write(scurl + "\n" + BfText) myfile.close() print(sctitle+"收藏夹第"+str(i)+"篇文章"+title+"=》"+scurl+"=》爬取成功") print(title,scurl,BfText) -
3、函数直接的关系图
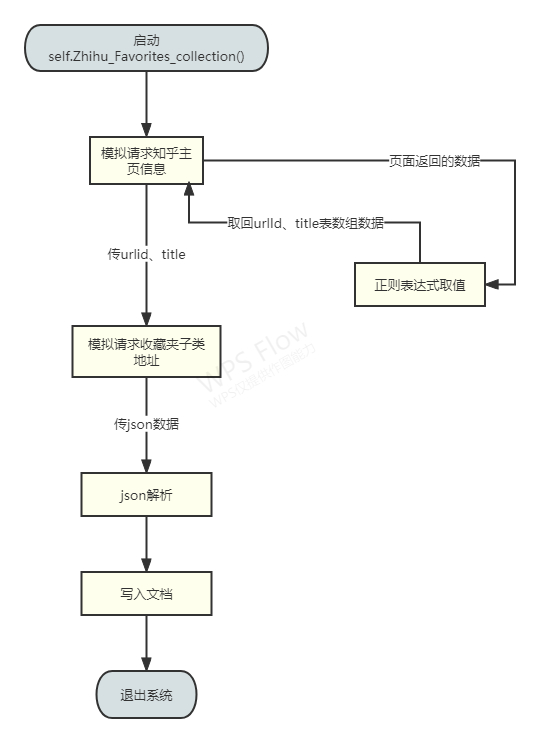
-
4、GitHub推送
-
-
-
(3)后期改进想法
1、通过手机号验证码协议登陆获取令牌 考虑到协议头的时效性
2、搜索栏式增加全局性自定义性数据搜索爬虫
3、增加关键字识别提取相关重要内容
-
(4)运行效果图


三、基于Pyhton+Fiddler开发的拉勾网数据爬虫
-
(1)解题思路描述
-
1、登陆拉钩网首页简单分析页面结构
-
2、从搜索栏搜索尝试请求数据并抓取相应数据包内容
-
3、分析数据包协议 及提交方式
-
4、对返回的JSON数据进行逐层剖析拆分找到需要的数据对象下的内容
-
5、以上基本工作完成后接下来开始代码的逻辑设计以及编写
-
6、分别设计了8个全局变量值
-
#查询总职位数 self.Cxnum=0 #当前查询到哪个职位上数 self.Dqnum=0 #相关数据的对应数据组 self.positionName = [] #存岗位名称 self.City = [] #存市 self.District = [] #存区 self.CompanyFullName = [] #存公司名称 self.CompanySize = [] #公司规模 self.salary = [] #薪资
-
-
7、设计了三个方法降低数据的冗余增加代码重复使用性
-
""" 拉钩招聘数据采集 @:param Search_position 岗位 @:param Pn 页数 """ def Lagou_collection(self,Search_position,Pn): """ 解析json数据 取出相关内容 并写入文档中 @:param JsonText json数据 """ def Lagou_json(self,JsonText): """ 保存数据到excel文件中 @:param num 对象数量 @:param positionName 职位名称 @:param City 市 @:param District 区 @:param CompanyFullName 公司名称 @:param CompanySize 规模 @:param salary 薪资 """ def defsava_excel(self,positionName,City,District,CompanyFullName,CompanySize,salary):
-
-
8、通过xlwt方式将数据存入excel表中
-
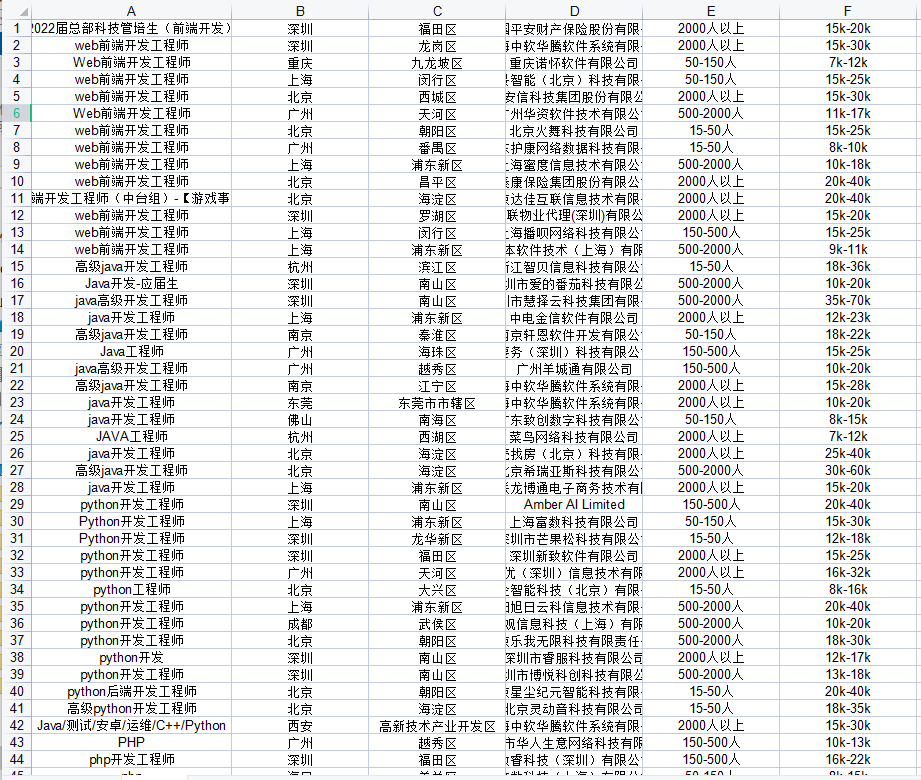
-
9、拉勾网招聘协议分析
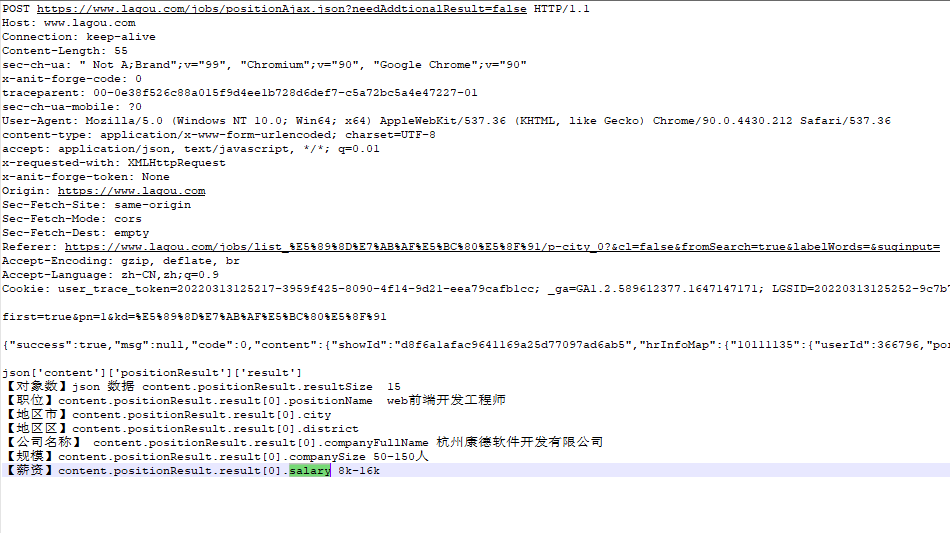
-
(2)拉钩招聘网不同岗位薪资数据保存开发设计实现过程
-
1、LaGouPost类
-
2、函数方法的设计
-
""" 拉钩招聘数据采集 @:param Search_position 岗位 @:param Pn 页数 """ def Lagou_collection(self,Search_position,Pn): #拉钩招聘数据api url="https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false" headers = { "Host": "www.lagou.com", "Connection": "keep-alive", "x-anit-forge-code": "0", "traceparent": "00-0e38f526c88a015f9d4ee1b728d6def7-c5a72bc5a4e47227-01", "sec-ch-ua-mobile": "?0", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36", "content-type": "application/x-www-form-urlencoded; charset=UTF-8", "accep": "application/json, text/javascript, */*; q=0.01", "x-requested-with": "XMLHttpRequest", "x-anit-forge-toke": "None", "Origin":"https://www.lagou.com", "Sec-Fetch-Site": "same-origin", "Sec-Fetch-Mode": "cors", "Sec-Fetch-Dest": "empty", "Referer": "https://www.lagou.com/jobs/list_%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=", "Accept-Language": "zh-CN,zh;q=0.9", "Cookie": "user_trace_token=20220313125217-3959f425-8090-4f14-9d21-eea79cafb1cc; _ga=GA1.2.589612377.1647147171; LGSID=20220313125252-9c7b70d7-2b04-4efc-895b-0a484f335d6f; PRE_UTM=m_cf_cpt_baidu_pcbt; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Flanding-page%2Fpc%2Fsearch.html%3Futm%5Fsource%3Dm%5Fcf%5Fcpt%5Fbaidu%5Fpcbt; LGUID=20220313125252-5264a6e2-29c8-4e57-af3b-68bd222be1c5; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1647147171; _gid=GA1.2.31684987.1647147247; sajssdk_2015_cross_new_user=1; gate_login_token=ad34d65330dcc2aa20fbc29795a01eb8cd8be27a97ee0334c6ecf65c0cb0105a; LG_LOGIN_USER_ID=aaa6d8fb24fb5f8475664272c2560a720b0af8677616f87778b3a0cbb05411fd; LG_HAS_LOGIN=1; _putrc=FAEB8F0633231DC8123F89F2B170EADC; JSESSIONID=ABAAAECABIEACCA9FB41C5C123C62AEEDA94168551121B6; login=true; hasDeliver=0; privacyPolicyPopup=false; WEBTJ-ID=20220313%E4%B8%8B%E5%8D%8812:55:05125505-17f81a14971480-0035520476d2-2363163-2073600-17f81a14972bd2; sensorsdata2015session=%7B%7D; unick=%E6%96%B9%E6%99%93%E4%BD%B3; RECOMMEND_TIP=true; __SAFETY_CLOSE_TIME__18626316=1; index_location_city=%E5%85%A8%E5%9B%BD; __lg_stoken__=dbfefc871edf710df7582985dee2ffd8170c1e12dd6b7926f1b854fae0f914202be16c09469620d5b8751ffde1ba364e0e6df63c2e7098b6d247b87a4d9abf7000d7ed6ba8c6; TG-TRACK-CODE=search_code; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2218626316%22%2C%22%24device_id%22%3A%2217f81a0646d68-09932428721ebe-2363163-2073600-17f81a0646e9c1%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24os%22%3A%22Windows%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%2290.0.4430.212%22%7D%2C%22first_id%22%3A%2217f81a0646d68-09932428721ebe-2363163-2073600-17f81a0646e9c1%22%7D; _gat=1; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1647148693; LGRID=20220313131815-bae5231f-a343-4ab6-a3e5-dbe187c7dbff; SEARCH_ID=c45f725c652a4a5b9c5ffbfeb91f0fe9; X_HTTP_TOKEN=038591d682f2abfb8888417461828b7bf478e167c2" } #post数据 岗位需要进行url utf-8编码 data="first=true&pn="+str(Pn)+"&kd="+parse.quote(Search_position) #post方式请求数据 response = requests.post(url=url,data=data ,headers=headers, verify=False) print(response.text) # loads方法是把json对象转化为python对象 jsonLagou= json.loads(response.text) # 调用json数据分割方法 分别取出对应数据 self.Lagou_json(jsonLagou)
-
""" 解析json数据 取出相关内容 并写入文档中 @:param JsonText json数据 """ def Lagou_json(self,JsonText): # 取出对象数 num = JsonText['content']['positionResult']['resultSize'] print("对象数="+str(num)) for i in range(0,num-1,1): # 职位名称 self.positionName.append(JsonText['content']['positionResult']['result'][i]['positionName']) # 市 self. City.append(JsonText['content']['positionResult']['result'][i]['city']) # 区 self.District.append(JsonText['content']['positionResult']['result'][i]['district']) # 公司名称 self.CompanyFullName.append(JsonText['content']['positionResult']['result'][i]['companyFullName']) # 规模 self.CompanySize.append(JsonText['content']['positionResult']['result'][i]['companySize']) # 薪资 self.salary.append(JsonText['content']['positionResult']['result'][i]['salary']) print(self.positionName) print(self.City) print(self.District) print(self.CompanyFullName) print(self.CompanySize) print(self.salary) # 判断目录,有则打开,没有新建 if os.path.exists(r'C:\Users\ASUS\Desktop\构建之法作业\02\拉钩招聘信息'): os.chdir(r'C:\Users\ASUS\Desktop\构建之法作业\02\拉钩招聘信息') else: os.mkdir(r'C:\Users\ASUS\Desktop\构建之法作业\02\拉钩招聘信息') os.chdir(r'C:\Users\ASUS\Desktop\构建之法作业\02\拉钩招聘信息') print(self.Cxnum,self.Dqnum) if(self.Cxnum==self.Dqnum): # 保存数据到excel文件中 self.sava_excel(self.positionName, self.City, self.District, self.CompanyFullName, self.CompanySize, self.salary)
-
""" 保存数据到excel文件中 @:param num 对象数量 @:param positionName 职位名称 @:param City 市 @:param District 区 @:param CompanyFullName 公司名称 @:param CompanySize 规模 @:param salary 薪资 """ def sava_excel(self,positionName,City,District,CompanyFullName,CompanySize,salary): #总数 num=len(positionName) # 打开excel文件 data = xlwt.Workbook() # 获取其中的一个sheet table = data.add_sheet('made') row=0 #行 col=0 #列 for i in range(0,num-1,1): table.write(row,col, positionName[i]) table.write(row, col+1, City[i]) table.write(row, col+2, District[i]) table.write(row, col+3, CompanyFullName[i]) table.write(row, col+4, CompanySize[i]) table.write(row, col+5, salary[i]) row=row+1 col=0 data.save(r"C:\Users\ASUS\Desktop\构建之法作业\02\拉钩招聘信息\Lgtemp.xls") print("数据写入成功。") #启动项 def run(self): str =['前端开发','java','Python','PHP'] #查询岗位数 self.Cxnum=len(str) for i in str: self.Dqnum = self.Dqnum+1 self.Lagou_collection(i,self.Dqnum)
-
-
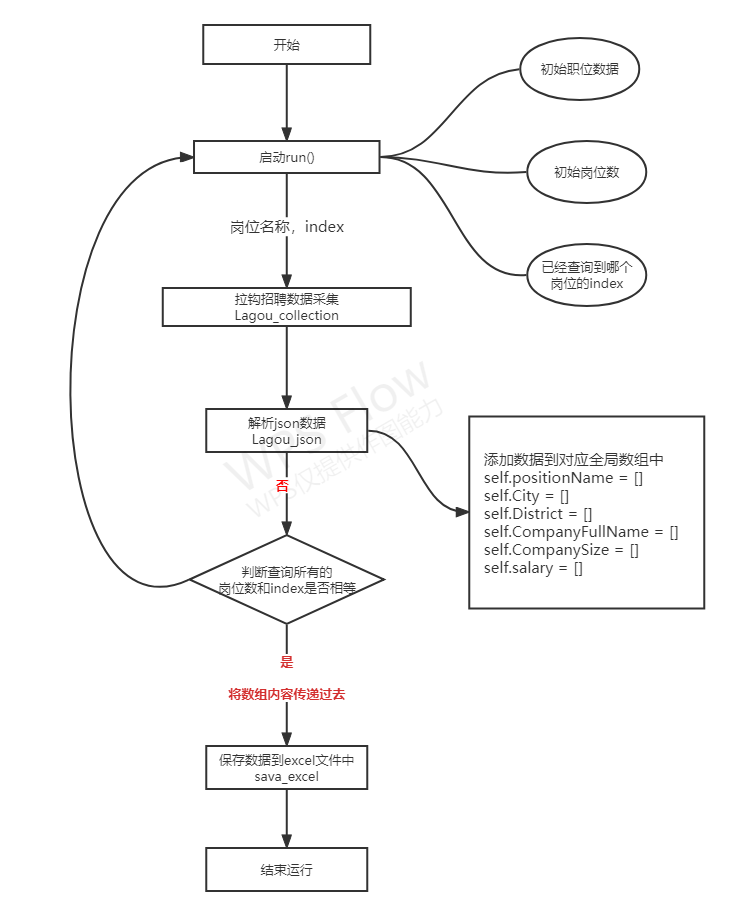
3、函数直接的关系图
-
-
4、GitHub推送
-
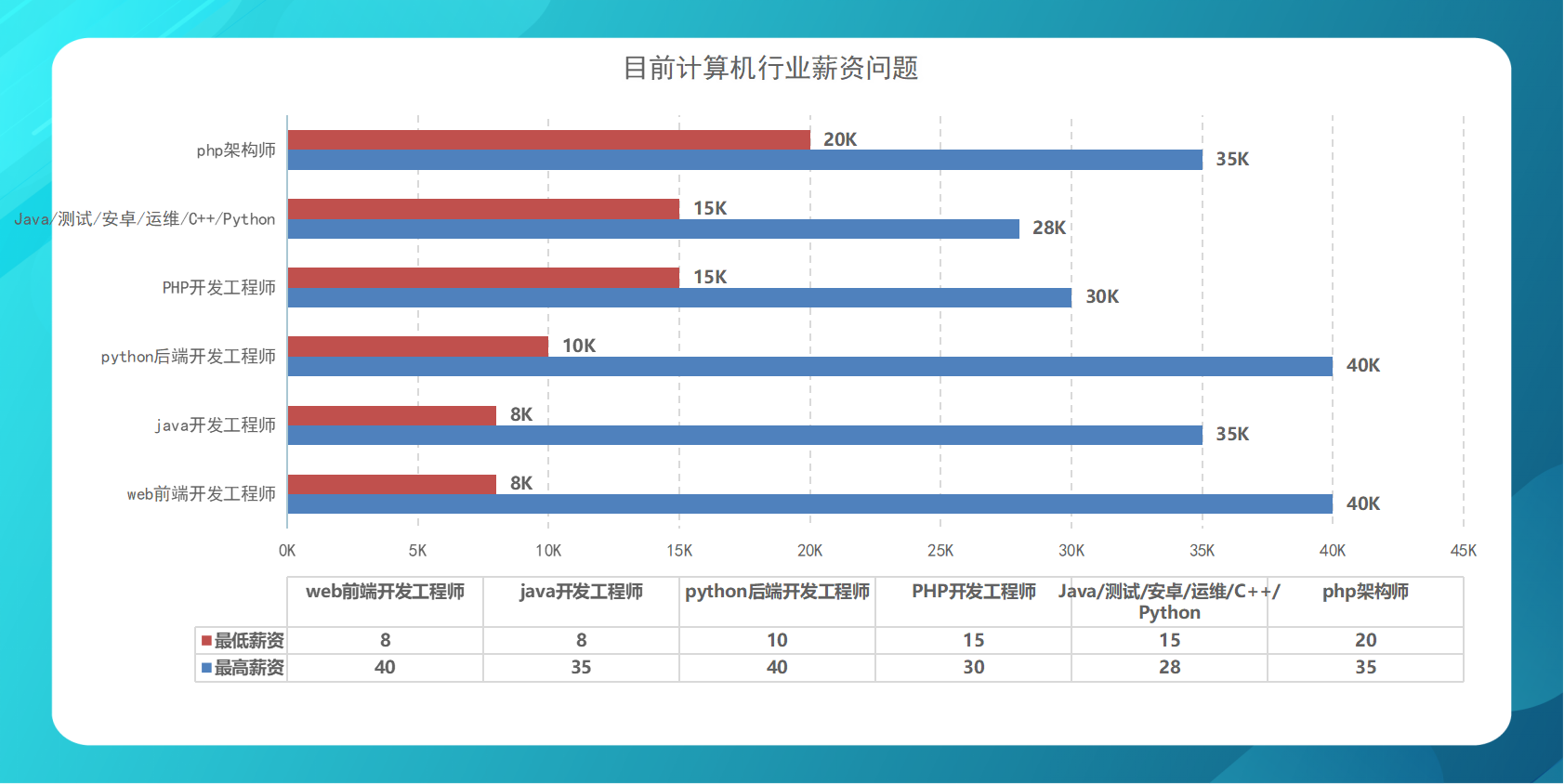
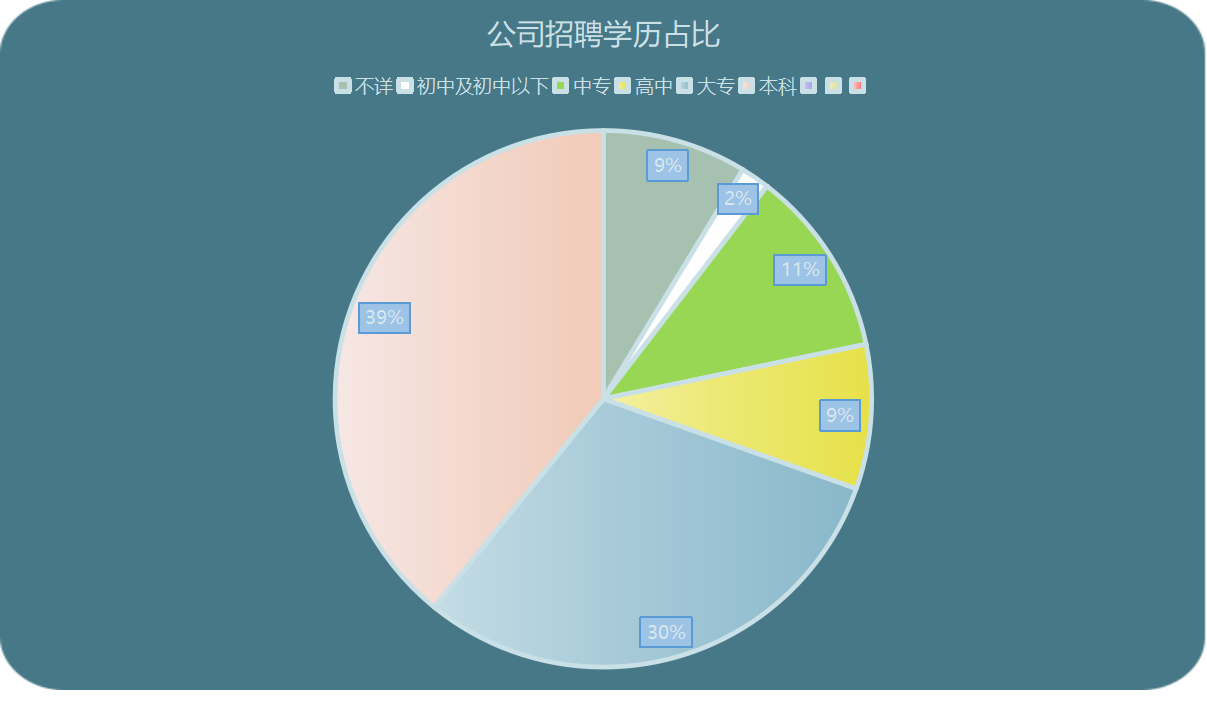
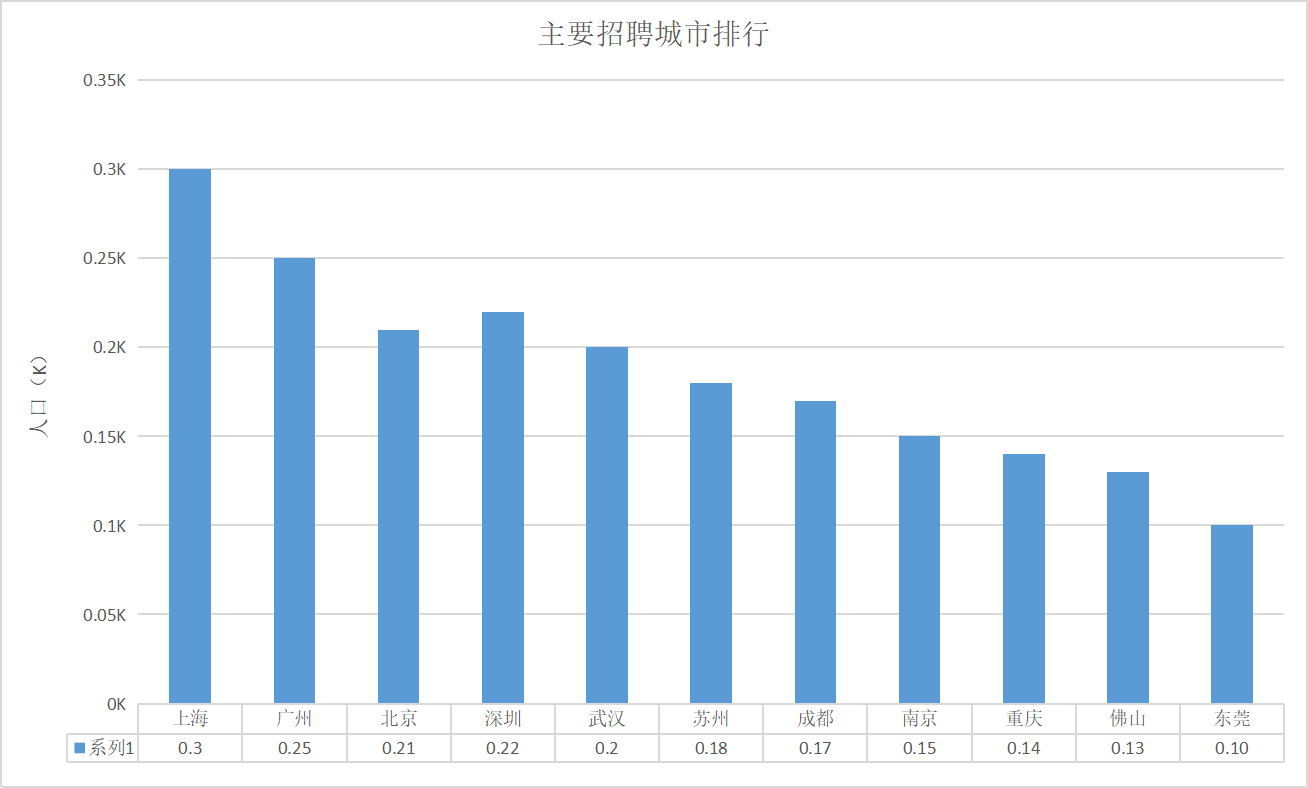
5、拉勾网图表数据展示
-
-
-
(3)、后期改进想法
1、通过Python的相关大数据算法分析得出当前行业比较热捧的专业
2、针对不同行业前景寻找不同公司高薪待遇
3、通过AES and RSA逆向解密方式在网页js数据中找出加密公钥或Key IV值对一些加密传递的数据内容可以轻松解析请求
-
(4)、GitHub仓库展示
四、总结
通过这一次课程作业练习让我很好的回顾了之前所学的知识,加以用之,大大锻炼了我对代码编程的灵敏性以及对看待事物的多面性.
在研究扑扑的过程中有发现Sign的加密算法与所查询物品以及时间戳息息相关,无论改变了哪个参数都无法请求到数据,所有我选择直接用抓包获取的数据信息,后续有时间我会再花时间去深究Sign的解密算法
在研究知乎的过程中最主要的就是用正则表达式取出主页收藏夹相关url以及标题内容,为后续访问子收藏夹里的内容做准备,整体麻烦点就是在处理正则以及json数据解析获取上。
在研究最后一个拉勾网项目有前面几个研究的经验整体还是比较轻松,像对于Post、get网页上这种以Http数据传输方式的最不好的就是数据太过于暴露裸露,随随便便就可以让人爬取相关数据,在拉勾网项目种有看到部分返回的数据有用RSA加密算法返回,也在尝试破解提取到密文。
这次整体锻炼也非常不错整体编写研究耗时一天半,再接再厉。。。。。。。。。。。。。。。

