
HBase
HBase
https://www.cnblogs.com/zhh567/p/17275625.html
用于存储数十亿行数百万列的大数据的kv数据库,基于Google的bigtable论文。Bigtable是一个稀疏的、分布式的、持久的多维排序map。该map以行键、列键、时间戳作为索引,对应的值为一个序列化的字节数组。
数据存储的逻辑架构:不同Region放在不同节点,不同store用于拆分为不同文件夹
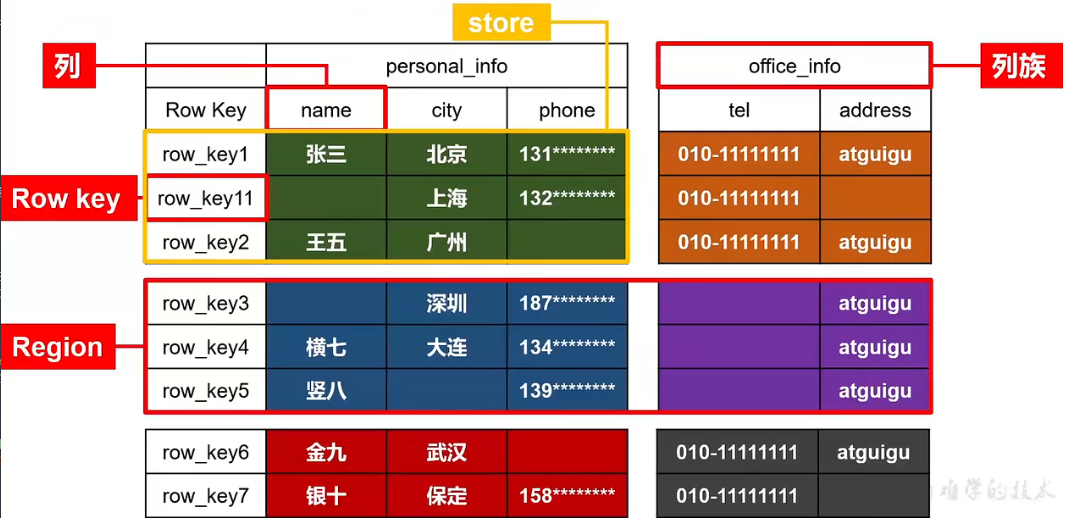
物理结构:以KV形式存储在hdfs,使用时间戳标记版本,不断追加新数据
- namespace
hbase使用namespace区分数据,默认自带habse和default两个命名空间。hbase命名空间用于存放HBase内置表,default是用户默认使用命名空间 - Table
类似RMDB的表概念,hbase定义表时只要声明列族即可,无需声明具体的列。因为数据稀疏,所以写数据时字段可动态指定 - Row
每行数据有一个RowKey和多个Column组成,按照字典序存储,查询时只能根据RowKey检索,所以RowKey设计很重要 - Column
每个列都有 Column Family 和 Column Qualifier,建表时指定列族,存储数据时再指定列名 - TimeStamp
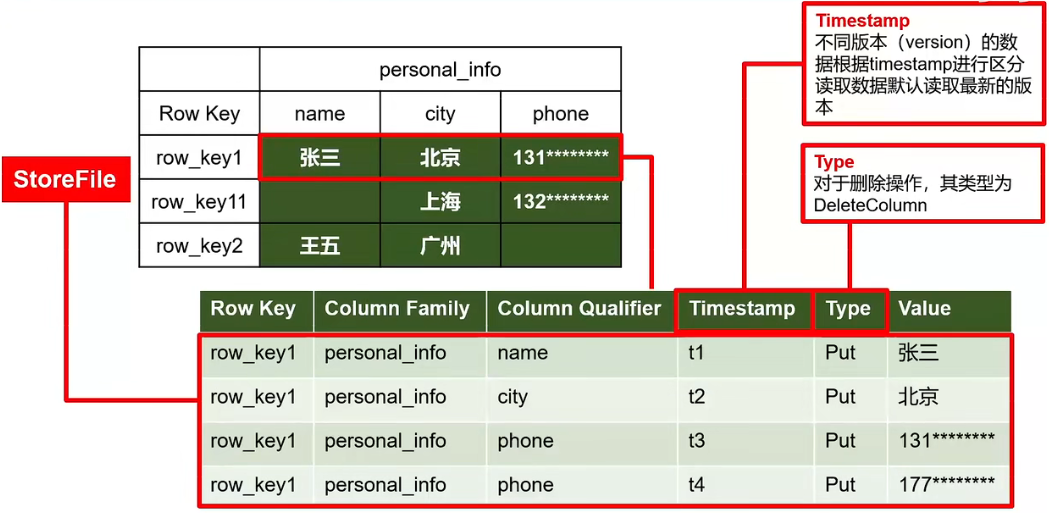
标识数据不同版本 - Cell
{rowKey, column Family: column Qualifer, timestamp}组成的唯一单元,以字节码形式存储,对应逻辑表中的一个小格
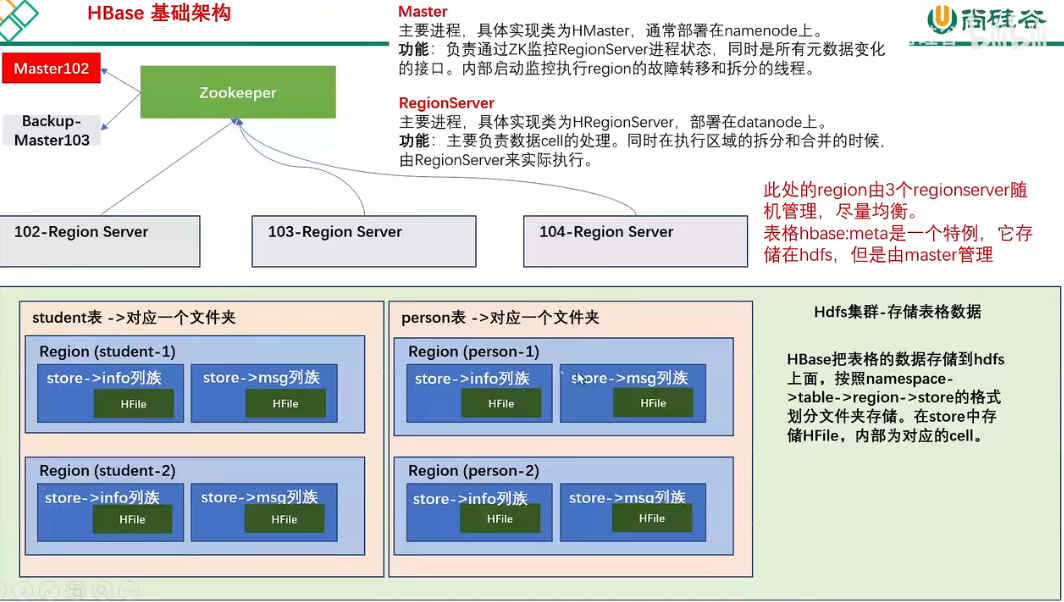
Master,实现类为HMaster:
- 监控集群中所有RegionServer
- 管理元数据表格 hbase:meta,接收用户对表格创建修改删除等命令
- 监控region是否需要负载均衡,故障转移,region拆分
- 启动多个监控线程:
- LoadBalancer:周期性监控region分布再regionServer上是否均衡
- CatalogJanitor 元数据管理器:定期检查和清理 hbase:meta 数据
- MasterProcWAL master 预写日志处理器:将master要执行的任务记录到预写日志WAL中,master宕机时让backupMaster读取并继续
Region Server,实现类为 hRegionServer:
- cell的处理
- 拆分合并 region 的实际执行者,由master监控
zookeeper:
实现master高可用、记录RegionServer信息、存储meta位置信息。对数据读写操作直接访问zookeeper,2.3版本后推出Master Registry,客户端可直接访问master以减轻zookeeper压力
安装
- 下载,解压
- 配置环境变量
export HBASE_HOME=/... - 修改配置文件 conf/hbase-env.sh
export JAVA_HOME=/usr/local/jdk8 # 手动指定JAVA export HBASE_MANAGES_ZK=false # 不使用hbase自带的zk export HBASE_PID_DIR=/usr/local/hbase-2.5.3-hadoop3/pids # 可能需要 - 修改文件 conf/hbase-site.xml
<property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>ubuntu01:2181</value> </property> <!-- 默认存储在zk的临时文件夹,重启后丢失,要指定目录 --> <property> <name>hbashe.zookeeper.property.dataDir</name> <value>/hbase</value> </property> <property> <name>hbase.rootdir</name> <value>hdfs://ubuntu01:9000/hbase</value> <!--hdfs的链接--> </property> - 修改 conf/regionservers
ubuntu01 ubuntu02 ubuntu03 - 解决HBase和Hadoop的log4j冲突问题,修改HBase jar包名,使其自动调用hadoop的
mv lib/client-facing-thirdparty/slf4j-api-1.7.33.jar lib/client-facing-thirdparty/slf4j-api-1.7.33.jar.bak - 分发到不同节点
启动停止:
bin/hbase-daemon.sh start master # 启动master节点
bin/hbase-daemon.sh start regionserver# 启动region节点
bin/start-hbase.sh # 启动整个集群
bin/stop-hbase.sh # 关闭整个集群访问 http://master:16010 看到hbase的web界面
高可用
支持HMaster的备份以实现高可用。
- 关闭HBase集群
- conf/ 下建立 backup-masters 文件
- 写入高可用 HMaster 节点hostname,注意要在hosts中配置ip
- 复制到所有节点
Shell 操作
/bin/hbase shell 进入shell界面,help '命令' 查看帮助。
# namespace
list_namespace
create_namespace 'ns01'
# ddl
create 'namespace1:table1', {NAME => 'f1', VERSIONS => 3},'f2' # 列族f1维护3个版本,列族f2默认保留一个版本
describe 'namespace1:table1'
list
alter 'ns1:t1', {NAME => 'f1', VERSION => 4} # 增加修改列族都使用覆盖的方法
alter 'ns1:t1', {METHOD => 'delete', NAME => 'f1'}
alter 'ns1:t1', 'delete' => 'f1'
disable 'ns:t1'
drop 'ns1:t1'
# DML
# 同一行数据put多次会覆盖,这也是hbase中修改数据的方法
put 'ns1:t1', 'rowKey', 'columnFamily:coumnName', 'value' [, 'timestamp'] # 建议使用默认的当前时间戳而非手动指定
# 读一行数据
get 'ns1:t1', 'rowKey'
get 'ns1:t1', 'rowKey', {COLUMN => ['columnFamily:columnName'], VERSIONS => 6}
# scan 扫描读取多行数据,不建议扫描过多数据,应当指定范围
scan 'ns1:t1', {STARTROW => '1001', STOPROW => '1002'}
# 删除一个版本,默认最新,可指定版本
delete 'ns1:t1', 'rowKey', '列族:列名'
# 删除所有版本
deleteall 'ns1:t1', 'rowKey', '列族:列名'API
代码DDL
package com.example.hbaseproject.dir01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
class Main{
/************************* 获取 hbase 单线程连接的方法,其相当重,适合一个进程共用一个 *************************/
public void fun01() throws IOException {
Configuration conf = new Configuration();
// 等于 hbase-site.xml 文件中的配置项
conf.set("hbase.zookeeper.quorum", "ubuntu01,ubuntu02,ubuntu03");
// 异步连接
// CompletableFuture<AsyncConnection> asyncConn = ConnectionFactory.createAsyncConnection();
// 默认同步连接,记得 close
try(Connection conn = ConnectionFactory.createConnection(conf);){
}
}
/************** hbase 是线程安全的,内部的Table和Admin不是线程安全的,也不建议缓存或池化二者 **************/
public static Connection connection = null;
static {
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "ubuntu01,ubuntu02,ubuntu03");
try {
// 无参的工厂方法会到 hbase-default.xml hbase-site.xml 中读取配置,那样无需在代码中配置
connection = ConnectionFactory.createConnection(conf);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static void closeConnection() throws IOException {
if (connection != null) {
connection.close();
}
}
/***************************************** DDL *****************************************/
// 链接的IO异常应当由方法调用者处理
public static void createNameSpace() throws IOException {
// 用于操作 DDL,轻量级链接,线程不安全,不推荐池化或缓存
Admin admin = connection.getAdmin();
NamespaceDescriptor.Builder builder = NamespaceDescriptor.create("namespace");
builder.addConfiguration("key", "value");
// 创建命名空间出现的问题,属于本方法自身的问题,不该抛出
try {
admin.createNamespace(builder.build());
} catch (IOException e) {
System.out.println("log : 命名空间已存在");
e.printStackTrace();
}
admin.close();
}
public static boolean isTableExits(String namespace, String tableName) throws IOException {
Admin admin = connection.getAdmin();
boolean exists = false;
try {
exists = admin.tableExists(TableName.valueOf(namespace, tableName));
} catch (IOException e) {
throw new RuntimeException(e);
}
admin.close();
return exists;
}
public static void createTable() throws IOException {
Admin admin = connection.getAdmin();
// 创建对列族的描述
ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder =
ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("columnFamily01"));
columnFamilyDescriptorBuilder.setMaxVersions(3);
ColumnFamilyDescriptor columnFamilyDescriptor = columnFamilyDescriptorBuilder.build();
// 创建对表的描述
// 这种方式得到的是一个新的表描述,没有已存在表的信息,不能用于修改
TableDescriptorBuilder tableDescriptorBuilder =
TableDescriptorBuilder.newBuilder(TableName.valueOf("tablename"));
tableDescriptorBuilder.setColumnFamily(columnFamilyDescriptor);
TableDescriptor tableDescriptor = tableDescriptorBuilder.build();
try {
admin.createTable(tableDescriptor);
} catch (IOException e) {
throw new RuntimeException(e);
}
admin.close();
}
public static void modifyTable() throws IOException {
Admin admin = connection.getAdmin();
// 通过这个方法获得已存在的表的描述
TableDescriptor existingTable = admin.getDescriptor(TableName.valueOf("namespace", "ExistingTable"));
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(existingTable);
// 新的列族
ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder =
ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("newColumnFamily"));
ColumnFamilyDescriptor newColumnFamilyDescriptor = columnFamilyDescriptorBuilder.build();
// 注意:没有在这一行中指定的列族都会被设置为初始值。如果想原有的值不变,需要从 existingTable 获取旧的列并插入
tableDescriptorBuilder.modifyColumnFamily(newColumnFamilyDescriptor);
admin.close();
}
// TableName tableName = TableName.valueOf("namespace", "table");
// admin.disable(tableName);
// admin.deleteTable(tableName);
}代码 DML
代码操作数据
package com.example.hbaseproject.dir01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.CompareOperator;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.ColumnValueFilter;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.Arrays;
class Main{
public static Connection connection = null;
static {
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "ubuntu01,ubuntu02,ubuntu03");
try {
// 无参的工厂方法会到 hbase-default.xml hbase-site.xml 中读取配置,那样无需在代码中配置
connection = ConnectionFactory.createConnection(conf);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static void putCell(String namespace, String tableName, String rowKey,
String columnFamily, String columnName, String value) throws IOException {
Table table = connection.getTable(TableName.valueOf(namespace, tableName));
// 创建一个要插入的数据单元
Put cell = new Put(Bytes.toBytes(rowKey));
// 指定命名空间、列族、列名等
cell.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(columnName), Bytes.toBytes(value));
try {
table.put(cell);
} catch (IOException e) {
e.printStackTrace();
}
table.close();
}
public static Cell[] getCell(String namespace, String tableName, String rowKey,
String columnFamily, String columnName) throws IOException {
Table table = connection.getTable(TableName.valueOf(namespace, tableName));
// 创建要查询的行对象
Get get = new Get(Bytes.toBytes(rowKey));
// 添加指定列
get.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(columnName));
// 指定读取所有的版本
get.readAllVersions();
Cell[] cells = null;
try {
Result result = table.get(get);
// 获得cell数组
cells = result.rawCells();
Arrays.stream(cells).forEach(cell -> {
// 真正的数据包裹在cell内部
String value = new String(CellUtil.cloneValue(cell));
System.out.println("value = " + value);
});
} catch (IOException e) {
e.printStackTrace();
}
table.close();
return cells;
}
public static void scanRows(String namespace, String tableName,
String startRow, String stopRow,
String columnFamily, String columnQualifier, String columnValue) throws IOException {
Table table = connection.getTable(TableName.valueOf(namespace, tableName));
// 得到 scan 对象,默认扫描整张表
Scan scan = new Scan();
// 过滤行
scan.withStartRow(Bytes.toBytes(startRow) /*, true 默认包含当前这条*/);
scan.withStopRow(Bytes.toBytes(stopRow) /*,false 默认不包含此条*/);
// 过滤列
FilterList filterList = new FilterList();
// 1. 查询结果只保留指定列的数据
ColumnValueFilter columnValueFilter = new ColumnValueFilter(Bytes.toBytes(columnFamily),
Bytes.toBytes(columnQualifier), CompareOperator.EQUAL, Bytes.toBytes(columnValue));
// 2. 查询结果保留匹配的整行数据,结果也会保留没有当前列的数据
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(Bytes.toBytes(columnFamily),
Bytes.toBytes(columnQualifier), CompareOperator.EQUAL, Bytes.toBytes(columnValue));
// filterList.addFilter(columnValueFilter);
filterList.addFilter(singleColumnValueFilter);
scan.setFilter(filterList);
try {
// 读取多行数据
// result 是一行数据,包含一个 cell 数组
// ResultScanner 是多行数据,包含一个 result 数组
ResultScanner resultScanner = table.getScanner(scan);
resultScanner.forEach(result -> {
Arrays.stream(result.rawCells()).forEach(cell -> {
System.out.printf("%s - %s:%s -%s",
new String(CellUtil.cloneRow(cell)),
new String(CellUtil.cloneFamily(cell)),
new String(CellUtil.cloneQualifier(cell)),
new String(CellUtil.cloneValue(cell)));
});
System.out.println();
});
} catch (IOException e) {
e.printStackTrace();
}
}
public static void deleteCell(String namespace, String tableName, String rowKey,
String columnFamily, String columnQualifier) throws IOException {
Table table = connection.getTable(TableName.valueOf(namespace, tableName));
Delete delete = new Delete(Bytes.toBytes(rowKey));
// 对应命令 delete,删除一个版本
// delete.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(columnQualifier));
// 对应命令 deleteall,删除所有版本
delete.addColumns(Bytes.toBytes(columnFamily), Bytes.toBytes(columnQualifier));
try {
table.delete(delete);
} catch (IOException e) {
throw new RuntimeException(e);
}
table.close();
}
}Master 架构
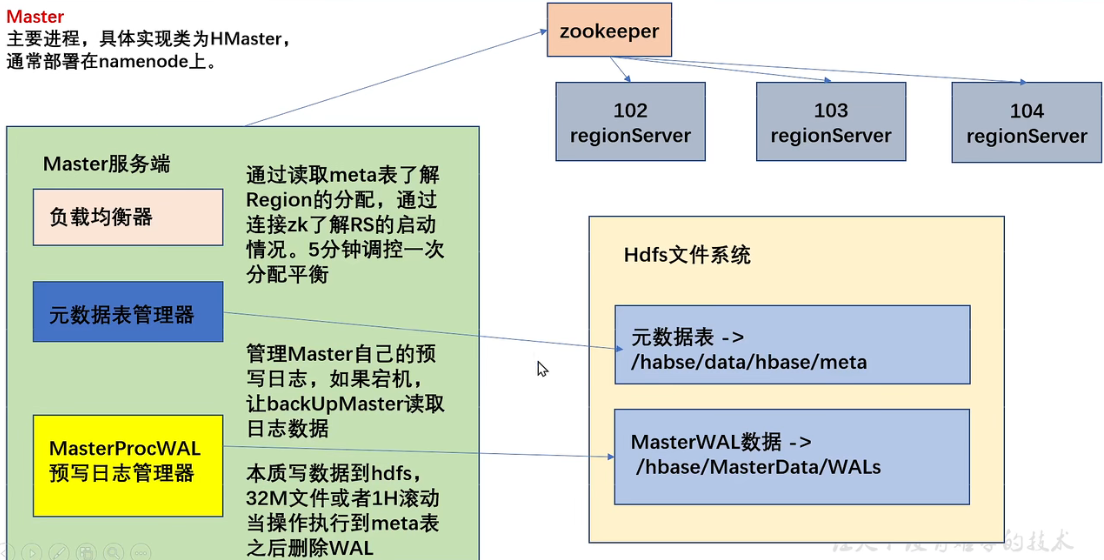
客户端操作元数据时才会连接master,读写数据时直接连接zookeeper读取目录/hbase/meta-region-server 节点信息,记录meta表格位置。直接读取无需访问master,这样减轻master压力。master专注meta表的写操作,客户端直接读取meta表。
HBase 2.3 提供了Master Registry,客户端可直接访问master读取meta表信息,将压力从zookeeper转移到了master。
Region Server
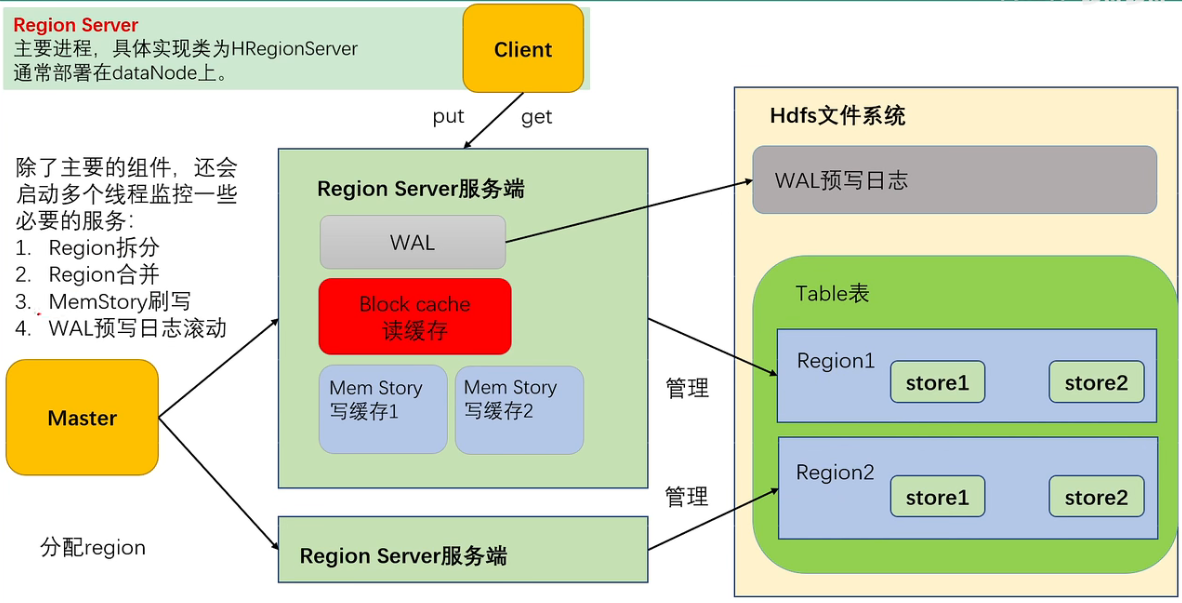
写流程
在写之前先创建连接,期间创建缓存这个步骤消耗巨大。
- 想zookeeper发请求
- 从zk获取meta表存在哪
- 从某个 region server 读取meta表
- 将读取的meta表保存在连接中
- meta表变化时更新缓存
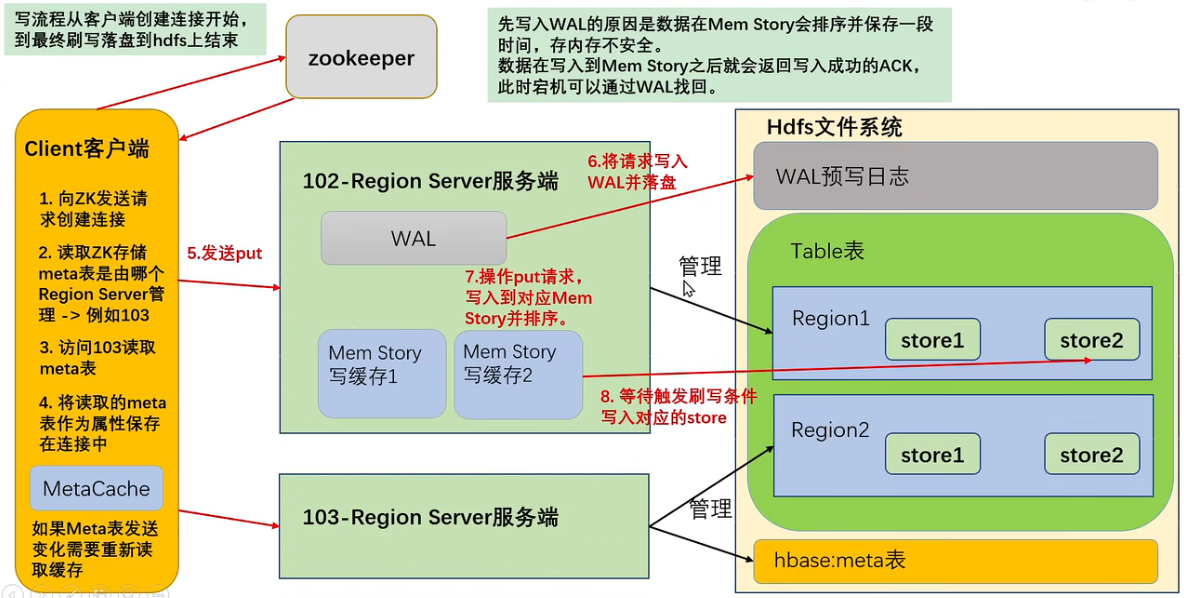
从缓存的meta表中得到要写数据的位置,如果写入失败说明 region server 发生变化,需要更新meta表缓存。数据先写到磁盘上的WAL中,在放入内存的写缓存进行排序。满足一定条件时写入hdfs,生成一个新的文件。HFile单文件内有序(在写缓存中排序了),文件间无序。
MemStore Flush
多个线程控制,条件相互独立。
- 当memstore大小达到 hbase.hregion.memstore.flush.size(默认128M,即hdfs中块大小),其所在region对应的所有memstore都会刷写。同时刷写多个region的目的是尽量使不同列的同一行数据同时写入。当某次检查时发现memstore大小达到阈值的指定倍数时阻止继续向memstore写,并持久化到HFile
- MemStoreFlusher线程通过 LOWER_MARK 和 HIGH_MARK 控制,避免写缓存使用过多内存照成OOM
- 低水位:java_heapsize * memstore占内存比率(默认0.4)* 低水位(默认0.95)
当写缓存memstore总大小达到这个值时也会触发刷写,如果存在过多的列族即memstore数量过多,那么可能每次刷写到内存时单个memstore的大小不到128M - 高水位:java_heapsize * memstore占内存比率(默认0.4)
阻止向所有memstore内写数据
- 低水位:java_heapsize * memstore占内存比率(默认0.4)* 低水位(默认0.95)
- 为防止数据长时间停留在内存,默认5min一次自动刷新
- WAL堆积一定长度后刷写(已废弃),刷写到磁盘后对应WAL会删除
HFile 结构
HFile 是存在HDFS上每个store目录下实际存储数据的文件,包括数据本身(KV对)、元数据信息、文件信息、数据索引、元数据索引、固定长度尾部信息(记录文件修改情况)。
- KV对按照块大小(默认64K)保存在文件
KV内容包括:- key长度
- key的值
- 列族长度
- 列族
- 列名
- 时间戳(默认系统时间)
- keytype:Put
- 块越多,数据索引就越多
- 每个HFile维护一个布隆过滤器,读取时判断要get的key是否在HFile中
读流程
优先访问BlockCache,读缓存保存了元数据用于快速查找、通过尾部信息判断数据是否修改。无论缓存是否有数据(判断数据是否过期),都需要读写缓存和store中的文件。读取数据的多个版本,用高版本覆盖低版本。
GC主要清理的就是读缓存的数据
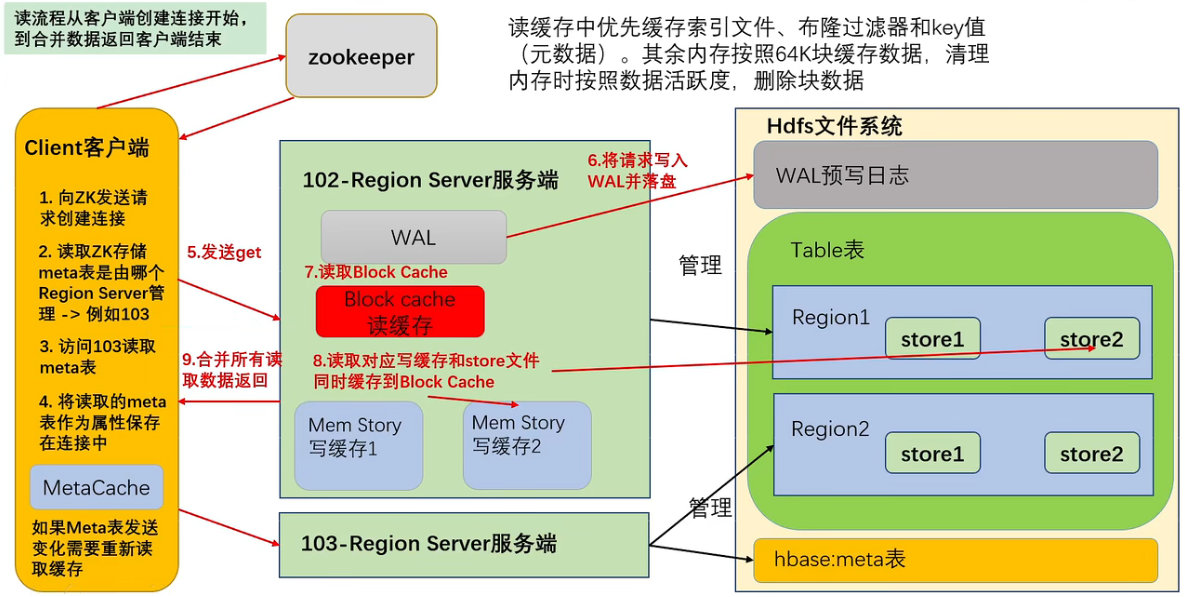
优化合并读取数据
每次读数据都要读三个位置的数据,然后版本合并,效率很低,需要优化:
- HFile带有索引文件,读取对应RowKey数据会更快
- Block Cache 缓存之前读取的内容和元数据,如果HFile尾信息表示没有变化,则无需再次读取
- 使用布隆过滤器快速过滤当前HFile不存在需要读取的RowKey,避免读取文件
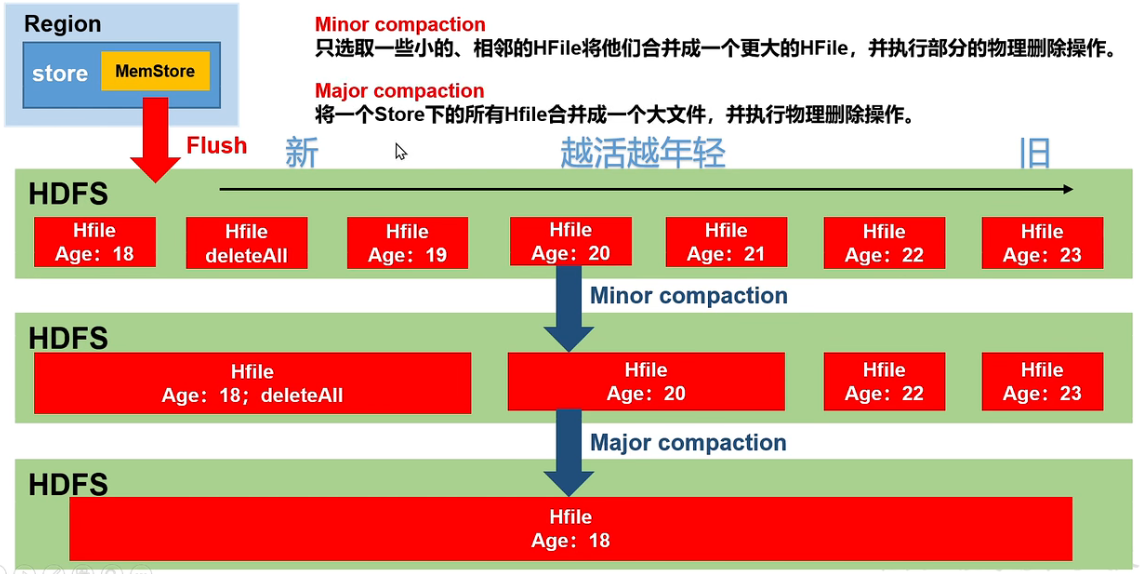
文件合并
每次刷写生成一个新的HFile,过多的文件不方便读取,所以需要 storeFile Compaction。分两种:
- Minor Compaction
将临近的若干小HFile合并成一个较大HFile,并清理部分过期和删除的数据 - Major Compaction
将一个store下所有HFile合并成一个大HFile,并清理部分过期和删除的数据,由hbase.hregion.majorcompaction控制,默认7天
预分区
切分Region,避免单个Region中数据量过大
预分区(自定义分区)
每个region维护着startRowKey和endRowKey
# 在创建表时指定切分的点,生成4个区间
create 'staff1', 'info', SPLITS => ['1000', '2000', '3000']
# 在文件中指定切分点
create 'staff1', 'info', SPLITS_FILE => 'splits.txt'
#文件内容:
#aaaa
#bbbb
#cccc
# 使用16进制拆分为15个分区
create 'staff2', 'info', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}系统分区
系统默认启动,由HRegionServer完成。操作前要通过zk汇报给master,修改对应的Meta表信息,添加两列 info:splitA 和 info:splitB ,之后在hdfs上拆分文件。此时创建文件的引用,不会移动数据。刚完成拆分时两个Region都由原RegionServer管理,之后汇报给master让其写入到meta表。等下一次触发负载均衡机制时,才会修改Region的管理服务者,等到下一次压缩时才会实际移动文件。
RowKey 设计
HBase有两种使用方法:1.当做关系数据库使用(不推荐) 2.作为一个TSDB(推荐)
rowKey是数据的唯一标识,决定了数据位于哪一个预分区的区间,rowKey的设计就是为了让数据尽可能均匀地分布在不同region中防止数据倾斜。常用生成方案:
- 随机数,hash
- 时间戳反转,用一个最大数字减去时间戳,这样越新的数据得到的rowKey越小,排序越靠前
- 字符串拼接
案例
使用hbase存储,要能通过api完成一下两个需求:
- 统计张三2023年4月消费总额
- 统计所有人2023年4月消费总额
使用扫描全表+过滤的方法并不高效,应当使用scan直接得到结果。数据格式:
user date pay
zhangsan 2023-04-22 09:16:00 100
zhangsan 2023-04-30 09:16:00 80
zhangsanfeng 2023-04-30 09:16:00 80
lisi 2021-04-30 09:16:00 50
wangwu 2022-04-30 09:16:00 70需求一:
数据中zhangsan和zhangsanfeng的长度不同,hbase提供了asiica为1的填充字符,其不可打印,用^A表示。使^A加姓名长度等于定长^A^A^A^AUsernameDate(yyyy-MM-dd hh:mm:ss ms) 即可实现需求一
scan扫描
startrow => ^A^Azhangsan202304 # 空字符的asiica的值小于字符-
stoprow => ^A^Azhangsan202304. # 字符.的asiica值大于-需求二:
前一种设计只能满足一种需求,如将date放在username前即可实现按时间划分数据。
解决方法:可穷举的放在前面。年月可穷举,而姓名、具体时间都不可,所以得到格式:Date(yyyy-MM)UsernameDate(-dd hh:mm:ss ms)
得到结果:
需求一:
scan:startRow => 2023-04^A^A^A^Azhangsan
stopRow => 2023-04^A^A^A^Azhangsan.
需求二:
scan:startRow => 2023-04
stopRow => 2023-04.预分区优化
预分区的分区号同样遵守scan的扫描原则,在rowKey前添加简单数字组成的前缀。使用用户名和月份组合计算hash得到分区号。单独使用用户名可能造成数据倾斜。
分区:
startKey stopKey
001
001 002
002 003
...
119 120分区号为:hash(username+date(MM)) % 120数字要添加前缀0以保证对应字符串长度为3
此时再考虑两个需求:
需求一:
通过用户名和月份得到分区号,拼接上原rowKey得到区间
分区号 => hash(zhangsan+04) % 120 得到分区号 015
scan:startRow => 0152023-04^A^A^A^Azhangsan
stopRow => 0152023-04^A^A^A^Azhangsan.需求二:
每个分区都有4月的数据,无法精准扫描,只能每个分区都去扫描
为此,可将分区和月份进行绑定
分区 000~009 存储1月份数据
分区 010~019 存储2月份数据
分区 020~029 存储3月份数据
...
分区 110~119 存储12月份数据将分区号的计算方式改为 hash(username+MM) % 10 + (MM-1)*10 如此在处理需求二时,只要扫描 030~039 分区的数据即可。
Phoenix
HBase的开源SQL接口,用 JDBC 代替原生客户端API,下载解压后将内部 phoenix-server-hbase-xxx.jar 放到集群所有节点的 HBASE_HOME/lib 目录下,然后在某个节点上配置环境变量,之后重启HBase:
export PHOENIX_HOME=/usr/local/phoenix
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export PATH=$PATH:$PHOENIX_HOME/bin运行方法:$PHOENIX_HOME/bin/sqlline.py zkserver01,zkserver02,zkserver03:2181,如果报错可尝试删除home目录下历史记录 .sqlline/ 目录
语法:https://phoenix.apache.org/language/index.html
注意:没有双引号的表名自动转为大写,默认对列名进行编码使用更短的字符串存储
全局索引
使用phoenix的二级索引需要添加 hbase-site.xml 配置
<property>
<name>hbase.regionserver.wal.code</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCode</value>
</property>创建全局索引时会在HBase中创建一张新表,适用于读多写少的场景。写数据时会产生大量消耗,因为索引表也要更新,而且索引表时分布在不同数据节点上的,跨节点的数据传输带来了较大的性能消耗。
CREATE INDEX my_index ON my_table(my_col) 使用explain执行查询计划可看见索引是否起效
但如果查询的字段不是索引字段,全局索引表不会被使用,也不会带来性能提升。可通过包含索引或本地索引解决。
包含索引
携带了其他字段的全局索引,本质还是全局索引。
create index my_index on student1(age) include (addr);
本地索引
适用于写操作频繁的场景。索引数据和数据表存放在同一张表同一个Region,避免了写操作往不同服务器索引表写索引的开销。
create local index my_index on my_table(my_column);
Hive 集成 HBase
推荐使用phoenix和hbase搭配,但当HBase上已经有大量数据时,phoenix不适合复杂的SQL处理,可使用hive映射hbase的表格编写HQL进行分析处理。
在 hive-site.xml 中添加 zookeeper 的属性
<property>
<name>hive.zookeeper.quorem</name>
<value>zkserver1,zkserver2,zkserver3</value>
</property>
<property>
<name>hive.zookeeper.client.prot</name>
<value>2181</value>
</property>