
大数据经典论文解读 - Spark
Spark
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
可看作一个支持多轮迭代的MapReduce模型,但是引入了 RDD 这样的函数式对象的数据集概念。Spark的多轮迭代中无需反复读写磁盘,而是直接在内存中操作。
- RDD 是什么,怎么优化分布式数据处理的,与什么观念比较像?
使用硬盘“容错”
MapReduce中Map的输出结果会存在硬盘,Reduce函数从Map所在节点拉取所需数据,再写入本地。再通过外部排序,将数据分组最后排序完成分组,通过Reduce处理。任何一个中间环节都要读写硬盘。
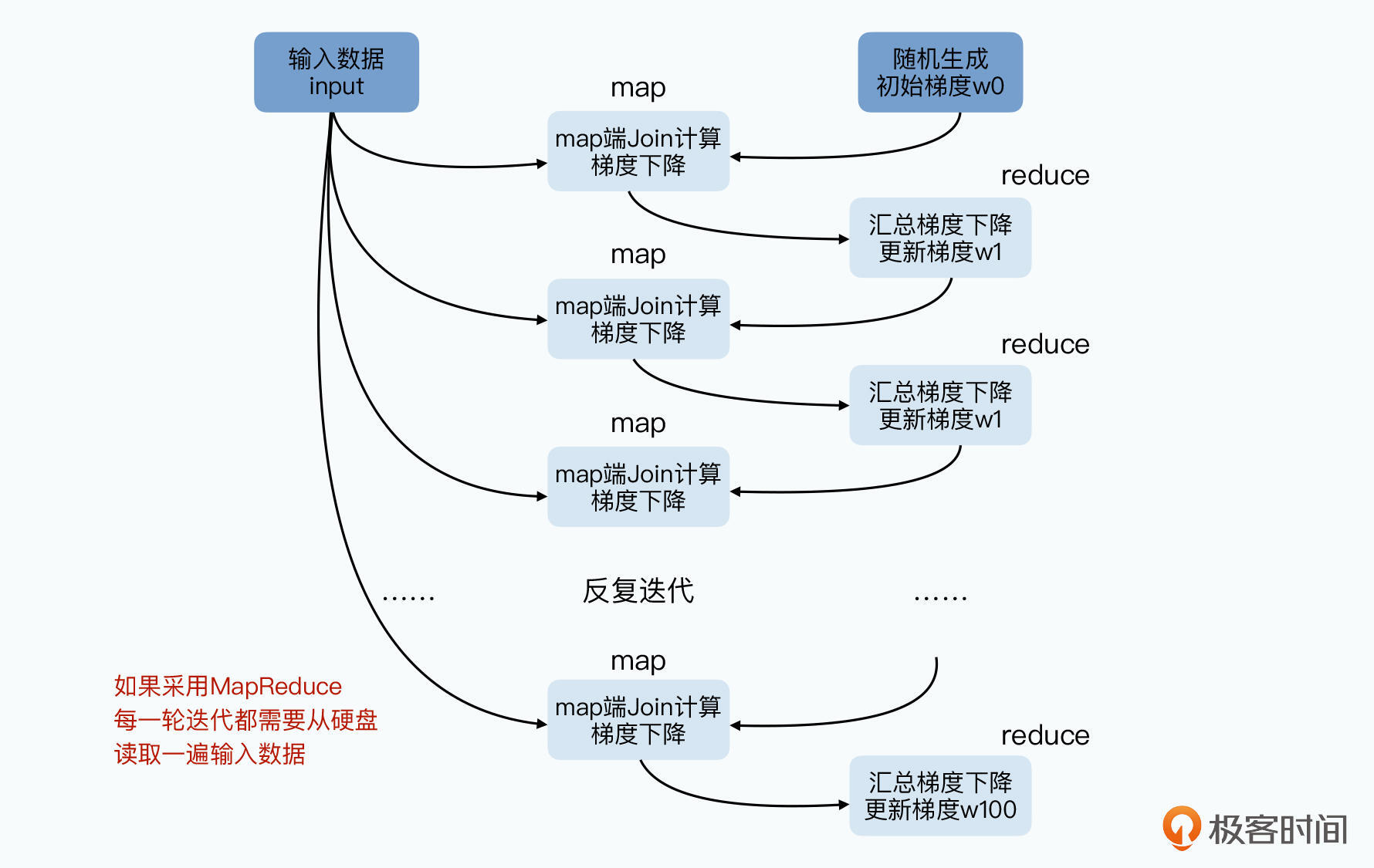
MapReduce之所以在硬盘暂存数据,为了设计的“简单”,和大规模集群下的“容错”能力。将Map的数据直接通过网络发送给Reduce,让Reduce在内存中处理数据,都可以加速。
直接使用网络传数据,Map或Reduce故障时怎么办?
因为Reduce对前面的Map函数有依赖关系,任何一个Map节点故障,意味Reduce只收到部分数据。那么Reduce只能失败,故障Map节点和其他Map节点都要重新运算一次。等于一个Map故障导致整个任务重来一遍。

传统的MPI分布式计算就是这样直接在节点间通过网络发数据,但是容错很差,集群规模也上不去。MapReduce的解决方案时将处理阶段拆开,将每个阶段的中间数据都落到硬盘上。
分布式系统的“函数式”数据集
新的方案:
- 将数据缓存在内存
- 记录我们运算数据生成的“拓扑图”
记录数据计算依赖关系,一部分节点故障时只要根据拓扑图重新计算这一部分即可,即可解决容错问题,而不是每次都写入硬盘 - 通过检查点在特定环节将数据写入硬盘
拓扑图层很深或迭代很多次时,拓扑图方式就很低效。采取折中方式,将一部分中间环节写入硬盘
例如在100轮迭代中没10次写入硬盘一次,一旦出现故障,只要重新读取一次日志数据。
// 论文中实现分布式逻辑回归的代码,输入数据通过 .persistent 缓存在内存,无需每个迭代都从硬盘读取
val points = spark.textFile(...).map(parsePoint).persist()
var w = //random initial vector
for (i<-1 to ITERATIONS){
val gradient points.map{ p =>
p.x * (1/(1+exp(-p.y*(w dot p.x)))-1) * p.y
}.reduce((a,b) => a+b)
w -= gradient
}“函数式”的RDD
Spark 使用了新思路——RDD(Resilient Distributed Dataset,弹性分布式数据集),等于 弹性 + 分布式 + 数据集
对于“弹性”:RDD是只读的、已分区的记录集合,RDD只能通过明确的操作,以及两种数据创建:稳定存储系统的数据,其他RDD。这是为了将map、filter、join等操作和其他操作区分开来。
数据被抽象为一个RDD,任何数据集每次传唤就是一个新RDD,但无需输出到硬盘。只有调用 persistent 函数时才作为一个完整数据集缓存在内存。被缓存后这个RDD就能被下游其他数据转换反复使用。这个数据无需写入硬盘。下游其他转换也无需从硬盘读取。
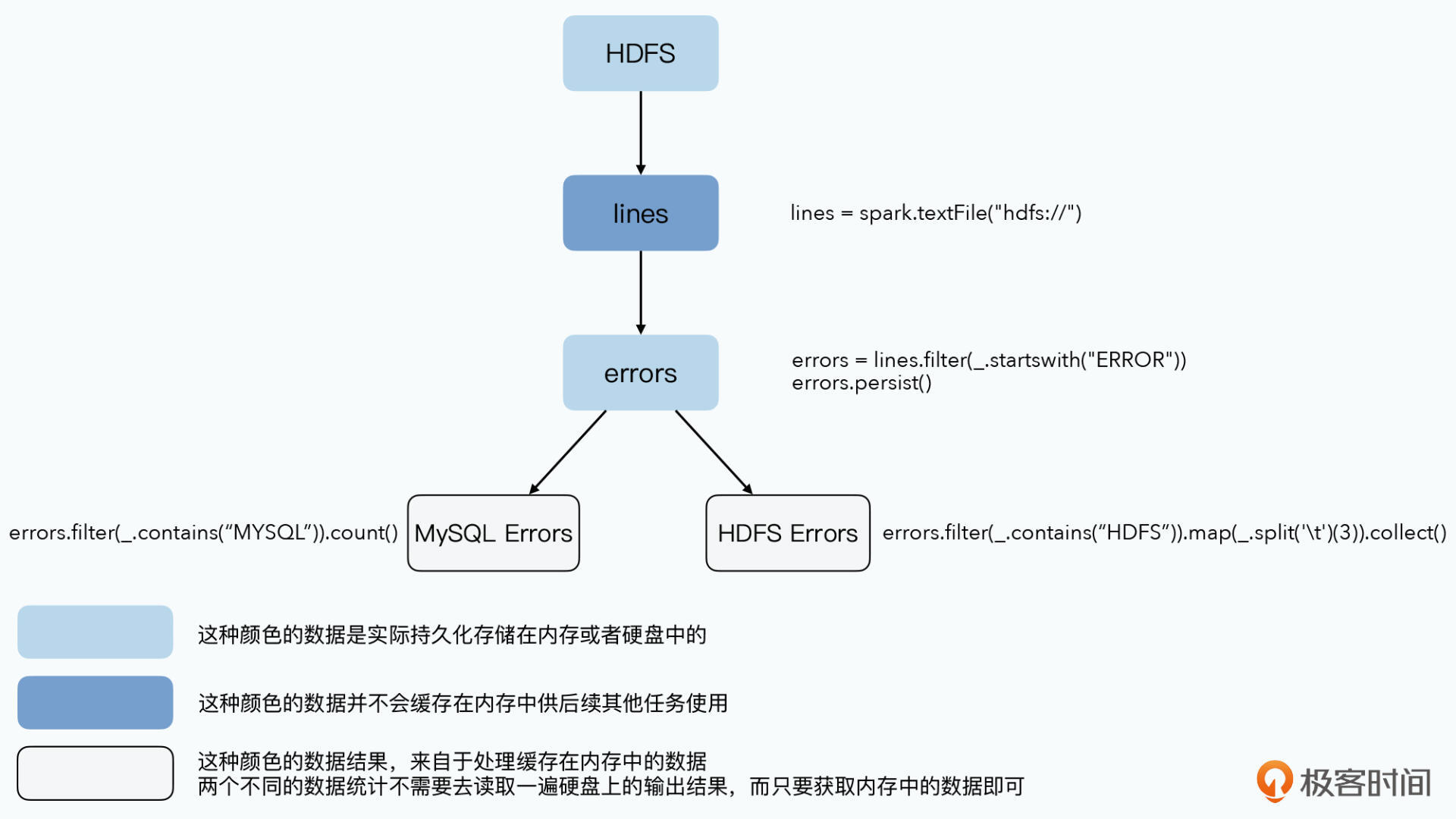
lines = spark.textFile("hdfs://...")
errors = lines.filter(_.startsWith("ERROR"))
errors.persist()
// Count errors mentioning MySQL:
errors.filter(_.contains("MySQL")).count()
// Return the time fields of errors mentioning
// HDFS as an array (assuming time is field
// number 3 in a tab-separated format):
errors.filter(_.contains("HDFS")).map(_.split('\t')(3)).collect()上方代码,从HDFS读取数据,按关键词过滤,调用 persistent 方法所以缓存到内存中。然后两个任务分别读取errors时就无需从硬盘读取,而是从内存读取。
- 惰性求值:没有调用 persistent 时就不对数据转化做计算,而是记录这个函数
- 数据库的视图功能:后续RDD的操作基于之前的RDD
宽窄依赖和检查点
将数据缓存到内存,减少了硬盘读写,但仍面临节点失效导致RDD重新计算的情况。所以,如果一个节点失效导致数据重新计算,影响节点太多就将结果输出到硬盘;影响节点少,将单独重新计算被响应到的节点。Spark 中对数据计算的拓扑图的依赖关系做了一个分类:
- 窄依赖:一个RDD分区只影响下游一个节点,重算一遍也只影响一条线上少数节点,对应中间结果无需输出到硬盘
- 宽依赖:一个RDD分区影响下游多个节点,上游一个节点失效要重新计算,对应的多个下游节点都要从这个节点拉取数据并重新计算,要占用更多资源,对下游影响扩大,将结果输出到硬盘
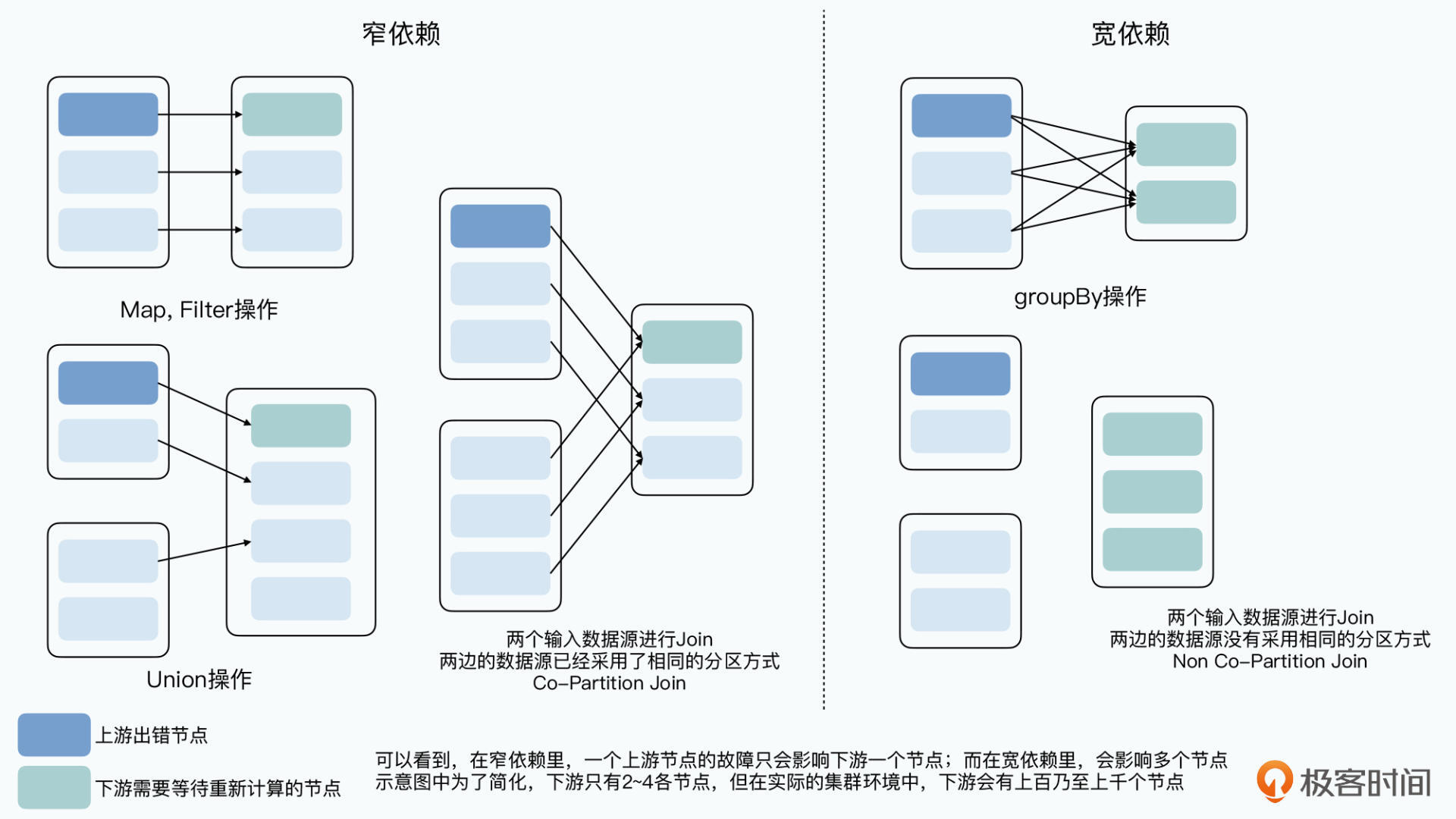
Spark 在 persistent 时添加一个 REPLICATE 参数,将当前结果作为检查点存在硬盘。可见 persistent、持久化存储、允许用户自己通过检查点存储中间结果,都为了在容错和性能间做一个平衡。
RDD与其他分布式系统最大差异在弹性:
- 数据存储:缓存、持久化
- 选择什么数据输出到硬盘:更加宽窄依赖进行,可自设定检查点
