
K-BERT
预训练大模型如Bert,通过大规模语料库训练获得一般性常识,缺少领域知识。可以注入三元组作为领域知识。但过多的知识参入使句子偏离原本意思,被称为“知识噪音”(KN:knowledge noise)。通过引入 soft-position 和 visible matrix 限制知识的影响。K-Bert能加载任何预训练模型,因为他们的参数是相同的;而且注入知识时无需训练,无需大量计算资源。
- 提高语言模型在特定领域的能力
- 降低模型训练成本
- 因注入知识可手动编辑,故具有可解释性
两个挑战:
- 异构嵌入空间(Heterogeneous Embedding Space HES):文本中单词与知识的来源不一致,使得嵌入向量空间不一致
- 知识噪音(Knowledge Noise KN):过多知识参入使句子偏离原意
贡献:
- 提出K-BERT模型,在没有HES和KN的情况下注入知识
- 注入知识后在专业领域和开放领域想过都很好
结构
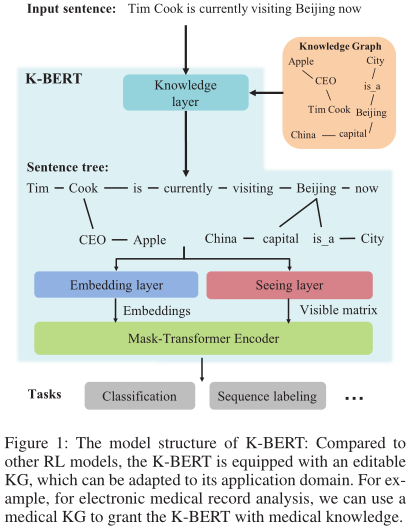
主要分4部分:
- Knowledge Layer:将输入语句注入三元组,生成带有知识的语句树
- Embedding layer:将带知识的语句树转化为token层的嵌入表示
- Seeing layer:将带知识的语句数转化为可见矩阵,可见矩阵用于解决知识噪音的问题
- Mask-Transformer Encoder
Knowledge Layer
用于注入句子知识和句子树转换,分两步:
- knowledge query (K-Query):查询语句中所有实体在知识图谱中对应的三元组
- knowledge injection (K-Inject):将查询到的三元组组合到对应的句子位置上,一个树可以有多个分支,但深度只为1

输入为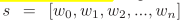 输出为
输出为
Embedding layer
用于将句子树转化为能被Mask-Transformer接收的嵌入表示,与bert类似都有词嵌入、位置嵌入、段落嵌入3种方式,但是K-Bert输入的是句子树而非token序列。如何转换句子树同时保留结构信息是关键。
Token Embedding
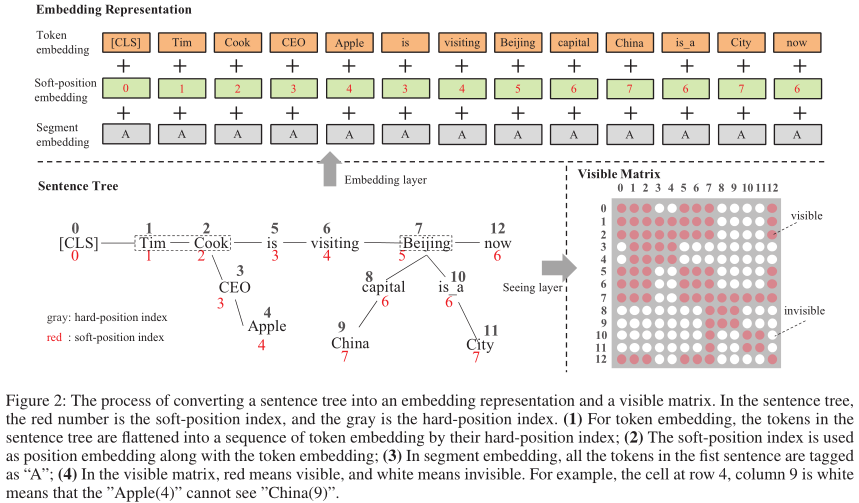
为了使句子树能够被bert接收,将树中的分支重排序插入相应节点后面。这个过程使得句子不可读且可能改变语义,不过 soft-position 和 visible matrix 可解决问题。
如图中关于“蒂姆库克到北京”的句子数被修改为“Tim Cook CEO Apple is visiting Beijing capital China is a City now”。
Soft-position embedding
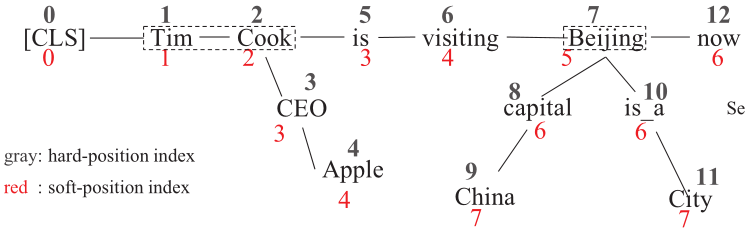
bert 通过位置编码接收结构信息,如 token 的顺序。在K-Bert中为每个词生成新的 soft-position 用于位置编码,使得按照新的编码顺序能够得到正确语义句子。
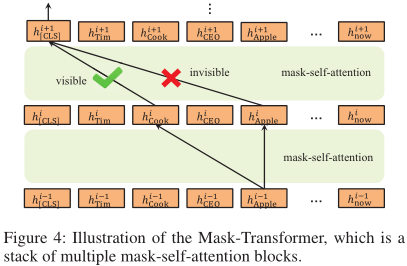
但是相同位置的词没有关联,如 is 和 CEO,这要通过 Mask-Self-Attention 解决。
下图中灰色为句子树转换后得到的语句顺序,红色是指定的软位置索引。
Segment embedding
与bert类似,K-BERT使用特殊符号 [SEP] 分割段落。
Seeing layer
解决知识噪音,即新增单词和原有句子间的冲突。使用可见性矩阵使得不相关单词不会看见对方。
可视性矩阵定义如下:
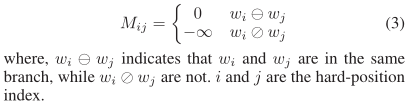
Mask-Transformer
BERT 编码器不能接受可见性矩阵作为输入,所以我们将其修改为 Mask-Transformer,其为多个 mask-self-attention 块的堆叠。
Mask-Self-Attention
mask-self-attention 公式如下:
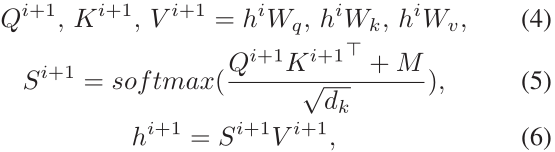
hi 和 hi+1 是隐藏层,M是可见性矩阵,M的行列编号对应语句的硬编码,每个位置对应的值代表着两个实体是否相互可见。可见性矩阵是对称矩阵。
