k-近邻算法(KNN)
最近邻算法可以说是最简单的分类算法,其思想是将被预测的项归类为和它最相近的项相同的类。我们通过简单的计算比较即将被预测的项与已有训练集中各项的距离(差距),选择其中差距最小的一项,该项的类别即为我们即将预测的类别。
下表为我们即将使用的数据集,所有的点分为红色和蓝色两种,我们随机给出一个坐标位置,然后预测其应该属于的类别。
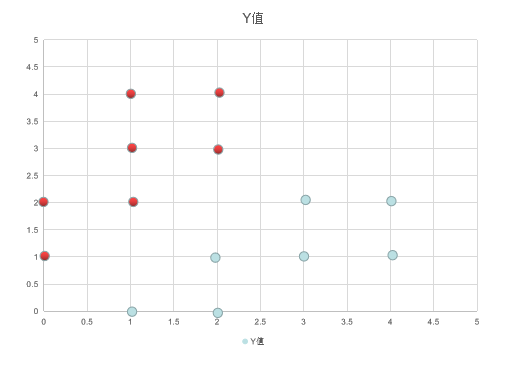
代码如下:
import math """ 此python程序用来实现最近邻算法 """ def dot_distance(dot1, dot2): # 计算两点之间的距离 return math.sqrt(pow(dot1.x - dot2.x, 2) + pow(dot1.y - dot2.y, 2)) def cal_nearest_neighbor(example, goal): """ :param example: 已有的样例集合 :param goal: 待预测的目标 :return: 距目标最近样例 """ dis, aim = dot_distance(example[0], goal), example[0] example_len = len(example) for i in range(1, example_len): dis1, aim1 = dot_distance(example[i],goal), example[i] if dis > dis1: dis, aim = dis1, aim1 return aim
最近邻算法只依据一个数据点来判断其类别,显然如果是一个噪音与即将预测的项目距离很近的话,这就有很大的可能会预测错误。然后就有了最近邻算法的改进--k-近邻算法。
k-近邻算法的思想与最近邻算法类似,不过,它是选择了k个与即将预测的项目最近的训练项目,然后让k个项目投票,以此判断其应该属于的类别。代码如下:
import math def dot_distance(dot1, dot2): # 计算两点之间的距离 return math.sqrt(pow(dot1.x - dot2.x, 2) + pow(dot1.y - dot2.y, 2)) def predict(example, goal, k): """ :param example: 训练集 :param goal: 待测点 :param k: 投票的个数,一般为奇数 :return: 最近的k个点 """ example_len = len(example) if example_len < k: k = example_len k_nearest_dots = [] for i in range(k): k_nearest_dots.append((example[i], dot_distance(example[i], goal))) k_nearest_dots.sort(key=lambda item: item[1]) for i in range(k, example_len): dis = dot_distance(example[i], goal) if dis < k_nearest_dots[k-1][1]: k_nearest_dots.pop() k_nearest_dots.append((example[i],dis)) k_nearest_dots.sort(key=lambda item: item[1]) return k_nearest_dots
k-近邻算法存在的问题是,当某一类的数据较大时,会对该类别的预测造成过大的影响。如一个小圆圈内都是一个类别,但是数据很少,然后一个同心圆中数据很多,这时我们预测一个在小圆圈内的数据,我们倾向于它应该是属于小圆圈同一个类别的,但是因为数据不足的原因,其可能会被预测为大圆圈类别。
k-近邻算法的改进是,为不同的距离确定不同的权重。即为更小的距离,确定一个较大的权重。
以上两部分测试代码如下:
import csv from NN import nearest_neighbor from NN import k_nearest_neighbor class Data: def __init__(self): self.x = 0 self.y = 0 self.type = None with open("test\\NN\\data.csv","r") as csv_file: reader = csv.reader(csv_file) rows = [row for row in reader] example = [] for item in rows: data = Data() data.x = int(item[0]) data.y = int(item[1]) data.type = item[2] example.append(data) goal = Data() goal.x = 0 goal.y = 3 result = nearest_neighbor.cal_nearest_neighbor(example,goal) print(goal.x, " ", goal.y, " :", result.type) goal.x = 3 goal.y = 0 result = nearest_neighbor.cal_nearest_neighbor(example,goal) print(goal.x, " ", goal.y, " :", result.type) k_num = 3 preset = k_nearest_neighbor.predict(example,goal,k_num) red = 0 blue = 0 for item in preset: if item[0].type == "red": red += 1 elif item[0].type == "blue": blue += 1 if red > blue: print("predict ", goal.x, " ", goal.y, " is red") else: print("predict ", goal.x, " ", goal.y, " is blue")
训练集数据,保存为data.csv
0,1,red
0,2,red
1,2,red
1,3,red
1,4,red
2,3,red
2,4,red
1,0,blue
2,0,blue
2,1,blue
3,1,blue
3,2,blue
4,1,blue
4,2,blue

 浙公网安备 33010602011771号
浙公网安备 33010602011771号