
Kafka
Kafka
https://www.cnblogs.com/zhh567/p/17301143.html
磁盘顺序顺序读写速度超过了内存随机读写速度
https://spring.io/projects/spring-kafka
kafka 组件:
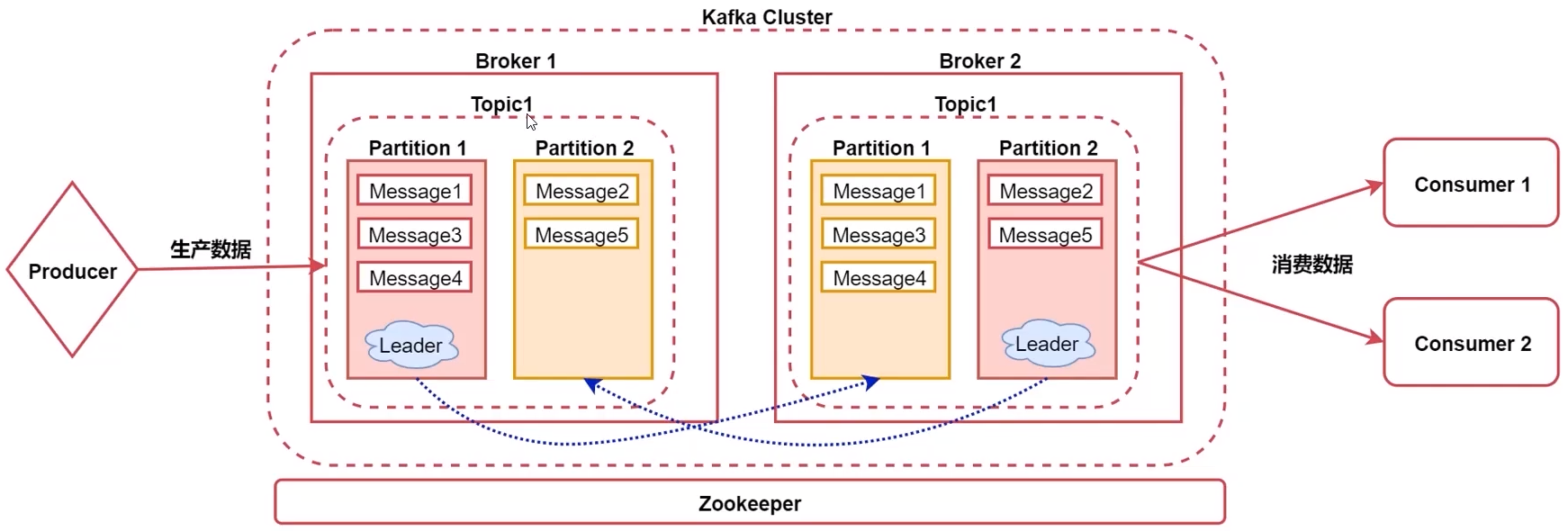
- Broker 一个节点就是一个Broker
- Topic 处理消息的不同分类,是一个逻辑概念
- Partition 是Topic的物理分组,提供容错,创建Topic时可指定副本数
- message 通信的基本单位
ZooKeeper 安装
监听 2181 端口
单机安装:下载解压即可,在conf目录中的zoo.cfg可配置数据目录dataDir,然后 bin/zkServer.sh start 启动,jps下的 QuorumPeerMain 进程就是zk进程。bin/zkServer.sh status 查看运行状态。bin/zkCli.sh 连接到zk的客户端
集群安装
- 修改配置文件:
# 指定集群中3个节点,2888为节点通信时端口,2888为选举时使用端口 server.0=hostname01:2888:3888 server.1=hostname02:2888:3888 server.2=hostname03:2888:3888 - dataDir目录中创建文件 myid 然后向其中写入对应id,hostname01写入0,hostname02写入1
- 在每台机器上分别执行
bin/zkServer.sh start启动
Kafka 安装
默认监听 9092 端口
单机安装
下载解压,修改 config/server.properites
# 存储kafka中的核心数据,不应放在tmp目录
log.dirs=/tmp/kafka-logs
# 指定连接的zookeeper地址
zookeeper.connect=localhost:2181通过 bin/kafka-server-start.sh -daemon config/server.properties 在后台启动,jps可见Kafka进程
集群部署
修改配置文件
borker.id=0 # 从0开始,每个节点一个id
log.dirs=/data/kafka-logs # 会存储相当大规模的数据
zookeeper.connect=hostname01:2182,hostname02:2181 # zk地址,集群和单机都可以每个机器上执行 bin/kafka-server-start.sh -daemon config/server.properties 以启动
简单操作
- 副本数不能大于集群中Broker数量
# 创建Topic ,旧版要指定zookeeper地址 bin/kafka-topics.sh --create --zookeeper localhost:2181 --partitions 2 # 分区数 --replication-factor 2 # 副本数 --topic MyTopic # kafka3.0 后直接指定kafka地址即可 bin/kafka-topics.sh --create --bootstrap-server KafkaServer:9097 # <== 直接指定 kafka 地址 --partitions 2 # 分区数 --replication-factor 2 # 副本数 --topic MyTopic -
# 查看所有Topic bin/kafka-topics.sh --list --bootstrap localhost:9092 # 旧版 --zookeeper localhost:2181 # 查看某个 Topic 信息 bin/kafka-topics.sh --describe --bootstrap localhost:9092 # 旧版 --zookeeper localhost:2181 --topic MyTopic # 结果: Topic: hello TopicId: RInbMZTIQ72inAVIHQkSjw PartitionCount: 2 ReplicationFactor: 2 Configs: Topic: hello Partition: 0 Leader: 0 Replicas: 0,2 Isr: 0,2 Topic: hello Partition: 1 Leader: 2(leader副本所在Borker的id) Replicas: 2,1(此分区副本所在的borker id) Isr: 2,1(正常提供服务的副本id) - 修改topic,只能增加partition数量,不能减少
bin/kafka-topics.sh --alter --bootstrap-server localhost:9092 --pattions 3 --topic hello - 删除Topic,操作不可逆
配置delete.topic.enable设置真正删除还是仅仅添加删除标识的伪删除
bin/kafka-topics.sh --delete --bootstrap-server localhost:9092 --topic hello - 生产者 消费者
# 生产者,执行后进入交互界面,可输入字符串消息到MQ bin/kafka-console-producer.sh --bootstrap-server localhost:9092,node2:9092 # 旧版使用 --broker-list --topic hello # 消费者,默认消费最新数据, bin/kafka-console-consumer.sh --bootstrap-server ubuntu01:9092 --topic hello --from-beginning # 声明获取消费者启动前的数据
扩展内容
Broker
通过 config/server.properties 文件配置
# Log Flush Policy 数据flush到磁盘的时机
log.flush.interval.messages=99999999 # 分区的消息达到这个数目就flush进磁盘
log.flush.interval.ms=999999 # 间隔多少ms后写入磁盘
# Log Retention Policy 数据保存周期,默认7天
log.retention.hours= # 达到指定时间就删除日志
log.retention.bytes= # 达到指定大小就删除日志
log.retention.check.interval= # 检测删除条件的时间间隔Producer
Kafka如何保证数据不丢?通过producer的acks机制,设置为all即可
# partitioner 根据用户设置计算发送到哪个分区,默认随机
# 数据通讯方式:同步 or 异步
acks= 1
1 需要Leader节点回复收到消息
all/-1 所有副本回复收到消息
0 无需任何节点回复(异步)Consumer
# 某个消费者都属于一个消费者组,可通过 group.id 指定
# 组内消费
组内消费者消费不同分区,一个分区不会被多个消费者消费。建议一个组内消费者的数量不大于分区数,否则会有消费者得不到数据
# 组间消费
多个消费者组消费相同的Topic消息且互不影响
# 一般消费数据流程,先根据group.id到kafka中查找之前保存的offset信息
# * 如果找到,则根据上次消费的记录继续消费
# * 若没有或offset对应数据已不存在(超时数据记录被删除,无法接着上次继续)此时根据这个配置设定消费逻辑,否则此配置无用
auto.offset.reset=latest
#earliest 从头消费
#latest 从最新数据消费,默认,使用实时场景
#none 没找到就抛异常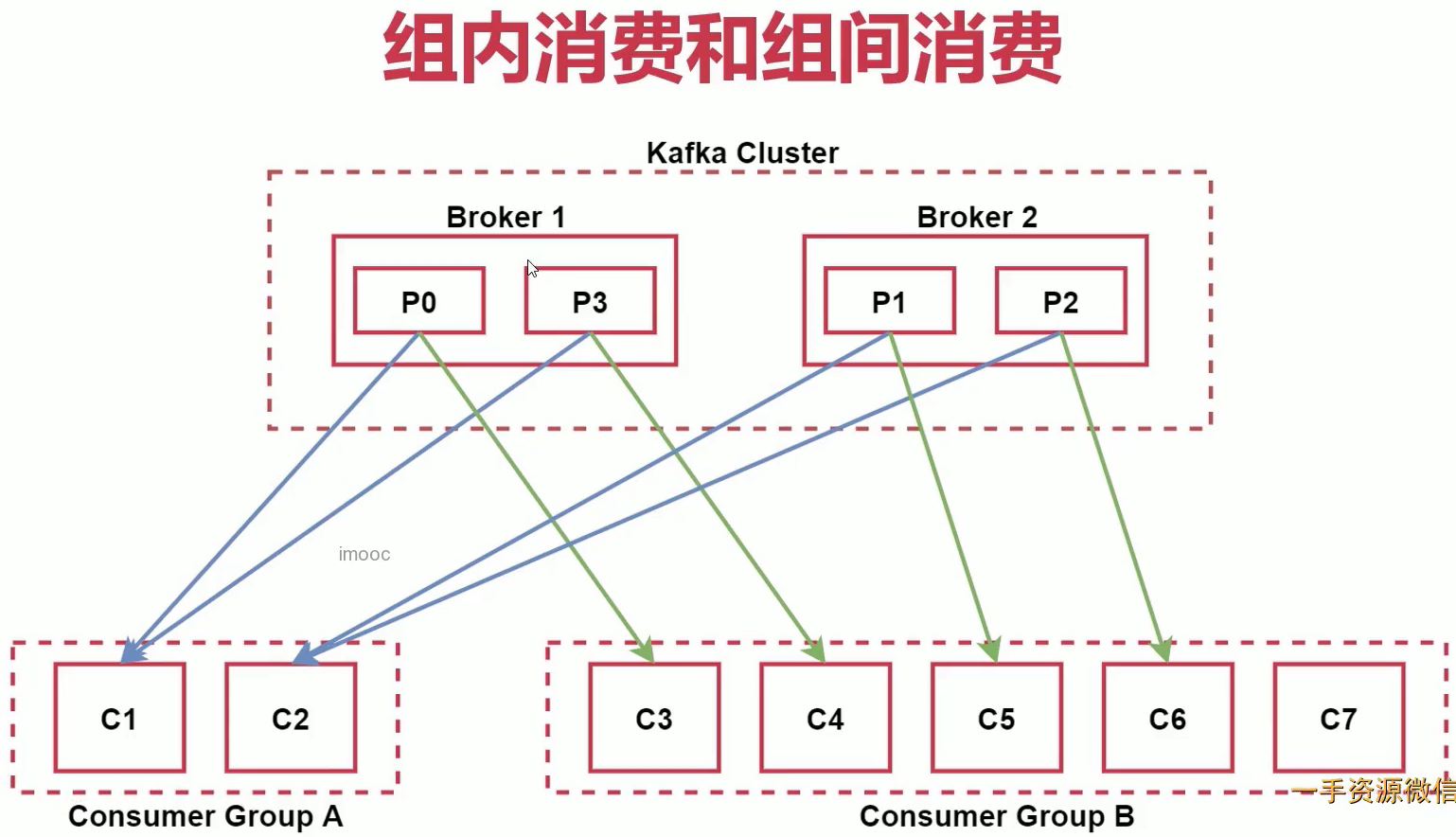
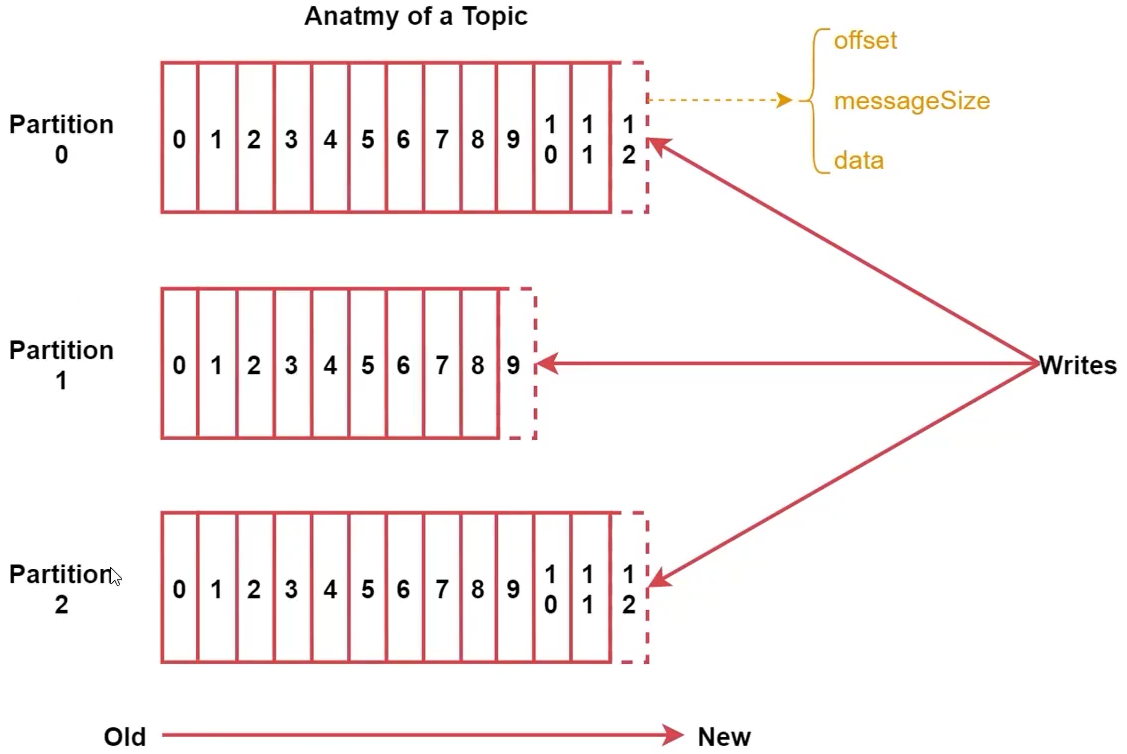
Topic Partition
- 每个Partition在物理存储上都是Append Log文件,消息在Log的位置被称为Offset
- Partition越多就可容纳越多的Consumer,可有效提升并发消费
- 业务类型增加要增加Topic,数据量增大要增加Partition
每个Message包含3个属性:
- offset,类型为long,表示消息在Partition中起始位置
- MessageSize,类型int32,消息的字节大小
- data,类型bytes,表示message具体内容
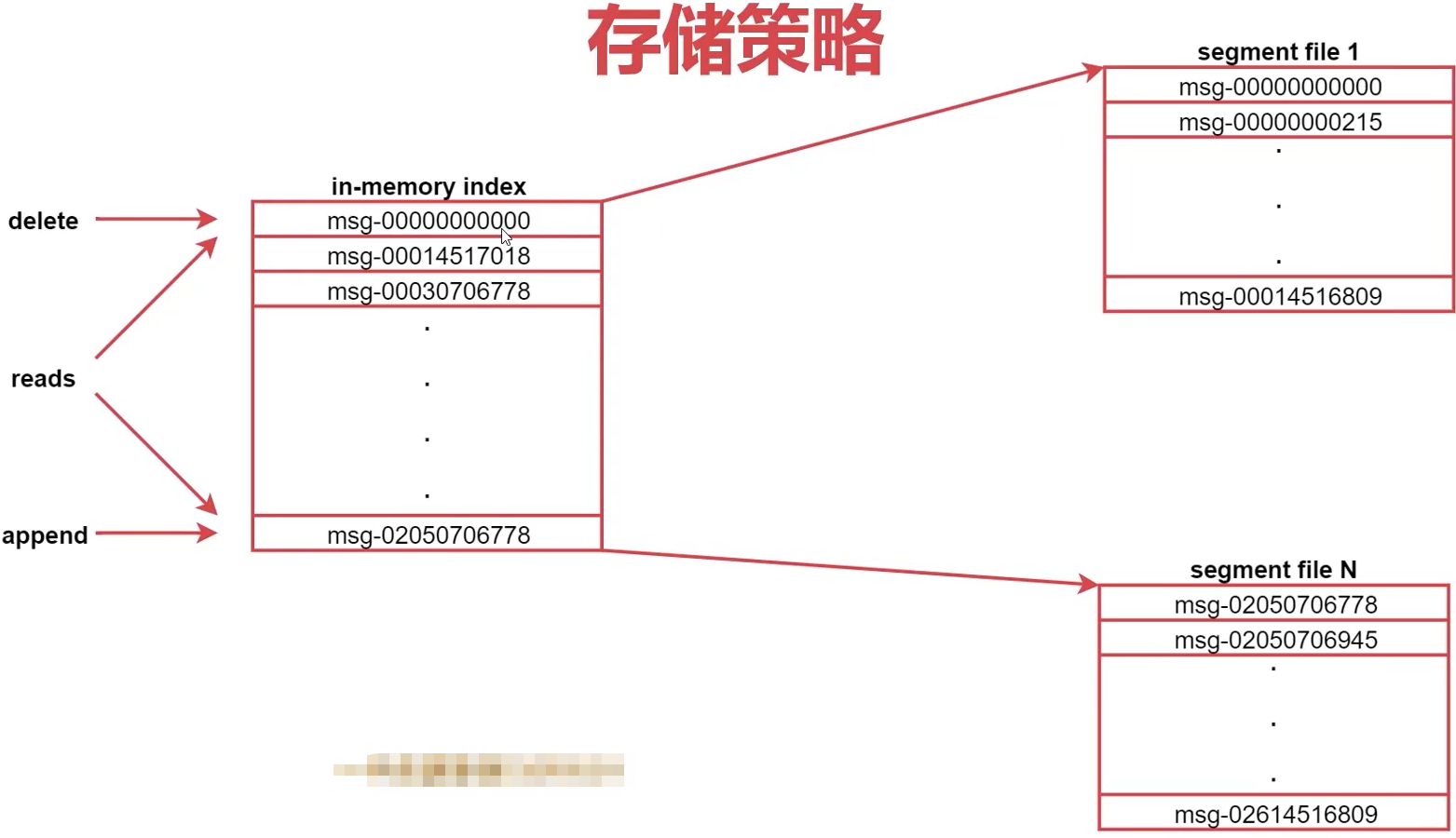
存储策略
每个Topic包含1~多个Partition,每个Partition存储一部分Message。每条Message包含3部分,offset相当于消息的唯一id
如何找到id?分段 + 索引
如何查看offset?
# 查看消费者分组
kafka-consumer-groups.sh
--bootstrap-server localhost:9092
--list
# 查看某个消费者组的信息,
# < Group, Topic, Partition,
# Current Offset 当前消费到哪个位置,
# Log end offset当前分区中最大的偏移量,
# LAG 未消费消息数量 >
kafka-consumer-groups.sh
--bootstrap-server localhost:9092
--describe
--group ConsumerGroupConsumer 消费顺序
消费一个partition时,消费顺序和生产顺序一致
一个消费者消费多个partition时,只保障一个partiton内的消费顺序是有序的,分区间顺序不保证
使用单一partition可保证消费顺序,但是kafka的高吞吐量依赖于partition实现
Kafka 三种语义
针对消费者实现3种:
- 至少一次:关闭autocommit,使用手动commit
- 至多一次:打开 enable.auto.commit 即可实现
- 仅一次:关闭autocommit,在代码中自己维护kafka的offset,使用事务实现消息的处理和消费的commit
参数调优
JVM
默认1G内存,造成大量GC。使用 jstat -gcutil pid 1000 查看GC信息,如果FGC频繁则需要更大内存。
Replication
# partition副本间socket通信的超时时间,如果网络条件不好可适当调大,否则可能误判为网络故障
replica.socket.timeout.ms=60000
# 指定时间未向leader发送请求、未从leader同步完数据,会将其从lsr中移除。可适当调大
replica.lag.time.max.ms=50000Topic 命名技巧
命名建议:action_r2p9,r2表示副本因子是2,p9表示分区数是9。缺点是增加了partition数量后具体数量与命名中不一致。建议开始时就预测好,大数据量通常设置40~50个partition,小数据量通常设置5~10个partition。
实战组件集成
Flume + Kafka
- Flume 采集数据写入kafka,使用 KafkaSink
- Flume 从kafka消费数据备份到HDFS,使用 KafkaSource
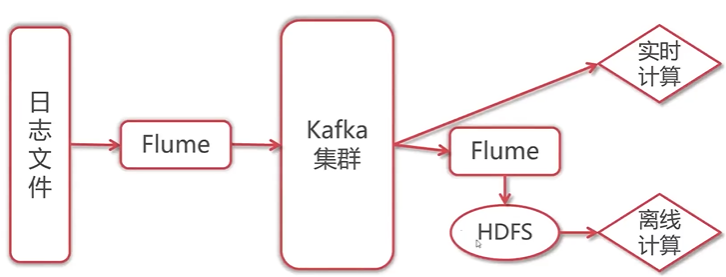
kafka_to_hdfs
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置 channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置 source
a1.sources.r1.type = org.apache.flume.sink.kafka.KafkaSource
a1.sources.r1.channels = c1
a1.sources.r1.batchSize = 1 # 一次向channel中写入的最大数据量,不可超过capacity和transactionCapacity
a1.sources.r1.batchDurationMillis = 2000 # 多长时间向channel写一次数据
a1.sources.r1.kafka.bootstrap.servers = server01:9092,server02:9092
a1.sources.r1.kafka.topics = test01_r2p3,test02_r3p6
# a1.sources.r1.kafka.topics.regex = ^topic[0-9]$
a1.sources.r1.kafka.consumer.group.id = flume-group
# 配置 sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs:///ip:port/from_kafka
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600Kafka 集群平滑升级
服务不停止情况下进行版本升级。注意:新旧版本的 log.dirs 配置一定要一样,否则读取不到旧数据
- stop 集群中一个旧节点,同时查看集群是否识别到副本下线
- 再在当前节点启动新版本Kafka,同时查看集群信息
- 确认节点可正常接收和发送数据后,不断重复操作,直到全部替换
