Deep learning with Python 学习笔记(9)
神经网络模型的优化
使用 Keras 回调函数
使用 model.fit()或 model.fit_generator() 在一个大型数据集上启动数十轮的训练,有点类似于扔一架纸飞机,一开始给它一点推力,之后你便再也无法控制其飞行轨迹或着陆点。如果想要避免不好的结果(并避免浪费纸飞机),更聪明的做法是不用纸飞机,而是用一架无人机,它可以感知其环境,将数据发回给操纵者,并且能够基于当前状态自主航行。下面要介绍的技术,可以让model.fit() 的调用从纸飞机变为智能的自主无人机,可以自我反省并动态地采取行动
训练过程中将回调函数作用于模型
训练模型时,很多事情一开始都无法预测。尤其是你不知道需要多少轮才能得到最佳验证损失。前面所有例子都采用这样一种策略:训练足够多的轮次,这时模型已经开始过拟合,根据这第一次运行来确定训练所需要的正确轮数,然后使用这个最佳轮数从头开始再启动一次新的训练。当然,这种方法很浪费
处理这个问题的更好方法是,当观测到验证损失不再改善时就停止训练。这可以使用 Keras 回调函数来实现。回调函数(callback)是在调用 fit 时传入模型的一个对象(即实现特定方法的类实例),它在训练过程中的不同时间点都会被模型调用。它可以访问关于模型状态与性能的所有可用数据,还可以采取行动:中断训练、保存模型、加载一组不同的权重或改变模型的状态
回调函数的一些用法示例如下所示
- 模型检查点(model checkpointing):在训练过程中的不同时间点保存模型的当前权重
- 提前终止(early stopping):如果验证损失不再改善,则中断训练(当然,同时保存在训练过程中得到的最佳模型)
- 在训练过程中动态调节某些参数值:比如优化器的学习率
- 在训练过程中记录训练指标和验证指标,或将模型学到的表示可视化(这些表示也在不断更新):Keras 进度条就是一个回调函数
keras.callbacks 模块包含许多内置的回调函数,如
keras.callbacks.ModelCheckpoint
keras.callbacks.EarlyStopping
keras.callbacks.LearningRateScheduler
keras.callbacks.ReduceLROnPlateau
keras.callbacks.CSVLogger
等
ModelCheckpoint 与 EarlyStopping 回调函数
如果监控的目标指标在设定的轮数内不再改善,可以用 EarlyStopping 回调函数来中断训练。比如,这个回调函数可以在刚开始过拟合的时候就中断训练,从而避免用更少的轮次重新训练模型。这个回调函数通常与ModelCheckpoint 结合使用,后者可以在训练过程中持续不断地保存模型(你也可以选择只保存目前的最佳模型,即一轮结束后具有最佳性能的模型)
import keras
# 通过 fit 的 callbacks 参数将回调函数传入模型中,这个参数接收一个回调函数的列表。你可以传入任意个数的回调函数
# EarlyStopping: 1. 如果不再改善,就中断训练 2. 监控模型的验证精度 3. 如果精度在多于一轮的时间(即两轮)内不再改善,中断训练
# ModelCheckpoint: 1. 在每轮过后保存当前权重 2. 如果 val_loss 没有改善,那么不需要覆盖模型文件
callbacks_list = [
keras.callbacks.EarlyStopping(
monitor='acc',
patience=1,
),
keras.callbacks.ModelCheckpoint(
filepath='model.h5',
monitor='val_loss',
save_best_only=True,
)
]
# 监控精度,所以" metrics=['acc'] "应该是模型指标的一部分
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
# 由于回调函数要监控验证损失和验证精度,所以在调用 fit 时需要传入 validation_data(验证数据)
model.fit(x, y, epochs=10, batch_size=32, validation_data=(x_val, y_val), callbacks=callbacks_list)
ReduceLROnPlateau 回调函数
如果验证损失不再改善,你可以使用这个回调函数来降低学习率。在训练过程中如果出现了损失平台(loss plateau),那么增大或减小学习率都是跳出局部最小值的有效策略
# 监控模型的验证损失,触发时将学习率除以 10,如果验证损失在 10 轮内都没有改善,那么就触发这个回调函数
callbacks_list = [
keras.callbacks.ReduceLROnPlateau(
monitor='val_loss'
factor=0.1,
patience=10,
)
]
model.fit(x, y,
epochs=10,
batch_size=32,
callbacks=callbacks_list,
validation_data=(x_val, y_val))
自定义回调函数
回调函数的实现方式是创建 keras.callbacks.Callback 类的子类。然后你可以实现下面这些方法(从名称中即可看出这些方法的作用),它们分别在训练过程中的不同时间点被调用
- on_epoch_begin -- 在每轮开始时被调用
- on_epoch_end -- 在每轮结束时被调用
- on_batch_begin -- 在处理每个批量之前被调用
- on_batch_end -- 在处理每个批量之后被调用
- on_train_begin -- 在训练开始时被调用
- on_train_end -- 在训练结束时被调用
这些方法被调用时都有一个 logs 参数,这个参数是一个字典,里面包含前一个批量、前一个轮次或前一次训练的信息,即训练指标和验证指标等。此外,回调函数还可以访问下列属性
- self.model:调用回调函数的模型实例
- self.validation_data:传入 fit 作为验证数据的值
自定义回调函数的简单示例,它可以在每轮结束后将模型每层的激活保存到硬盘(格式为 Numpy 数组),这个激活是对验证集的第一个样本计算得到的
import keras
import numpy as np
class ActivationLogger(keras.callbacks.Callback):
def set_model(self, model):
self.model = model
layer_outputs = [layer.output for layer in model.layers]
self.activations_model = keras.models.Model(model.input, layer_outputs)
def on_epoch_end(self, epoch, logs=None):
if self.validation_data is None:
raise RuntimeError('Requires validation_data.')
validation_sample = self.validation_data[0][0:1]
activations = self.activations_model.predict(validation_sample)
f = open('activations_at_epoch_' + str(epoch) + '.npz', 'w')
np.savez(f, activations)
f.close()
TensorBoard 简介:TensorFlow 的可视化框架
TensorBoard,一个内置于 TensorFlow 中的基于浏览器的可视化工具。只有当 Keras 使用 TensorFlow 后端时,这一方法才能用于 Keras 模型
-- 等待尝试
让模型性能发挥到极致
高级架构模式
除残差连接外,标准化和深度可分离卷积在构建高性能深度卷积神经网络时也特别重要
批标准化
标准化(normalization)是一大类方法,用于让机器学习模型看到的不同样本彼此之间更加相似,这有助于模型的学习与对新数据的泛化。最常见的数据标准化形式就是:将数据减去其平均值使其中心为 0,然后将数据除以其标准差使其标准差为 1。实际上,这种做法假设数据服从正态分布(也叫高斯分布),并确保让该分布的中心为 0,同时缩放到方差为 1
normalized_data = (data - np.mean(data, axis=...)) / np.std(data, axis=...)
前面的示例都是在将数据输入模型之前对数据做标准化。但在网络的每一次变换之后都应该考虑数据标准化。即使输入 Dense 或 Conv2D 网络的数据均值为 0、方差为 1,也没有理由 假定网络输出的数据也是这样
批标准化(batch normalization)是在 2015 年提出的一种层的类型(在Keras 中是 BatchNormalization),即使在训练过程中均值和方差随时间发生变化,它也可以适应性地将数据标准化。批标准化的工作原理是,训练过程中在内部保存已读取每批数据均值和方差的指数移动平均值。批标准化的主要效果是,它有助于梯度传播(这一点和残差连接很像),因此允许更深的网络。对于有些特别深的网络,只有包含多个 BatchNormalization 层时才能进行训练
BatchNormalization 层通常在卷积层或密集连接层之后使用
conv_model.add(layers.Conv2D(32, 3, activation='relu'))
conv_model.add(layers.BatchNormalization())
dense_model.add(layers.Dense(32, activation='relu'))
dense_model.add(layers.BatchNormalization())
BatchNormalization 层接收一个 axis 参数,它指定应该对哪个特征轴做标准化。这个参数的默认值是 -1,即输入张量的最后一个轴。对于 Dense 层、Conv1D 层、RNN 层和将data_format 设为 "channels_last"(通道在后)的 Conv2D 层,这个默认值都是正确的。但有少数人使用将 data_format 设为 "channels_first"(通道在前)的 Conv2D 层,这时特征轴是编号为 1 的轴,因此 BatchNormalization 的 axis 参数应该相应地设为 1
深度可分离卷积
深度可分离卷积(depthwise separable convolution)层(SeparableConv2D)可以替代 Conv2D,并可以让模型更加轻量(即更少的可训练权重参数)、速度更快(即更少的浮点数运算),还可以让任务性能提高几个百分点。这个层对输入的每个通道分别执行空间卷积,然后通过逐点卷积(1×1 卷积)将输出通道混合
如图示
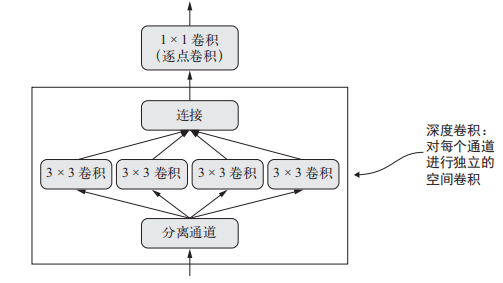
这相当于将空间特征学习和通道特征学习分开,如果你假设输入中的空间位置高度相关,但不同的通道之间相对独立,那么这么做是很有意义的。它需要的参数要少很多,计算量也更小,因此可以得到更小、更快的模型。因为它是一种执行卷积更高效的方法,所以往往能够使用更少的数据学到更好的表示,从而得到性能更好的模型
demo
from keras.models import Sequential, Model
from keras import layers
height = 64
width = 64
channels = 3
num_classes = 10
model = Sequential()
model.add(layers.SeparableConv2D(32, 3, activation='relu', input_shape=(height, width, channels,)))
model.add(layers.SeparableConv2D(64, 3, activation='relu'))
model.add(layers.MaxPooling2D(2))
model.add(layers.SeparableConv2D(64, 3, activation='relu'))
model.add(layers.SeparableConv2D(128, 3, activation='relu'))
model.add(layers.MaxPooling2D(2))
model.add(layers.SeparableConv2D(64, 3, activation='relu'))
model.add(layers.SeparableConv2D(128, 3, activation='relu'))
model.add(layers.GlobalAveragePooling2D())
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(num_classes, activation='softmax'))
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
超参数优化
构建深度学习模型时,你必须做出许多看似随意的决定:应该堆叠多少层?每层应该包含多少个单元或过滤器?激活应该使用 relu 还是其他函数?在某一层之后是否应该使用BatchNormalization ?应该使用多大的 dropout 比率?还有很多。这些在架构层面的参数叫作超参数(hyperparameter),以便将其与模型参数区分开来,后者通过反向传播进行训练
超参数优化的过程通常如下所示:
- 选择一组超参数
- 构建相应的模型
- 将模型在训练数据上拟合,并衡量其在验证数据上的最终性能
- 选择要尝试的下一组超参数(自动选择)
- 重复上述过程
- 最后,衡量模型在测试数据上的性能
这个过程的关键在于,给定许多组超参数,使用验证性能的历史来选择下一组需要评估的超参数的算法。有多种不同的技术可供选择:贝叶斯优化、遗传算法、简单随机搜索等
更新超参数非常具有挑战性,如
- 计算反馈信号(这组超参数在这个任务上是否得到了一个高性能的模型)的计算代价可能非常高,它需要在数据集上创建一个新模型并从头开始训练
- 超参数空间通常由许多离散的决定组成,因而既不是连续的,也不是可微的。因此,你通常不能在超参数空间中做梯度下降。相反,你必须依赖不使用梯度的优化方法,而这些方法的效率比梯度下降要低很多
通常情况下,随机搜索(随机选择需要评估的超参数,并重复这一过程)就是最好的解决方案,虽然这也是最简单的解决方案。也存在一些工具比随机搜索要好很多,如:Hyperopt。它是一个用于超参数优化的 Python 库,其内部使用 Parzen 估计器的树来预测哪组超参数可能会得到好的结果。另一个叫作 Hyperas 的库将 Hyperopt 与 Keras 模型集成在一起
模型集成
集成是指将一系列不同模型的预测结果汇集到一起,从而得到更好的预测结果。集成依赖于这样的假设,即对于独立训练的不同良好模型,它们表现良好可能是因为不同的原因:每个模型都从略有不同的角度观察数据来做出预测,得到了“真相”的一部分,但不是全部真相。每个模型都得到了数据真相的一部分,但不是全部真相。将他们的观点汇集在一起,你可以得到对数据更加准确的描述
集成最简单的方法就是就不同模型的结果进行平均,以平均值作为预测的结果。但是这种方法假设了所使用的分类器的性能都差不多好。如果其中一个模型性能比其他的差很多,那么最终预测结果可能不如这一组中的最佳模型好
而更加适用的方法是对各个模型的结果进行加权平均,其权重从验证数据上学习得到。通常来说,更好的模型被赋予更大的权重,而较差的模型则被赋予较小的权重。为了找到一组好的集成权重,你可以使用随机搜索或简单的优化算法(比如 Nelder-Mead 方法)
还有许多其他变体,比如你可以对预测结果先取指数再做平均。一般来说,简单的加权平均,其权重在验证数据上进行最优化,这是一个很强大的基准方法。想要保证集成方法有效,关键在于这组分类器的多样性(diversity)。多样性能够让集成方法取得良好效果。用机器学习的术语来说,如果所有模型的偏差都在同一个方向上,那么集成也会保留同样的偏差。如果各个模型的偏差在不同方向上,那么这些偏差会彼此抵消,集成结果会更加稳定、更加准确
因此,集成的模型应该尽可能好,同时尽可能不同。这通常意味着使用非常不同的架构,甚至使用不同类型的机器学习方法。有一件事情基本上是不值得做的,就是对相同的网络,使用不同的随机初始化多次独立训练,然后集成。如果模型之间的唯一区别是随机初始化和训练数据的读取顺序,那么集成的多样性很小,与单一模型相比只会有微小的改进。集成不在于你的最佳模型有多好,而在于候选模型集合的多样性
注
在进行大规模超参数自动优化时,有一个重要的问题需要牢记,那就是验证集过拟合。因为你是使用验证数据计算出一个信号,然后根据这个信号更新超参数,所以你实际上是在验证数据上训练超参数,很快会对验证数据过拟合
Deep learning with Python 学习笔记(10)
Deep learning with Python 学习笔记(8)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号