关于性能测试组出现的问题查询和优化
刚开始压测说总体性能慢达不到指标
我用arthas,这个在压测的时候查询问题,或者线上查找问题真的很重要,像之前去平安银行的测试组(开发岗位)面试也问了这个问题(2021年初),那时候他们也刚开始研究,还问了一些测试数据如何在网页前端大批量实时展示的解决方案,但自己真的很弱arthas真的没听过,不过实时展示的解决方案还是回答的不错的,比如用前端写个5秒定时的请求我后端拉取数据,而数据存储在elasticsearch里面,前端根据上一次返回的id往后查询,但这个有延迟的缺点,另外一个方案就是前端和后端建议类似于Netty的长连接,有数据就往这里面推送。
可用 curl -O 或者wget直接下载
curl -O https://arthas.aliyun.com/arthas-boot.jar
但下载之后启动发现还会外网下载插件(可是内外网隔离访问不了),有点坑,所以直接下载一下的东西传进内网
https://maven.aliyun.com/repository/public/com/taobao/arthas/arthas-packaging/3.5.2/arthas-packaging-3.5.2-bin.zip
文档可用看github上面的arthas文档
虽然测试的性能压测所慢,但是又找不到原因说哪里拖垮了这个微服务
用 Monitor 监控 了下所有 ServiceImpl 下面的所有微服务,发现我们有个方法特别的慢,需要160秒才有反应,设置10秒打印一次查询命令如下
monitor -c 10 org.apache.dubbo.demo.provider.* *
后肯定要仔细看下里面这个方法耗时情况,用 trace 命令去跟踪这个方法的具体耗时
trace demo.MathGame run
也可以设置响应时间超过多久的命令,一下是设置超过1秒的命令
trace demo.MathGame run '#cost > 1000'
一下是trace在线教程
也可以用 tt -t ,支持事后查看方法调用的参数,返回值
这边有个调用挡板(就是本来因为真实往第三方发送数据,但由于我们压测频繁,怕压垮第三方,所以调用内网的一个api地址,模拟返回数据),需要160秒才返回数据,把这个微服务给拖跨了。
过了两天有出现问题。。。
nginx报一下错误
on live upstreams while connecting to upstream,
upstream server temporarily disabled while reading response header from upstream
connect() failed (111: Connection refused) while connecting to upstream
nginx 由于网络突然卡顿之类,连接不上gateway(这里根本没压力)报 504 会在502, 中间件有差不多11秒不能访问微服务
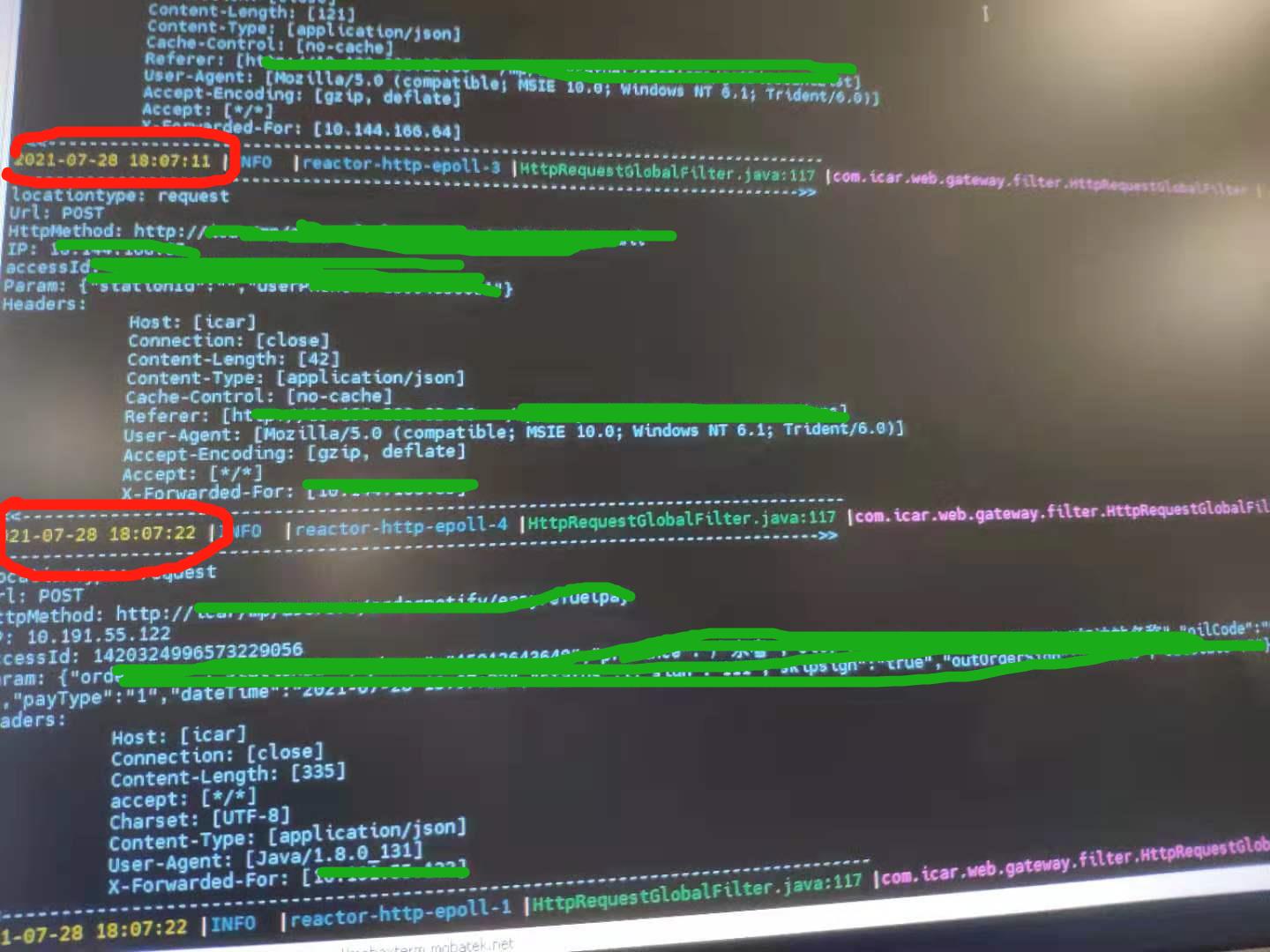
所以要配置max_fails,一般设置3-5次重试,另外可以配置keepalive ,设置长连接来减少三次握手
在 upstream 里面配置 和 keepalive 和max_fails
例子
upstream yyy.xxx.web{ server 36.10.xx.107:9001 max_fails=5 ; server 36.10.xx.108:9001 max_fails=5; keepalive 400; } server { ··· location /zzz/ { proxy_pass http://yyy.xxx.web; ··· } }
fail_timeout 默认是10s,
参考来源
线上nginx的一次“no live upstreams while connecting to upstream ”分析
压测引起的 nginx报错 502 no live upstreams while connecting to upstream解决
nginx的upstream异常
发现还是无效
跟朋友说起这事,他怀疑网络有问题,每秒用户数450分配到2台电脑上,平均225/秒,那么也就是平均访问是0.004444444 一个用户,约0.0045,设置跑50W命令就是
ping 172.1.10.1 - i 0.0045 -c 500000
得到的结果是
500000 packets transmitted ,499987 received,0% packet logs, 0% packet logs, time 2005529ms,丢包13次,约0.000026的概率,也就是10W次有2.6次。
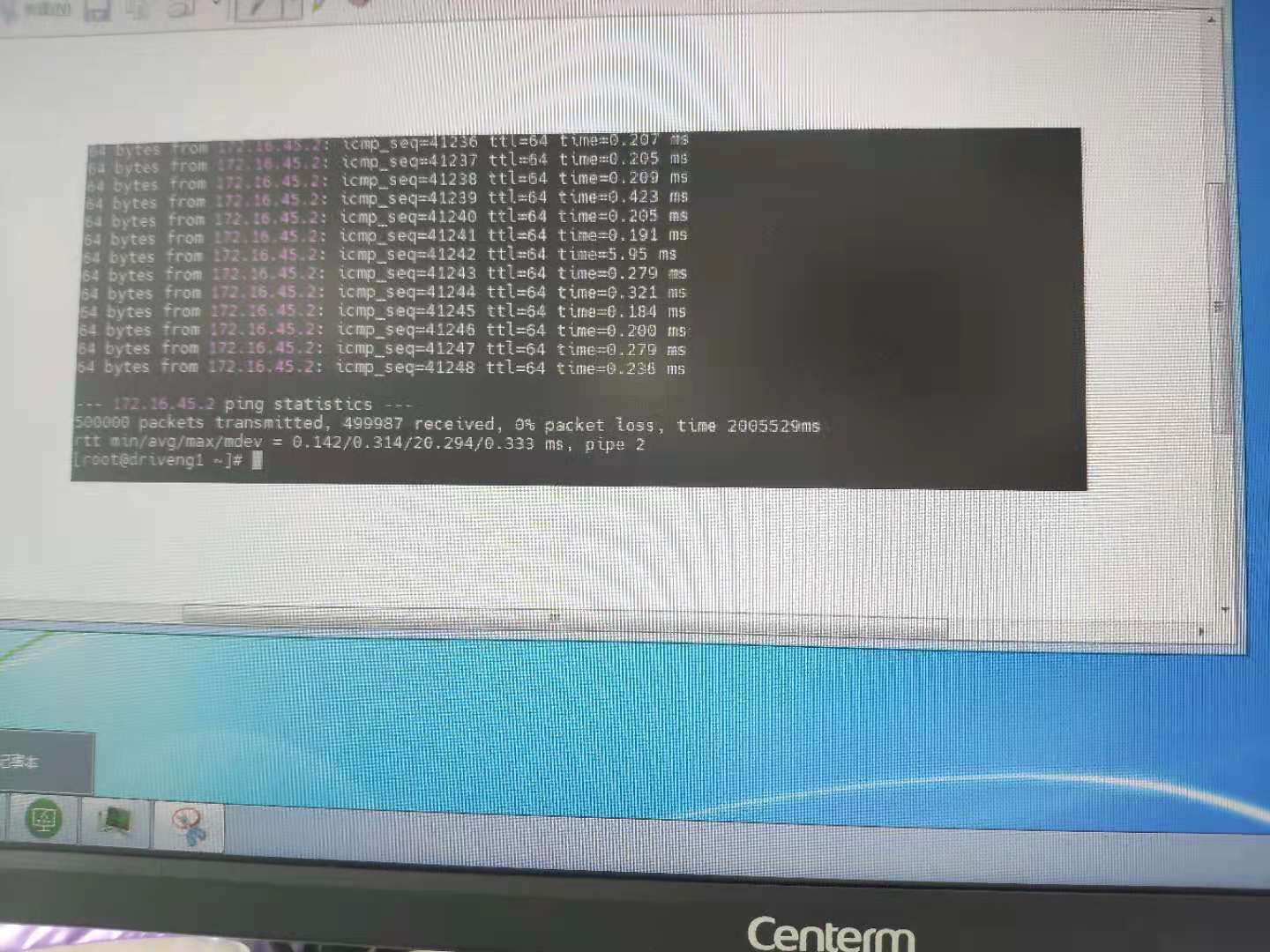
我们这边设置双nginx(前面还有F5)、双gateway,防止并发有台gateway或者nginx挂掉或者需要升级软件需要重启。
压测服务器配置如何
| IP说明 | 角色 | 规格 | ||
| nginx | 2C6G | |||
| nginx | 2C6G | |||
| Gateway、微服务 | 4C12G | |||
| Gateway、微服务 | 4C12G | |||
| DB、mogodb | 4C12G | |||
| DB、mogodb | 4C12G | |||
| Redis、kafka、nacos | 4C12G | |||
| Redis、kafka、nacos | 4C12G |
nginx 单独的机子(2C6G),gateway跟微服务混合在一起(4C12G)也是两台,-Xms 300m -Xmx 800m,采用naocs做注册中心。
发起端并发450并发用户数,分摊到每台约225
两台同时跑每台每秒225次
ping 192.168.1.3 -i 0.0045 -c 500000
ping 192.168.1.4 -i 0.0045 -c 500000
平均丢包的概率为10W有2.9次。
两台同时跑每台每秒225次,设置数据包的大小2014字节吗,设置t,共50W次
ping 192.168.1.3 -i 0.0045 -t 64 -s 1024 -c 500000
ping 192.168.1.4 -i 0.0045 -t 64 -s 1024 -c 500000
平均丢包的概率为10W有3.2次。
而性能测试组在2021.07.29晚2:00到早上,跑了数据量约1700W,时长:10小时20分钟,报错约2000条。
每秒访问数:1700W/((60*10+20)*60) ≈456.989
所以我上面设置每台平均225/秒是合理可行的。
所以报错错误率:2000/1700W ≈0.0001176 .也就是10W次有11.76次报错。
压测600用户数,在gateway那里的端口连接数大约1.25W
压测800用户数,在gateway那里的端口连接数大约1.4W,
压测900用户数,在gateway那里的端口连接数最高1.52W,之后就上不去了。在nginx的error.log中查看到no live upstreams while connecting to upstream 。可以像前面所说的配置max_fails ,怀疑吞吐已经达到瓶颈了,毕竟内存限制800m在那里,或者说是并发用户数太多(可以根据测试模拟的并发用户数去模拟),丢包更严重了。
查询连接数的查询命令如下
netstat -nat | grep -i "9001" | wc -l
另外可以在arthas 里面导出heap, 然后用Memory Analyzer tool 分析导出的*.hpof文件 ,当前当前占用内存的主要成分是哪些
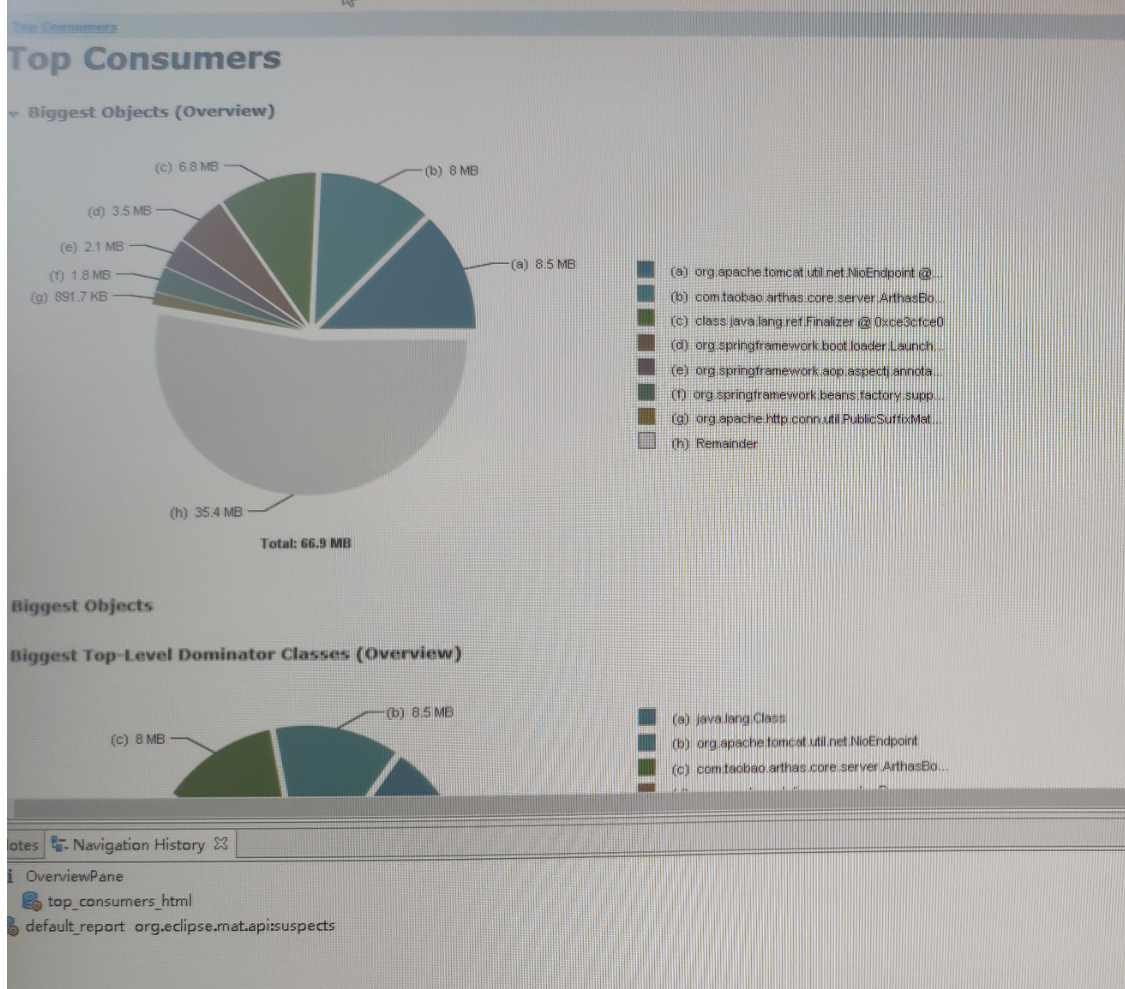
像我图片中主要有三部分组成:
1、频繁创建的Class对象
2、NioEndpoint http远程调用连接池
3、arthas的监控
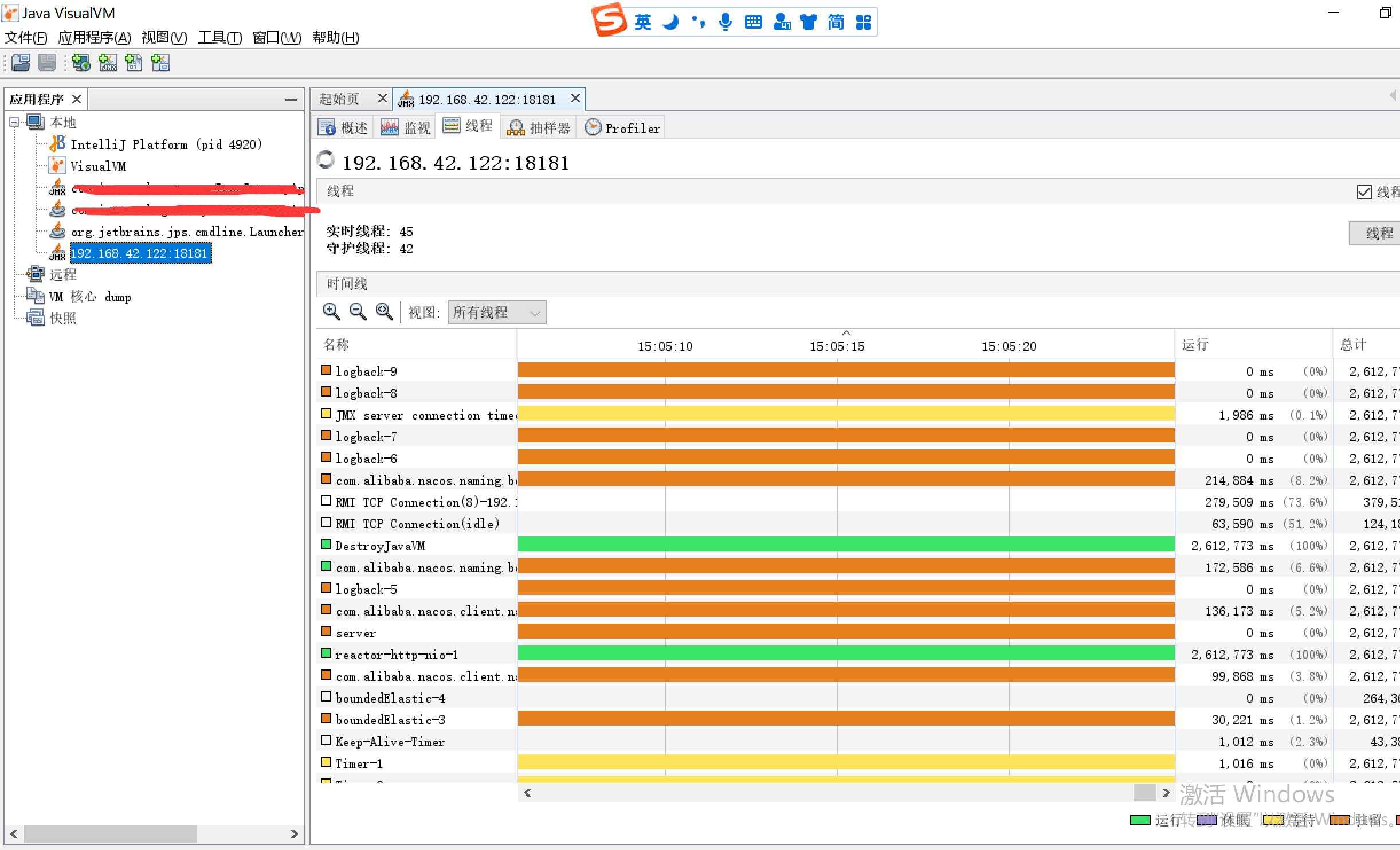
也可以用启动命令加jmxremote实时监控jar的内存线程情况,因为这个是有图标更好看得懂。 比如我启动jar服务的IP是192.168.42.122,开启让外部监听的端口是18181
-Dcom.sun.management.jmxremote=true -Djava.rmi.server.hostname=192.168.42.122 -Dcom.sun.management.jmxremote.port=18181 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false
可以用JDK里面的jvisualvm.exe 启动去观察
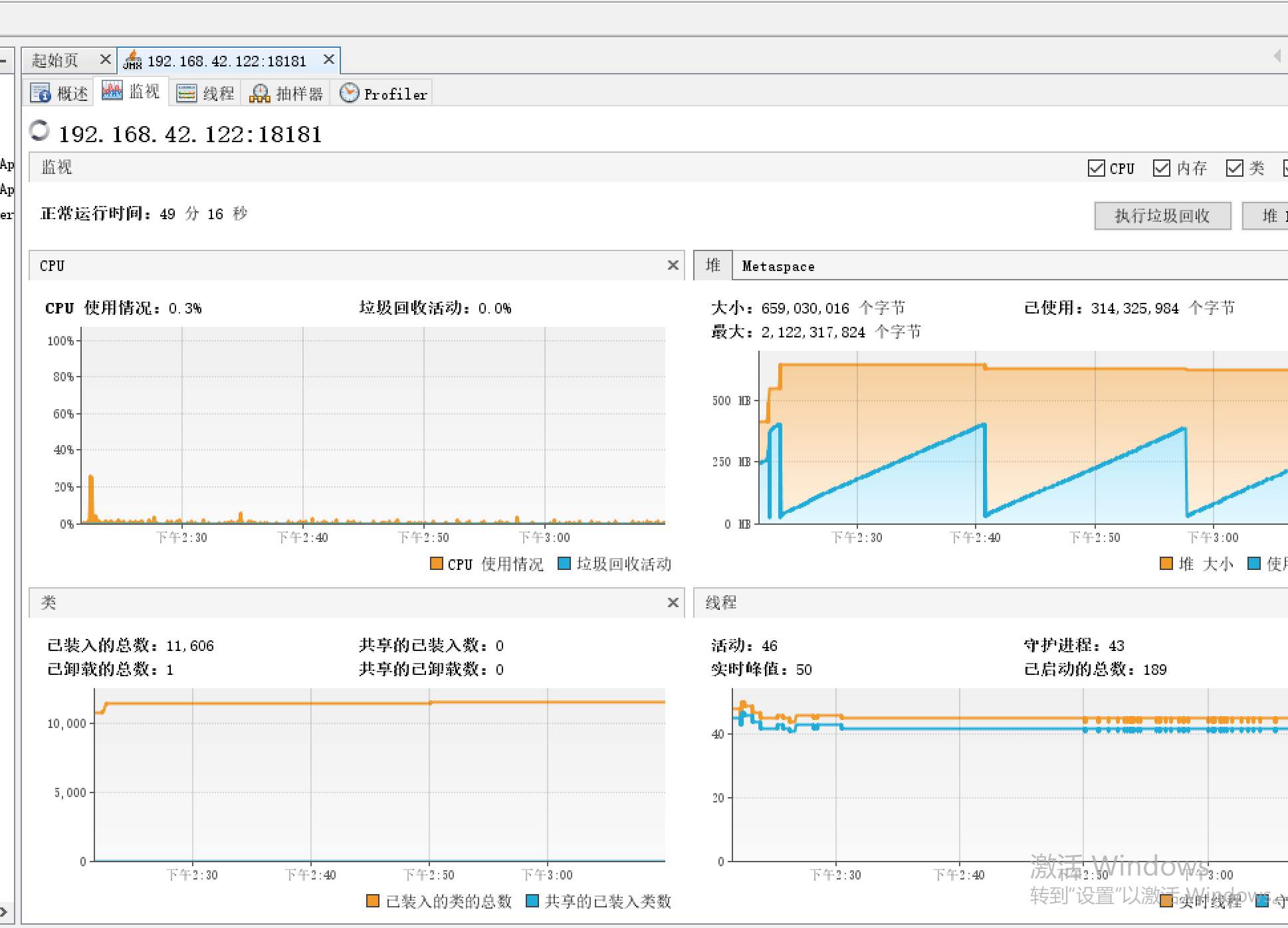
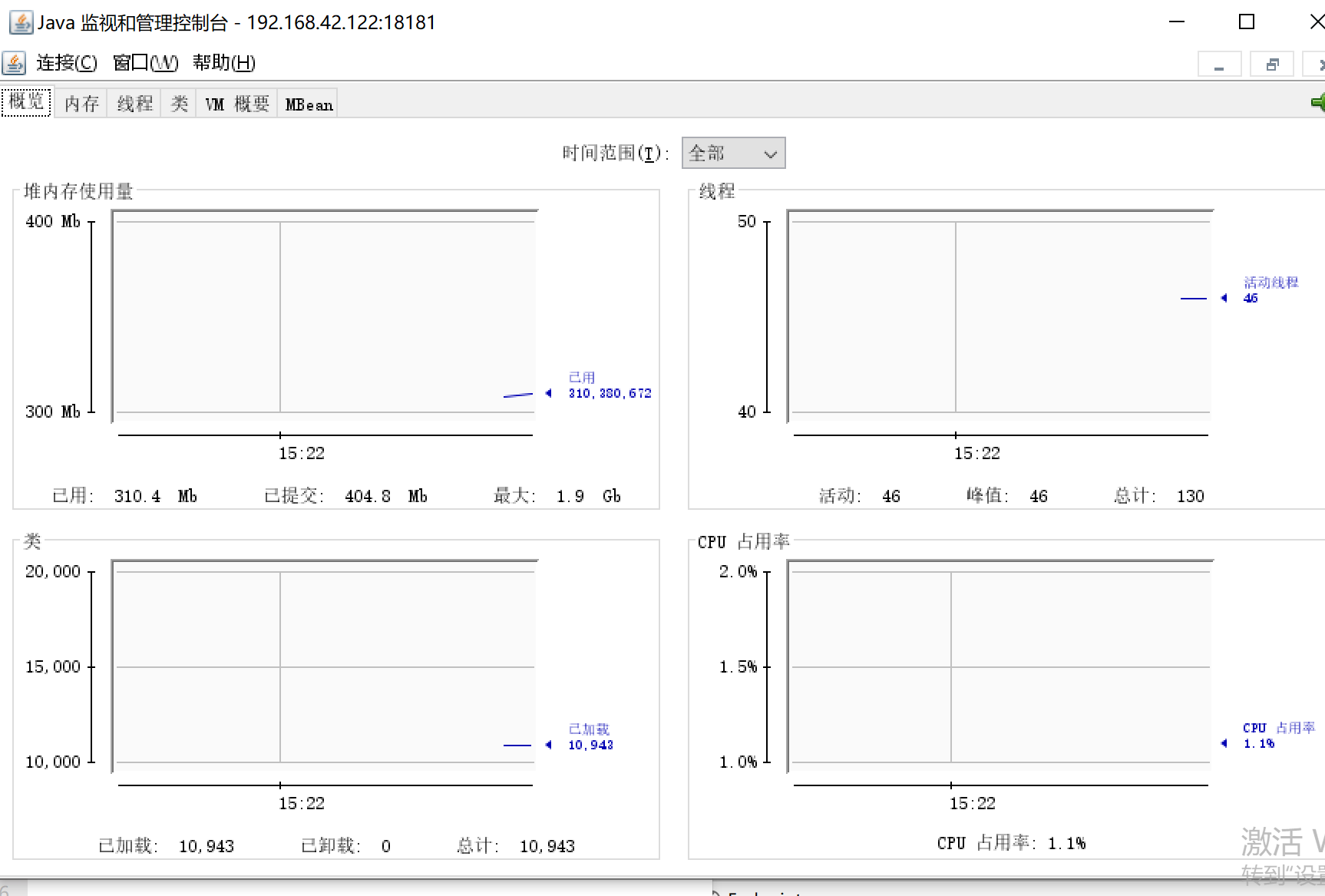
也可以用jconsole.exe
每天一个linux命令(54):ping命令
Linux ping 命令
性能优化工具(八)-MAT
JConsole远程连接配置
9 connect() failed (111: Connection refused) while connecting to upstream
nginx上游的服务端有问题,可能是没开或者端口配置错了,可以用postman去模拟请求下上游的能不能通

 浙公网安备 33010602011771号
浙公网安备 33010602011771号