
GPT
GPT
继 BERT 之后,研究者们注意到了大规模预训练模型的潜力,不同的预训练任务、模型架构、训练策略等被提出。但 BERT 类模型通常存在两大缺点:一是过分依赖有标签数据;二是存在过拟合现象。
GPT1
传统NLP模型面临的两大缺点:
- 需要大量标注数据,高质量的标注数据往往很难获得
- 根据一个任务训练的模型很难迁移到其他任务
GPT使用了预训练模型,有一下难点:
- 无监督学习的优化函数,不同任务有不同的优化目标,没有通用的优化函数
- 如何将学习到的文本表示传递到子任务上,nlp的子任务差距较大,没有一致的迁移方式
无监督预训练
基于语言模型训练的,给定无标签序列 U={u1, u2, ... un} 最大化下一个词的概率
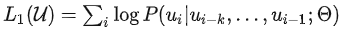 k为窗口大小,P是条件概率,Φ为模型参数
k为窗口大小,P是条件概率,Φ为模型参数
使用12个transformer解码器堆叠,然后通过全连接得到输出的概率分布
 n是层数,We是词嵌入矩阵,Wp是位置嵌入矩阵
n是层数,We是词嵌入矩阵,Wp是位置嵌入矩阵
有监督微调
得到预训练模型后通过全连接层和softmax得到预测结果,微调目标就是最大化标签概率:
预测标签的概率:
![]()
优化目标:
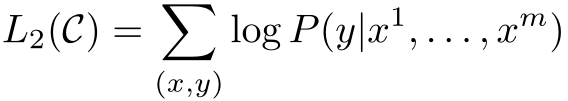
微调时同时使用词预测和序列分类效果更佳
![]()
任务相关输入
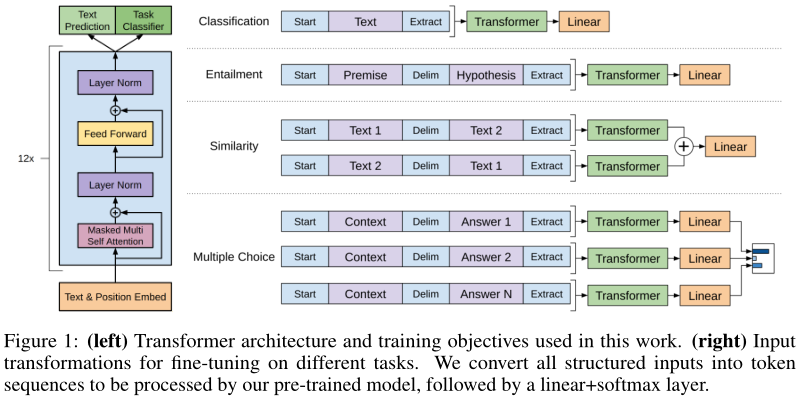
使用开始符、分割符、终止符用于区分任务
数据集
7000本未发表的书:
- 更长的上下文依赖
- 因为没发布,所以更能验证泛化能力
规模
12层transformer,每层12个头768维,有约1.17亿参数。
同等级参数下被bert打败。
特点
bert使用非标准的语言模型,使用“完形填空”可看见上下文信息;
gpt使用“预测未来”,只使用上文信息;
相同的语料gpt能获取的信息更少,但是gpt要完成的任务更加困难。
性能
在部分任务上得到了最好结果,比LSTM更加稳定。
GPT-1有很强的泛化能力,能很好的迁移到其他任务中去。
未经微调的模型也有效果但是不显著,GPT-1是简单领域专家,而非通用NLP机器人。
GPT2
旨在训练一个泛化能力更强的词向量模型,网络架构上在每个self-attention后添加一个Layer Normalization,没有过多的创新。作者认为单一领域数据集上的单一任务训练的流行是当前系统中观察到的缺乏泛化的主要原因。
核心思想
根据上文预测下文可表示为
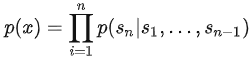 或
或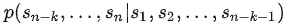
因此语言模型可表示为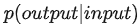
有监督任务可表示为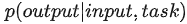
任何有监督任务都是语言模型的一个子集,当模型的容量非常大且数据量足够丰富时,仅仅靠训练语言模型的学习便可以完成其他有监督学习的任务。
zero-shot
无需修改就可以应用于下游任务,这要求不能使用预训练时没有使用过的符号,如开始、分割、终止符
如:(translate to french, english text, french text) (answer the question, documnet, question, answer) 开头词语为提示符prompt,代替了gpt1中的符号
数据集
名为WebText的Reddit的高赞文章,约800万篇文章,累计40G。
模型参数
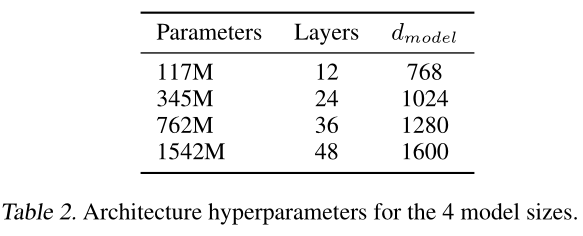
- 同样的字节对编码构建字典,大小50,257
- 滑动窗口大小512
- batchsize为512
总结
表现不优异,但是与有监督模型的效果很接近。
GPT-2的最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型有迁移到其它类别任务中而不需要额外的训练。
GPT-2表明随着模型和数据量的增大潜能还能进一步开发。
GPT3
GPT-3将模型大小增加到1750亿个参数,在子任务上做微调的代价过大,故在作用到子任务上时不使用任何的梯度更新和微调。
预训练模型存在问题
- 大量有标签数据用于微调
- 微调时使得预训练模型与任务相关数据可能过拟合,当目标任务在微调数据中没出现时泛化性不见得就很好
- 人类不需要大量数据用于有监督学习
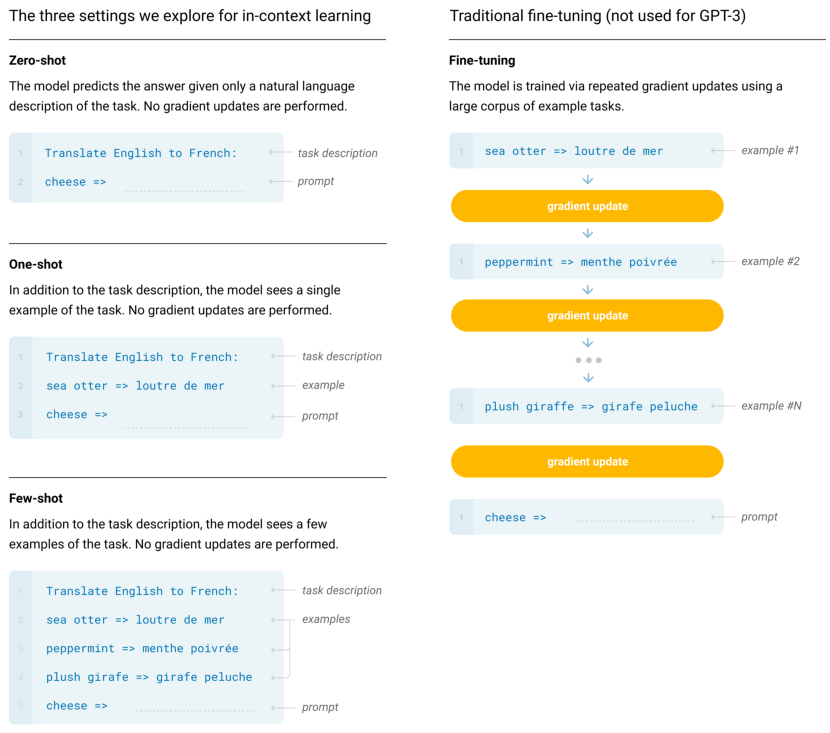
in-context learning
不进行微调,而是给出<输入 - 标签>示例即可预测。
根据给出的示例数分为:
- zero shot:只使用无标签数据训练,直接使用得到的模型
- few shot:每个子任务提供10~100训练样本,但是模型不一定能够处理长序列,所以并不一定比 one shot 好
- one shot:只有一个子任务样本,不修改模型,而是希望通过自注意力机制使得能够从中抽取信息(GPT3采用)
相应的,每次预测都要先输入一个序列
模型
zhuanlan.zhihu.com/p/350017443
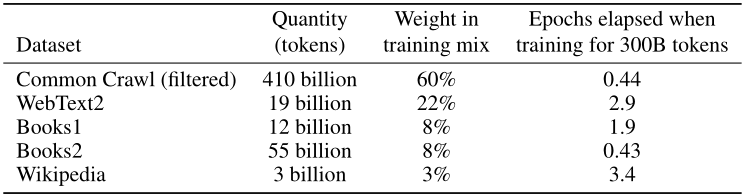
数据集
45TB的训练数据,高达1200万美元的训练费用
局限
- 不能很好的生成长文本
- 结构和算法的局限性,transformer解码器不能看到下文
- 对每个要预测的词都是等权重的,无法分辨是否重要
- 没有接触过视频音频等其他领域
- 样本有效性,GPT3使用了几乎全网络的文本
- 无法解释
总结
在所有任务上取得很好成绩。
