
ETL方法与过程讲
1 ETL基本概念和术语
1.1 ETL
Extract-Transform-Load的缩写,数据抽取(Extract)、转换(Transform)、装载(Load)的过程。
1.2 DW
DataWarehousing,根据Bill.Inmon的定义,“数据仓库是面向主题的、集成的、稳定的、随时间变化的,主要用于决策支持的数据库系统”。
1.3 MetaData
元数据,就是描述数据的数据,指在数据仓库建设过程中所产生的有关数据源定义、目标定义、转换规则等相关的关键数据。
1.4 ETL在数据仓库中的位置
1.5 数据质量
正确性(Accuracy):数据是否正确体现在现实或可证实的来源
完整性(Integrity):数据之间的参照完整性是否存在或一致
致性(Consistency):数据是否被一致的定义或理解
完备性(Completeness):所有需要的数据是否都存在
有效性(Validity):数据是否在企业定义的可接受的范围之内
时效性(Timeliness):数据在需要的时间是否有效
可获取性(Accessbility):数据是否易于获取、易于理解和易于使用
1.6 数据质量原因
业务系统不同时期数据模型不一致
业务系统不同时期业务过程有变化
各个源系统之间相关信息不一致
遗留系统和新业务、管理系统数据集成不完备带来的不一致性
源系统缺少输入验证过程,不能阻止非法格式的数据进入系统
可以验证但不能改正数据,验证程序不能发现格式正确但内容不正确的错误
源系统不受控制的更改,而这种更改不能及时的传播到受影响的系统
数据由多个交叉的访问界面,难以统一管理数据质量问题
缺少参照完整性检查低劣的源系统设计
数据转换错误,比如ETL过程错误或数据迁移过程的错误
源系统与数据仓库系统的数据组织方式完全不同
1.7 数据转换
空值处理
规范化数据格式
拆分数据
验证数据合法性
数据替换
实现数据规则过滤
数据排序
数据类型统一转换
2 逻辑架构图
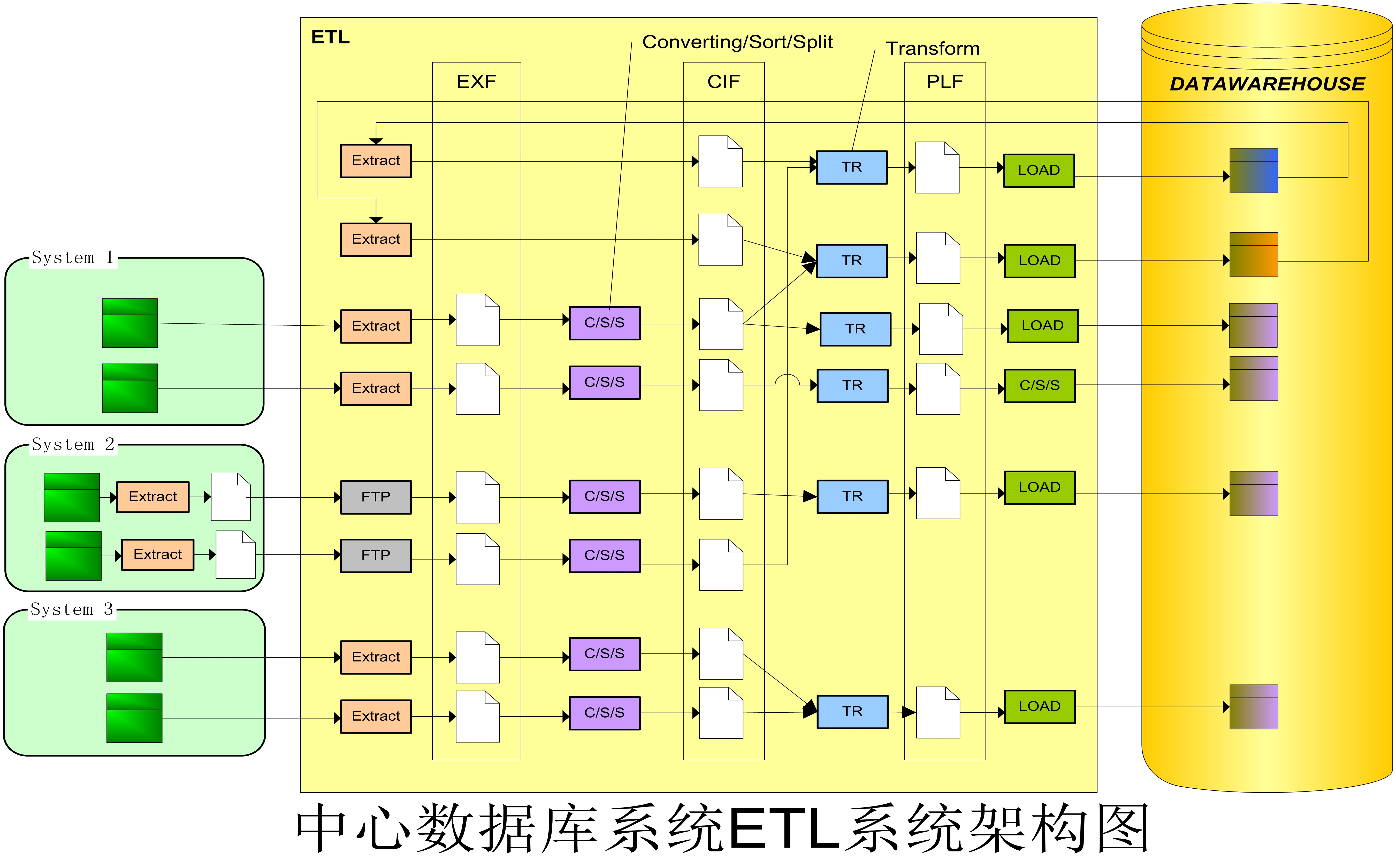
2.1 Extract
设计原则
为提高ETL效率,数据在进入ETL系统后的EXF文件都将转换为Flat Text文件格式
从ETL程序设计的灵活性和整体结构的一致性考虑,尽量采用Pull的方式,减少对源系统的影响和对其他开发队伍的依赖,并减少网络压力
由于Batch Windows的限制,如果日源数据量大于5GB则必须考虑采用Push的方式以提高传送速度,如,可以由源系统将数据转换为Flat Text文件后,由ETL程序采用FTP的方式进行传送
EXF的文件格式接近数据源的数据结构定义
在Extract过程中过滤数据仓库不需要的数据记录和字段
Push和Pull
Push
在源系统上根据定义的数据格式将每日增量数据生成数据文件,再通过FTP或文件拷贝的方式传送给ETL程序处理。
Pull
由ETL程序通过DRDA或ODBC等数据库协议直接访问源数据库获取所需数据进行处理。
2.2 数据转换过程中产生的文件
EXF (Extracted Format)
由数据源Extract产生的文件,文件结构与Source相似,经过过滤,部分字段被忽略。
CIF (Common Interface Format)
CIF是ETL经过C/S/S过程产生的中间数据文件。
PLF (Pre-Load Format)
经过数据转换,用于直接加载到数据仓库的文本文件,其数据结构与数据仓库中的表定义一致。
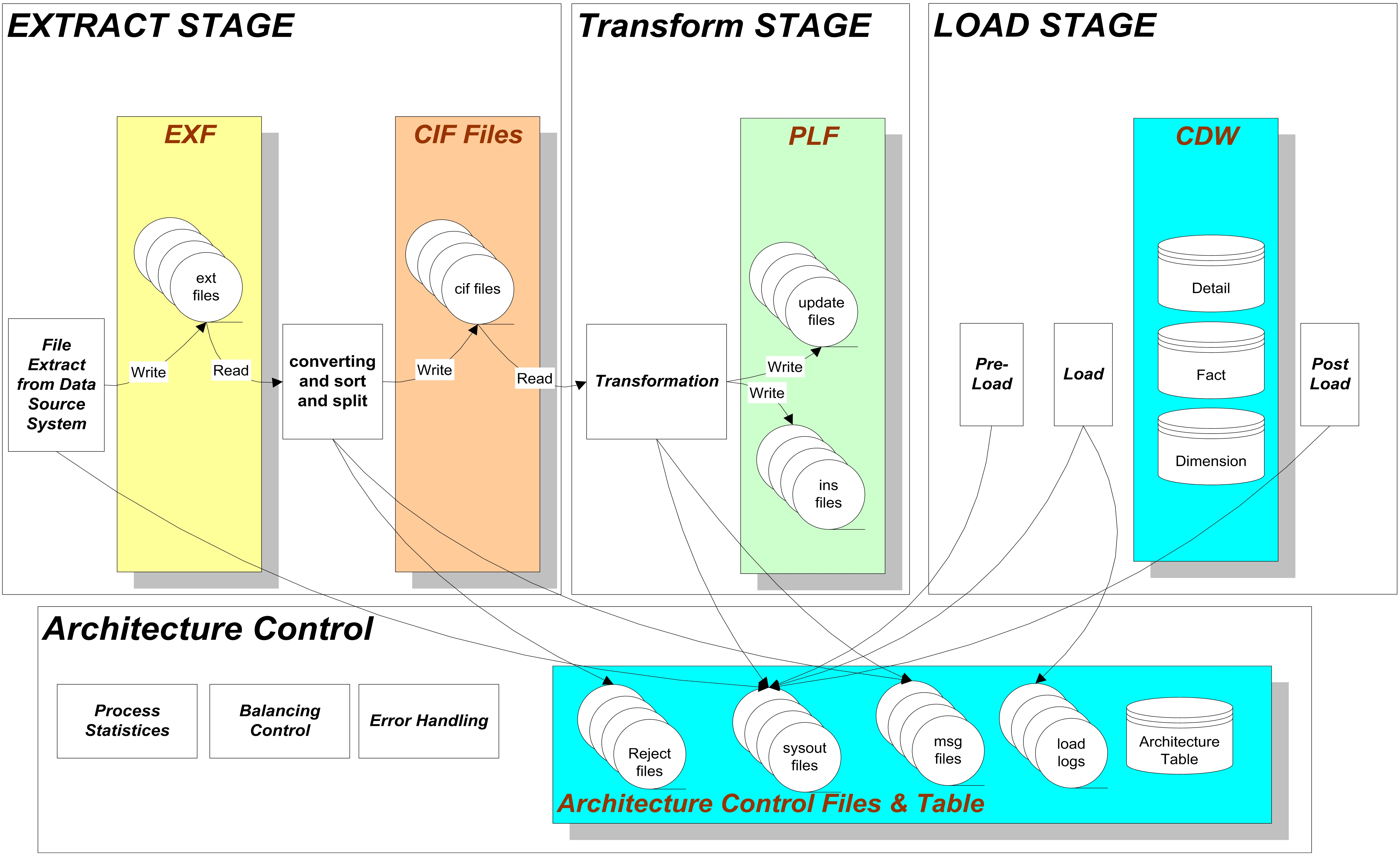
3 数据处理流程图
4 数据对照开发流程
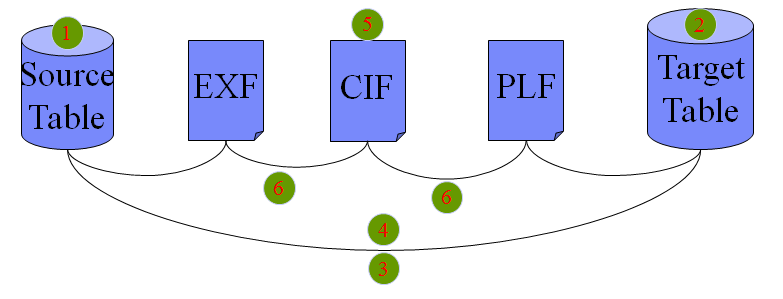
收集整理所有数据源,定义源数据结构(与EXF相同)
根据物理模型设计定义数据仓库数据(与PLF相同)结构
设计源数据表(文件)与数据仓库数据表对应关系(Table Mapping),确定Pilot的数据源范围
设计源数据字段与数据仓库字段的数据对照
设计CIF的数据结构
设计源数据字段-EXF-CIF-PLF-数据仓库数据字段的数据对照

