AD分类论文研读(1)
迁移学习对阿尔茨海默病分类的研究
原文链接
摘要
将cv用于研究需要大量的训练图片,同时需要对深层网络的体系结构进行仔细优化。该研究尝试用转移学习来解决这些问题,使用从大基准数据集组成的自然图像得到的预训练权重来初始化最先进的VGG和Inception结构,使用少量的MRI图像来重新训练全连接层。采用图像熵选择最翔实的切片训练,通过对OASIS MRI数据集的实验,他们发现,在训练规模比现有技术小近10倍的情况下,他们的性能与现有的基于深层学习的方法相当,甚至更好
介绍
AD的早期诊断可以通过机器学习自动分析MRI图像来实现。从头开始训练一个网络需要大量的资源并且可能结果还不够好,这时候可以选择使用微调一个深度网络来进行转移学习而不是重新训练的方法可能会更好。该研究使用VGG16和Inception两个流行的CNN架构来进行转移学习。结果表明,尽管架构是在不同的领域进行的训练,但是当智能地选择训练数据时,预训练权值对AD诊断仍然具有很好的泛化能力
由于研究的目标是在小训练集上测试转移学习的鲁棒性,因此仅仅随机选择训练数据可能无法为其提供表示MRI足够结构变化的数据集。所以,他们选择通过图像熵提供最大信息量的训练数据。结果表明,通过智能训练选择和转移学习,可以达到与从无到有以最小参数优化训练深层网络相当甚至更好的性能
方法
CNN的核心是从输入图像中抽取特征的卷积层,卷积层中的每个节点与空间连接的神经元的小子集相连,为了减少计算的复杂性,一个最大池化层会紧随着卷积层,多对卷积层和池化层之后会跟着一个全连接层,全连接层学习由卷积层抽取出来的特征的非线性关系,最后是一个soft-max层,它将输出归一化到期望的水准
因为小的数据集可能会使损失函数陷入local minima,该研究使用转移性学习的方法来尽量规避这种情况,即使用大量相同或不同领域的数据来初始化网络,仅使用训练数据来重新训练最后的全连接层
研究中使用两个流行的架构:
VGG16
VGG16是一个16层的网络,它是第一个将网络深度拓展到16-19层的使用3*3卷积核的架构
Inception
Inception架构是Google构建的深度学习架构的变体,本文章中使用Inception V4,Inception的突破遭遇实现了通过改变卷积层的连接方式可以学习非线性函数。同时取代全连接,使用全局平均池化,之后连接一个用于分类的softmax层,这样我们使用的参数就变得更少,以此可以降低过耦合
最翔实的数据选择
在之前的方法中,数据的选择都是随机的,而此研究提取最翔实的切片来训练网络,使用计算每个切片的图像熵的方法来进行选取,熵的计算方法
其中,M为概率为p1,p2...,pM的样例的集合
熵提供了切片中的变化的度量。因此,如果按熵降序对切片进行排序,熵值最高的切片可以被认为是信息量最大的图像,并且使用这些图像进行训练将提供更好的鲁棒性
实验
在实验中数据集合来自从416个主题中随机选择的200个主题,其中AD和HC组各一半,然后从每个三维扫描的轴向平面抽取信息熵最大的32张图片来组成6400张训练图片
VGG16的输入为 150 * 150,Inception V4输入为 299 * 299
5折交叉验证在此被使用,同时将数据按8:2分为训练和测试
预训练网络权重来自ImageNet,对于VGG16,使用batch_size=40,epochs=100,优化器使用RMSProp;对于Inception V4使用batch_size=8,epochs=100,随机梯度下降学习率围殴0.0001优化的设置
结果
| Model | Avg.ACC.(st.dev)(%) |
|---|---|
| VGG16(from scratch) | 74.12(1.55) |
| VGG16(transfer learning) | 92.3(2.42) |
| Inception V4(transfer learning) | 96.25(1.2) |
总结
该研究特点是使用预训练模型,同时使用图片的熵来挑选图片进行训练。
作者认为该研究的优势是仅使用6400张的小数据集就达到了一个比较可人的精度,但是此6400张图片是基于所有的200个主题的图片进行挑选的,这种数据数量的算法是否存在问题
综合多种方法改善阿尔茨海默病分类
原文链接
摘要
皮层灰质体积、皮层厚度和皮层下体积已成功地用于阿尔茨海默病的诊断,但是目前这些解剖MRI措施主要单独使用。为了进一步提高AD的诊断水平,该研究提出了一种基于多尺度的MRI图像ROI特征和区域间特征提取方法,用于区分AD、MCI(包括MCIc和MCIC)和健康对照(HC)
首先,根据每位受试者的六种不同的解剖测量(即CGMV、CT、CSA、CC、CFI和SV)和自动解剖标记(AAL)图谱构建六个单独的网络。然后,针对每个网络,提取所有节点(ROI)特征和边缘(区域间)特征,分别表示为节点特征集和边缘特征集,可以从六个不同的解剖测量中得到六个节点特征集和六个边缘特征集。然后,对特征集中的每个特征按降序进行F分排序,并将每个特征集的最高排序特征应用于MKBoost算法,以获得最佳的分类精度
在获得最佳分类精度后,可以得到每个节点或边缘特征集的最优特征子集和相应的分类器。随后,为了研究仅含节点特征的分类性能,提出了一个加权多核学习(wMKL)框架来组合这六个最优节点特征子集,并得到一个组合的分类器来执行AD分类。类似地,可以获得仅具有边缘特征的分类性能。最后,我们结合六个最优节点特征子集和六个最优边缘特征子集进一步提高了分类性能
介绍
皮质灰质体积(CGMV)、皮质厚度(CT)、皮质表面积(CSA)、皮质曲率(CC)、皮质折叠指数(CFI)、皮质下体积(SV)
MRI分为两大类:结构(解剖)成像和功能成像。结构性MRI由于其在临床上容易获得,因此受到研究者的广泛关注。在该研究中使用了T1加权MRI图像
基于区域的分析方法已经成为自动AD诊断的最流行的方法之一。基于区域的分析方法的关键是兴趣区域(ROI)的确定。一旦确定了大脑中的ROI,就可以利用它们来识别AD、MCI和健康对照(HC)人群之间的解剖学差异,并随后确定AD相关特征以辅助诊断、预后以及MCI进展和治疗效果的评估。根据ROI的数量,基于区域的分析方法可以分为两类:单ROI方法和多ROI方法。不同的研究学者将大脑划分为不同个数的ROI。在该研究中不仅考虑大脑中的每个ROI,而且考虑两个ROI之间的相关性,结合多种解剖学MRI检查方法诊断AD
核方法,如支持向量机(SVM),已经在许多数据分析应用中得到了广泛的应用。由于单核方法可能不足以有效处理实际应用中的不同模式和复杂决策边界,因此提出了多核学习(MKL)方法,以获得更好的能力和更大的灵活性来解决现实世界的挑战。MKL可以集成不同的特征空间源,从而为数据融合提供通用框架
在本文中,提出了一种新的AD诊断方法,通过MKL结合多种措施。使用的解剖措施包括CGMV,CT,CSA,CC,CFI和SV
首先,基于六种不同的解剖测量和针对每个受试者的自动解剖标记(AAL)图谱构建六个单独的网络。其它步骤如摘要所述
图像描述与预处理
所有T1加权MRI图像使用Freesurfer图像分析套件进行预处理。图像预处理主要包括运动校正、强度归一化、颅骨剥离和小脑切除
脑区测量
测量皮质区
本研究整合了CGMV、CT、CSA、CC和CFI等皮层区域的多种测量方法
为了计算皮质区域的CGMV、CT、CSA、CC和CFI,使用Freesurfer软件,对T1加权MRI图像的皮质表面进行解剖学重建。在解剖重建之前,所有T1加权MRI图像都登记到AAL地图集
在解剖重建过程中,利用基于局部强度值和几何拓扑约束的变形算法生成表示白质表面边界和软质表面边界的三角形网格。每个三角形网格由每个半球的100000个顶点组成。重复重建过程,直到获得白质和软质表面的精确表示。重建的表面被用来计算这些测量。白质和软脑膜表面之间的体积计算为CGMV,计算白质与软膜表面之间两个最短距离的平均值作为CT。温克勒等人认为每个顶点的CSA等于其周围三角形的平均值。因此,三角形的面积之和可以用来表示ROI的CSA。在这些方向上密切圆的半径长度的倒数用作在这些方向上的顶点的曲率,因此,曲面的两个主要方向的曲率值的平均值可以用来表示ROI的CC。CFI,也称为局部回转指数(lGI),是由Sch.等人先前提出的基于表面的3D回转技术测量的。在皮层表面上给定体素处的lGI被计算为折叠的皮层表面上半径为25mm的圆形ROI的表面与对应的皮层外周表面之间的比率。皮层折叠的数量(lGI)在每个软脑膜表面位置反映了皮层埋藏在沟褶内周围区域的数量。LGI的值越大,在沟状褶皱中埋藏的表面越多
AAL地图集

皮质下区测量
SV已成功地用于区分AD患者与HCS(47)。在本研究中,使用FSL中的FIRST计算皮层下结构的体积。在第一阶段,使用非线性MNI—152模板来配准所有的全脑图像。此外,为了实现更准确的配准,在先前结果的基础上使用皮层下掩模(来自表2所示的AAL图谱)。在第二阶段,使用可变形网格对皮层下结构的形状进行建模,并且使用结构分割方法将边界体素分类为皮层下结构的一部分。在第三阶段,通过FSL获得的颅内容积校正皮质下容积
独立网络的构建
本研究中构建了两个独立网络:皮层网络和皮层下网络
网络通常被定义为
其中,V、E分别顶点的集合和边的集合
皮层网络
根据上述的五种皮层区域测度,可以构建五种个体网络
对于GCGMV,节点是由AAL图集定义的皮质区域,边缘是一对节点之间CGMV的某种相似性。在这项研究中,一对节点之间的CGMV的相似性计算如下
其中d(a,b)定义为 ROIs a和b的差异
其中t(a),t(b)分别为ROIs a和b的CGMV
其它四个网络的构造方法与此相似,这五个单独的皮层网络共享同一组皮层区域,并使用相同的方法计算一对节点之间的相似性,只是它们对于t(.)使用不同的定义,对于GCT,GCSA,GCC,GCFI分别使用CT,CSA,CC和CFI的皮质区
对于皮层下网络,我们仅基于上述皮层下区域的度量来构建单个网络,表示为GSV。GSV的构造方法类似于上述五个单独的网络。他们使用相同的方法来计算一对节点之间的相似性。它们的差异主要表现在GSV的节点集合是皮层下区域而不是皮层区域,GSV中的t(.)代表皮层下区域的SV
两个ROIs之间的差异越小,它们的相关性越大。如果两个ROIs具有相同的值,它们具有最强的相似性,其相关性等于1
将提取每个网络的所有节点和边缘作为AD分类的原始特征。基于这六个独立的网络,我们可以提取两类特征集:节点特征集和边缘特征集
特征排序是识别降维相关特征和提高泛化性能的有效手段。在本研究中,使用F-得分对每个特征集(如NCGMV、NCT、ECC、ECFI等)中的所有特征进行排序
F-score用于测量两个实数集之间的差距
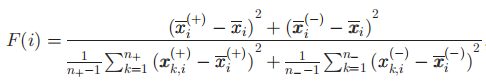
其中n+和n-分别代表正/负数实例的个数
多核学习分类
在这项研究中,提出了一个两步MKL方法来实现最终分类
首先,使用MKBOSTST-S2算法获得之前定义的每个特征集的最优特征子集和最优分类器。由于多项式核具有良好的全局性能和高斯核具有良好的局部性能,因此在本研究中,定义了一组用于MKBoost-S2算法(即M=13)的13个基核
多项式核被定义为
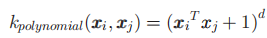
表示多项式核的度,该研究中使用d={1,2,3}对于每个特征集合
Gaussian被定义为
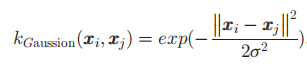
其中\(\sigma\)表示Gaussian核的宽度,研究中使用\(\sigma\)={2-4,2-3...25}共10个值对于每个特征集合
对于一个特别的特征集NCGMV,使用他的top pi特征构造K个不同的特征子集。对于13个已经定义的基核,MKBoost-S2为每个K特征子集生成了一个分类器。然后我们就得到了K个分类器,在这K个分类器中,准确度最高的一个即为优化分类器,与它相关的特征集即为优化特征集,以同样的方法来得到其它各个特征集的优化分类器,优化特征子集。之后,一个带权重的MKL框架被提出来利用最优特征子集和相应的最优分类器来构造组合分类器,以研究分类性能

最终组合的分类器的计算方法

其中,\(\eta\)v表示分类器的权重
提出的架构

总结
在本研究中,提出了一种通过多核学习结合多种解剖学MRI测量来诊断阿尔茨海默病的方法。基于AAL图集和六种不同的解剖学测量手段,首先为每个被试构建六个单独的网络,提取两类特征集:节点特征集和边缘特征集。然后,使用F得分方法来对每个特征集的特征进行排序。然后,将排名最高的特征应用到MKBoostS2算法中,得到最佳的分类精度、相应的分类器和最优特征子集。最后,提出了一种加权MKL框架,将节点特征集、边缘特征集以及节点特征集和边缘特征集分别组合起来进行最终分类
基于Wasserstein GANs的视觉特征属性
原文链接
摘要
先前训练的神经网络分类器的方法已经成为事实上的最新技术,并且通常用于医学和自然图像数据集。在本文中,讨论了这些方法的局限性,这可能导致只检测到类别特定特征的子集。为了解决这个问题,开发了一种基于Wasserstein生成对抗网络(WGAN)的新颖的特征识别技术,它没有这种局限性
研究显示,提出的方法在视觉归因方面,在合成数据集和来自轻度认知障碍(MCI)和阿尔茨海默病(AD)患者的真实3D神经影像学数据上明显优于现有技术。对于AD患者,该方法产生非常逼真的疾病效果图,非常接近观察到的效果
介绍
目前,解决视觉属性问题最常用的方法是训练神经网络分类器来预测一组图像的类别,然后遵循两种策略之一:分析预测相对于输入图像的梯度。或者分析图像的特征图的激活,以确定图像的哪个部分负责进行关联预测
直接基于神经网络分类器的决策是基于某些突出区域而不是整个感兴趣的对象。最近表明,在训练期间,神经网络使输入层和输出层之间的相互信息最小化,从而压缩输入特征。这些发现表明,如果目标具有冗余信息的更强的特征可用,则分类器可以忽略分辨能力低的特征。换句话说,神经网络训练可能与视觉归因的目标相反。因此,如果在图像中的多个位置(例如医学图像中的多个病灶)存在类证据,则一些位置可能不影响分类结果,因此可能不被检测
该文章的贡献是向以一种捕捉图像中所有特定类别效果的方式可视化特定类别的证据的方向迈进了一步。该方法不依赖于分类器,而是旨在找到一个map,当将其添加到一个类别的输入图像时,将使其与来自基线类别的图像不可区分。为此,提出了一个生成模型,在该模型中,可加map作为图像的函数被学习。该方法基于Wasserstein生成对抗网络(WGAN),具有使生成的图像与实际图像之间的Wasserstein距离的近似最小的理想性质
该方法没有处理分类问题,而是假设测试图像的类别标签已经确定,此外,该方法需要基线类别,目的是预测阿尔茨海默病(AD)的主体特异性疾病效应图
基于多模型卷积网络组合的阿尔茨海默病分类
原文链接
摘要
结构磁共振成像(MRI)在帮助理解AD相关的脑解剖结构变化中起着重要作用。该研究提出了一种基于多模型3D卷积网络结合的分类方法,以从MR脑图像中学习各种特征
首先,建立一个深度3D卷积神经网络,以将MR图像分层转换成更紧凑的高级特征。其次,构造多尺度3D卷积自动编码器(3D CAEs)以从MR脑图像中提取特征。将这些模型所学的特征与上层完全连接层和SOFTMAX层结合起来,用于AD诊断中的图像分类。所提出的方法能够自动地从成像数据中学习一般特征以进行分类,而无需对脑组织和区域进行分割。使用的数据为MRI(T1)
介绍
原始的脑图像太大,噪声很大,不能直接用于分类。因此,有必要提取代表性的图像分类特征
对于脑图像的形态分析,多个解剖区域,即感兴趣区域(ROI),是通过对标记的atlas进行翘曲来分组体素而产生的,并且区域测量被计算为图像分类的特征
但ROIS的定义需要积累研究人员的长期经验。ROIS的分割也受到科研人员个体差异和主观因素的影响。神经系统疾病引起的形态学异常并不总是发生在预定义的ROI中,这可能涉及多个ROI或部分提取的ROI,因此该方法在应用中的性能不稳定。体素特征是一种客观分析技术,用于定量测量基于体素的三种组织成分(灰质、白质和脑脊液)的密度或体积。VBM方法需要空间标准化(配准),即,空间中的脑图像的个体图像标准化为标准三维空间
标准化过程一般包括线性仿射变换和非线性形变配准两部分。为了捕获丰富的图像信息,在配准所有脑图像数据之后提取体素明智特征以将每个体素与标量测量向量的AD诊断相关联
本文提出了一种基于多模型卷积网络组合的分类方法,从MR脑图像中学习各种特征,并对AD和NC对象进行分类。在整个MR脑图像上构建多模型卷积网络,用于对紧凑的高级特征进行分层提取,方法如摘要中所述
分类框架
提出的方法不假设一个特定的神经成像方式。使用的数据为MRI(T1),在特征提取之前进行图像的预处理。特别地,在使用非参数非均匀强度归一化算法对强度不均匀性进行校正之后,所有MR图像都进行颅骨剥离和小脑去除。MR图像被注册成具有Demons的模板
研究所提出的分类方法基于结合了多模型的卷积网络,该网络具有以下两个步骤:使用多模型卷积网络进行特征提取然后将多种特征结合起来用于图像分类。该方法的优势有:
- 深层卷积学习结构能够从低层到高层提取特征,对训练图像的平移、尺度和旋转具有不变性
- 不同的深度卷积网络模型有助于学习对分类任务有用的互补特征,这些互补特征可以结合起来捕获MR脑图像的丰富信息,从而改进最终的分类
架构图
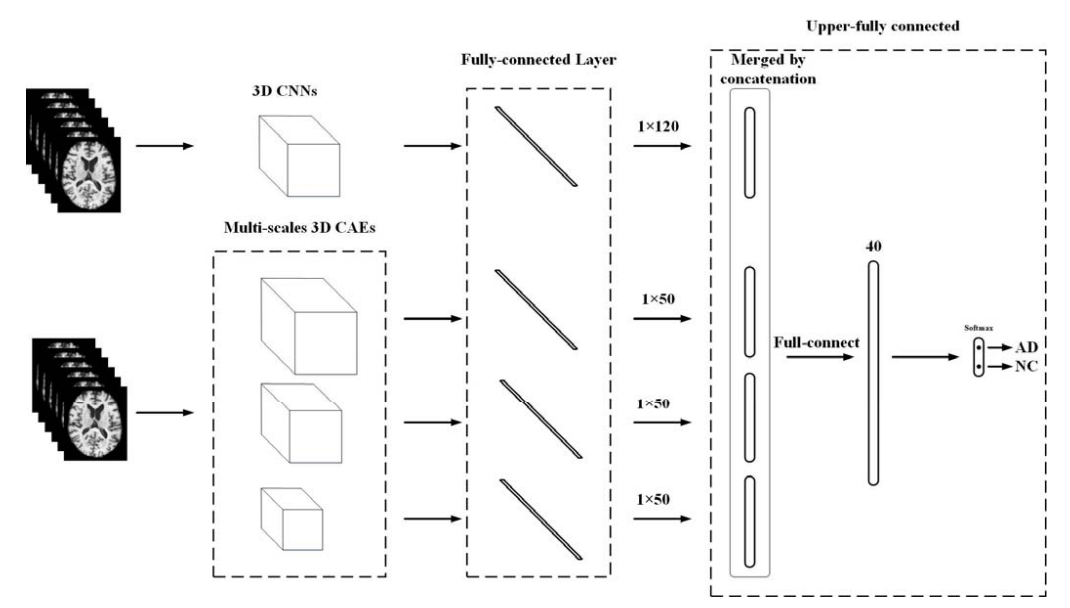
3DCNN的特征学习
该研究使用的MR脑图是3D数据,因此,使用了3D卷积核来编码它的丰富的空间信息。设计的用来提取特征的3D CNN包含四层
- 第一层是输入层,接收大小为69*59*57的3D图像
- 第二层是卷积层,它使学习滤波器与输入图像卷积,并为每个滤波器产生特征图
- 第三种是池化层,它通过将每个非重叠块替换为它们的最大值来沿空间维度对输入特征图进行下采样
- 第四层是全连接层,学习之前层输出的线性特性的非线性特征
研究实际设计(6个卷积层,3个池化层,2个全连接层,使用Tanh激活函数)
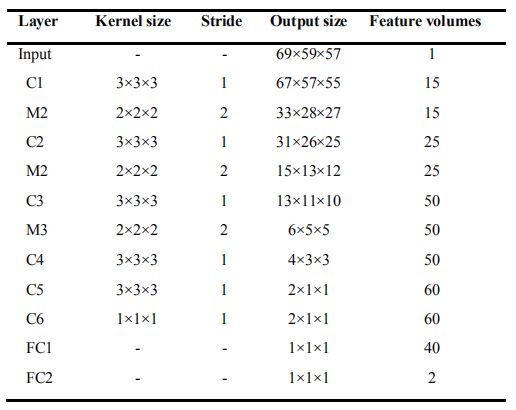
在预训练阶段,针对分类任务对每个深度CNN分别进行优化,其输出是softmax层产生的类概率分数。在反向传播时,使用Adadelta梯度下降法,同时在池化层和卷积层之间使用dropout来降低过拟合
3D卷积自动编码器的特征学习
用于提取3D图像特征的3D卷积自编码器是基于重建输入图像
在第一阶段中,使用三个卷积层
对卷积层进行逐层训练,将核大小和核数分别设置为2×2×2和16
每个层都有两个步骤:编码和解码。首先,通过将每个固定体素邻域映射到隐藏层中的向量特征空间,对输入图像进行编码。然后在输出层对原始空间进行重建,重建误差由重建图像与原始输入之间的欧几里德距离来计算。使用Adadelta梯度下降来最小化训练中的重建误差
当训练一个层时,我们使用最大池化后的隐藏层作为下一层的输入,最大池化的尺寸为2*2*2,并且前一个卷积层的训练权重设置为常数。迭代相同的步骤以生成所有三个层。同时,使用ReLu作为激活函数
三个卷积层之后的输出被展平成一个向量,作为全连接层的输入
利用训练好的权值对三个卷积层进行初始化,并通过深度监督对分类任务进行细化
最后是一个用于分类的(AD,NC)的softmax层。使用Adadelte梯度下降来微调整个过程
架构图
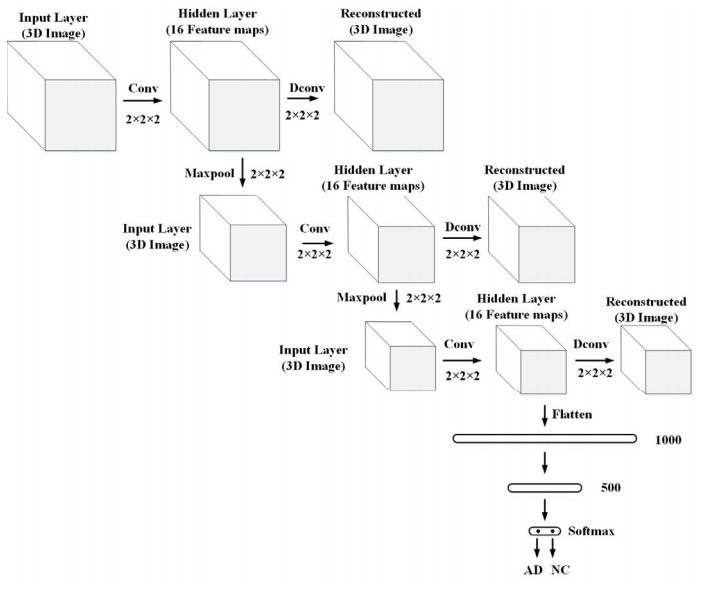
由于多尺度的三维MR图像可以捕获不同的图像信息进行分类,因此该研究通过改变图像大小来建立三个三维CAE模型。对输入的三维MR图像进行2、3、4采样,训练多尺度三维CAE模型以学习图像的各种特征。为了简单起见,建立了具有相同网络结构的多尺度CAE模型
AD集成分类
3D CNN和3D CAE捕捉了不同的图像特征,该研究又提出结合多重模型以提取3D MRI丰富特征来进行集成分类
首先3D CNN和3D CAEs都独立地训练以从脑MRI中提取特征。对于3D CNN模型,其FC1层的输出直接作为特征用于集成。对于多规模CAE模型,一个额外的全连接层被用来将输出特征进行降维(500 -> 50)
然后,多模型的特征被级联为一个新的270的向量,一个上部全连接层被添加以对特征降维。最后一个softmax层用降维后的特征进行分类
实践做法
先独立地训练CNN和CAE学习特殊的特征
之后,被训练的卷积层和池化层被固定,最后的卷积层和上部全连接层的参数被联合微调,以将特征与softmax层结合用于任务特定分类
为最后的集成分类微调最后几个层的优点有
- 通过固定前几个层,从3D CNN和3D CAE中学习的信息将被保留以提取精细的特征。通过微调后几个层,模型可以更好地适应分类任务。因此成像变量和分类任务中的信息可以被集成以帮助提高分类精度
- 与训练整个网络相比,微调最后几个层可以减少计算量和降低过拟合问题
实验
使用5折交叉验证策略来训练和测试深度学习模型以评估分类性能
该方法的优势
- 不需要在MR图像的预处理中进行分割,这将减少计算花费,和减少由于分割导致的错误
- 通过单独训练多模型,并对最后几层进行微调,以集成之前学习的不同特征,所提出的方法可以更好地适应全局分类任务,获得更好的性能
总结
本文提出了一种基于3D CNN和CAE的多模型卷积网络相结合的MR脑图像AD分类方法。通过建立3D CNNs模型和多尺度3D CAE,从MR脑图像中提取各种特征。将模型学习到的特征与上部全连通层相结合,用于AD诊断中的图像分类。在图像预处理中不需要分割
基于CNNs的AD诊断多模态分类
原文链接
摘要
本文提出用多层卷积神经网络(CNN)逐步学习和结合MRI和PET图像的多模态特征来进行AD分类
首先,构造3D CNNs来将整个大脑信息转换成每个模式的紧凑的高级特征
之后,级联一个2D CNNs以集成高级特征用于图像分类
该方法能够从MRI和PET成像数据中自动学习AD分类的一般特征。在脑图像上不需要进行刚性图像配准和分割
介绍
本文提出了一种基于级联CNNs的新的分类框架,利用MRI和PET图像学习多级、多模态的成像特征,并将它们结合起来对AD和NC对象进行分类
首先,构建一个深度3D CNN模型来逐层地、渐进地将整个脑图像变换为每个模式的更紧凑、更可区分的特征
之后,将一个高级的2DCNN级联,以结合从多个CNN学习的多模态特征用于图像分类
对每个模态图像分别学习下部3D CNN,并对上部2D卷积层进行微调,以组合用于图像分类的多模态特征
该方法能够很好地从高维成像数据中自动提取一般特征,并将多模态特征结合起来进行图像分类
架构图
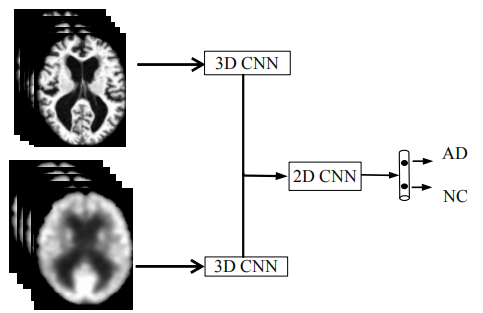
对单一模式提取特征的深度3D CNN
结构图

激活函数为tanh,使用最大池化层,在CNN结尾,加入softmax分类层,用负对数似然微调反向传播预测分类概率,4个卷积层核地个数分别为15,25,50,50。利用沙维尔均匀化初始化方法(xavier uniform initializer method)初始化三维卷积核,通过使交叉熵损失最小,利用Adadelta的反向传播来调整提出的网络的这些参数。批大小设置为64。此外,通过随机和暂时断开输入和输出神经元来实现丢弃策略,可以减少过拟合问题,提高模型的泛化能力
用于多模态分类的级联CNNs
该研究将每个单模态神经图像训练的多个深层CNN组合形成多模态分类。3D-CNN的下层可以提取鉴别特征,上层用这些特征训练用于任务特定分类。因此,所提出的多模态分类的训练包括单个CNN的预训练和用于最终分类的特定于任务的微调
首先,通过直接将全连接层的输出映射到所有类标签的概率得分来分别训练每个模态的深度CNN,提出学习二维CNN来组合多模态特征并进行最终分类。将三维CNN输出的特征映射平面化为一维,然后将MRI和PET的一维特征向量组合成二维特征映射,进行二维CNN
在二维CNN的学习过程中,初始训练后的3D CNN的前三个卷积层和池化层的参数固定,同时对最后一个卷积层和上部CNN层的参数进行联合微调,以结合多模态特征。用softmax最高级输出层进行任务特定分类
对最后几层进行微调有两个优点
- 通过固定前几层,可以保留从每个模态中学习的知识以提取特定特征。通过微调最后几层,模型可以更好地适应全局分类任务。因此,可以将图像变化和分类任务中的知识进行集成,有助于提高分类精度
- 与微调整个网络相比,微调最后几层显著降低了计算成本和减轻了过拟合问题
使用深度CNNs有三个主要优点
- 深层复杂结构可以从大量的训练图像中提取从低层到高层的特征学习
- 由于不同的神经图像具有不同的解剖和功能特征,深层CNN能够充分利用图像的空间关系,有效地学习这些局部3D滤波器,完成最终的分类任务
- 通过叠加多模态CNN,可以提取代表阿尔茨海默病状态的更复杂特征的层次结构,最终提供全局分类预测概率
实验
在特征提取和分类之前,对MRI图像进行预处理步骤。尤其在MRI中,首先采用非参数非均匀强度归一化算法对强度不均匀性进行校正,然后进行颅骨剥离和小脑切除
数据类型:MRI(T1)和FDG-PET
PET图像被处理以使来自不同系统的图像看起来类似,然后,进行强度归一化和各向同性分辨率均匀的8mm FWHM。每个PET图像的体素强度用于分类。在图像分析中去除了平均灰度值为零的体素,最终使用的图像大小为98×78×76个体素。为了减少实验所需的计算和存储成本,进一步将神经图像降采样到49×39×38个体素
使用10折交叉验证来避免影响结果的随机因素,训练、验证、测试数据比率为8:1:1
为了增加训练数据,通过移位、采样和旋转执行增强以生成训练集的附加图像
总结
本文提出了一种基于级联CNN的多模态分类方法,利用MRI和PET图像对AD与NC进行分类。两个深度CNNs建立在不同的模态图像上,以学习特定的鉴别特征。然后与一个高级CNN级联,以结合从不同模式学习的特征进行图像分类。在MRI和PET扫描上不需要进行分割和刚性图像配准

 浙公网安备 33010602011771号
浙公网安备 33010602011771号