小样本学习介绍
基本概念
在大多数时候,你是没有足够的图像来训练深度神经网络的,这时你需要从小样本数据快速学习你的模型。
Few-shot Learning 是 Meta Learning 在监督学习领域的应用。Meta Learning,又称为 learning to learn,在 meta training 阶段将数据集分解为不同的 meta task,去学习类别变化的情况下模型的泛化能力,在 meta testing 阶段,面对全新的类别,不需要变动已有的模型,就可以完成分类。
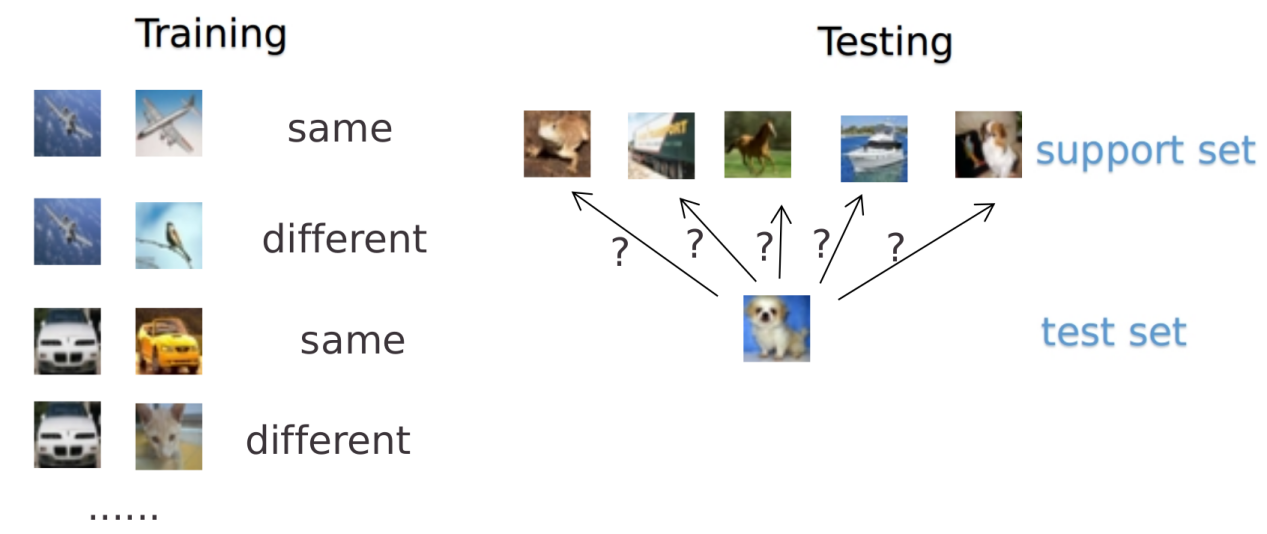
形式化来说,few-shot 的训练集中包含了很多的类别,每个类别中有多个样本。在训练阶段,会在训练集中随机抽取 C 个类别,每个类别 K 个样本(总共CK 个数据),构建一个 meta-task,作为模型的支撑集(support set)输入;再从这 C 个类中剩余的数据中抽取一批(batch)样本作为模型的预测对象(batch set)。即要求模型从 C*K 个数据中学会如何区分这 C 个类别,这样的任务被称为 C-way K-shot 问题。如果K值很小(通常K<10),我们称这种分类任务为极少样本分类任务(当K=1时,变成单样本分类任务)。
1998年,Thrun和Pratt指出,对于一个指定的任务,一个算法“如果随着经验的增长,在该任务上的表现得到改进”,则认为该算法能够学习。
与此同时,对于一族待解决的多个任务,一个算法“如果随着经验和任务数量的增长,在每个任务上的表现得到改进”,则认为该算法能够学习如何学习,我们将后者称为元学习算法。它不学习如何解决一个特定的问题,但可以成功学习如何解决多个任务。每当它学会解决一个新的任务,它就越有能力解决其他新的任务:它学会如何学习。
meta learning是机器学习的一个子领域,它自动学习一些应用于机器学习实验的元数据,主要目的是使用这些元数据来自动学习如何在解决不同类型的学习问题时变得灵活,从而提高现有的学习算法。灵活性是非常重要的,因为每个学习算法都是基于一组有关数据的假设,即它是归纳偏(bias)的。这意味着如果bias与学习问题中的数据相匹配,那么学习就会很好。学习算法在一个学习问题上表现得非常好,但在下一个学习问题上表现得非常糟糕。这对机器学习或数据挖掘技术的使用造成了很大的限制,因为学习问题与不同学习算法的有效性之间的关系尚不清楚。
通过使用不同类型的元数据,如学习问题的属性,算法属性(如性能测量)或从之前数据推导出的模式,可以选择、更改或组合不同的学习算法,以有效地解决给定的学习问题。
元学习一般有两级,第一级是快速地获得每个任务中的知识,第二级是较慢地提取所有任务中学到的信息。下面从不同角度解释了元学习的方法:
- 通过知识诱导来表达每种学习方法如何在不同的学习问题上执行,从而发现元知识。元数据是由学习问题中的数据特征(一般的,统计的,信息论的......)以及学习算法的特征(类型,参数设置,性能测量...)形成的。然后,另一个学习算法学习数据特征如何与算法特征相关。给定一个新的学习问题,测量数据特征,并且可以预测不同学习算法的性能。因此,至少在诱导关系成立的情况下,可以选择最适合新问题的算法。
- stacking. 通过组合一些(不同的)学习算法,即堆叠泛化。元数据是由这些不同算法的预测而形成的。然后,另一个学习算法从这个元数据中学习,以预测哪些算法的组合会给出好的结果。在给定新的学习问题的情况下,所选择的一组算法的预测被组合(例如通过加权投票)以提供最终的预测。由于每种算法都被认为是在一个问题子集上工作,所以希望这种组合能够更加灵活,并且能够做出好的预测。
- boosting. 多次使用相同的算法,训练数据中的示例在每次运行中获得不同的权重。这产生了不同的预测,每个预测都集中于正确预测数据的一个子集,并且结合这些预测导致更好(但更昂贵)的结果。
- 动态偏选择(Dynamic bias selection)通过改变学习算法的感应偏来匹配给定的问题。这通过改变学习算法的关键方面来完成,例如假设表示,启发式公式或参数。
- learning to learn,研究如何随着时间的推移改进学习过程。元数据由关于以前的学习事件的知识组成,并被用于高效地开发新任务的有效假设。其目标是使用从一个领域获得的知识来帮助其他领域的学习。
如果我们希望解决一项任务T,会在一批训练任务{Ti}上训练元学习算法。我们希望元学习模型“随着经验和任务数量的增长”得到不断地改进,算法在被训练解决这些任务的过程中得到的经验将被用于解决最终的任务T。注意:{Ti}任务中不需要包含T任务的学习内容。
在训练过程中,每次训练(episode)都会采样得到不同 meta-task,所以总体来看,训练包含了不同的类别组合,这种机制使得模型学会不同 meta-task 中的共性部分,比如如何提取重要特征及比较样本相似等,忘掉 meta-task 中 task相关部分。通过这种学习机制学到的模型,在面对新的未见过的 meta-task 时,也能较好地进行分类。
标准的学习分类算法学习映射图像→标签,元学习算法通常学习映射支持集→c(.),其中c是映射查询→标签。
元学习算法
元学习模型可以用于解决一个少样本分类的任务,解决方案有多种。
度量学习
度量学习的基本思想是学习数据点(如图像)之间的距离函数。事实证明,它对于解决少样本分类任务非常有用:度量学习算法不必在支持集(少量的带标签图像)上进行微调,而是通过将查询图像与带标签图像进行比较来对其进行分类。
将查询图像与支持集的每个图像进行比较,它的标签取决于与其最接近的图像。当然,你不能逐个像素地比较图像,你要做的是在相关的特征空间中比较图像。
为了清楚起见,让我们详细说明度量学习算法是如何解决少样本分类任务的(以下定义为带标签样本的支持集,以及我们要分类的查询图像集):
- 我们从支持集和查询集的所有图像中提取特征(通常使用卷积神经网络)。现在,我们在少样本分类任务中必须考虑的每个图像都由一个一维向量表示。
- 每个查询图像根据其与支持集图像的距离进行分类。对于距离函数和分类策略,可以有许多可能的设计选择。例如,欧氏距离和k-最近邻分类。
- 在元训练期间,在每一场景(episode)结束时,对由查询集的分类错误产生的损失值(通常是交叉熵损失)进行反向传播,从而更新CNN的参数。
现有很多方法可以用于提取特征或者比较特征。以下将介绍一些现有的解决方案。
孪生网络(Siamese Neural Networks)这个方法对输入的结构进行限制并自动发现可以从新样本上泛化的特征。通过一个有监督的基于孪生网络的度量学习来训练,然后重用那个网络所提取的特征进行one/few-shot学习。它是一个双路的神经网络,训练时,通过组合不同类的样本成对,同时输入网络进行训练,在最上层通过一个距离的交叉熵进行loss的计算,如下图。
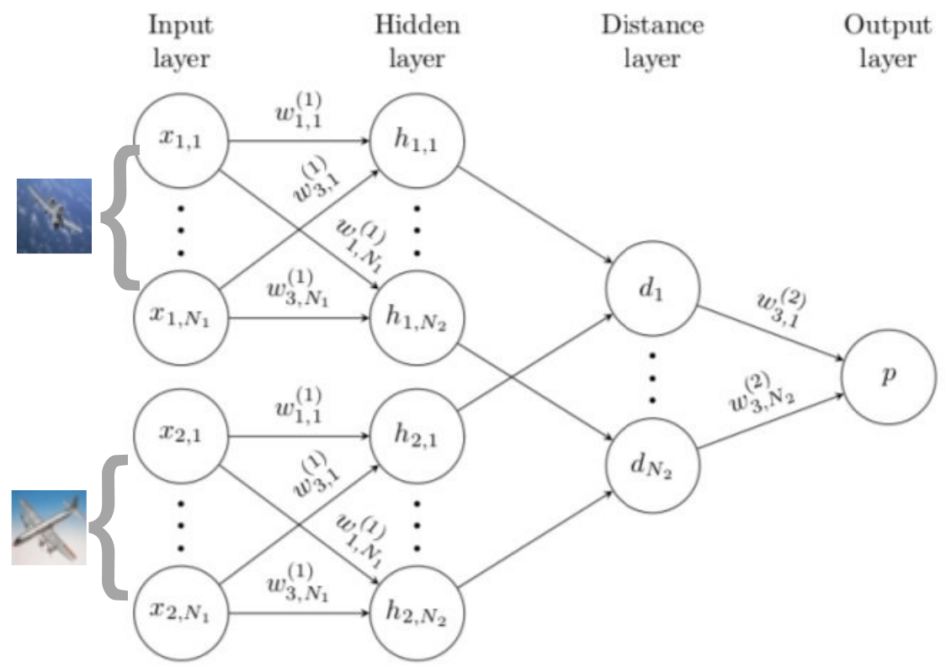
在预测时,以5way-5shot为例子,从5个类中随机抽取5个样本,把这个mini-batch=25的数据输入网络,最后获得25个值,取分数最高对应的类别作为预测结果,如图。
匹配网络算法 对于支持集图像和查询图像,特征提取器是不同的。使用余弦相似性,将查询的嵌入特征与支持集中的每个图像进行比较。然后用softmax进行分类。
匹配网络是第一个使用元学习的度量学习算法。在这个方法中,我们不会以同样的方式提取支持图像和查询图像的特征。来自Google DeepMind的 Oriol Vinyals 和他的团队有一个想法,即在特征提取过程中使用LSTM网络使所有图像交互。他们称之为完全上下文嵌入,因为你允许网络为了找到最合适的嵌入,这不仅需要知道要嵌入的图像,还需要知道支持集中的所有其他图像。这使得他们的模型比所有的图像都通过一个简单的CNN时表现得更好的同时,也需要更多的时间和更大的GPU。
该文章也是在不改变网络模型的前提下能对未知类别生成标签,其主要创新体现在建模过程和训练过程上。对于建模过程的创新,文章提出了基于memory和attantion的matching nets,使得可以快速学习。对于训练过程的创新,文章基于传统机器学习的一个原则,即训练和测试是要在同样条件下进行的,提出在训练的时候不断地让网络只看每一类的少量样本,这将和测试的过程是一致的。
在最近的工作中,我们不会将查询图像与支持集中的每个图像进行比较。多伦多大学的研究人员提出了原型网络。在他们的度量学习算法中,学习了一个度量空间,从图像中提取特征后,为每个类计算一个原型。为此,他们使用类中每个图像嵌入的平均值。一旦计算出原型,就可以计算查询图像到原型的欧式距离,从而对查询图像进行分类。并且在原型网络中,我们将查询标记为与其最接近的原型的标签。
模型无关的元学习(MAML)是目前最优雅和最有潜力的元学习算法之一。它基本上是最纯粹的元学习形式,通过神经网络进行两级反向传播。
该算法的核心思想是训练一个神经网络,使其能够仅用少量样本就能快速适应新的分类任务。下图将展示MAML如何在元训练的一个场景(即,从数据集D中采样得到的少样本分类任务Tᵢ)中工作的。假设你有一个用𝚯参数化的神经网络M:
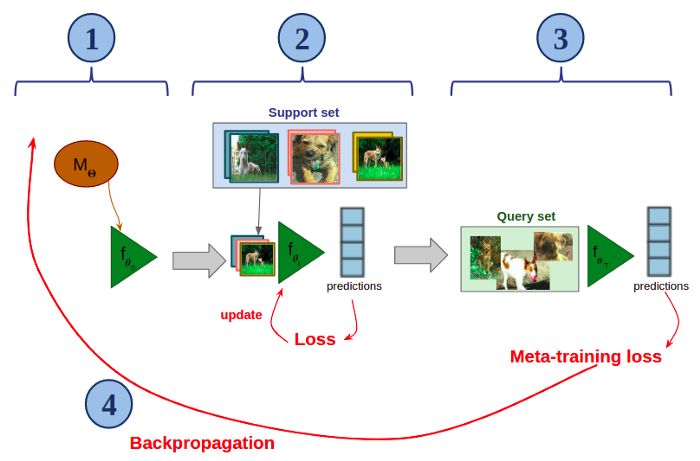
用𝚯参数化的MAML模型的元训练步骤:
- 创建M的副本(此处命名为f),并用𝚯对其进行初始化(在图中,𝜽₀=𝚯)。
- 快速微调支持集上的f(只有少量梯度下降)。
- 在查询集上应用微调过的f。
- 在整个过程中,对分类错误造成的损失进行反向传播,并更新𝚯。
然后,在下一场景中,我们创建一个更新后模型M的副本,我们在新的少样本分类任务上运行该过程,依此类推。
在元训练期间,MAML学习初始化参数,这些参数允许模型快速有效地适应新的少样本任务,其中这个任务有着新的、未知的类别。
MAML目前在流行的少样本图像分类基准测试中的效果不如度量学习算法。由于训练分为两个层次,模型的训练难度很大,因此超参数搜索更为复杂。此外,元的反向传播意味着需要计算梯度的梯度,因此你必须使用近似值来在标准GPU上进行训练。
但是,模型无关的元学习之所以如此令人兴奋,是因为它的模型是不可知的。这意味着它几乎可以应用于任何神经网络,适用于任何任务。掌握MAML意味着只需少量样本就能够训练任何神经网络以快速适应新的任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号