
时序知识图谱补全
Temporal Knowledge Graph Completion: A Survey
知识图谱补全KGC用于补全三元组的节点或链接,时序知识图谱补全TKGC用于补全带有时间信息的知识。TKGC在多个不同知识库上的表现比KGC更好。
论文考虑以下3方面:
- 根据如何将时间嵌入到链接预测对已有方法分类
- 分析TKGC方法,基准数据库,通用评估方法
- 讨论已有方法的限制和如何提升
符号定义
g=(E, R, T, F)对应中文为 图谱=(实体,关系,时间,事实) ,其中事实F为 s={h, r, t, τ},使用 s' 表示负样本,使用 q(s) q(s') 表示打分函数。目标最大化q(s') 最小化q(s)
在处理时间时,可以使用时间点或事件段。一般使用离散的时间点。
损失函数
- margin ranking loss
确保事实与负样本间差距大![]()
[x]+=max(x, 0),γ是期望的样本和负样本间差值的超参数 - 交叉损失 corss entropy loss
也专注于正负样本间差值,但没指定固定差值![]()
- 二元交叉熵损失 binary cross entropy loss
强调单个的正负样本![]()
x为正时y为1,否则为0

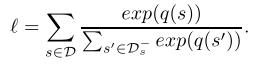
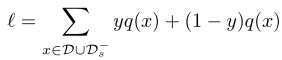
基准数据集
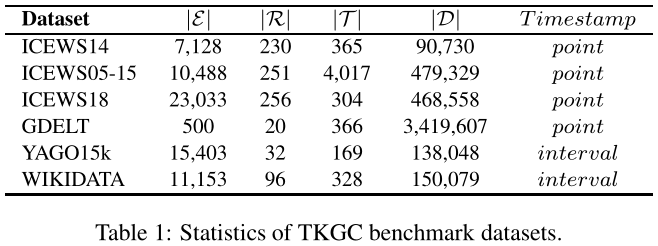
ICEWS 从 Integrated Crisis Early Warning System repository 中提取,使用时间戳表示事件
GDELT 从 Global Database of Events, Language, and Tone 中提取,使用时间戳表示事件。这个库中包含大量fact,但实体和关系较少,其中包含大量抽象的、概念性的实体。
WIKIDATA 从维基百科提取使用 “occursSince 2013” 表示时间段
YAGO 也使用时间段,但有很多没有事件,挑战较大
评测指标
Hits@k
Mean Ranking(MR)
Mean Receprocal Ranking(MRR)
TKGC 方法
包含时间戳的张量分解
轻量且容易训练。静态的张量分解是使用一个3维张量,每个维度分别表示头、尾、关系,使用分解出的低维矩阵代表实体或矩阵。时序张量分解就是添加一个时间维度。
Canonical Polyadic Decomposition(张量CP分解)
张量分解-CP分解 - 熊伏枥个人空间 (xiongfuli.com)
CP分解:
可使用4维张量处理四元组,对于静态知识给定一个虚拟时间戳。
Tucker 分解
张量分解-Tucker分解 - 熊伏枥个人空间 (xiongfuli.com)

基于时间的翻译模型
将时间和关系合并
如 {Lakers, championOf, N BA, 2010} 变为 {Lakers, championOf:2010, N BA}
如: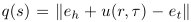 ,其中函数u将关系和时间融合,可选择的操作有: 连接er:τ;相加 er + eτ;相乘 pτ*er (可学习时pτ为1否则为0),实验表明相加效果最好。
,其中函数u将关系和时间融合,可选择的操作有: 连接er:τ;相加 er + eτ;相乘 pτ*er (可学习时pτ为1否则为0),实验表明相加效果最好。
线性翻译
- 将时间视为超平面,获得实体和关系在超平面的投影
- 通过乘积将实体映射到某个时间的复空间中
动态嵌入
关系会随着时间的变化而有规律的变化
关于时间的函数嵌入
e = estatic + trend(τ) + seasonal(τ) + Ntrend和seasonal都是关于时间的函数,N为随机噪音。或者采用更复杂的双曲线等函数。
使用RNN的隐藏层嵌入
将时间作为隐藏层传递,类型RNN结构
通过知识图谱快照学习
原始的静态知识图谱可以看作某个时间上的知识的快照。
马尔可夫方法
将知识图按照一阶马尔可夫过程随时间演化。即知识图快照的状态依赖于它的前一个快照,通过一个概率转移矩阵进行更新。模型训练以递归更新的方式实现,静态嵌入被用作有效的初始化。
自回归模型
使用历史上下文推理
知识图谱中事实的顺序按照时间戳排序,可以通过查询上下文预测缺失的链接。
Attention-based Relevance
使用注意力机制选择性地选取相关事实。
Heuristic-based Relevance
使用外部知识作为启发。可以通过历史趋势进行打分,且某件事大概率曾经在历史上发生过。
未来趋势
- 使用外部数据,例如使用预训练模型
- 涉及时间戳的负样本
- 大规模的基于时间的知识图谱
- TKGC的增量学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号