

工程优化学习笔记
矩阵行列式计算
二阶行列式计算
三阶行列式计算
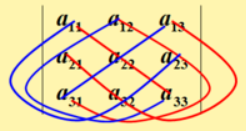
形式化表述为:(红线为加数,蓝线为减数)
矩阵的逆的计算
1. 待定系数法
令矩阵 \(A = \left( \begin{matrix} 1 & 2 \\ -1 & -3 \end{matrix}\right)\),令所要求解的逆矩阵为\(A^{-1} = \left( \begin{matrix} a & b \\ c & d \end{matrix}\right)\)。则有\(A*A^{-1} = I\),可得到方程组
从而解的\(a = 3, b = 2, c = -1, d = -1\),即
2. 初等变换求逆矩阵
同样,令矩阵 \(A = \left( \begin{matrix} 1 & 2 \\ -1 & -3 \end{matrix}\right)\),写出它的增广矩阵 \(A|E\),即矩阵\(A\)右侧放置一个同阶的单位矩阵,得到一个新矩阵。
对其进行初等变换,使原来\(A\)处的矩阵变换成为单位矩阵,则原单位矩阵处就变换成了\(A^{-1}\),变换后的矩阵为:
常用的梯度公式
Taylor展开公式
设\(f:R^n \rightarrow R\)二阶可导,在\(x^*\)的领域内
一阶Taylor展开式为
二阶Taylor展开式为
凸集
若集合\(D\)中任意两点的连线段都属于\(D\),则称\(D\)为凸集。
两点\(x^1, x^2\)连线段上任一点可表示为\(x=ax^1+(1-a)x^2,a\in[0,1]\)
设\(A,B\subseteq R^n\)是凸集,则\(A\bigcap B, A + B, A - B\)也是凸集。其中\(A + B := {a+b:a\in A, b\in B}\), \(A-B:={a-b:a\in A, b \in B}\),注意\(A \bigcup B\)不一定是凸集。
\(D\)是凸集\(\Longleftrightarrow D\)中任意有限多个点的凸组合也属于\(D\)。
凸函数
定义:设集合\(D \subseteq R^n\)为凸集,函数\(f:D \rightarrow R\),若\(\forall x^1,x^2 \in D, \alpha \in (0,1)\),均有:
则称\(f\)为凸集\(D\)上的凸函数。
假设\(f(x),g(x)\)均为凸函数,证明\(max\lbrace f(x), g(x)\rbrace\)也是凸函数。
证明:
\(f(tx_1 + (1-t)x_2) \leq tf(x_1) + (1-t)f(x_2), g(tx_1 + (1-t)x_2) \leq tg(x_1) + (1-t)g(x_2)\)
\(max \lbrace f(tx_1+(1-t)x_2), g(tx_1, (1-t)x_2) \rbrace \leq max\lbrace tf(x_1) + (1-t)f(x_2), tg(x_1) + (1-t)g(x_2) \rbrace \leq t max\lbrace f(x_1), g(x_1) \rbrace + (1-t) max\lbrace f(x_2), g(x_2) \rbrace\)
凸函数判定定理
设\(D \subseteq R^n\)为非空开凸集,函数\(f:D\rightarrow R\)在\(D\)上二次可微,则
(i) \(f\)在\(D\)上为凸函数 \(\Longleftrightarrow \forall x\in D, \nabla^2f(x)\)半正定
(ii) 若\(\forall x \in D, \nabla^2 f(x)\)正定,则\(f\)在\(D\)上为严格凸函数
对于凸规划
\(
min\ f(x)
\)
\(
s.t.\ g_i(x) \leq 0, i=1,2,L,m
\)
若 \(\overline{x} \in D, f \in C^1\),则\(\overline{x}\)为上式的最优解的充要条件为\(\forall x \in D\),有
精确一维搜索
成功失败法
步骤1:选取初始点\(x\in R\),初始步长\(h \gt 0\)及精度\(\epsilon \gt 0\),\(\varphi_1 = f(x)\)
步骤2:计算 \(\varphi_2 = f(x+h)\)
步骤3:若\(\varphi_2 < \varphi_1\),搜索成功, 转步骤4;否则,搜索失败,转步骤5。
步骤4:令\(x:= x + h\), \(\varphi_1 := \varphi_2, h := 2h\),转步骤2。
步骤5:判断\(|h| < \epsilon\)?,若\(|h| < \epsilon\)停止迭代,\(x^*=x\);否则令\(h = \frac{-h}{4}\)转步骤2。
0.618法
使用四个点来依次缩短区间,当区间长度充分小时,可将区间中点取做极小点的近似点。所选取的四个点分别为\(a,b,x_1,x_2\),其中,\(a,b\)分别为区间的下界和上界。\(x_1,x_2\)的计算符合0.618准则,如下:
二分法
因为我们假定函数在所给区间为凸函数,因此区间范围内必存在一点使得其导数为0,该点即为极小点。所以可以每次计算区间中点的导数值,以此来缩小区间,当区间足够小时,使区间的中点为局部极小点。
步骤1:计算 \(x_0 = \frac{a+b}{2}\)
步骤2:若\(f^{'}(x_0) \lt 0\),令\(a = x_0\),转步骤3;
若\(f^{'}(x_0) \gt 0\),令\(b = x_0\),转步骤3;
若\(f^{'}(x_0) = 0\),停止,\(x^* = x_0\);
步骤3:若\(|b-a| \lt \epsilon\),则\(x^* = \frac{a+b}{2}\),停止,否则,转步骤1.
牛顿法
步骤1:给定初始点\(x_1,\epsilon \gt 0\),令\(k=1\)
步骤2:计算\(x_{k+1} = x_{k} - \frac{f^{'}(x_k)}{f^{''}(x_k)}\)
步骤3:若\(|f^{'}(x_{k+1})| \lt \epsilon\),停止,\(x^* \approx x_{k+1}\)
拟Newton法
需要构造\(H_k\),\(H_k\)需要满足的几个原则有:
- 拟牛顿性质
$\Delta x_k = H_{k+1}\nabla g_k \(,其中\)H_{k+1}$不唯一,该式表现了拟牛顿性质,称为条件或者方程。
- 二次收敛性
\(f(x)=\frac{1}{2}x^TAx+b^Tx+c, A对称正定\)
把算法用于\(n\)元正定二次函数时,至多\(n\)次达到极小点。
- 稳定性
在算法的迭代点\(x^k\)处可选择步长,使得下个迭代点\(x^{k+1}处的函数值下降,则称此算法是稳定的。\)
插值法
使用成功失败法寻找“高,低,高”三点,分别作为区间和区间内的一点,然后通过这三个点构造二(三、四)次方程,得到该方法的极值点作为第四个点,然后通过这四个点的函数值来进一步缩短区间。
步骤1:(用成功失败法) 寻找“高-低-高”三点:即三点满足
步骤2:确定二次插值多项式\(P(x) =a_0+a_1 x + a_2 x^2\),求出\(P\)的极小点\(\overline{x}\)(因\(P(x_1) \gt P(x_2) \lt P(x_3)\)),故\(a_2 \gt 0\),\(\overline{x} \in [x_1, x_3]\)
步骤3:若\(|x_2 - \overline{x}| \lt \epsilon\),则迭代结束,取\(x^* = \overline{x}\),否则在点\(x_1,x_2,x_3,\overline{x}\)中,选取使\(f\)最小的点作为新的\(x_2\),并使新的\(x_1,x_3\)各是新的\(x_2\)近旁的左右两点,转步骤2,继续迭代,直到满足终止条件。
最速下降法
步骤1:选定初始点\(x,\epsilon \gt 0\),并令\(k=1\)。
步骤2:若\(||\nabla f(x^k)|| \leq \epsilon\),得到近似驻点\(x^k\),否则转步骤3
步骤3:令\(d^k = - \nabla f(x^k)\)
步骤4:由精确一维搜索确定最佳步长\(\lambda_k=arg\ min\ f(x^k+\lambda d^k)\)。令\(x^{k+1}=x^k+\lambda _kd^k, k:=k+1\),转步骤2
Newton法
求函数\(f\)的极小点,给定误差极限\(\epsilon\).
步骤1:选定初始点\(x^1\),计算\(f_1 = f(x^1),k=1\)
步骤2:如果\(||\nabla f(x^k)|| \leq \epsilon\),停止,得到近似驻点\(x^k\),否则转步骤3
步骤3:计算搜索方向\(d^k = -(\nabla ^2f(x^k))^{-1}\nabla f(x^k)\)
步骤4:令\(x^{k+1} = x^k+d^k, k=k+1\),转步骤2
阻尼Newton法
将Newton法中的迭代公式进行替换,加入精确一维搜索\(min f(x^k + \lambda d^k)\),求得最佳步长\(\lambda_k\),得到下一个迭代点\(x^{k+1} = x^k+\lambda_k d^k\)
利用阻尼Newton法求n元正定二次函数的极小点,从任意初始点出发,一步迭代即可达到极小点。
FR共轭梯度法
步骤1:选定初始点\(x^1\)
步骤2:如果\(||g_1|| \leq \epsilon\),停止,得到近似驻点\(x^1\),否则转步骤3
步骤3:取\(p^1=-g_1,k=1\)
步骤4:精确一维搜索找最佳步长\(\lambda_k\),令\(x^{k+1} = x^k + \lambda_kp^k\)
步骤5:如果\(||g_{k+1}|| \leq \epsilon\),停止,得到近似驻点\(x^{k+1}\),否则转步骤6
步骤6:如果\(k=n\),令\(x^1=x^{k+1},p^1=-g_{k+1},k=1\),转步骤4;否则转步骤7
步骤7:计算\(a_k=\frac{||g_{k+1}||^2}{||g_k||^2},p^{k+1}=-g_{k+1}+a_kp^k,k=k+1\),转步骤4
变尺度法--DFP算法
步骤1:选定初始点\(x^1\),初始矩阵\(H_1=I_n\),\(\epsilon \gt 0\)
步骤2:如果\(||g_1|| \leq \epsilon\),停止,得到近似驻点\(x^1\),否则转步骤3
步骤3:取\(p ^1=-H_1g_1,k=1\)
步骤4:精确一维搜索找最佳步长\(\lambda _k\),令\(x^{k+1} = x^k + \lambda_k p^k\)
步骤5:如果\(||g_{k+1}|| \leq \epsilon\),停止,得到近似驻点\(x^{k+1}\),否则转步骤6
步骤6:如果\(k=n\),令\(x^1=x^{k+1},p^1=-g_{k+1},k=1\),转步骤4,否则转步骤7
步骤7:令\(\Delta x_k = x^{k+1} - x^k, \Delta g_k = g_{k+1} - g_k, r_k=H_k \Delta g_k\),计算:
和\(p^{k+1}=-H_{k+1}g_{k+1}\),令\(k = k+1\),转步骤4
两阶段法首先需要向原变量等式中引入人工变量,且人工变量均大于等于0,然后使用单纯形方法求解使得人工变量之和最小的条件,之后将修改单纯形表,将人工变量删去,继续使用单纯形方法得到目标函数的最优解。值得注意的是,在选择进基变量时,选择检验数,即\(\sigma_j\)大于0,且最大的一个。选择离基变量时,选择\(\theta\)大于0且最小的一个。当值相等时,离基变量选择下标最大的,进基变量选择下表最小的。
大\(M\)法
在约束中引入人工变量\(x_a\),同时修改目标函数,在原目标中加上惩罚项\(Me^Tx_a\),其中\(M\)为充分大的正数。
对偶规划

对偶单纯形法
对偶单纯形法的基本思想: 从(P)的一个对偶可行的基本解出发,在保证对偶可行的条件下,逐步使原问题基本解的不可
行性消失(即x非负),直到获得原问题的一个基本可行解为止,而这个基本可行解就是原问题的最优解.
对偶单纯形方法与原单纯形方法主要的区别就是,先计算\(\overline{b}\),找出其中小于0,且最小的一个作为离基变量,然后用\(\sigma_j\)除以对应的行,得到参考值,选择参考值中大于0,且最小的一个作为进基变量。目标是使\(\overline{b}\)值均大于等于0.
K-T点计算,一阶最优性条件
满足以上两个条件中的任意一个即为K-T点。若要求K-T点,用下式,若要验证,用上式。其中,\(g_i\)为大于约束,\(h_i\)为等式约束。
外点罚函数法
构造罚函数:\(min F(x,M_k)=f(x)+M_k p(x)\)。
其中\(M_k\)逐渐趋于无穷
优化函数为
则\(p(x) = \sum_{i=1}^{m}(min\lbrace g_i(x),0 \rbrace )^2+\sum_{j=1}^l h_j^2(x)\),可用\(x\)来表示\(M\),然后让\(M\)趋于无穷,以此求得\(x\)。
外点罚函数法性质
- \(F(x^{k+1}, M_{k+1}) \geq F(x^k, M_k)\)
- \(p(x^{k+1}) \leq p(x^k)\)
- \(f(x^{k+1}) \geq f(x^k)\)
外点罚函数法不等式证明
- \(F(x^{k+1}, M_{k+1}) \geq F(x^k, M_k)\)
对于由外点法产生的点列\(\lbrace x^k \rbrace\),\(k \geq 1\),总有:
\( F(x^{k+1}, M_{k+1}) = f(x^{k+1}) + M_{k+1}p(x^{k+1}) \geq f(x^{k+1}) + M_kp(x^{k+1}) \)
=\( F(x^{k+1}, M_k) \)
\( \geq F(x^k,M_k) \)
- \(p(x^{k+1}) \leq p(x^k)\)
\( f(x^{k+1}) + M_kp(x^{k+1}) = F(x^{k+1}, M_k) \geq F(x^k, M_k) = f(x^k)+M_kp(x^k) \)
\( f(x^{k+1}) - f(x^k) \geq M_k[p(x^k)-p(x^{k+1})] \)
\( f(x^k)+M_{k+1}p(x^k)=F(x^k, M_{k+1})\geq F(x^{k+1}, M_{k+1})=f(x^{k+1})+M_{k+1}p(x^{k+1}) \)
\( f(x^k)-f(x^{k+1}) \geq M_{k+1}[p(x^{k+1})-p(x^k)] \)
\( 0 \geq (M_{k+1}-M_k)[p(x^{k+1})-p(x^k)] 已知M_{k+1}\geq M_k \)
\( p(x^{k+1}) \leq p(x^k) \)
- \(f(x^{k+1}) \geq f(x^k)\)
\(f(x^{k+1}) + M_kp(x^{k+1})=F(x^{k+1},M_k)\geq F(x^k,M_k)=f(x^k)+M_kp(x^k)\)
\(已知p(x^{k+1})\leq p(x^k)\)
\(f(x^{k+1})\geq f(x^k)\)
内点罚函数法
构造罚函数:\(F(x,r)=f(x)+rB(x)\),只可用于不等书约束的条件,要求大于等于0
内点罚函数法性质
- \(F(x^{k+1}, r_{k+1}) \leq F(x^k, r_k)\)
- \(B(x^{k+1}) \geq B(x^k)\)
- \(f(x^{k+1}) \leq f(x^k)\)
约坦狄克可行方向法
步骤1:给定初始可行点\(x^0\),令\(k=0\)
步骤2:在点\(x^k\)处将\(A\)和\(b\)分解成
使得\(A_1x^k=b, A_2x^k\gt b_2\),计算\(\nabla f(x^k)\)。
步骤3:求解线性规划\(
\begin{matrix}
min(\nabla f(x^k))^Td \\
s.t.\ A_1d \geq 0 \\
Cd = 0\\
|d_j| \leq 1, \forall j
\end{matrix}
\)得到最优解\(d^k\)
步骤4:若\((\nabla f(x^k))^Td^k = 0\),则算法结束,\(x^k\)是K-T点,否则转步骤5
步骤5:利用(*)式计算\(\lambda_{max}\),求解一维搜索问题
得到极小点\(\lambda _k\),令\(x^{k+1}=x^k+\lambda _kd^k,k=k+1\),转步骤2.
\(
\lambda _{max}=\left \lbrace
\begin{matrix}
min\lbrace \frac{\overline{b_i}}{\overline{d_i}}| \overline{d_i} \lt 0\rbrace\ if \exist\overline{d_i} \lt 0 \\
+\infty\ \ if\ \overline{d} \geq 0
\end{matrix}
\right.
\) (*)
\(
\overline d = A_2d^k ,\ \overline b = b_2 - A_2x^k
\)
注:单纯形法,\(\sigma_j\)选择大于0且值最大的进基,\(\theta\)选择大于0且值s最小的进基。
对偶单纯形,先找离基再找进基。\(\overline{b}\)选择小于0且最小的一个离基,\(\sigma\)除以对应的行,所得大于0且最小的进基。

