


K-均值聚类算法
聚类是一种无监督的学习,它将相似的对象归到同一个簇中。
K-均值算法将数据点归为K个簇,每个簇的质心采用簇中所含数据点的均值构成。
K-均值算法的工作流程:首先随机确定K个初始点为质心,然后将数据集中的每个点非配到一个簇中,分配原则是分给距离最近的质心所在的簇。然后每个簇的质心更新为该簇所有数据点的平均值。
伪代码:
随机创建K个质心:
当任意一个点的簇分配结果发生改变时:
对数据集中的每个数据点:
对每个质心:
计算质心到数据点的距离
将数据点分配给距离最近的质心所在簇
对每一个簇,计算簇中所有数据点的均值作为质心(更新质心)
K-均值聚类支持函数:加载文件、欧式距离计算、随机初始化质心
from numpy import *
def loadDataSet(filename):
dataSet=[]
f=open(filename)
for line in f.readlines():
curLine=line.strip().split('\t')
floatLine=list(map(float,curLine))
dataSet.append(floatLine)
return dataSet
def distEclud(vecA,vecB):
return sqrt(sum(power(vecA-vecB,2)))
def randCent(dataSet,k):
n=shape(dataSet)[1]
centroids=mat(zeros((k,n)))
for i in range(n):
minI=min(dataSet[:,i])
rangeI=float(max(dataSet[:,i])-minI)
centroids[:,i]=minI+rangeI*random.rand(k,1)
return centroids
K-均值聚类算法的结束条件是数据点的簇分配结果不再改变。即达到局部最优。
def kMeans(dataSet, k, distMeans =distEclud, createCent = randCent):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))
centroids = createCent(dataSet, k)
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m):
minDist = inf
minIndex = -1
for j in range(k):
distJI = distMeans(centroids[j,:], dataSet[i,:])
if distJI < minDist:
minDist = distJI
minIndex = j
if clusterAssment[i,0] != minIndex:
clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**2 #有这种用法,更新数据点i的分类簇和误差
# print(centroids) #显示质心的迭代过程
for cent in range(k):
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A == cent)[0]] #分类为cent簇的数据点重新构成新的簇
centroids[cent,:] = mean(ptsInClust, axis = 0) #将新的簇的均值作为新的质点
return centroids, clusterAssment
簇分配结果矩阵clusterAssment包含两列:第一列记录数据所属的簇索引值,第二列存储误差。误差即为欧式距离的平方。
绘制数据点及聚类结果:
def plotPoint(dataMat,myCent,clustAssment):
dataMat=array(dataMat)
myCent=array(myCent)
import matplotlib.pyplot as plt
mark=['o','*','s','v','h']
for cent in range(shape(myCent)[0]):
typeCent=dataMat[nonzero(clustAssment[:,0].A==cent)[0]]
plt.plot(typeCent[:,0],typeCent[:,1],mark[cent])
plt.plot(myCent[:,0],myCent[:,1],'k+',markersize=20) #标记散点形状和颜色的前后顺序任意
plt.show()
聚类结果测试:
if __name__=='__main__':
dataMat = mat(loadDataSet('testSet.txt'))
myCent, clustAssing = kMeans(dataMat, 4)
plotPoint(dataMat, myCent, clustAssing)
输出:
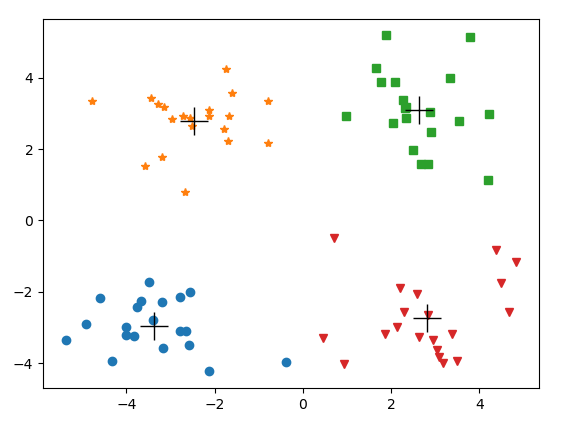
K-均值聚类的参数K 是用户定义的,然而用户无法知道恰当 的K值,并且此算法只能达到局部最优,无法达到全局最优。
一种用于度量聚类效果的指标是SSE(Sum of Squared Error,误差平方和):对应于clusterAssment第二列的总和。SSE值越小表示数据点越接近质心,聚类效果越好。聚类的目标是在保持簇数目不变的情况下提高簇的质量。
K-均值算法的改进:使用后处理来提高聚类性能。将具有最大SSE值得簇划分为两个簇。具体方法是将SSE最大的簇包含的点用数组过滤的方法过滤出来形成新的小数据集,在此小数据集上运行K-均值算法将其一分为二。
二分K-均值聚类算法:首先将所有数据点作为一个簇,然后将该簇一分为二。划分原则有两种:
1、选择对其划分可以最大程度降低SEE值的簇进行划分;
2、选择SSE最大的簇进行划分。
选择对其划分可以最大程度降低SEE值的簇进行划分:
def bitKmeans(dataSet, k, distMeas=distEclud):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))
centroid0 = mean(dataSet, axis=0).tolist()[0] #初始化为一簇
centList =[centroid0] #簇列表,初始化只有一簇
for j in range(m):
clusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2 #初始化分类簇的误差
while (len(centList) < k):
lowestSSE = inf
for i in range(len(centList)):
ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:] #属于当前簇的所有数据点组成的小数据集
centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas) #将小数据集二分
sseSplit = sum(splitClustAss[:,1]) #小数据集二分后的总误差
sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1]) #剩余数据点的总误差
print ("用于分割的数据集的误差:%s ,剩余数据集的总误差:%s "%(sseSplit,sseNotSplit))
if (sseSplit + sseNotSplit) < lowestSSE: #全部数据集的误差等于用于分割的数据集的误差加上剩余数据集的误差
bestCentToSplit = i
bestNewCents = centroidMat #更新质点
bestClustAss = splitClustAss.copy() #更新分类簇信息
lowestSSE = sseSplit + sseNotSplit #更新误差
bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList) #如果将当前小数据集进行分割的话,划分出两个簇,标签分别是原有的i和质点的总数
bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit #因为目前质点列表并没有及时更新,所以质点的长度为索引值加一
print ('最好的分割簇索引值: ',bestCentToSplit)
print ('被分割的数据点个数: ', len(bestClustAss))
centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0] #bestNewCents 2*n的矩阵 被更新的那一行质点信息更新为bestNewCents的第0行
centList.append(bestNewCents[1,:].tolist()[0]) #质心列表长度加一,新增的是bestNewCents的第1行信息
clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:]= bestClustAss #更新簇信息,待更新的是原本分类簇为i的那些数据点
return mat(centList), clusterAssment
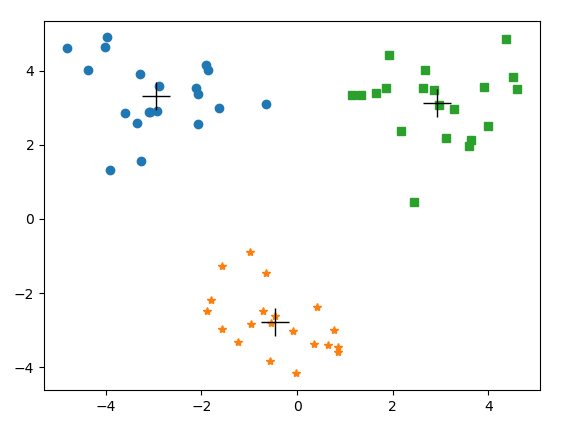
测试:
if __name__=='__main__':
dataMat = mat(loadDataSet('testSet2.txt'))
myCent, clustAssing = bitKmeans(dataMat, 3)
plotPoint(dataMat, myCent, clustAssing)
输出:
用于分割的数据集的误差:453.0334895807502 ,剩余数据集的总误差:0.0 最好的分割簇索引值: 0 被分割的数据点个数: 60 用于分割的数据集的误差:77.59224931775066 ,剩余数据集的总误差:29.15724944412535 用于分割的数据集的误差:12.753263136887313 ,剩余数据集的总误差:423.8762401366249 最好的分割簇索引值: 0 被分割的数据点个数: 40
因为只有3簇,所以划分两次就可以了。
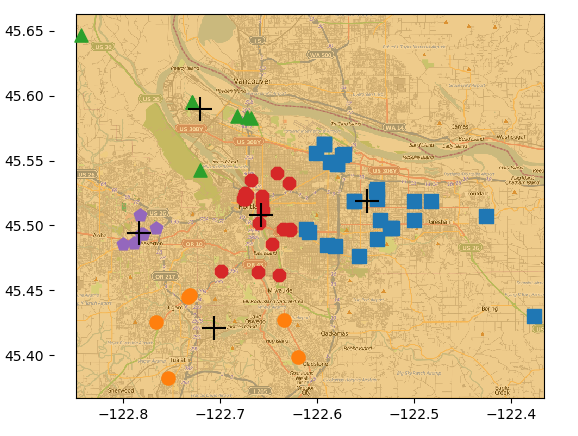
对地图上的点进行聚类:没有使用API,直接从places.txt中获取各俱乐部的经纬度信息。
def distSLC(vecA, vecB): # 返回地球表面两点之间的距离
a = sin(vecA[0, 1] * pi / 180) * sin(vecB[0, 1] * pi / 180)
b = cos(vecA[0, 1] * pi / 180) * cos(vecB[0, 1] * pi / 180) * cos(pi * (vecB[0, 0] - vecA[0, 0]) / 180)
return arccos(a + b) * 6371.0
import matplotlib
import matplotlib.pyplot as plt
def clusterClubs(numClust=5): # 将俱乐部进行聚类并画出结果
datList = []
for line in open('places.txt').readlines():
lineArr = line.split('\t')
datList.append([float(lineArr[4]), float(lineArr[3])])
datMat = mat(datList)
myCentroids, clustAssing = bitKmeans(datMat, numClust, distMeas=distSLC)
fig = plt.figure()
rect = [0.1, 0.1, 0.8, 0.8]
scatterMarkers = ['s', 'o', '^', '8', 'p','d', 'v', 'h', '>', '<']
axprops = dict(xticks=[], yticks=[])
ax0 = fig.add_axes(rect, label='ax0', **axprops)
imgP = plt.imread('Portland.png') # imread 基于图像创建矩阵
ax0.imshow(imgP)
ax1 = fig.add_axes(rect, label='ax1', frameon=False)
for i in range(numClust):
ptsInCurrCluster = datMat[nonzero(clustAssing[:, 0].A == i)[0], :]
markerStyle = scatterMarkers[i % len(scatterMarkers)] # 使用索引来选择标记形状
ax1.scatter(ptsInCurrCluster[:, 0].flatten().A[0],ptsInCurrCluster[:, 1].flatten().A[0],marker=markerStyle, s=90)
ax1.scatter(myCentroids[:, 0].flatten().A[0],myCentroids[:, 1].flatten().A[0], marker='+',color='black',s=300)
plt.show()
测试:
if __name__=='__main__':
clusterClubs(5)
输出:
用于分割的数据集的误差:3436.254083558642 ,剩余数据集的总误差:0.0 最好的分割簇索引值: 0 被分割的数据点个数: 69 用于分割的数据集的误差:689.8706952996852 ,剩余数据集的总误差:2312.355075698593 用于分割的数据集的误差:1163.3644904835776 ,剩余数据集的总误差:1123.899007860049 最好的分割簇索引值: 1 被分割的数据点个数: 52 用于分割的数据集的误差:701.3190736813707 ,剩余数据集的总误差:1163.3644904835776 用于分割的数据集的误差:451.92459095764076 ,剩余数据集的总误差:1523.8240844582879 用于分割的数据集的误差:329.2991930704607 ,剩余数据集的总误差:1887.3384217453877 最好的分割簇索引值: 0 被分割的数据点个数: 17 用于分割的数据集的误差:18.792573676179693 ,剩余数据集的总误差:1690.9230046725252 用于分割的数据集的误差:463.6732476050007 ,剩余数据集的总误差:1101.2441502796096 用于分割的数据集的误差:197.3863640526132 ,剩余数据集的总误差:1464.7584875667094 用于分割的数据集的误差:253.98662218778765 ,剩余数据集的总误差:1337.1250499760008 最好的分割簇索引值: 1 被分割的数据点个数: 34
5个簇,需要划分4次。
二分K-均值聚类算法内部在将某个小数据集一分为二时调用了K-均值算法,K-均值算法又调用了随机产生质心的randCent方法,造成了算法的不确定性,多次运行程序,发现聚类效果并不是每次都好。
重点在于如何在不引入随机的条件下对数据集初始化出两个簇。

