
分布式协议与算法实战 - 分布式算法 paxos raft
paxos算法用于分布式共识,分成2部分
- Basic Paxos算法,描述多节点间如何就某个值达成共识
- Multi-Paxos算法,执行多个Basic Paxos实例,就一系列值达成共识
Basic Paxos
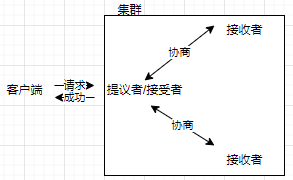
三种角色
- 提议者(Proposer):(接入与协调)提出一个值用于投票表决,多数情况下接收客户端请求的节点为提议者使得无需在业务代码中实现
- 接受者(Acceptor):(协调与存储)一般集群中所有节点都是接受者,参与协商和存储。一般提议者同时也是接受者,这里为了方便将其分开
- 学习者(Learner):(存储)被告知投票结果,接受共识并存储,备份容灾
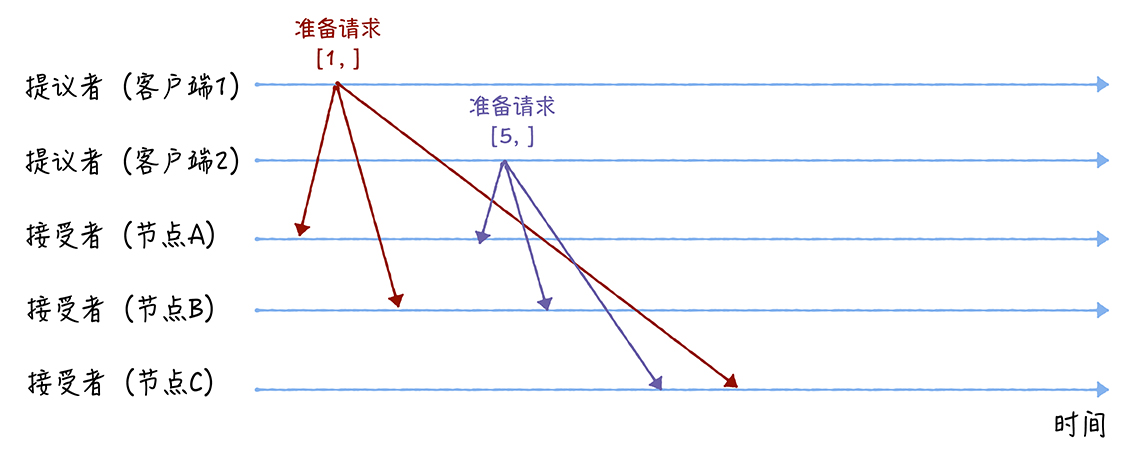
每个要达成一致的数据被称为提案,每个提案包括提案编号和提议值,使用 [n, v] 表示
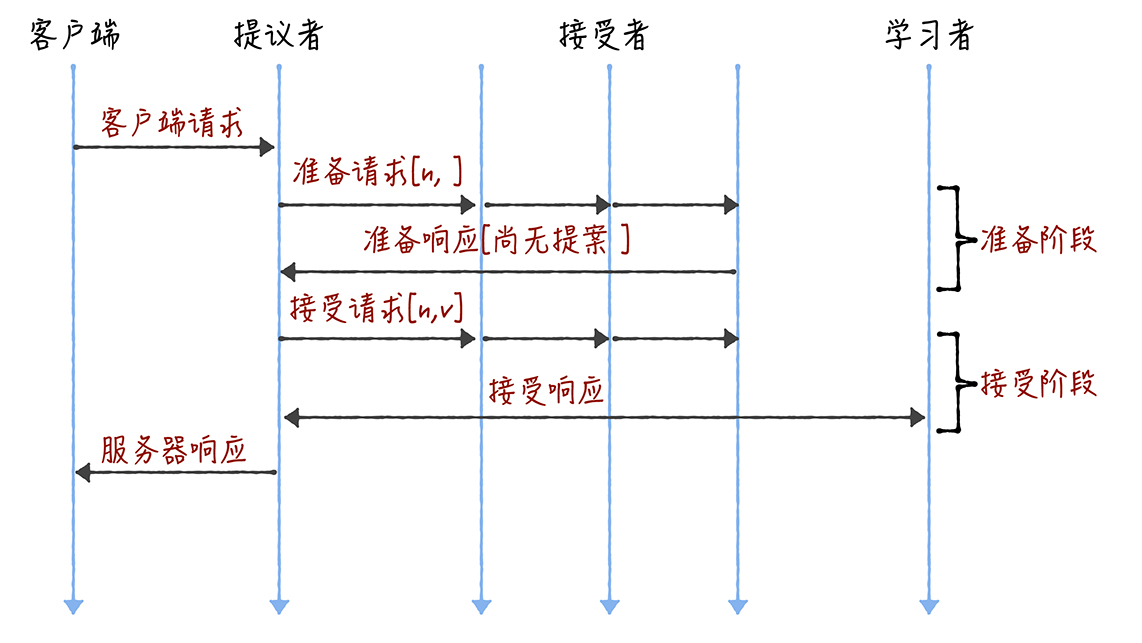
类似二阶段提交,这里也有两个阶段。这里以分布式KV存储为例
准备阶段
此阶段请求中只需提案编号即可,无需值。
假设客户端1 2的提案编号分别为1和5,节点AB先收到1的请求,节点C先收到2的请求
由于之前没有收到提案,ABC节点在收到第一个提案时响应“尚无提案”同时承诺不再接受编号小于接受值的提案。
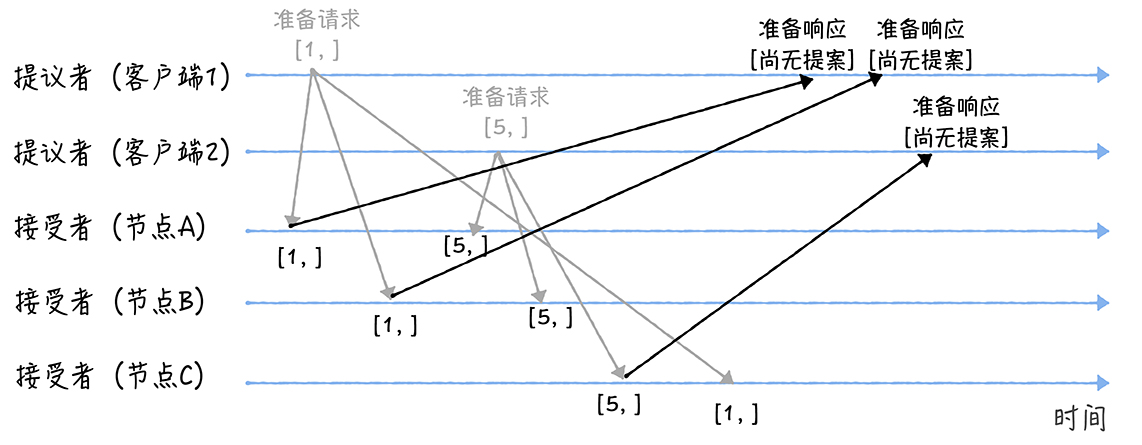
所以接受到第二个请求时会判断提案编号的大小再返回响应
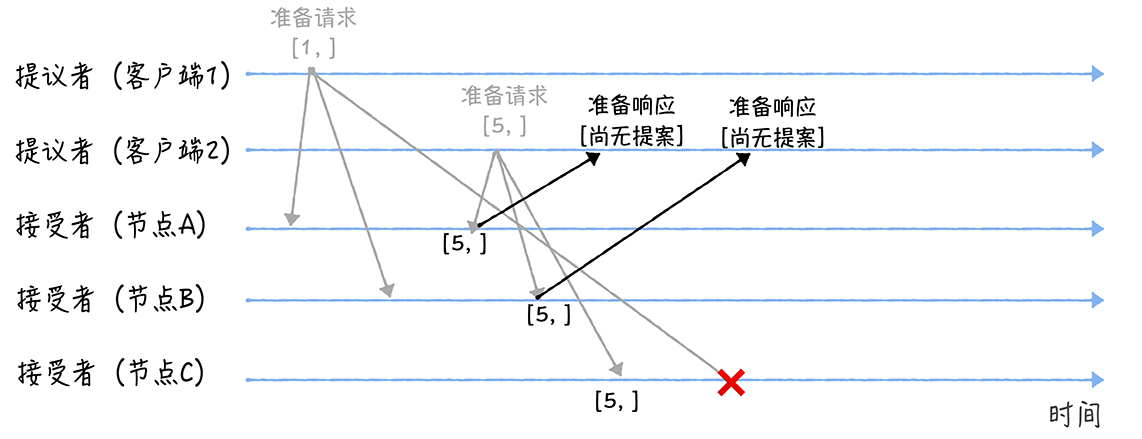
AB接受到编号为5的提案,因为5大于之前接受的提案编号,所以返回“尚无提案”,之后不再接受编号小于5的提案。
当节点C收到编号1时,判断1小于5,所以丢弃该请求不做响应。
接受阶段
如果所有响应者返回“尚无提案”则将自己的提案编号作为请求的提案号,将提案号和提案值一起发送。如果响应值不为空,则以响应中提案编号最大的作为自己的请求提案号。
因为客户端1、2的响应大多都为“尚无提案”所以使用原有的提案号和请求值得到 [1,3] [5,7]
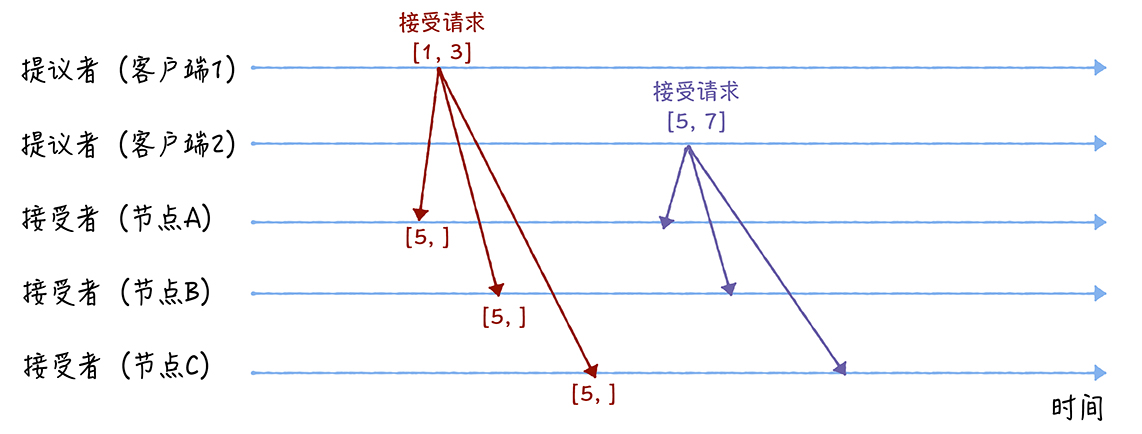
节点接受请求[1,3]时由于1小于三个节点承诺的能通过的提案的最小提案编号5,所以此提案被拒绝。
当收到[5,7]时,由于5不小于承诺的能通过的提案的最小提案编号5,所以通过提案[5,7],也就是接受了值7,三个节点就X值为7达成共识。
当接受者通过一个提案就通知给所有学习者,当学习者发现大多数接受者都通过了某个提案,那么它也通过该提案接受提案的值。
总结
Basic Paxos通过二阶段提交方式达成共识,这是一种常用方法。
Basic Paxos 的容错能力来自于“大多数”的约定,当少于一般节点故障时共识协商仍能正常工作。不像分布式事务要所有节点都同意才提交操作。
根据提案编号做出3种操作:
- 准备请求阶段,当 提案编号小于等于接受者已响应的准备请求编号,接受者将不响应
- 接受请求阶段,提案编号小于接受者已经响应的准备请求提案编号,不通过提案
- 接受请求阶段,若之前通过提案,在准备请求的响应中,包含已通过的最大编号提案信息
Multi-Paxos 思想
basic paxos只能就单个值达成共识,当需要一系列值达成共识时需要拓展。multi-paxos不是一个具体算法,而是通过多次执行Basic Paxos实例实现一系列值的共识。(Chubby的Muti-paxos,Raft,ZAB都是在此思想上补充的细节)
关于Basic Paxos的缺点
Basic Paxos要通过二阶段提交达成共识,在准备阶段接收到大多数准备响应,才能进入第二阶段。
- 在准备阶段多个提议者同时提交提案使得提案冲突,没有提议者接受到大多数准备响应,需要重新协商。
例如:5节点集群,3个提议者同时提案,得票为1:2:2,使得准备失败 - 2轮RPC通信消耗多、延迟大。
领导者
引入领导者作为唯一提议者,这就不存在多节点同时提交的情况了。不同算法使用不同选举领导者方法。
优化 Basic Paxos 执行
当领导者处于稳定状态时,省略准备阶段直接进入接受阶段。领导者节点上序列中命令是最新的,无需通过准备请求来发现之前被大多数节点通过的提案。领导者提交命令时可省略准备阶段,直接进入接受阶段。

引入领导节点后:
- 只有一个提议者,不存在提案冲突
- 省略准备阶段,直接进入接受阶段,提升性能降低延迟
Chubby 的 Multi-Paxos 实现
- 引入主节点,不存在多提案同时提交
- 主节点通过 Basic Paxos 算法投票选举产生,通过不断续租来延长租期。当主节点故障,其他节点会投票选出新主节点。
- 实现了当领导者处于稳定状态,省略准备阶段,直接进入接受阶段
- 实现成员变更以保证节点变更时集群的平稳
- 为了实现强一致性,读操作也只能在主节点上执行
所有读写请求都有主节点处理。
主节点接受请求后作为提议者执行 Basic Paxos 实例,将数据发给所有节点。在大多数节点接受这个写请求后再响应客户端成功。
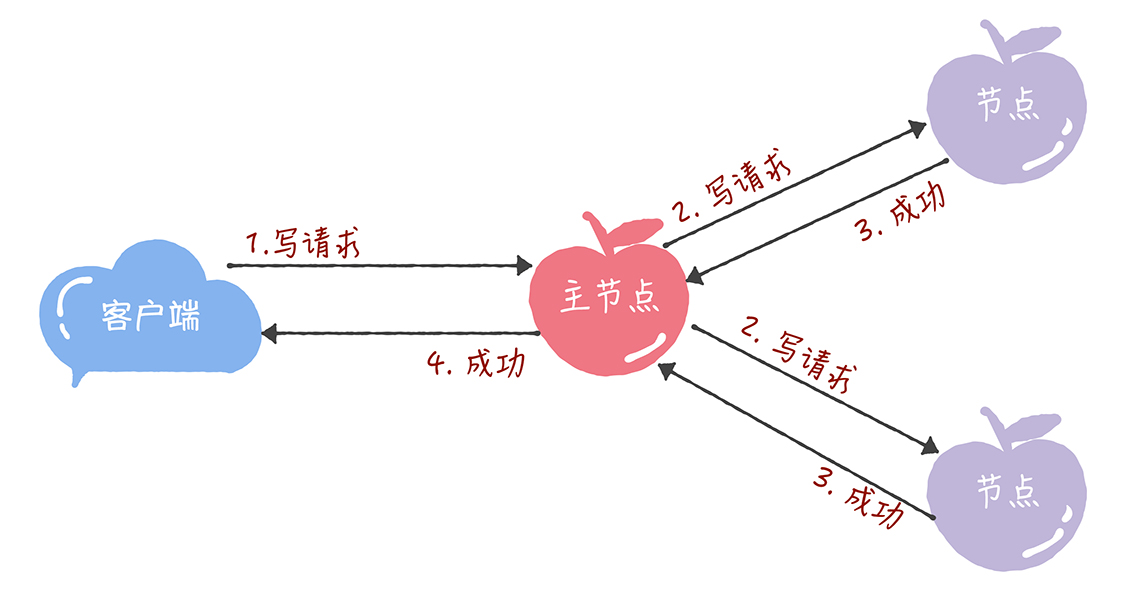
主节点接受到读请求后查询本地数据返回给客户端,无需集群间交互。
总结
- Multi-Paxos是一种思想而非算法,每个人的实现不同
- Chubby实现了领导者和“领导者稳定时,省略准备节点,直接进入接受阶段”。这提高效率,但所有请求都在主节点处理,限制了集群并发能力,约等于单机
- Chubby也约定了“大多数原则”,只要大多数节点正常运行,集群能正常工作,及容忍 (n-1)/2 个节点的故障
- 省略准备阶段的优化机制是通过减少非必须协商步骤来提升性能
Raft - 如何选举领导者
Raft (thesecretlivesofdata.com) hesecretlivesofdata.com/raft/
Raft协议详解 - 知乎 (zhihu.com) zhuanlan.zhihu.com/p/27207160
raft在Multi-Paxos 上做了简化和限制,如日志必须是连续的,只支持leader、follower、candidater三种状态。raft通过一切以领导者为准的方式,实现一系列值的共识和各节点日志的一致。raft是强领导者算法,集群中只能有一个leader。
- 跟随者 follower:接受leader消息,当leader心跳超时,推荐自己当候选人
- 候选人 candidater:follower向其他节点发送请求投票的消息,通知其他节点投票,赢得大多数票即可晋升leader
- 领导者 leader:处理写请求、管理日志复制、不断发送心跳消息
选举过程
初始,所有节点都是follower。所有节点实现了随机超时,及每个节点等待leader心跳的超时时间是随机的。
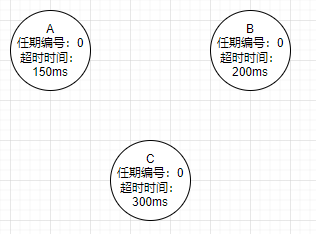
A最先超时,并要求投票给他
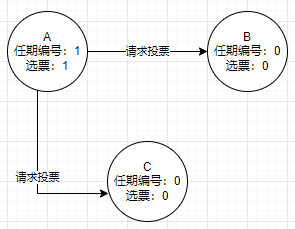
其他节点接受到候选人A的请求投票消息,在编号为1的任期内没进行过投票,那么投票给A,并增加自己的任期编号
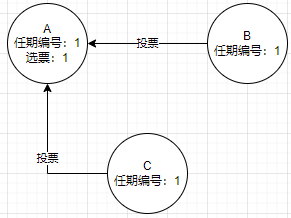
得到大多数选票后A变为本届任期内leader,当选后周期性给其他节点发送心跳
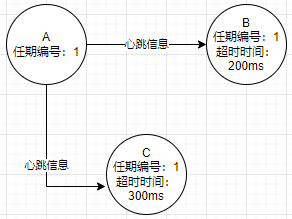
节点如何通讯
在选举期间有用到两类RPC
- 请求投票RPC,由候选人在选举期间发起,通知各节点投票
- 日志复制RPC,由且仅由领导者发起,用于复制日志和提供心跳
什么是任期
由任期编号决定,随着选举的举行而变化。
- 心跳超时后,follower推举自己为candidater,增加自己任期号
- 一个节点发现自己任期编号比其他节点小,那么会更新自己的编号到较大的值。
如B的任期编号为0,接受到A的编号为1请求投票消息时,将自己的任期编号更新为1
任期编号会影响选举
- 当一个leader或candidater发现自己任期编号比其他节点小,那么立即恢复成follower状态。
如分区错误期间,数量较小的分区无法正常运行,任期编号不变。在错误恢复后,被分到较小分区的leader恢复为follower状态。 - 若接受到更小编号的投票请求,它直接拒绝。
如C的任期编号为4,接收到任期编号为3的投票请求,它将拒绝这个消息
选举有哪些规则
- leader周期性发送心跳(即不包含日志项的RPC消息)
- 超时时间内没接收到leader消息,认为当前无leader,发起选举
- 选举中赢得大多数选票晋升为leader
- 一个任期内,除非因为宕机、网络延迟等问题重新选举,否则leader一直是leader
- 一次选举中,一个节点最多对一个任期编号投一张票,按“先来先得”原则
- 任期编号相同时,日志完整性高的follower拒绝投票给完整性低的candidater
例如BC的任期编号为3,BC的最后一条日志对于任期编号为3、2,C请求投票时B拒绝投票。
随机超时时间是什么
大多数选票规则为了保证给定任期内最多只有一个leader。为了防止选票被分给多个节点导致选举失败,随机超时时间保证多数情况下只有一个服务器先发起选举,而非同时。这里的随机超时有两种含义:
- follower等待leader心跳的超时时间间隔是随机的
- 当没有领导人赢得过半选票,选举无效。这时要等一个随机间隔,这个等待选举的超时时间是随机的
总结
- 不是所有节点都能当领导者,只有日志最完整的节点才能
- raft中日志必须是连续的
- 通过 任期、leader心跳机制、随机选举超时时间、先来先服务的投票原则、大多数选票原则等,保证了一个任期只能有一个领导,也减少了选举失败的情况
- raft一切以领导者为准,达成共识,实现日志的一致
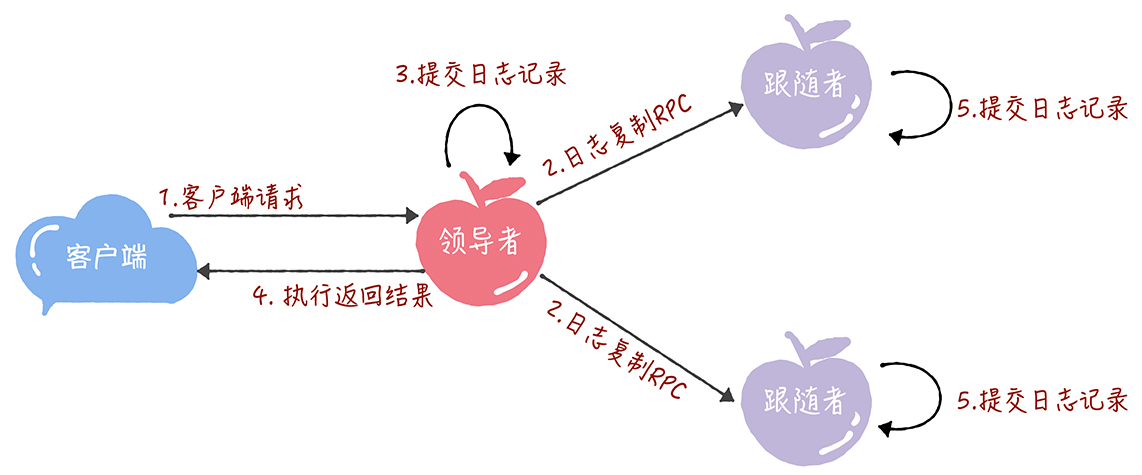
Raft - 日志复制
在raft中,副本数据以日志形式存在,leader接到客户端写请求后,处理写请求的过程就是一个复制和提交日志的项的过程。
日志
日志项主要包含:
- 指令(Command):用户请求指令
- 索引值(Log index):日志对应的整数索引值,用于标识日志项,是连续、单调递增的整数
- 任期号(Term):创建这条日志时leader的任期号
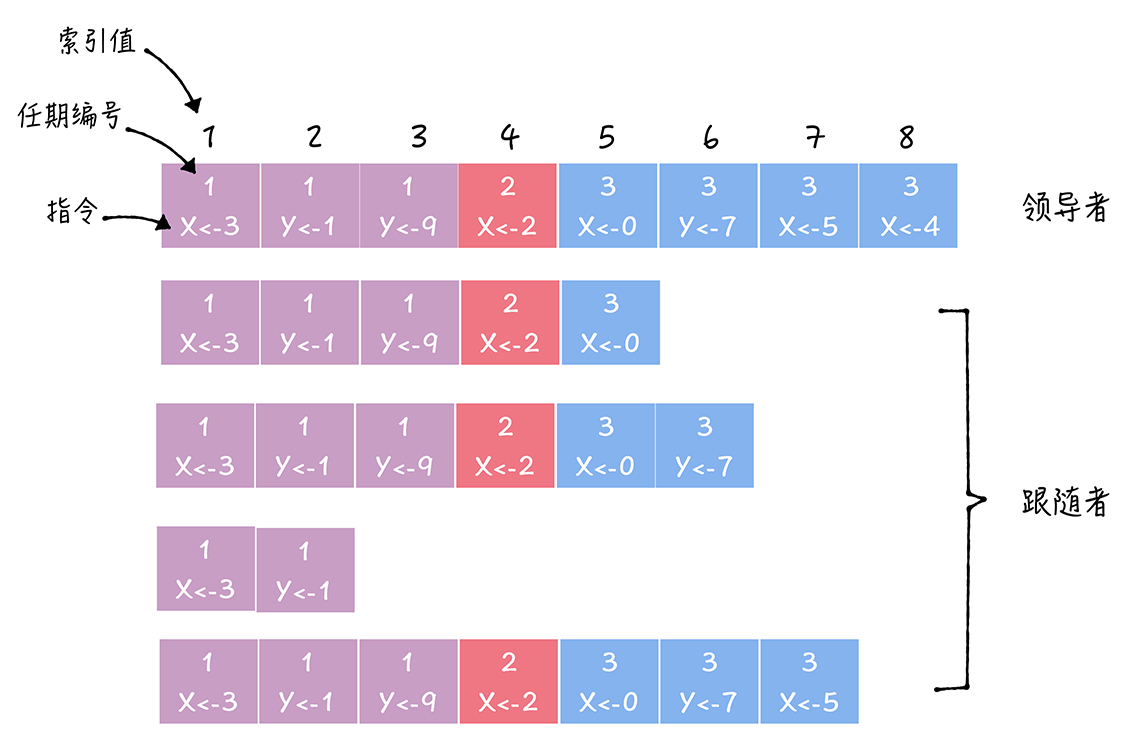
一届领导者任期往往有多条日志项,且索引值是连续的。
如何复制日志
可理解为一个优化后的二阶段提交(将二阶段优化成了一阶段),减少了一半往返的消耗和延迟。
- leader 进入第一阶段,通过日志复制RPC消息将日志复制到其他节点
- leader 接收到大多数的“复制成功”响应后,将日志项提交到自己的状态机,并返回“成功”给客户端;
若没接收到大多数的成功响应,那么返回“错误”给客户端
领导者不直接发送消息通知其他节点提交执行日志项,但是日志复制RPC和心跳消息包含了,当前最大的将被提交的日志项索引值。所以通过日志复制RPC消息或心跳消息,follower可知道领导者的日志提交位置信息。
当其他节点接收到leader的心跳消息或日志复制PRC后,将这条日志项提交到它的状态机。这个优化降低了延迟,将二阶段提交优化为一阶段提交。
如何实现日志一致
leader强制follower直接复制自己的日志项,处理不一致日志。
- leader通过日志复制RPC检查一致性,找到follower上与自己相同日志项的最大索引值。
- leader强制follower更新覆盖不一致日志项,实现一致
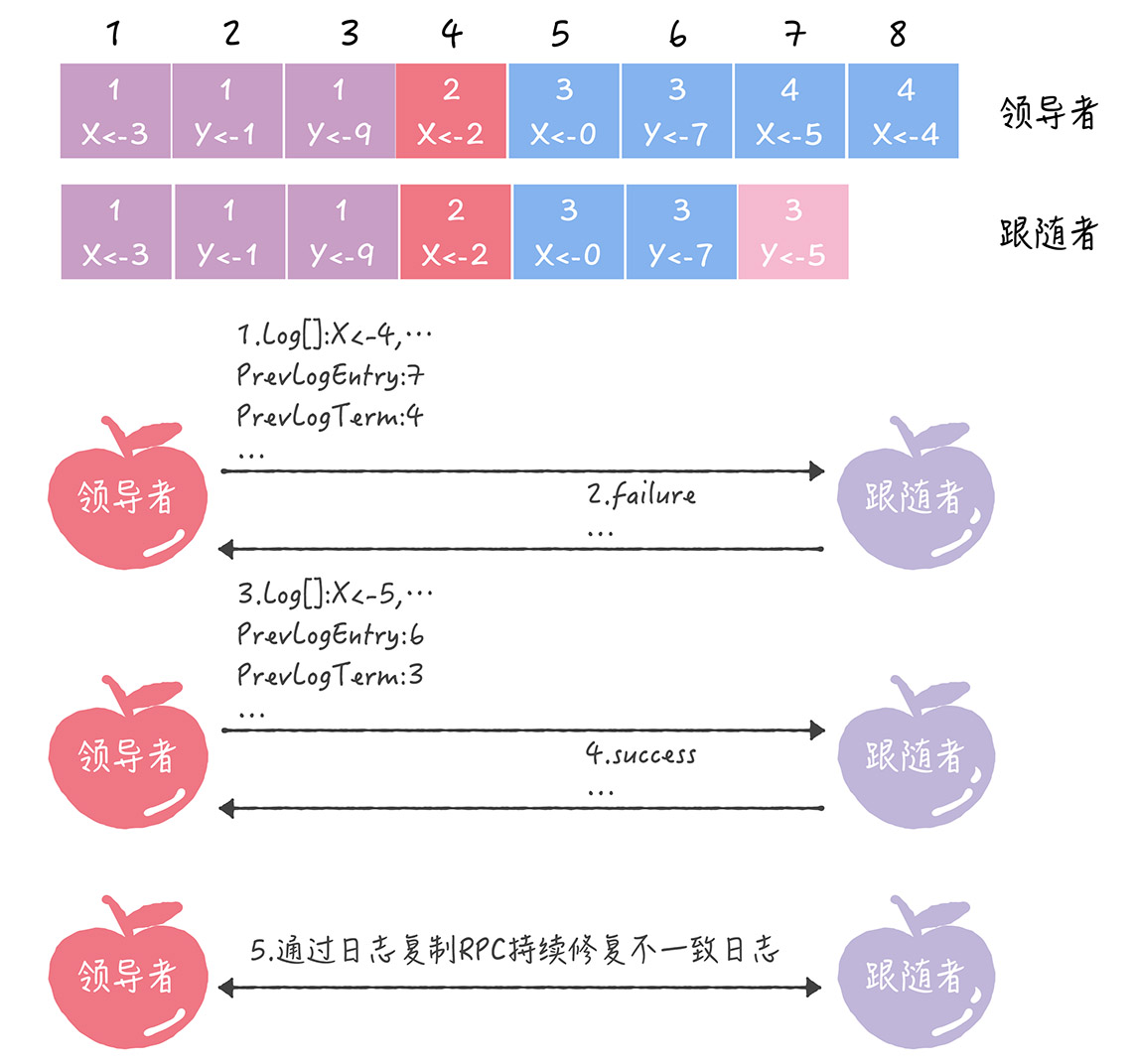
PrevLogEntry:当前要复制日志项前一项的索引。图中当前日志项索引为8,对应PrevLogEntry为7
PrevLogTerm:当前要复制日志项前一项的任期编号。图中PrevLogTerm为4
- leader通过日志复制RPC发送当前最新日志项到follower(也可以复制非最新日志),此消息PrevLogEntry为7,PrevLogTerm为4
- follower在自己日志中找不到相同日志,即不一致。follower拒绝新的日志项,返回失败信息
- leader递减要复制的日志项索引并发送到follower,其PrevLogEntry为6,PrevLogTerm为3
- follower找到了PrevLogEntry为6,PrevLogTerm为3的日志,返回成功,leader就知道他们的日志项在这个位置相同
- 领导者通过日志复制RPC复制并更新索引后的日志项,即不一致日志项,最终达到一致
leader通过日志复制RPC一致性检查,找到follower上与自己不一致的日志项,并强制覆盖。
follower中不一致的日志会被leader覆盖,但是leader的日志永不会被覆盖或删除。
总结
- raft中副本以日志形式存在
- raft中日志必须连续,且日志不仅是数据的载体还影响领导者选举的结果。日志完整性最高的才能当领导者。
- 日志等一切都以leader为准
Raft - 成员变更
当集群中机器增加或减少时可能引起新旧两个配置的“大多数”,出现混乱。
配置:集群由哪些节点组成,时集群各节点地址信息的集合。如集群有A、B、C三节点,那么配置为[A、B、C]
成员变更问题
有3台机器的raft集群增加了2台机器。
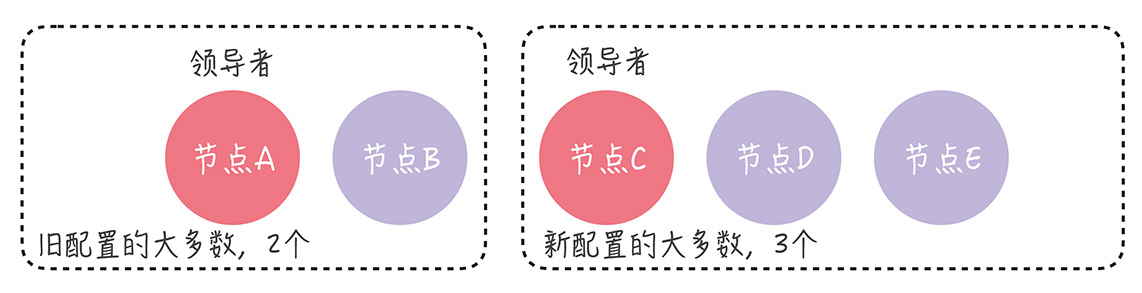
这里最大的风险就是出现两个leader。如ABC中发生分区错误,AB成旧配置中的“大多数”,A成为领导者;C与DE组成新配置,成为了新的“大多数”,C成为领导者。
单节点变更
通过一次变更一个节点实现成员变更,变更多节点则要执行多次单节点变更。
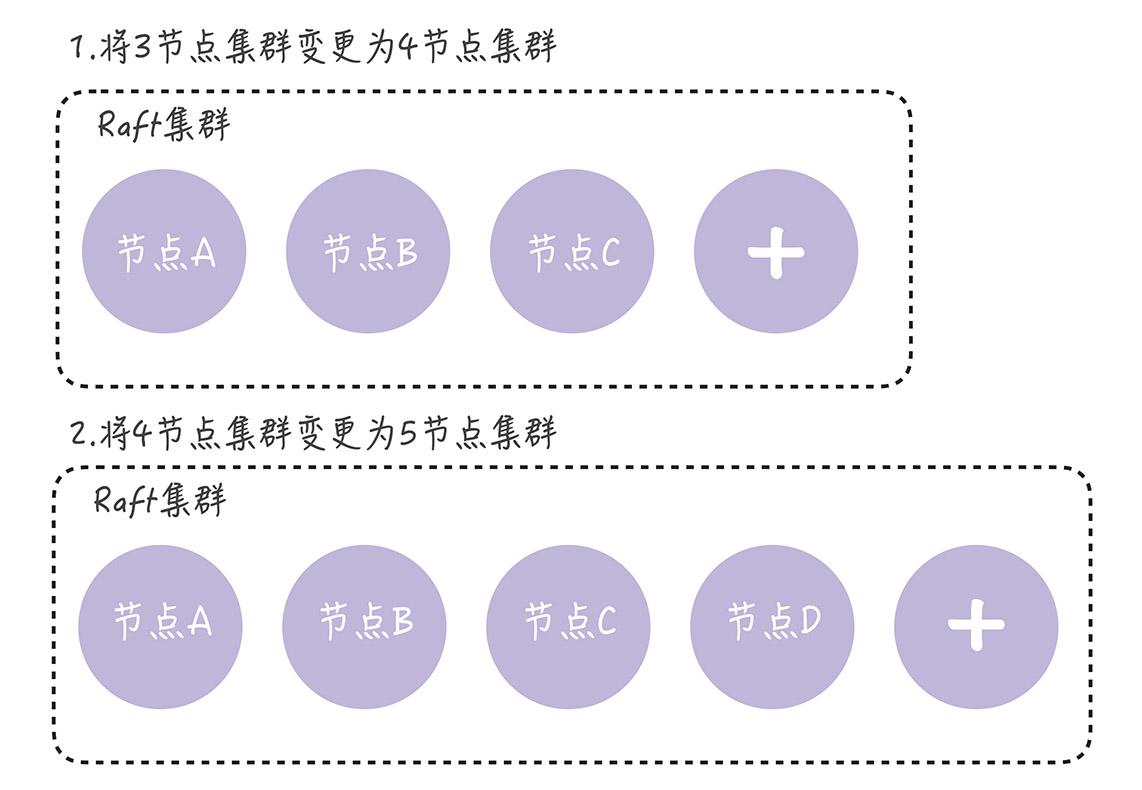
3节点增加节点D
集群配置[A、B、C] 加入节点 D 变为新配置 [A, B, C, D],过程分两步:
- leader(节点A)向新节点D同步数据
- leader 将新配置 [A, B, C, D] 作为一个日志项,复制到新配置中所有节点上,然后将这条日志提交,完成单节点变更
4节点增加节点E
向现在的集群配置 [A, B, C, D] 中新加节点 E,得到新配置 [A, B, C, D, E]。步骤类似:
- leader向新节点E同步数据
- leader将新配置 [A, B, C, D, E] 作为一个日志项复制到新配置所有节点上,在提交到本地状态,完成单机变更
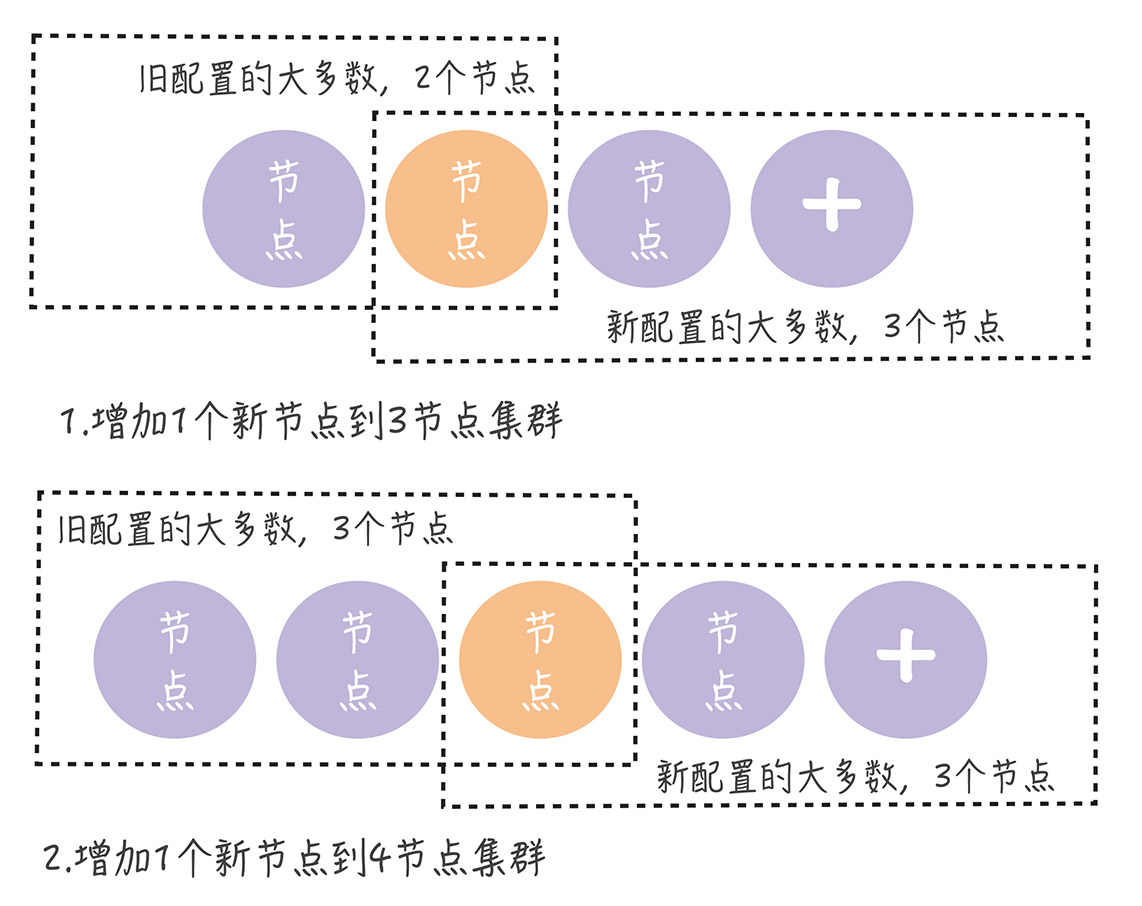
通过一次变更一个节点保证集群中始终只有一个领导者,且集群稳定运行提供服务。
且无论新旧配置如何组成,旧配置的“大多数”和新配置的“大多数”都有一个节点重叠。不会出现分裂为旧配置和新配置的2各“大多数”。
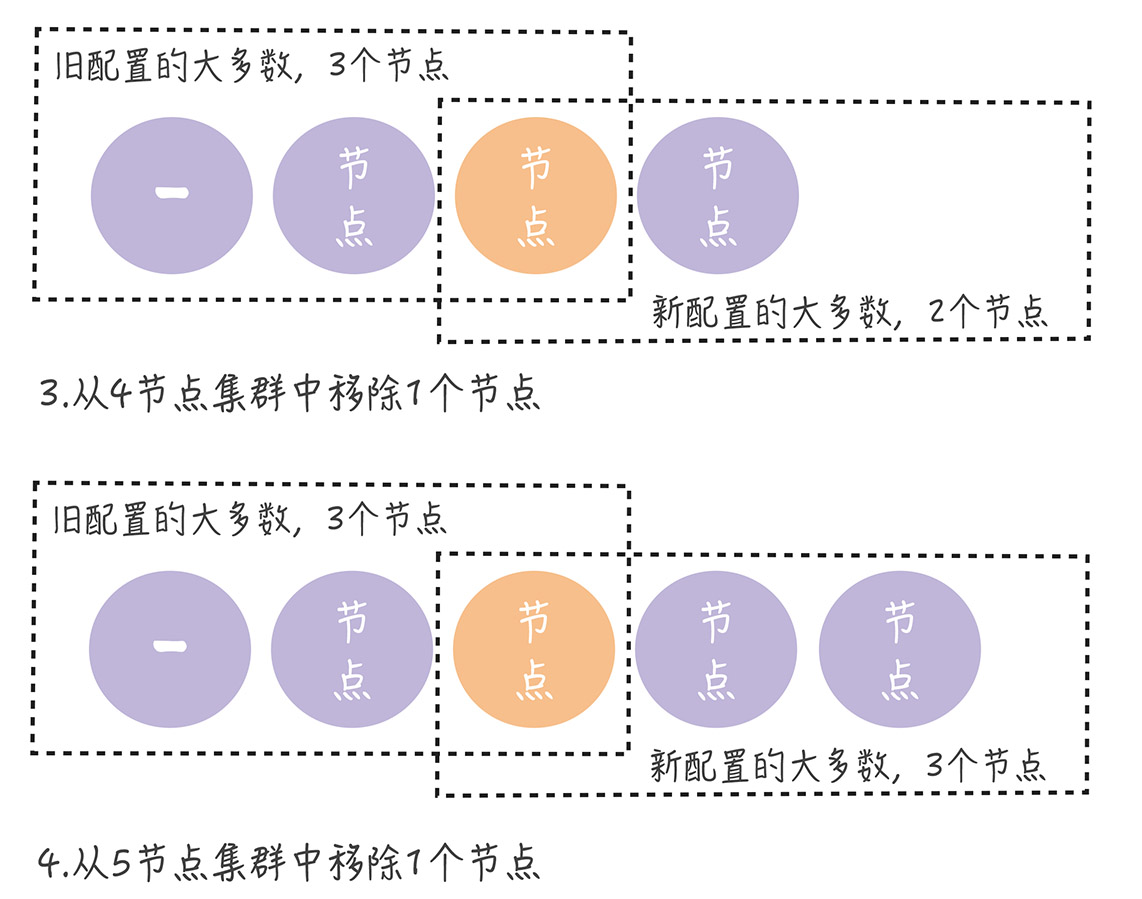
在分区错误、节点故障等情况下,若并发执行单节点变更,那么可能一次单节点变更尚未完成新的单节点变更又在执行,导致出现两个leader情况。可在leader启动时创建一个空白日志项,当leader将其提交后再执行成员变更请求。(没看懂)
总结
- 成员变更时可能不同节点使用不同配置,导致新旧两种配置共存。使得不同节点对于“大多数”的判断不同,导致出现2个leader
- 一次变更一个节点不会同时存在新旧两种配置
- 原版的联合共识算法实现复杂,很少用。大多采用了单点变更法
Raft是一种共识算法,是Multi-Paxos思想的一种实现。能容忍少数节点故障,可通过客户端协议的配合实现线性一致性。
一致性哈希
Raft的写请求只能限制在leader上,集群性能约等于单机。可通过一致性哈希分集群。
使用哈希算法分集群
使用一个proxy层,将key计算出哈希并取余得到服务器编号
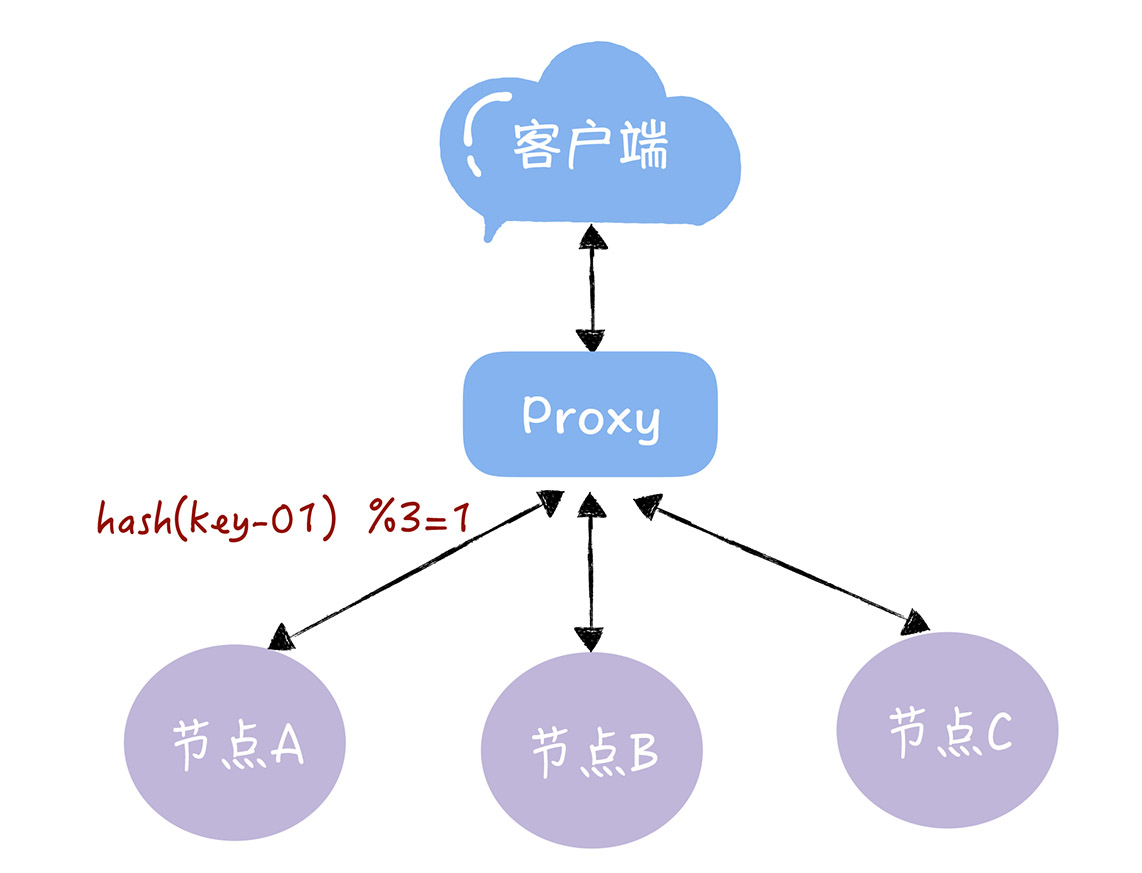
如果节点数发生变化,基于新服务器数量的方法会出现路由寻址失败,Proxy找不到之前找到的节点。例如增加到4个节点后取余得到的值与之前不同:
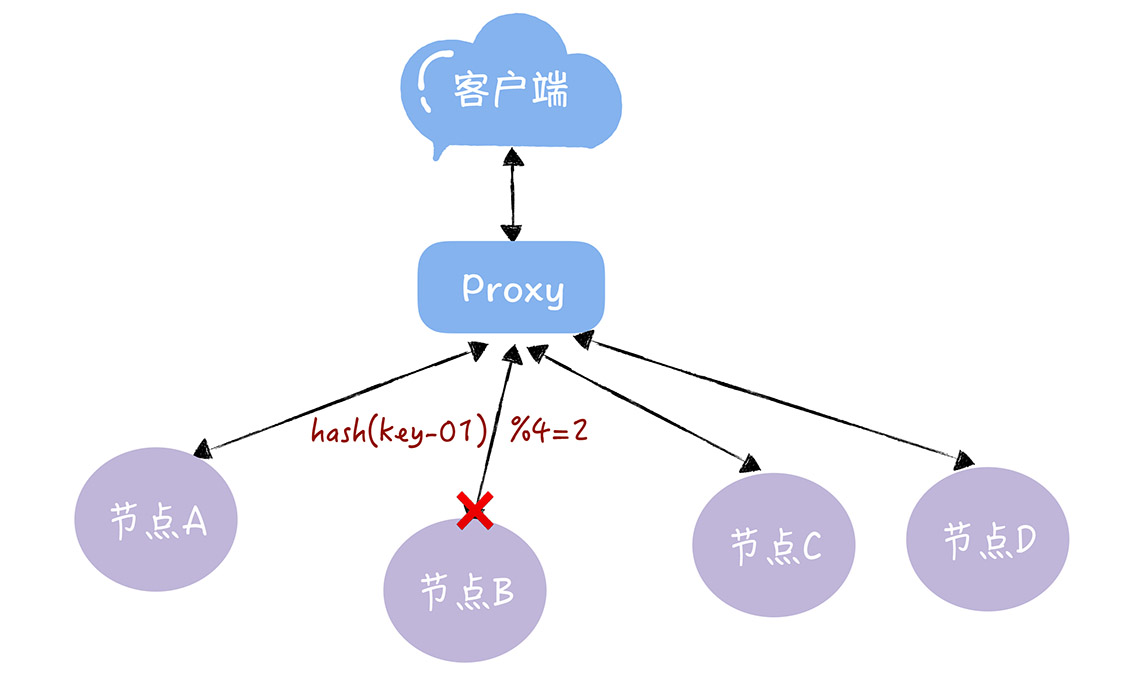
这种情况需要迁移数据,基于新的计算公式重新做数据和节点的映射。但是数据迁移的成本非常高。
一致性哈希寻址
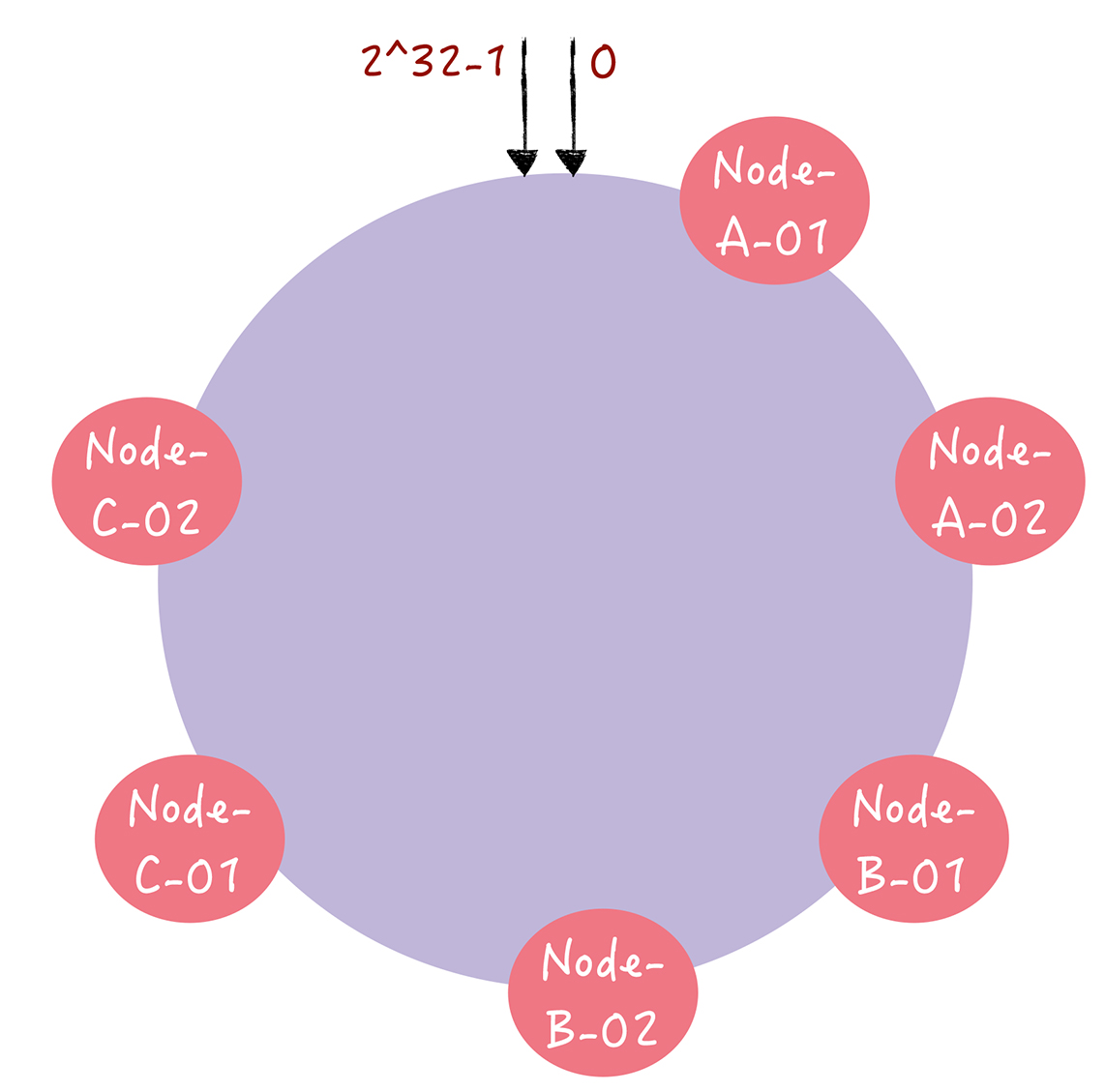
哈希算法对数量取余,而一致性哈希算法对2^32进行取余。一致性哈希算法将整个哈希值组成一个虚拟的哈希环。
用 c-hash 代表哈希算法函数,将节点主机名作为参数通过函数映射到哈希环上。对指定key进行读写时通过2步进行寻址:
- 将key作为参数执行c-hash函数得到哈希值,确定在换上的位置。
- 沿着环行走,遇到的第一个节点就是key对应节点
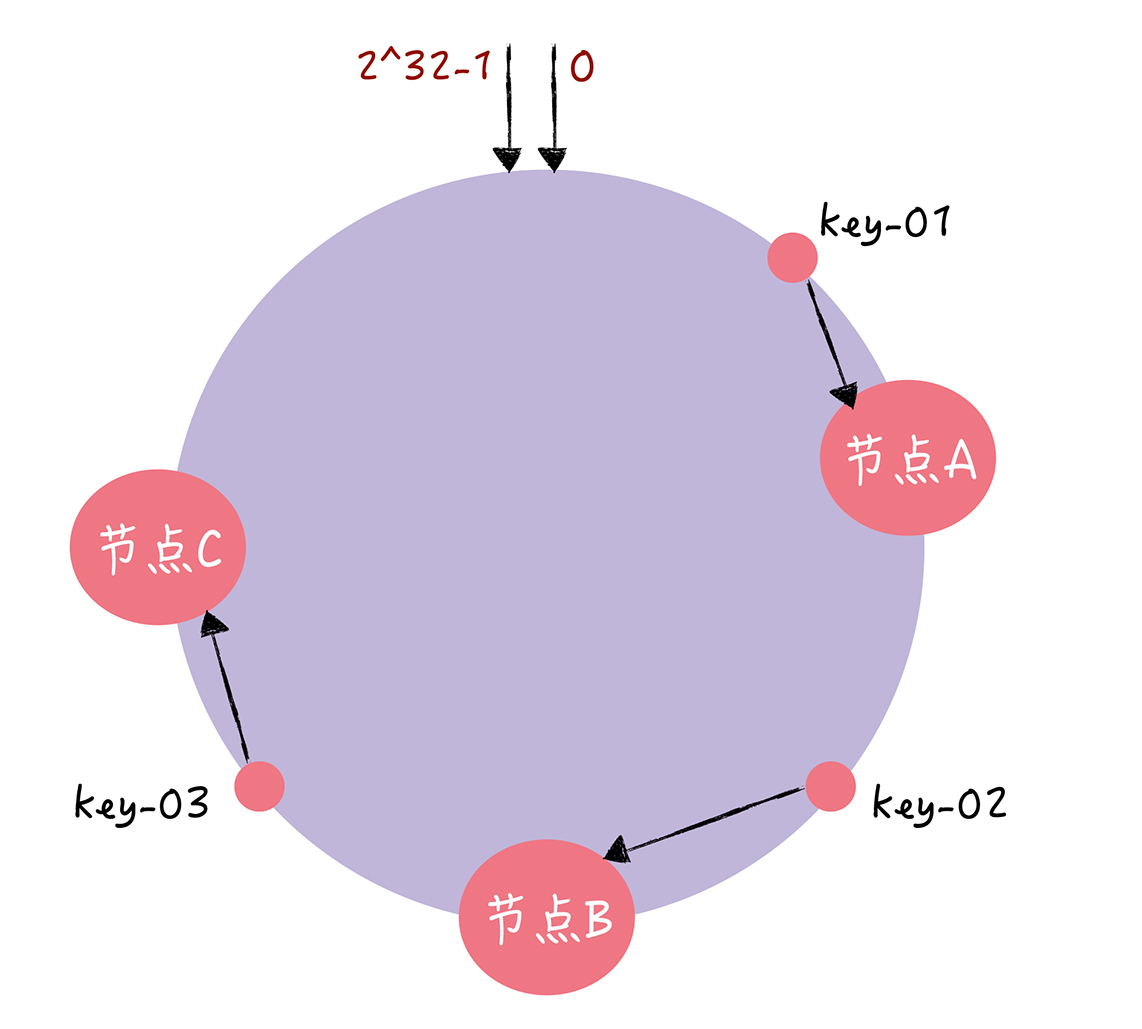
key-01,key-02,key-03 分别映射到 A B C 上。
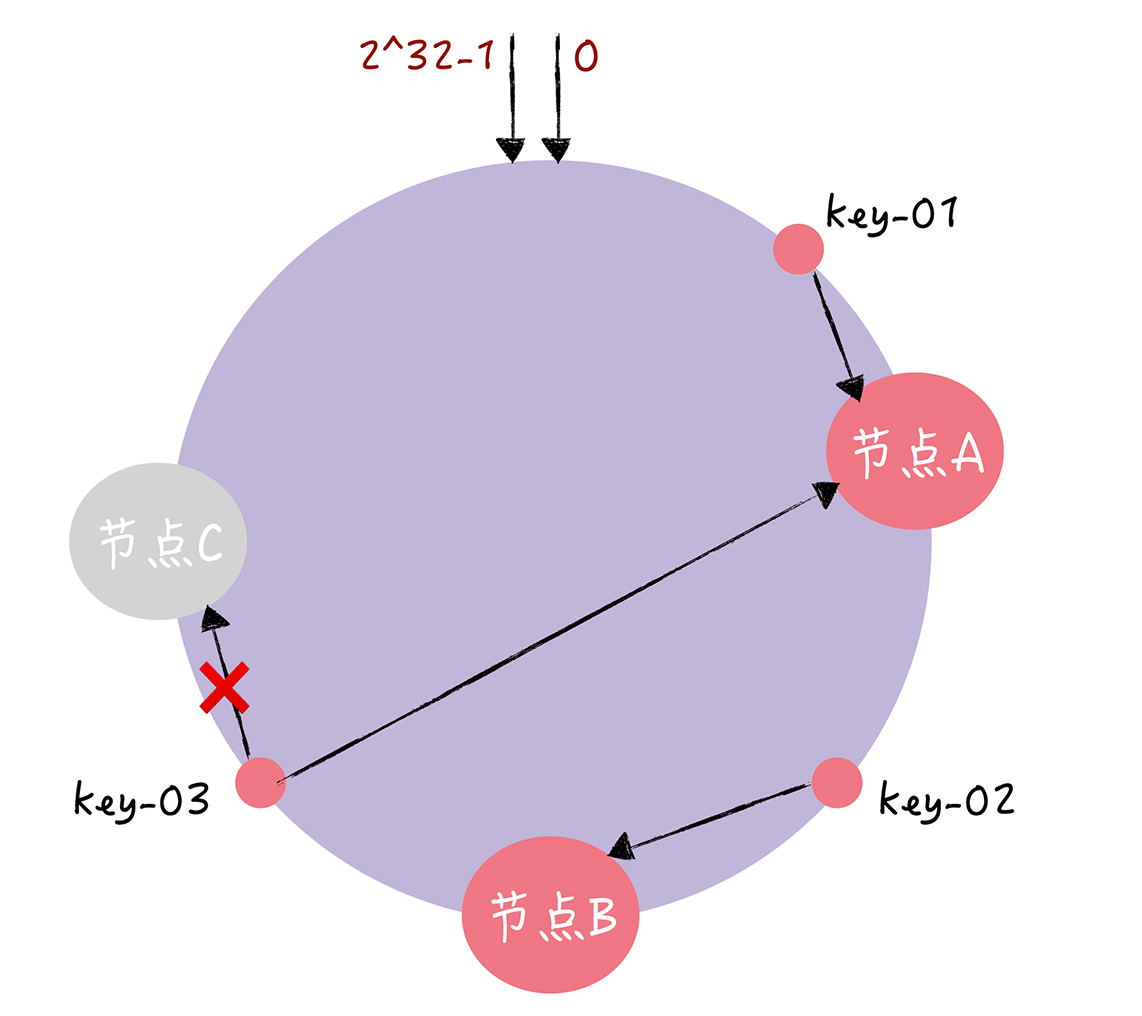
当节点故障后原本映射到其的数据映射到下一个节点,如图,只有原本映射到BC间的数据在寻址时受到影响,映射到A。
扩容时环上位于新增节点前的数据被定位到新节点
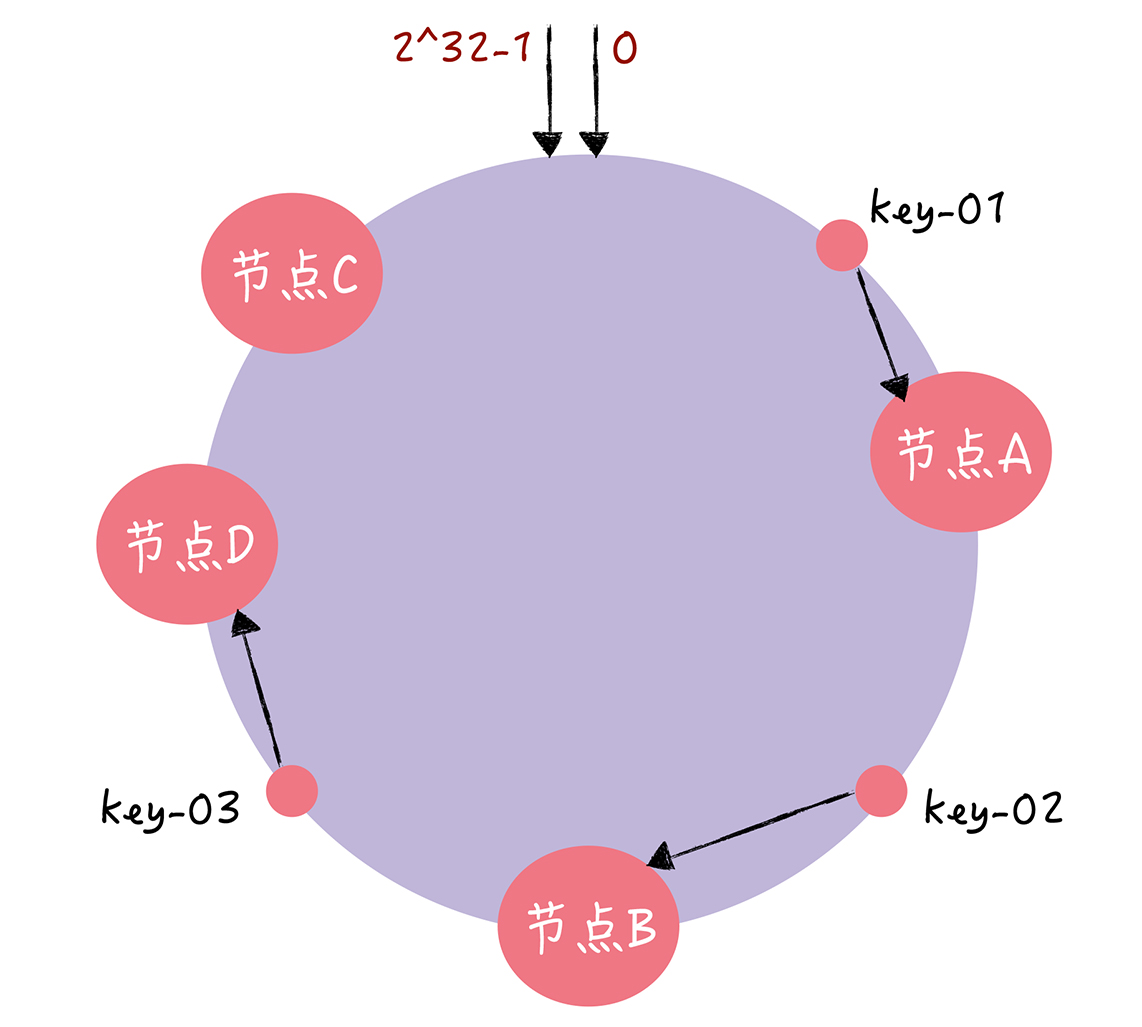
使用一致性哈希算法后扩容和缩容都只要重定位环空间中一小部分数据,拥有较好的容错性和可拓展性。
冷热不均
如果节点太少,可能节点分布不均匀,大多数请求分布在少量几个节点上。可通过虚拟节点解决冷热不均的问题。比如为每个机器再起几个别名,使其对应更多的虚拟节点:
使用一致性哈希后机器数量越多,迁移时的影响越小。
总结
- 一致性哈希是一种特殊的哈希算法,节点增减只影响部分数据的路由寻址
- 节点较少时可能出现节点在哈希环分布不均的现象,导致冷热不均,可通过引入虚拟节点解决
- 一致性哈希本质是一种简单路由寻址算法,特点是无需维护路由信息。适合简单场景,如KV存储系统内部等
