
大数据经典论文解读 - Dremel
Dremel 列式存储
Dremel: Interactive Analysis of Web-Scale Datasets
Dremel: A Decade of Interactive SQL Analysis at Web Scale
开源项目:Parquet
Hive通过分区分桶加快了扫描速度,但这还不够快。MapReduce处理数据的方式就是简单的将数据扫描一遍。Hive等格式存储数据的方式都是“宽表”,将上百个字段存在一张表中,但分析时往往只用其中几个字段。如果Hive中分区分桶太多又会导致文件数量急速上升。此外每个MapReduce任务都有很大的额外开销。
从行存储到列存储
常见的行存储将一行数据连续存储在一起,这方便程序解析数据,只要顺序读取数据并遍历处理即可。但当每行数据有100个字段,分析程序只要其中5个时,顺序读取解析要多读20倍数据。对于硬盘,顺序读远优于随机读,所以根据索引或偏移量随机读取数据可能性能更差。为了解决问题,将要大量分析的数据按一列一列的方式存储,要读取某几列数据时只要顺序读取连续的、放在一起的那几列即可。极端情况下可以将一列数据存为一列。

这样存储数据的写入就更加复杂,可使用 WAL+MemTable+SSTable 的组合方案解决。对于追加写请求,可先写入WAL日志然后再更新到内存,再从内存定期导出到列存储的硬盘上。这样所有数据都是顺序写入,也不需要追加一行数据就再上百个列存储文件后追加记录,那样会面临海量随机写请求。
然而在分布式环境中,数据并不是完全的列存储,因为在分析时可能需要多个列的组合筛选条件。如果两列存在不同服务器,那就需要通过网络传输数据,而网络通常是最主要的瓶颈。
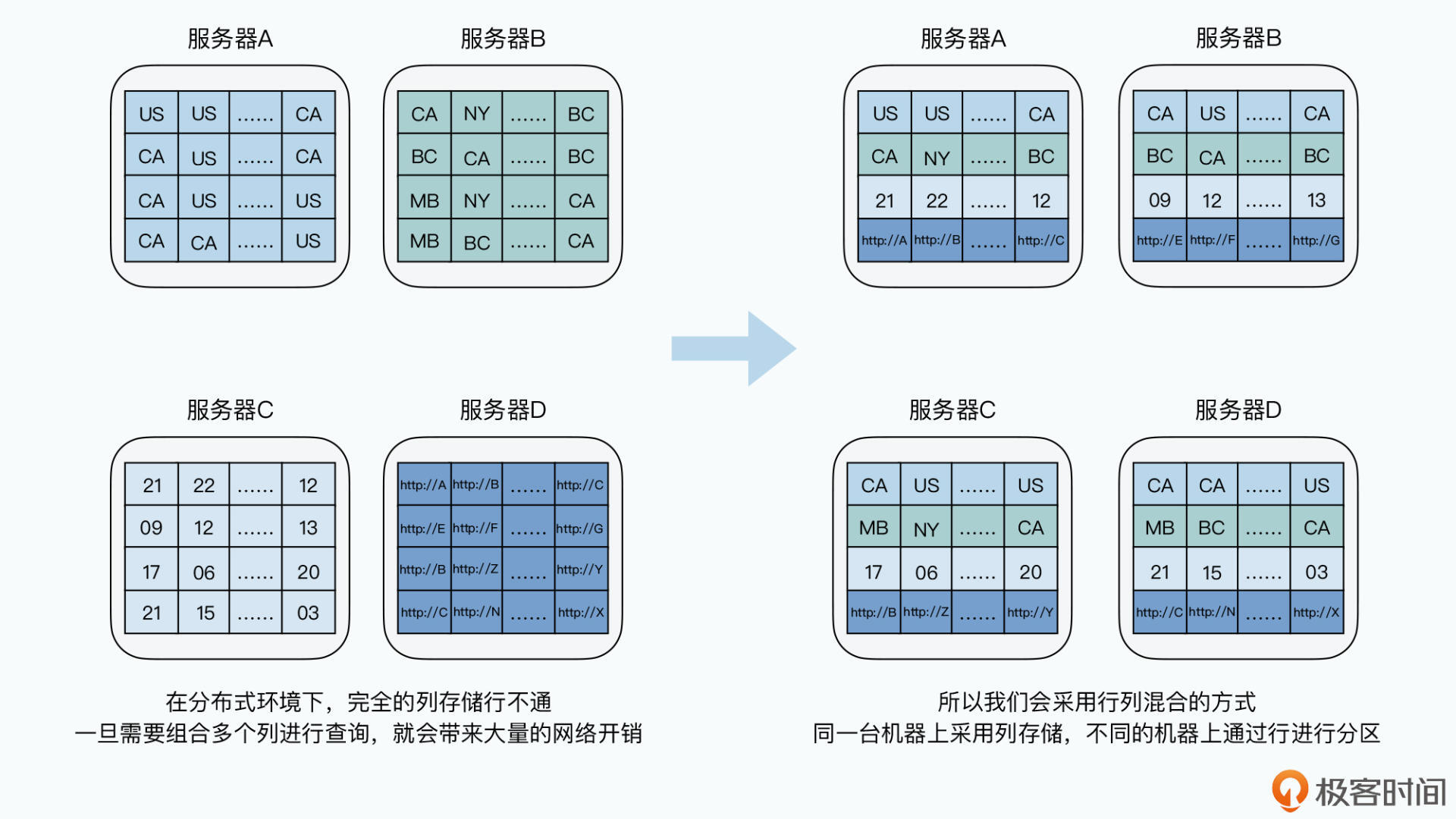
更合理方案是行列混合存储,将一批相同的数据放在同一个服务器。类似Bigtable中对数据进行分区,行键在同一区间的列存储的数据存在同一服务器。这样基于列存储的数据组装成行时也无需通过网络传输。
嵌套结构
在大数据领域,这些数据对象支持复杂的嵌套结构
// 定义了一个Document结构,可有很多正向和反向链接,Name和Language都是可可重复的List,List里嵌套了List
message Document {
required int64 DocId;
optional group Links {
repeated int64 Backward;
repeated int64 Forward;
}
repeated group Name {
repeated Language {
required string Code;
optional string Country;
}
optional string Url;
}
}之前的列存储,每列数据都是固定的,组装数据时只要将每列的第N条数据和其他列的第N条组装起来即可。但存在数据嵌套时,不同行的同一字段可能有不同的长度。不同列存储的数据行数就不一样了,如下图:
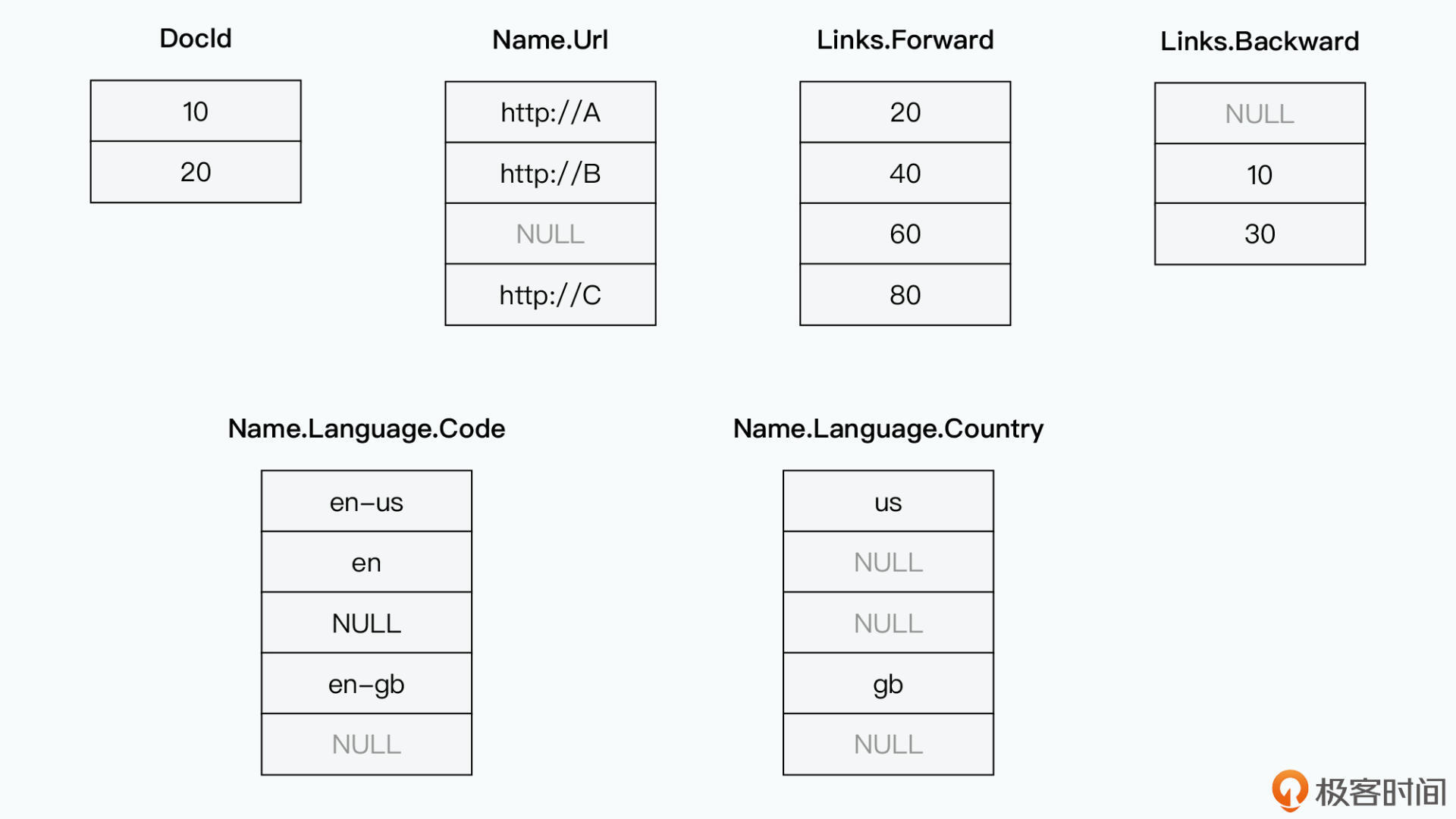
记录每行数据有多少值?这无法处理List嵌套List情况。Dremel使用两个新增字段解决:
- Repetition Level:这个值相对上次出现,是第几层嵌套结构引起的
- Definition Level:这个值为空的可选字段是因为多层嵌套的哪一层的字段为空
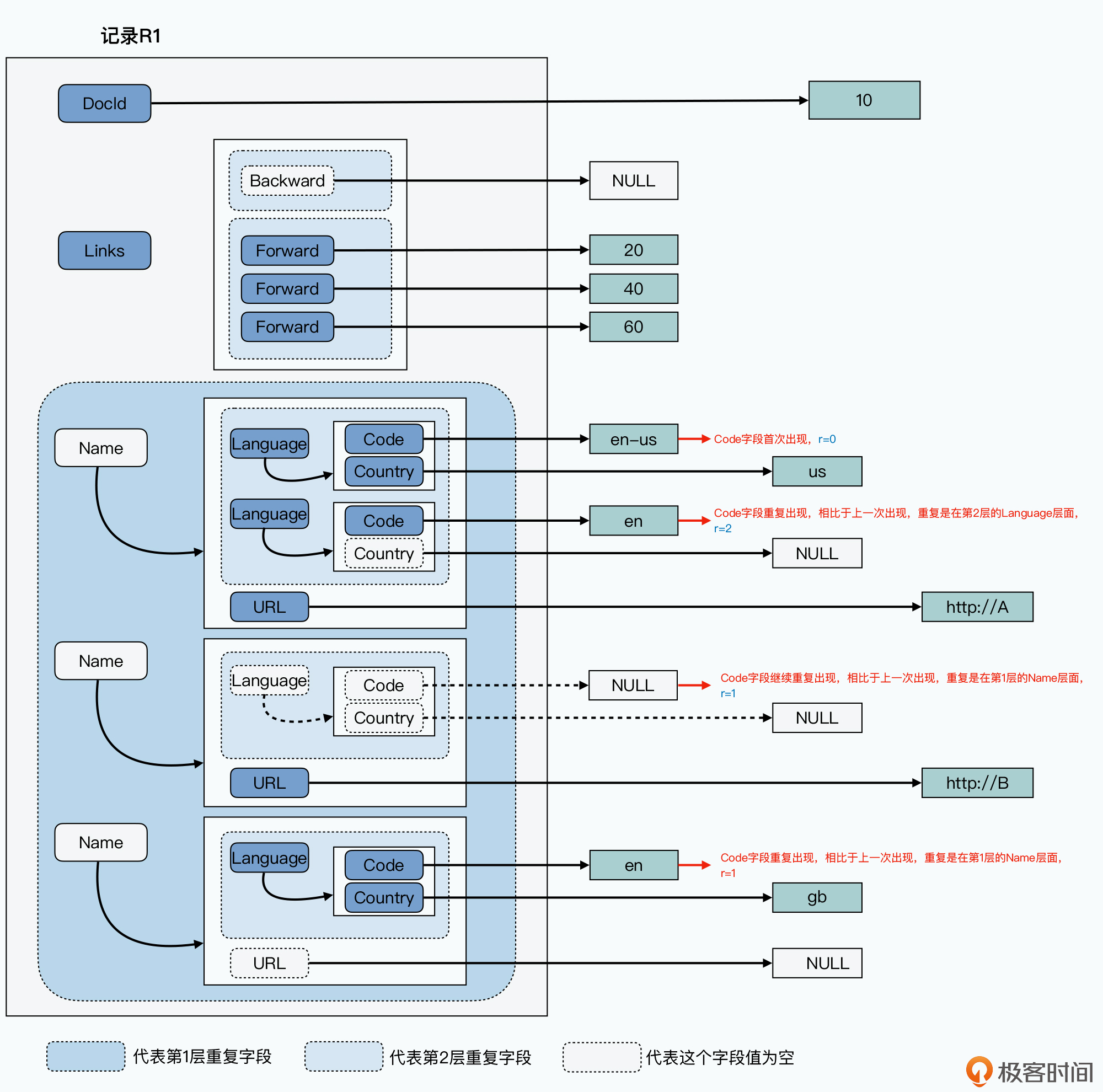
// 示例数据
DocId: 10
Links
Forward: 20
Forward: 40
Forward: 60
Name
Language
Code: 'en-us'
Country: 'us'
Language
Code: 'en'
Name
Url: 'http://A'
Name
Language
Code: 'en-gb'
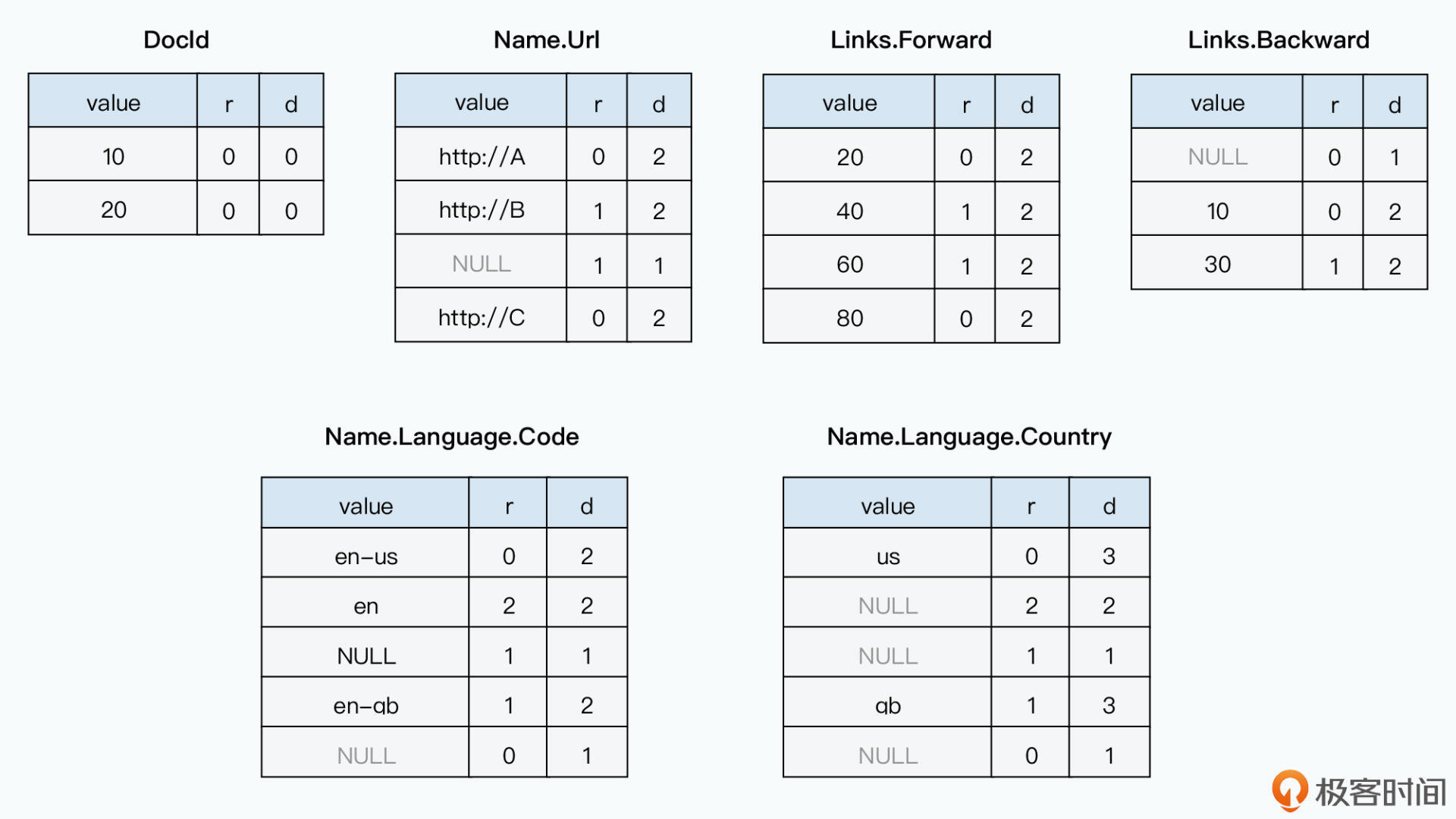
Country: 'gb'两个字段分别简写为 r 和 d
Repetition Level
例如 Name.Language.Code 就是一个三层嵌套,是List嵌套List。考虑示例数据的存储:
- 'en-us',因为没重复过,所以r为0。每当遇到 r=0 就是一个新的documnet记录
- 'en', r=2,因为它是在第2层重复中出现的。它与上一个兄弟出现在同一个Name下,而不是在第一次出现一个新的Name
- null,r=1,它是在第一层重复出现,在一个新的Name字段下,对应URL为'http://A'的Name
- 'en-gb',r=1,重复在第1层,也就是需要一个新的Name
- null,r=0,这个值不来自之前重复的列表,是新的Document记录
Repetition 指向Protobuf中的repeated关键字,通过 Repetition Level 可区分这个值存储的是哪一层 repeated 的值。
Definition Level
用于区分是必须字段的值为NULL,还是可选字段没有值,还是由于上一层的Optional字段的整个对象为空。记录r1中第2、3个Country字段都为空,但是不确定是Name.Language.Country为空,还是Name.Language为空。这个字段就是用与第几层嵌套的Optional字段为NULL。
对于 Name.Language.Code 字段,Name和Code都是必须的,Language是可选的。所以Code为Null时,必然是Language为空,这时d=1。取值不为NULL时,这个d值就是当前字段作为Optional字段定义的层数加1。考虑 Name.language.Country 的数据:
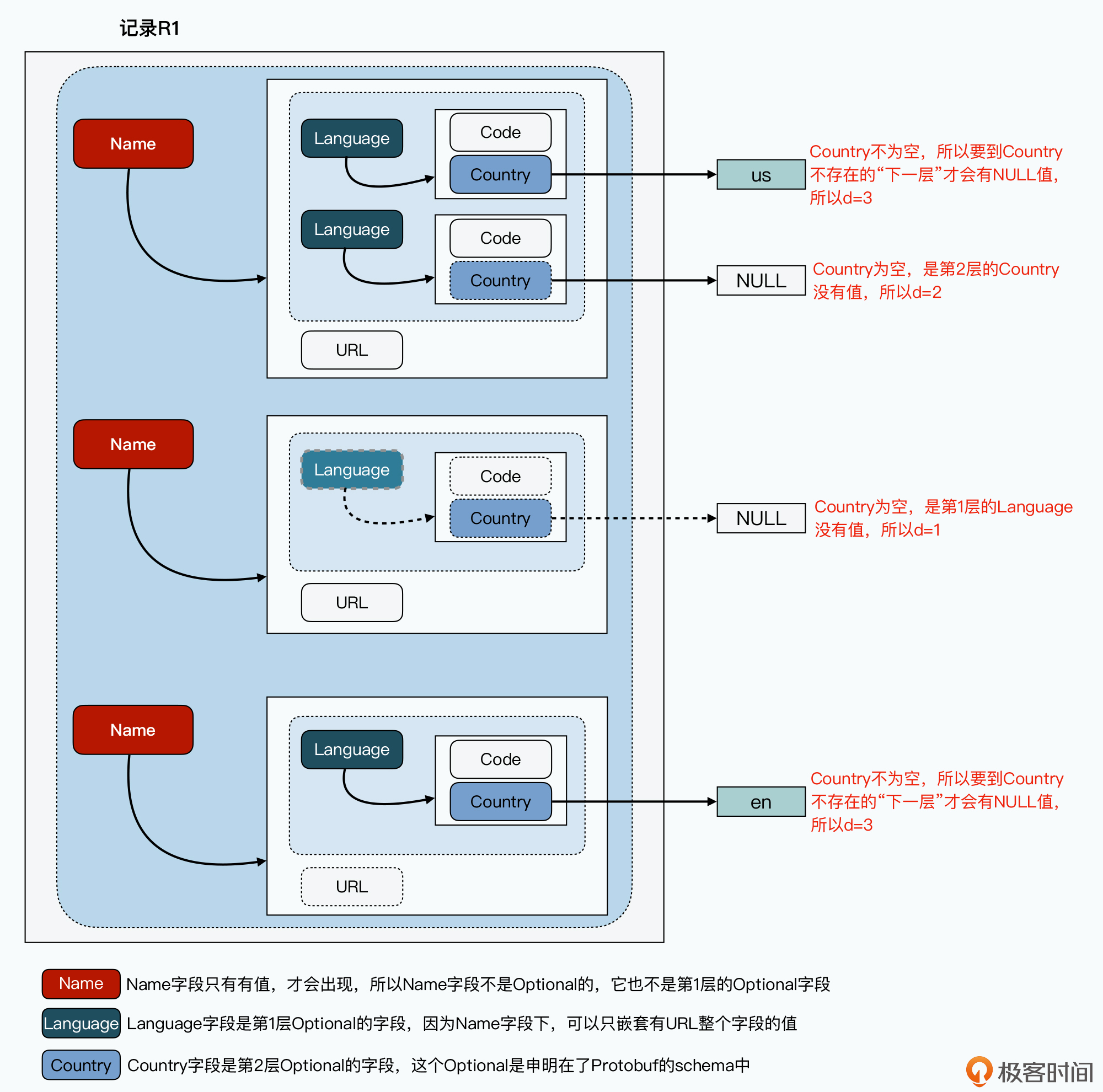
Name是必选的,Language、Country是可选的。Contry为NULL可能是因为第1层的Lanuage为NULL,也可能是因为第2层的Country本身是NULL。
存储模型总结
使用行列混合的形式存储,在单个服务器上数据列存储,在全局数据根据行分区并分到不同节点。
为了防止数据的追加造成大量随机追加,采用类似 Bigtable 的 WAL+MemTable+SSTable 的形式,先写日志再更新内存、最后定期输出到硬盘,确保所有数据写入都是顺序的。
Repetition Leve 区分每个值隶属哪一层嵌套;Definition Level 确定是否要填充对应的 Optional 字段或结构体。保证数据能够存储和提取。
计算模型
- 从MPP数据库学到了数据分区和行列混合存储,并将计算节点和存储节点放在同一台服务器
- 从搜索引擎的分布式索引,学到了通过树形架构快速检索再层层归并,再返回最后结果
- 从MapReduce中借鉴了推测执行,解决少部分节点拖慢整个系统运行时间的问题
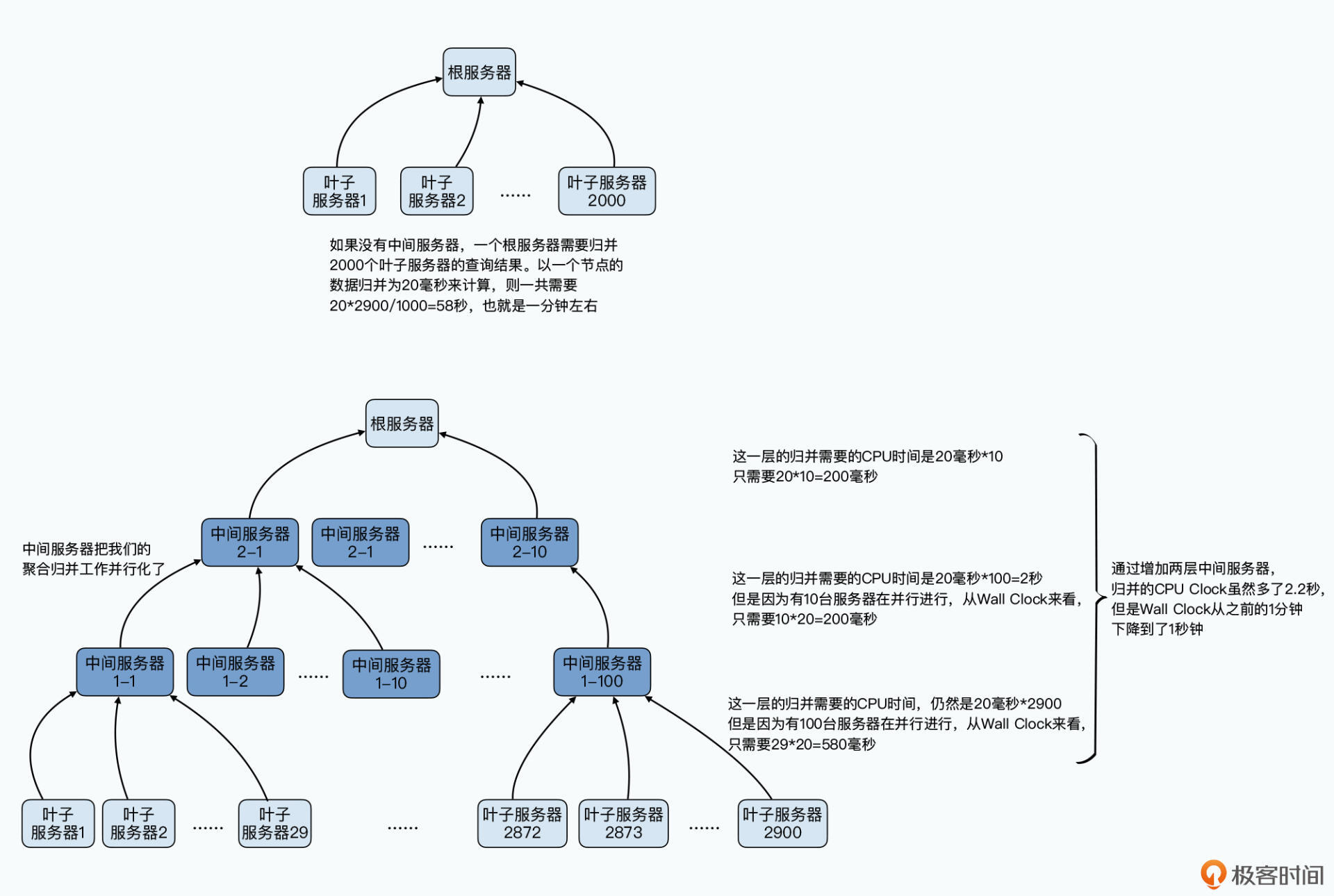
MapReduce伸缩性很好,但是每个任务有很大的额外开销。虽然Hive简化了用户操作,列存储减少了扫描的耗时,但这个额外开销还是会让运行时间保持在分钟级别。Dremel 的底层计算引擎不是MapReduce,提出新思路:
- 让计算节点和存储节点在同一服务器
- 进程常驻,做好缓存,防止冷启动
- 树状架构,多层聚合。这样单个节点响应时间和计算量都较小,能快速拿到返回结果。
- 存储:即使不适用GFS,数据也会复制3份到不同节点
计算:检测各个叶子服务器的执行速度,对于落后的节点会调度到其他计算节点
只扫描98%~99%的数据就返回结果以加速
Dremel 采用多层服务树架构,有三类节点:
- 根服务器(root server):接收外部查询请求,读取Dremel里各个表的METADATA,将对应的查询请求路由到下一级服务树(serving tree)
- 中间服务器(intermediate servers):可以有很多层,层层转发。没下发一层,SQL就重写一次,然后将结果在当前节点聚合并返回上一级
- 叶子服务器(leaf servers):最终完成数据查询和实际存储数据的节点
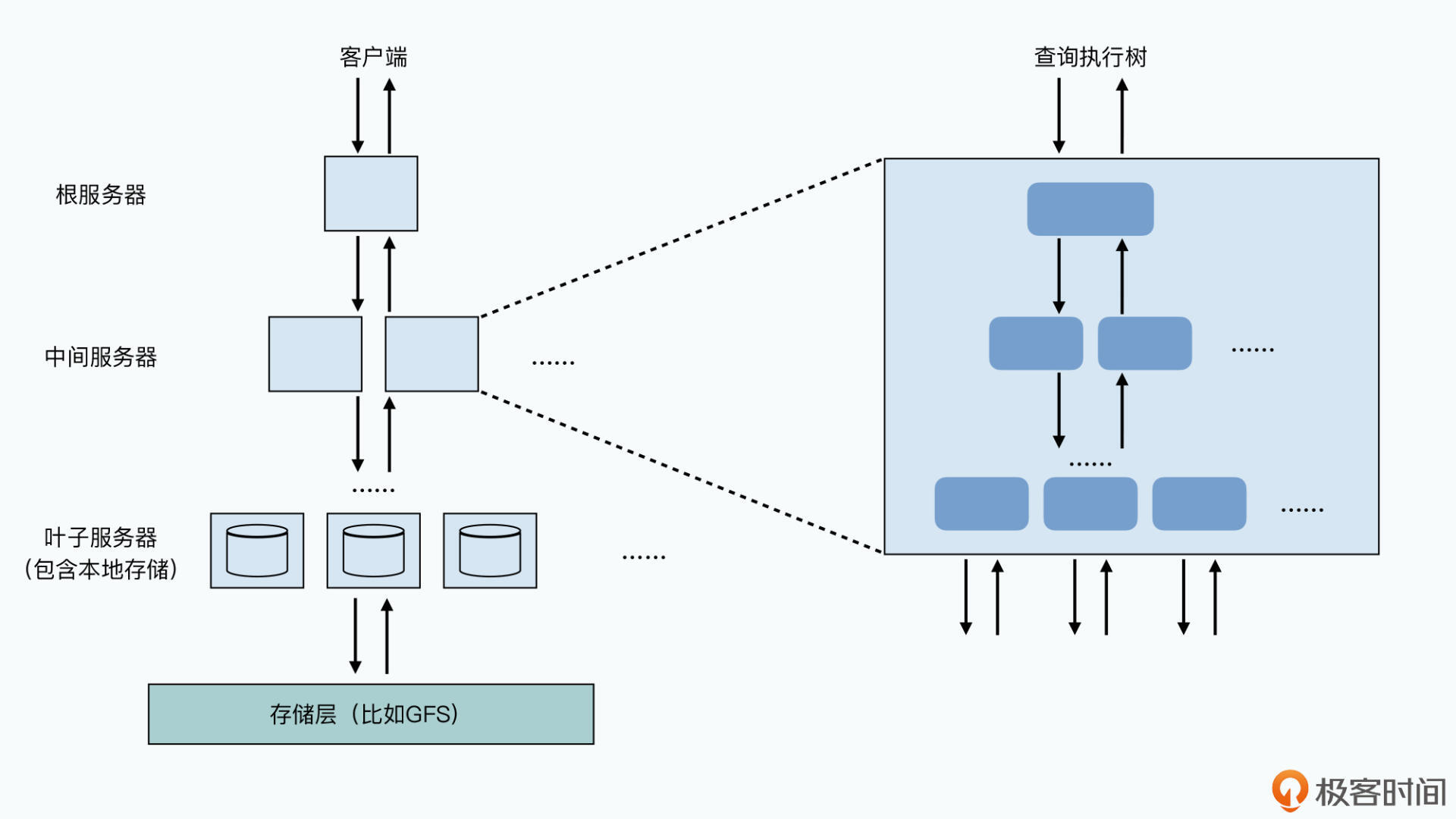
行列混合存储的MPP架构
行列混合存储,每个节点存的数据是一个特定分区所有的数据。这样数据到达叶子节点时,叶子节点只要访问一台物理节点。有两种方案:
- 数据存在叶子节点的本地硬盘(已废弃)
- 采用GFS等共享存储层
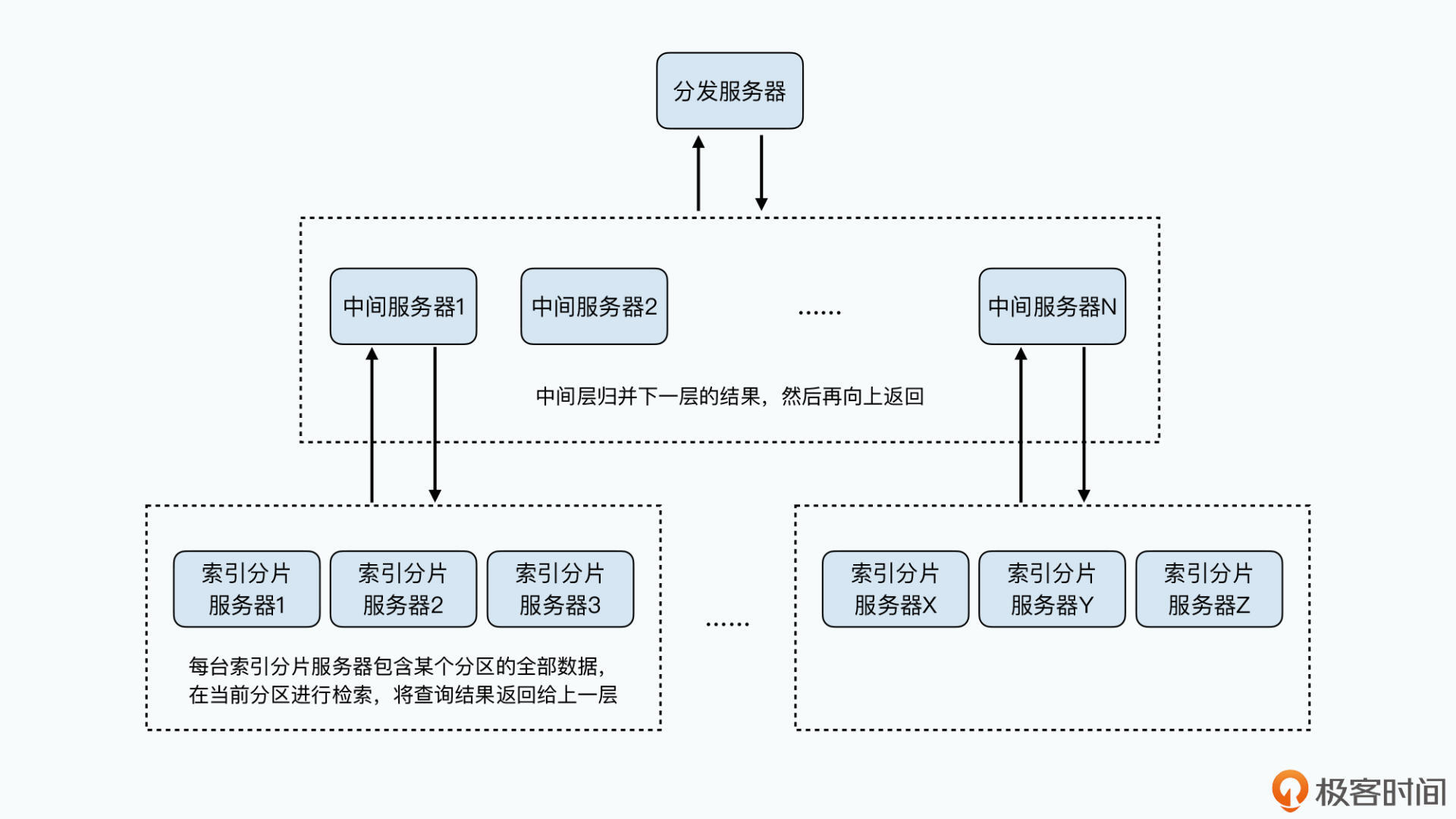
树形分发的搜索引擎架构
数据分区到不同叶子节点,类似文档分片到不同索引分片节点。每个索引分片节点,会完成自己分片数据的检索并返回上一层。中间服务器也会将检索结果合并再返回,直到根服务器
SELECT A, COUNT(B) FROM T GROUP BY A这条SQL发到根节点后会重写成
SELECT A, SUM(c) FROM (R_1_1 UNION ALL ... R_1_n) GROUP BY A其中每个R都是下一层的一个SQL计算结果,下一次SQL为:
R_1_i = SELECT A, COUNT(B) AS c FROM T_1_i GROUP BY A这就是让中间节点分别统计一部分分区数据,再将其相加。
这个架构的核心是可以通过中间服务器进行“垂直”扩张,这样可以在计算量基本不变情况下通过服务器并行缩短SQL花费时间。中间层把数据归并的工作并行化了。
容错方案
借鉴MapReduce的容错:
- 输出存储3份副本,个别节点故障时可调度到其他有副本的节点
- “推测执行”功能,Dremel会监测叶子节点运行任务的进度,当遇到个别节点速度极慢拖慢了整个系统,这时将任务转发给其他单点
- 可设置只扫描98%数据即返回结果


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律