

GoogLeNetv4 论文研读笔记
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
摘要
向传统体系结构中引入残差连接使网络的性能变得更好,这提出了一个问题,即将Inception架构与残差连接结合起来是否能带来一些好处。在此,研究者通过实验表明使用残差连接显著地加速了Inception网络的训练。也有一些证据表明,相比没有残差连接的消耗相似的Inception网络,残差Inception网络在性能上具有微弱的优势。针对是否包含残差连接的Inception网络,本文同时提出了一些新的简化网络,同时进一步展示了适当的激活缩放如何使得很宽的残差Inception网络的训练更加稳定
引言
在本研究中,研究者研究了当时最新的两个想法:残差连接和最新版的Inception架构。他们研究了使用残差连接来代替Inception架构中的过滤连接阶段,这将使Inception架构保持它的计算效率的同时获得残差连接方法的好处。除了将两者直接集成,也研究了Inception本身能否通过加宽和加深来变得更高效。为此,他们设计了Inception v4,相比v3,它有更加统一简化的网络结构和更多的inception模块
在本文中,他们将两个纯Inception变体(Inception-v3和v4)与消耗相似的 Inception-ResNet混合版本进行比较。挑选的模型满足和非残差模型具有相似的参数和计算复杂度的约束条件。实验对组合模型的性能进行了评估,结果显示Inception-v4和Inception-ResNetv2的性能都很好,同时发现单个框架性能的提升不会引起组合性能大幅的提高
相关工作
残差连接的作者认为残差连接在训练深度卷积模型是很有必要的,但是至少在图像识别上,本研究并不支持这一点,该实验表明使用残差连接来训练深度网络也不是很难做到。不过,残差连接所带来的潜在优势可能需要在更深网络结构中来展现。但是,使用残差连接确实能够极大地提高训练速度,这一点很值得肯定。
残差连接

为减少计算而优化的ResNet连接
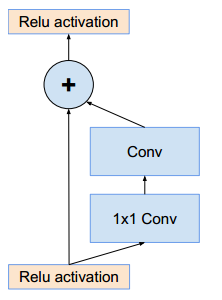
架构选择
纯Inception模块
以前的Inception模块为了能够在内存中对整个模型进行拟合,采用分布式训练的方法,该方法将每个副本划分成一个含多个子网络的模型。然而,Inception结构是高度可调的,这就意味着各层滤波器的数量可以有多种变化,而整个训练网络的质量不会受到影响。为了优化训练速度,他们对层的尺寸进行调整以平衡多模型子网络的计算。因为TensorFlow的引入和为了优化,本研究对Inception块的每个网格尺寸进行了统一。以下所有架构图中,卷积层没有标记"V"的表示使用相同的填充原则,即它们的输出网格尺寸与它们的输入相匹配。标记了"V"的卷积层使用valid填充,即每个单元输入块全部包含在前几层中,同时输出激活图(output activation map)的网格尺寸也相应地减少
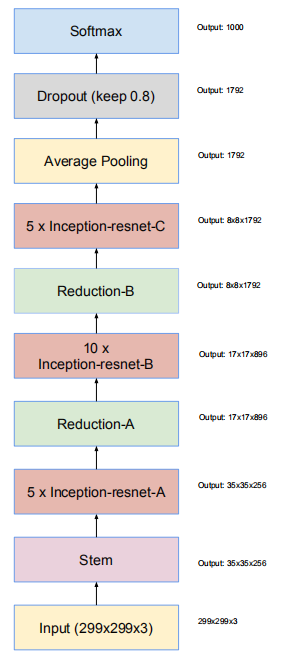
Inception-v4网络整体架构
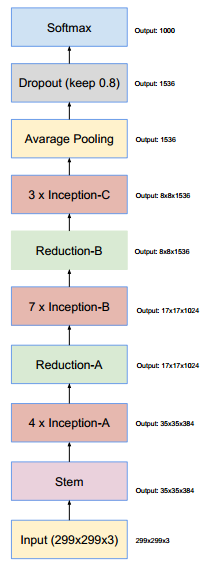
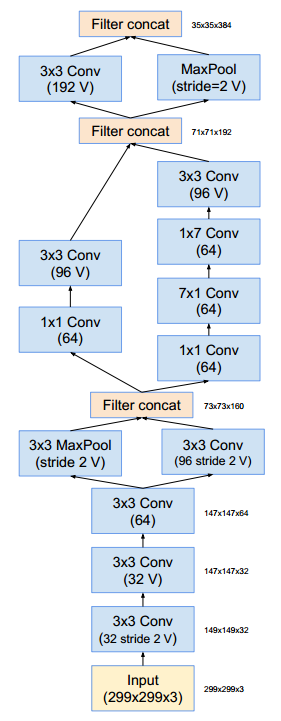
Inception-v4和Inception-ResNet-v2网络结构,这是输入部分(Fig3)
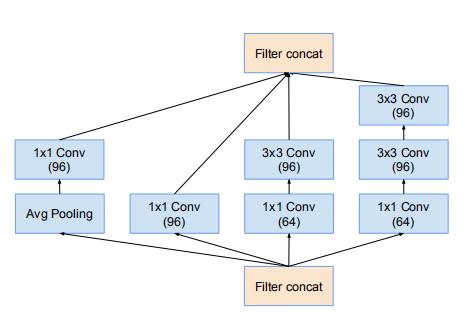
Inception-v4网络的35 * 35 网格模块,对应Inception-v4的Inception-A
Inception-v4网络的17 * 17 网格模块,对应Inception-v4的Inception-B
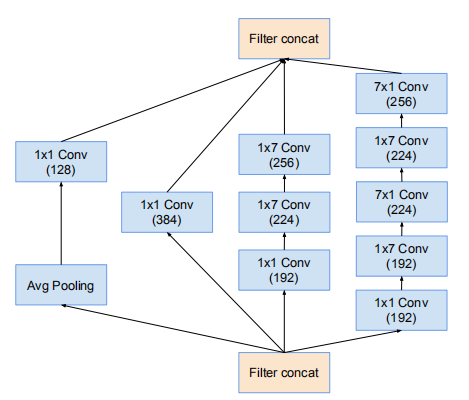
Inception-v4网络的8 * 8 网格模块,对应Inception-v4的Inception-C
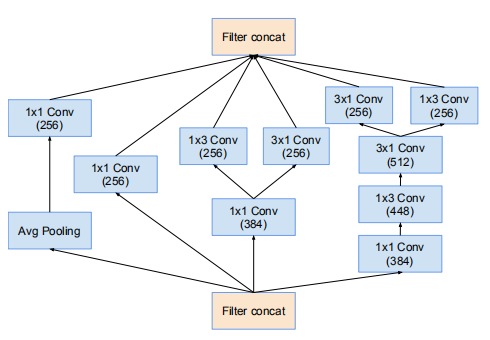
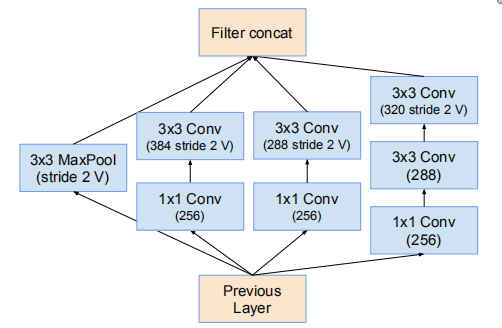
35 * 35 -> 17 * 17 的降维模块(Fig7)
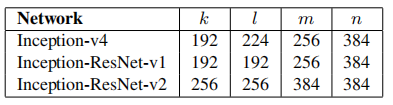
参数设置
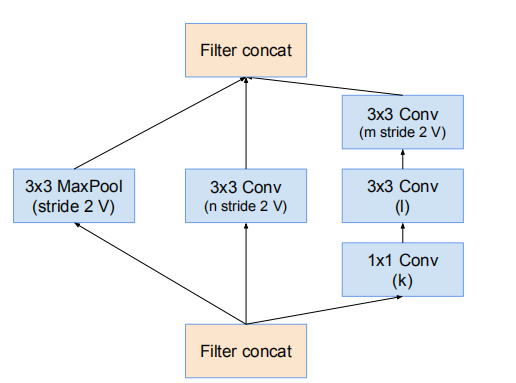
17 * 17 -> 8 * 8 的网格缩减模块
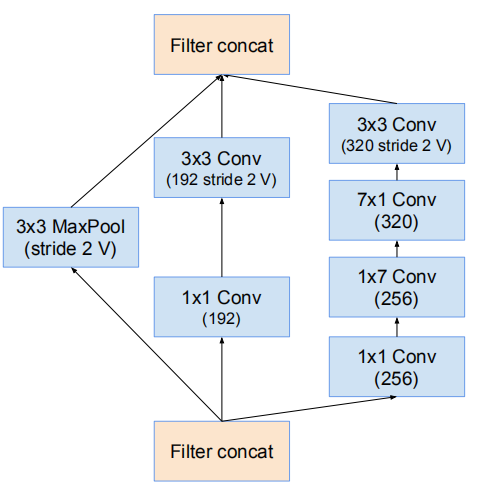
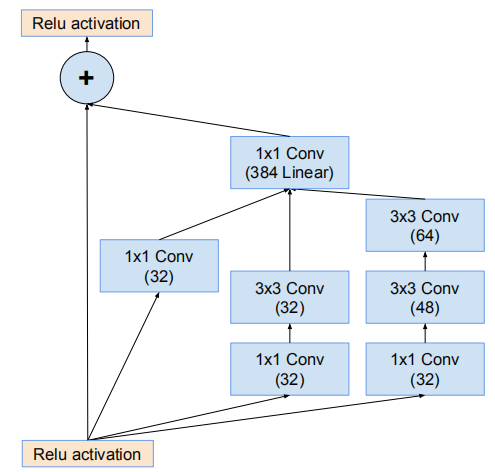
残差Inception块
残差版本的Inception网络使用了比源Inception更廉价的Inception块。每个Inception块后紧连接着滤波膨胀层(没有激活函数的1×1卷积)以在相加之前放大滤波器组的维度,以实现输入的匹配。这样补偿了在Inception块中的降维。
Inception-ResNet-v1与Inception-v3的计算代价相近,Inception-ResNet-v2与Inception-v4的计算代价相近。另一个研究使用的残差和非残差变体技术上的不同是:在Inception-ResNet上仅在传统层的顶部而非所有层的顶部中使用batch-normalization。这是因为研究者想要保持每个模型副本在单个GPU上就可以训练,在部分层的顶部忽略 batch-normalization能够增加Inception块的数量
Inception-ResNet-v1和Inception-ResNet-v2网络完整架构
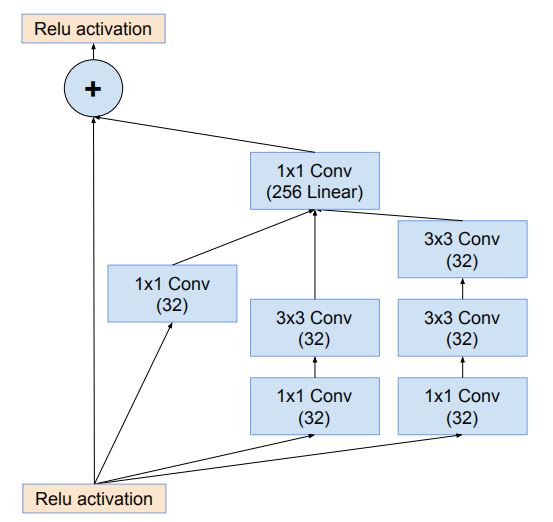
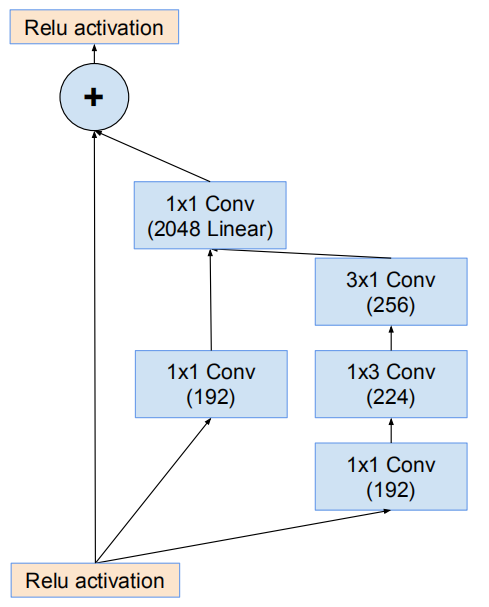
Inception-ResNet-v1
网络使用35*35网格模块(Inception-ResNet-A)
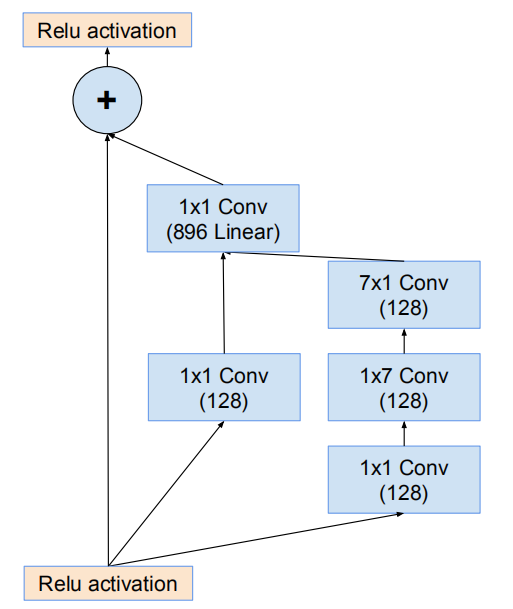
网络的17*17网格模块(Inception-ResNet-B)
使用Fig7作为Reduction-A
网络的17*17 -> 8*8网格缩减模块(Reduction-B)

网络的8*8网格模块(Inception-ResNet-C)
网络的主干(stem)

Inception-ResNet-v2
Fig3用于网络stem
网络35*35的网格模块(Inception-ResNet-A)
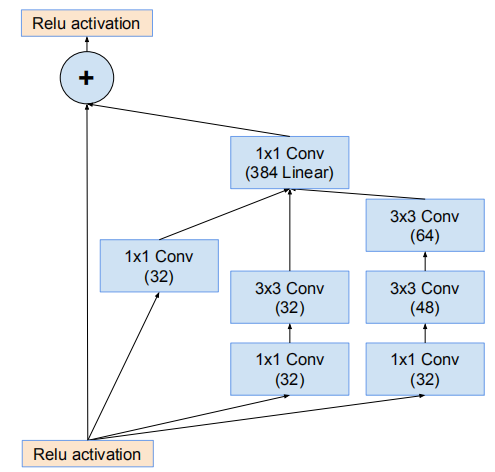
网络17*17网格模块(Inception-ResNet-B)
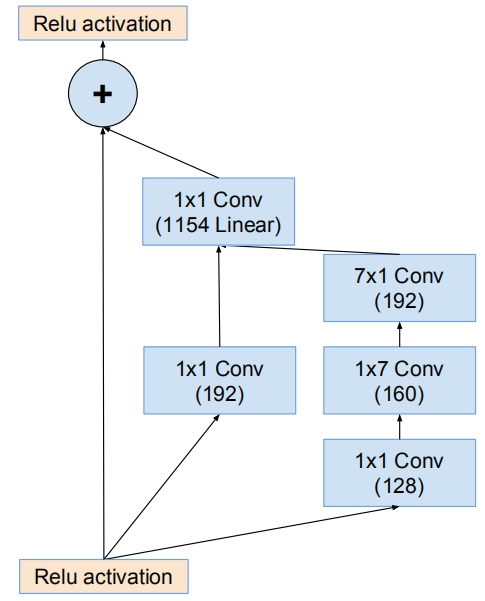
Fig7用于Reduction-A
网络17*17 -> 8*8网格缩减模块(Reduction-B)
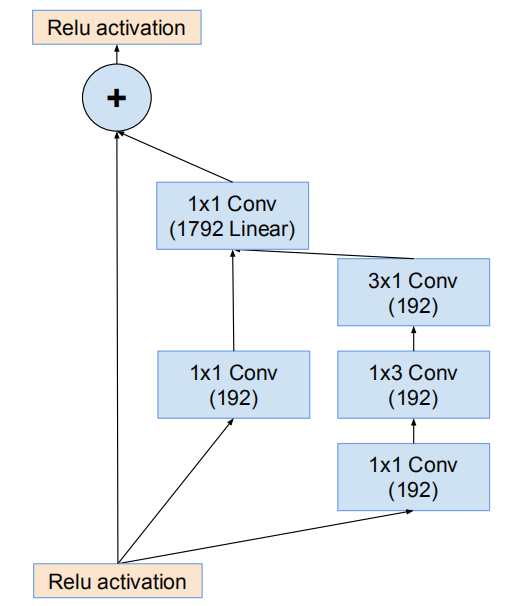
网络8*8网格模块(Inception-ResNet-C)
对残差模块的缩放
研究者发现如果滤波器数量超过1000,残差网络开始出现不稳定,同时网络会在训练过程早期便会出现“死亡”,意即经过成千上万次迭代,在平均池化(average pooling) 之前的层开始只生成0。通过降低学习率,或增加额外的batch-normalizatioin都无法避免这种状况。同时,发现在将残差模块添加到activation激活层之前,对其进行放缩能够稳定训练,通常来说将残差放缩因子定在0.1-0.3,即使缩放并不是完全必须的,它似乎并不会影响最终准确率,但是放缩能有益于训练的稳定性
实验结果表明Inception-ResNet-v1,Inception-v4,Inception-ResNet-v2的错误率逐个降低并都比Inception-v3和BN-Inception表现的好
结论
本文详细呈现了三种新的网络结构
- Inception-ResNet-v1:混合Inception版本,它的计算效率与Inception-v3相近
- Inception-ResNet-v2:更加昂贵的混合Inception版本,明显改善了识别性能
- Inception-v4:没有残差连接的纯Inception变种,性能与Inception-ResNet-v2相近
研究者们研究了引入残差连接如何显著地提高Inception网络地训练速度。并且他们最新地模型仅仅凭借增加模型尺寸就能表现地优于他们现有的网络
总结
本文研究了将Inception和残差连接相结合的效果,实验表明结合ResNet可以加速训练,同时提高性能,在构建 Inception-ResNet 网络同时,还设计了一个更深更优化的 Inception v4 模型,能达到相媲美的性能
比较了一下文章中提到的三个网络的架构,然后发现,Inception-ResNet-v1与Inception-ResNet-v2,Inception-v4相比,最明显的差别是stem部分不同,特别是与Inception-ResNet-v2相比,其它部分几乎就只是卷积层数的变化,而在stem部分,其它两个使用相同的结构,使用的参数量的比较 4112 : 5344,同时v1这部分输出为35*35*256,其它两个输出为35*35*384,显然这里明显让v1吃亏了,其性能差的原因我觉得这个部分有很大的原因。之后Inception-ResNet-v2与Inception-v4相比,架构的总体结构可以看出是很相似的,最大的区别在于数据是否是直接传到下一层的,如下
Inception-v4(Inception-A)
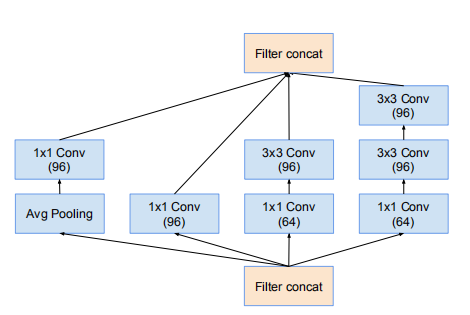
Inception-ResNet-v2(Inception-A)
Inception-v4(Reduction-B)
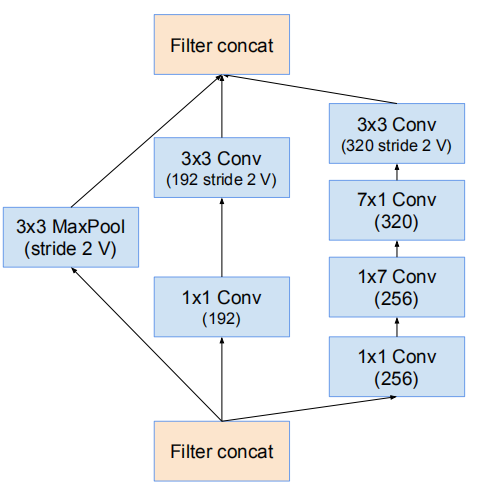
Inception-ResNet-v2(Reduction-B)
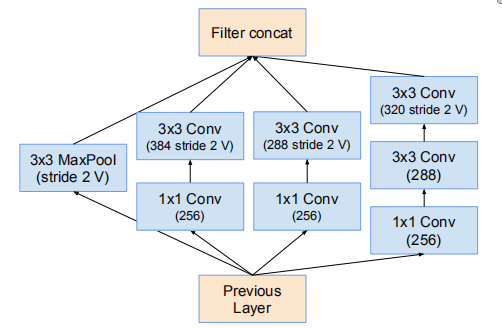
个人感觉差别不是很大,很直观地可以看出因为Inception-ResNet-v2使用的变换较少,计算量较小,因而可以获得更好的性能吧,其它的更多是各种参数的问题
GoogLeNetv1 论文研读笔记
GoogLeNetv2 论文研读笔记
GoogLeNetv3 论文研读笔记
ResNet 论文研读笔记

