

RabbitMQ实战指南
RbbitMQ
作用:
- 解耦
- 冗余(存储)
- 扩展性
- 削峰
- 可恢复性
- 顺序保证
- 缓冲
- 异步通信
RabbitMQ从最初就实现了一个特性:使用协议本身就可以对队列和交换器(Exchange)这样的资源进行配置。
工作模型
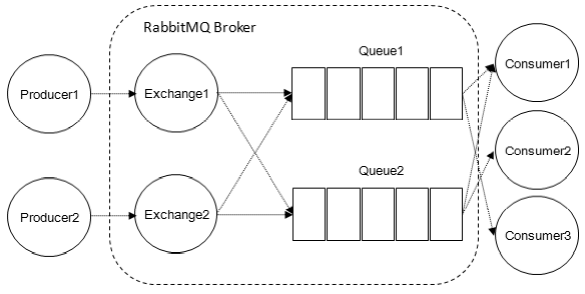
- Exchange
交换机,将消息路由到一个或多个队列种,若路由不到则返回给producer或丢弃。有4种类型- direct:消息发送到BindingKey和RoutingKey完全匹配的队列
- fanout:消息发送到所有绑定队列
- topic:BindingKey和RoutingKey模糊匹配,使用点分单词列表,
*代表一个单词,#代表零个或多个单词 - headers:使用消息的headers键值对匹配(不实用,基本看不见)
- RoutingKey
Producer将消息发给交换机时携带的label,用于指定路由规则。要与Exchange的BIndingKey联合使用才能生效 - Binding
将Exchange和Queue关联起来,同时会指定一个绑定键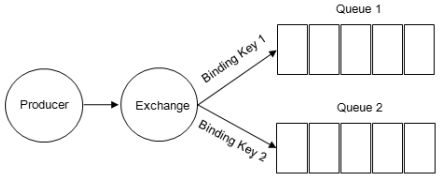
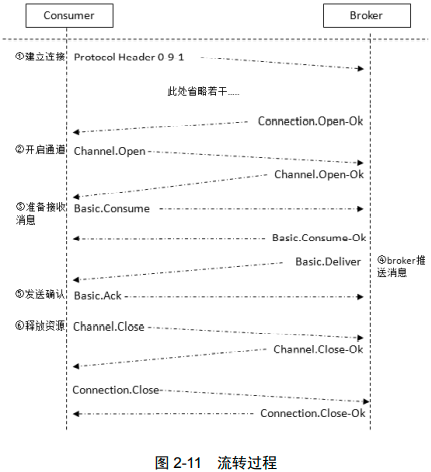
生产者流程
- Producer连接到mq,建立Connection,创建Channel
- 指定Exchange
- 指定Queue
- 通过BindingKey绑定Exchange和Queue
- 发送消息
- Exchange根据RoutingKey匹配Queue
- 找到则发送,没有则丢弃或回退
- 关闭Channel
- 关闭Connection
消费者流程
- Consumer连接到mq,建立Connection,创建Channel
- 向mq请求相应队列种消息
- 接收消息并处理。java使用回调函数,go使用channel
- 自动或手动回复ack
- mq从Queue种删除被确认消息
- 关闭Channel
- 关闭Connection
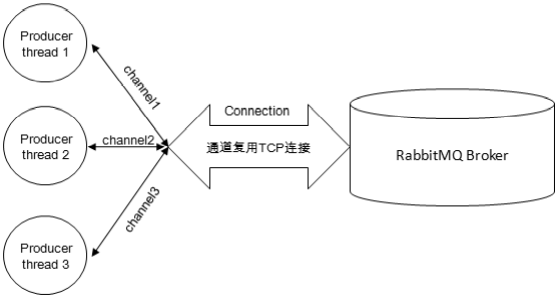
一个Connection对应一个TCP连接,线程安全;多个Channel复用一个Connection,线程不安全。当数据量大时需要使用多个Connection调优
Exchange用于路由,发送消息时只要指定它即可,无需指定Queue
Queue用于暂存数据,有Queue存在MQ才能保持数据;双方都能够创建和绑定。
Producer没有创建Queue而直接向Exchange发送消息,如果此时没有Consumer则会丢失消息
推荐Producer和Consumer都使用ExchangeDeclare和QueueDeclare显式指定,如果已存在同名且属性不同的Exchange和Queue则会创建失败,若名称和属性都相同则使用已有组件
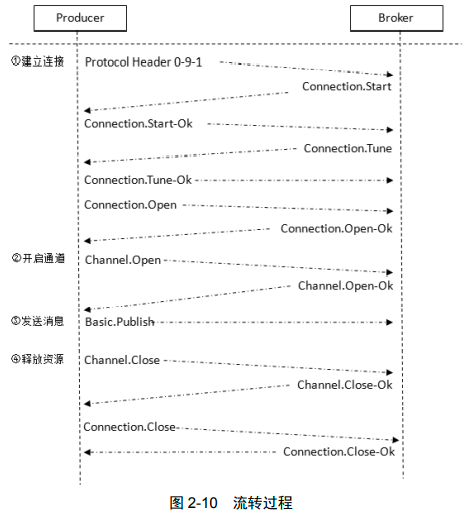
AMQP协议
是一种位于TCP之上的应用层协议,类似HTTP,涉及到 Connection.Start Connection.Start-Ok等命令
生产者
消费者
5种模式
官网展示7种模式,有5种比较重要
- Simple

simple
package main import ( "context" "log" "time" "github.com/rabbitmq/amqp091-go" ) func failOnError(err error, msg string) { if err != nil { log.Fatalf("%s: %s", msg, err) } } func main() { var err error conn, err := amqp091.Dial("amqp://guest:guest@192.168.56.121:5672/vhost") failOnError(err, "Failed to connet RabbitMQ") defer conn.Close() ch, err := conn.Channel() failOnError(err, "Failed to open channel") defer ch.Close() q, err := ch.QueueDeclare( "hello", // name false, // durable false, // delete when unused false, // exclusive false, // no-wait nil, // arguments ) failOnError(err, "Failed to declare a queue") body := "Hello world" /**************** 获取接收消息的Delivery通道 *******************/ ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second) defer cancel() err = ch.PublishWithContext( ctx, "", // exchange q.Name, // routing key false, // mandatory false, // immediate amqp091.Publishing{ ContentType: "text/plain", Body: []byte(body), }) failOnError(err, "Failed to publish a message") log.Printf(" [x] Sent: %s\n", body) /**************** 获取接收消息的Delivery通道 *******************/ msgs, err := ch.Consume( q.Name, // queue "", // consumer true, // auto-ack false, // exclusive false, // no-local false, // no-wait nil, // args ) failOnError(err, "Failed to register a consumer") d := <-msgs log.Printf("%s", d.Body) } - Work Queues
多个消费者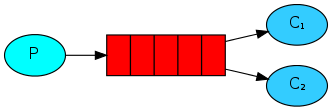
producer
package main import ( "context" "log" "strconv" "time" "github.com/rabbitmq/amqp091-go" ) func failOnError(err error, msg string) { if err != nil { log.Fatalf("%s: %s", msg, err) } } func main() { var err error conn, err := amqp091.Dial("amqp://guest:guest@192.168.56.121:5672/vhost") failOnError(err, "Failed to connet RabbitMQ") defer conn.Close() ch, err := conn.Channel() failOnError(err, "open a channel failed") defer ch.Close() q, err := ch.QueueDeclare( "task_queue", // name true, // 持久的 false, // delete when unused false, // 独有的 false, // no-wait nil, // arguments ) failOnError(err, "delare queue feailed") msg := "message" for i := 0; i < 10; i++ { body := msg + strconv.Itoa(i) ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second) defer cancel() err = ch.PublishWithContext( ctx, "", q.Name, false, false, amqp091.Publishing{ DeliveryMode: amqp091.Persistent, ContentType: "text/plain", Body: []byte(body), }) failOnError(err, "publish message failed") log.Printf("Sent: %s", body) } }consumer
package main import ( "log" "time" "github.com/rabbitmq/amqp091-go" ) func failOnError(err error, msg string) { if err != nil { log.Fatalf("%s: %s", msg, err) } } func main() { var err error conn, err := amqp091.Dial("amqp://guest:guest@192.168.56.121:5672/vhost") failOnError(err, "Failed to connet RabbitMQ") defer conn.Close() ch, err := conn.Channel() failOnError(err, "open a channel failed") defer ch.Close() q, err := ch.QueueDeclare( "task_queue", // name true, // 持久的 false, // delete when unused false, // 独有的 false, // no-wait nil, // arguments ) failOnError(err, "delare queue feailed") //将预取计数设置为1,在处理并确认一条消息前,不要向worker发送新消息 err = ch.Qos( 1, // prefetch count 0, // prefetch size false, // global ) failOnError(err, "ch.Qos() failed") // 立即返回一个Delivery的通道 msgs, err := ch.Consume( q.Name, // queue "", // consumer false, // 注意这里传false,关闭自动消息确认 false, // exclusive false, // no-local false, // no-wait nil, // args ) failOnError(err, "consume failed") go func() { for d := range msgs { log.Printf("Received message: %s", d.Body) d.Ack(false) time.Sleep(time.Second) } }() <-make(chan bool) } - Publish/Sublish
多个消费者接收到相同内容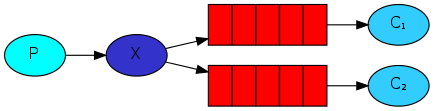
publish
package main import ( "log" "strconv" "time" "github.com/rabbitmq/amqp091-go" ) func failOnError(err error, msg string) { if err != nil { log.Fatalf("%s: %s", msg, err) } } func main() { var err error conn, err := amqp091.Dial("amqp://guest:guest@192.168.56.121:5672/vhost") failOnError(err, "Failed to connet RabbitMQ") defer conn.Close() ch, err := conn.Channel() failOnError(err, "Failed to open channel") defer ch.Close() err = ch.ExchangeDeclare( "logs", // 使用命名的交换器 "fanout", // 交换器类型 true, // durable false, // auto-deleted false, // internal false, // no-wait nil, // arguments ) failOnError(err, "Failed to declare an exchange") msg := "message" for i := 0; i < 10; i++ { body := msg + strconv.Itoa(i) err = ch.Publish( "logs", // exchange "", // routing key false, // mandatory false, // immediate amqp091.Publishing{ ContentType: "text/plain", Body: []byte(body), }) log.Printf("Sent: %s", body) time.Sleep(time.Second) } }subscribe
package main import ( "log" "time" "github.com/rabbitmq/amqp091-go" ) func failOnError(err error, msg string) { if err != nil { log.Fatalf("%s: %s", msg, err) } } func main() { var err error conn, err := amqp091.Dial("amqp://guest:guest@192.168.56.121:5672/vhost") failOnError(err, "Failed to connet RabbitMQ") defer conn.Close() ch, err := conn.Channel() failOnError(err, "Failed to open channel") defer ch.Close() err = ch.ExchangeDeclare( "logs", // 使用命名的交换器 "fanout", // 交换器类型 true, // durable false, // auto-deleted false, // internal false, // no-wait nil, // arguments ) failOnError(err, "Failed to declare an exchange") q, err := ch.QueueDeclare( "", // 空字符串作为队列名称 false, // 非持久队列 false, // delete when unused true, // 独占队列(当前声明队列的连接关闭后即被删除) false, // no-wait nil, // arguments ) failOnError(err, "queue declare failed") err = ch.QueueBind( q.Name, // queue name "", // routing key "logs", // exchange false, // no-wait nil, ) failOnError(err, "bind failed") msgs, err := ch.Consume( q.Name, // queue "", // consumer true, // auto-ack false, // exclusive false, // no-local false, // no-wait nil, // args ) failOnError(err, "Failed to register a consumer") go func() { for d := range msgs { log.Printf("receve: %s", d.Body) time.Sleep(500 * time.Microsecond) } }() <-make(chan bool) } - Routing
根据字符串选择消息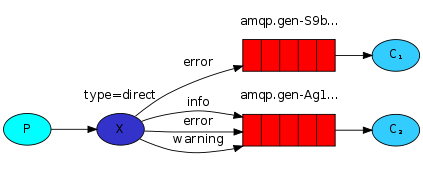
pub
package main import ( "context" "log" "strconv" "time" "github.com/rabbitmq/amqp091-go" ) func failOnError(err error, msg string) { if err != nil { log.Fatalf("%s: %s", msg, err) } } func main() { var err error conn, err := amqp091.Dial("amqp://guest:guest@192.168.56.121:5672/vhost") failOnError(err, "Failed to connet RabbitMQ") defer conn.Close() ch, err := conn.Channel() failOnError(err, "Failed to open channel") defer ch.Close() msg := "message" for i := 0; i < 10; i++ { ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second) defer cancel() body := msg + strconv.Itoa(i) err = ch.PublishWithContext( ctx, "amq.direct", // 指定exchange类型,此处使用默认交换机 strconv.Itoa(i%2), // routing key false, // mandatory false, // immediate amqp091.Publishing{ ContentType: "text/plain", Body: []byte(body), }) failOnError(err, "Failed to publish") log.Printf("Sent %s", body) } }sub
package main import ( "log" "os" "github.com/rabbitmq/amqp091-go" ) func failOnError(err error, msg string) { if err != nil { log.Fatalf("%s: %s", msg, err) } } func main() { var err error conn, err := amqp091.Dial("amqp://guest:guest@192.168.56.121:5672/vhost") failOnError(err, "Failed to connet RabbitMQ") defer conn.Close() ch, err := conn.Channel() failOnError(err, "Failed to open channel") defer ch.Close() q, err := ch.QueueDeclare( "", false, true, true, false, nil, ) failOnError(err, "Failed to declare queue") if len(os.Args) < 2 { panic("必须传入参数 routing-key") } routingKey := os.Args[1] if routingKey != "0" && routingKey != "1" { panic("必须传入 0 或 1") } err = ch.QueueBind( q.Name, routingKey, "amq.direct", // 绑定默认交换机 false, nil) failOnError(err, "Failed to bind queue") msgs, err := ch.Consume( q.Name, // queue "", // consumer true, // auto ack false, // exclusive false, // no local false, // no wait nil, // args ) failOnError(err, "Failed to consume") go func() { for d := range msgs { log.Printf("Receve: %s", d.Body) } }() <-make(chan bool) } - Topics
根据正则表达式选择消息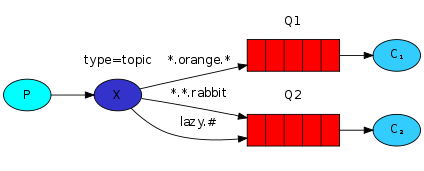
使用点分的单词列表作为 routing_key ,*代表一个单词,#代表零个或多个单词
使用#作为key时交换机和fanout类型一致
不使用*和#时与direct一致pub
package main import ( "context" "fmt" "log" "math/rand" "strconv" "time" "github.com/rabbitmq/amqp091-go" ) func failOnError(err error, msg string) { if err != nil { log.Fatalf("%s: %s", msg, err) } } var local = [...]string{"beijing", "shanghai"} var halfDay = [...]string{"AM", "PM"} func main() { rand.Seed(time.Now().Unix()) var err error conn, err := amqp091.Dial("amqp://guest:guest@192.168.56.121:5672/vhost") failOnError(err, "Failed to connet RabbitMQ") defer conn.Close() ch, err := conn.Channel() failOnError(err, "Failed to open channel") defer ch.Close() msg := "message" for i := 0; i < 10; i++ { body := msg + strconv.Itoa(i) ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second) defer cancel() topicKey := fmt.Sprintf("%s.%s", local[rand.Intn(len(local))], halfDay[rand.Intn(len(halfDay))]) err = ch.PublishWithContext( ctx, "amq.topic", topicKey, false, false, amqp091.Publishing{ ContentType: "text/plain", Body: []byte(body), }) failOnError(err, "Failed to publish") log.Printf("with topic [%s] Sent: %s", topicKey, body) } }sub
package main import ( "log" "os" "github.com/rabbitmq/amqp091-go" ) func failOnError(err error, msg string) { if err != nil { log.Fatalf("%s: %s", msg, err) } } func main() { var err error conn, err := amqp091.Dial("amqp://guest:guest@192.168.56.121:5672/vhost") failOnError(err, "Failed to connet RabbitMQ") defer conn.Close() if len(os.Args) < 2 { panic("必须有参数 topic_key") } for _, topicKey := range os.Args[1:] { ch, err := conn.Channel() failOnError(err, "Failed to open channel") defer ch.Close() q, err := ch.QueueDeclare( "", // name false, // durable false, // delete when unused true, // exclusive false, // no-wait nil, // arguments ) failOnError(err, "Failed to declare a queue") err = ch.QueueBind( q.Name, topicKey, "amq.topic", false, nil) failOnError(err, "Failed to bind queue") msgs, err := ch.Consume( q.Name, // queue "", // consumer true, // auto ack false, // exclusive false, // no local false, // no wait nil, // args ) failOnError(err, "Failed to register a consumer") key := topicKey go func() { for d := range msgs { log.Printf("channel [%10s] receve: %s", key, d.Body) } }() } <-make(chan bool) } // .\sub.exe beijing.* shanghai.* *.AM *.PM - RPC
就是使用两个Queue,一个接收参数,一个返回结果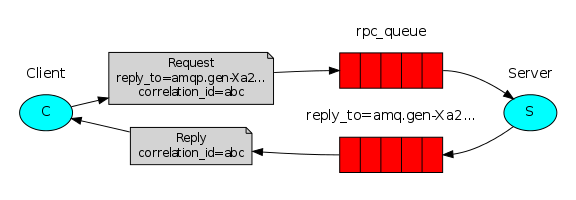
API详解
创建
// ExchangeDeclarePassive 用于判断Exchange是否存在
func (ch *Channel) ExchangeDeclare(
name, // 交换机名称
kind string, // 类型,fanout direct topic
durable, // 是否持久化到硬盘
autoDelete, // 在有至少一个Exchange或Queue与这个Exchange绑定,解绑后自动删除
internal, // 是否位内置,如果为true客户端无法直接发消息到这个Exchange种,只能通过Exchange发送
noWait bool, // 为true时,不接收server发出的是否Declare成功的信息。出错时Channel会被关闭
args Table // 结构体,其他参数
) error {
// 绑定两个Exchange
func (ch *Channel) ExchangeBind(
destination,
key,
source string,
noWait bool,
args Table
) error {
// QueueDeclarePassive 将passive参数设置为true,用于判断queue是否存在
func (ch *Channel) QueueDeclare(
name string, // 队列名称,为空字符串时返回一个由MQ创建的临时队列
durable, // 是否持久化
autoDelete, // 至少有一个消费者连接到这个Queue,之后所有消费者都断开时会自动删除
exclusive, // 是否排他,仅对首次声明它的Connection可见。
// 与普通队列不同,即使是持久化的,一旦连接关闭或client退出,该队列自动删除
noWait bool,
args Table
) (Queue, error) {
// 绑定一个Exchange和一个Queue
func (ch *Channel) QueueBind(
name, // queue名称
key, // BindingKey
exchange string, // Exchange名称
noWait bool, // 是否等待
args Table // 其他参数结构体
) error {两个Exchange绑定

发送消息
mandatory(强制的,法定的) : 参数告诉服务器至少将该消息路由到一个队列中,否则将消息返回给生产者。
immediate (立即的,直接的):(弃用)参数告诉服务器,如果该消息关联的队列上有消费者,则立刻投递;如果所有匹配的队列上都没有消费者,则直接将消息返还给生产者,不用将消息存入队列而等待消费者了。
func (ch *Channel) PublishWithContext(
ctx context.Context, // 一般使用timeoutContext
exchange, // 指定Exchange
key string, // RoutingKey
mandatory, // 为true时,找不到合适Queue时会调用 Basic.Return(AMQP协议规定的命令) 命令将消息返回给生产者
// 为false时,直接丢弃
immediate bool, // (弃用)为true时,如果匹配的队列上没有消费者,这条消息不存入队列,
// 所有匹配的队列都没有消费者时使用 Basic.Return 返回至生产者
msg Publishing
) error {
// 此函数返回一个DeferredConfirmation,用于接收消息的确认,用于确认模式
_, err := ch.PublishWithDeferredConfirmWithContext(ctx, exchange, key, mandatory, immediate, msg)
return err
}接收消息
消费分两种推和拉
使用Consume会将Channel设置为接收模式,直到取消队列的订阅为止。不能使用循环加Get代替Consume,这回严重影响性能。实现高吞吐应使用Consume
// 推模式,go中应当使用一个新协程处理chan;java中使用回调函数,由一个新的线程池调用callback
func (ch *Channel) Consume(
queue,
consumer string, 消费者标签,用于区分消费者
autoAck,
exclusive, 是否排他
noLocal, The noLocal flag is not supported by RabbitMQ.
noWait bool,
args Table
) (<-chan Delivery, error) {
// 拉模式,一次只获取一条
func (ch *Channel) Get(
queue string,
autoAck bool
) (msg Delivery, ok bool, err error) {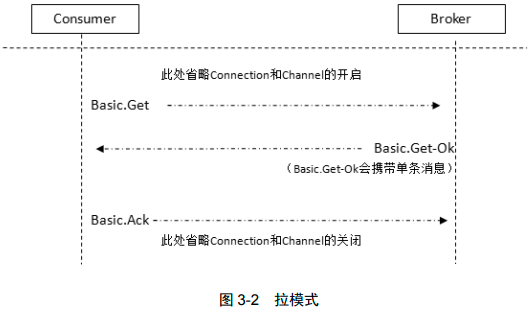
消息确认与拒绝
autoAck为true时,自动把发出的消息置为确认,不管消费者是否真的消费到;
为false时,将发出的消息标记为删除,接收到Ack后才从内存或磁盘删除,如果一直没有ack且消费者断开则重发。
建议使用false
func (ch *Channel) Reject(
tag uint64, // 即 Channel.DeliveryTag,是消息的编号
requeue bool // 为true则mq发给下一个订阅者
// 为false则mq丢弃,启用“死信队列”
) error {
// 批量拒绝
func (ch *Channel) Nack(
tag uint64,
multiple bool, // 为false时与前一个一样,为true时拒绝所有tag标号之前的未被当前消费者确认的消息
requeue bool
) error {
// 让mq重发未被确认的消息
func (ch *Channel) Recover(
requeue bool // 为false则发给相同消费者,为true则可能发给任何消费者
) error {高级设置
备份交换机 Alternate Exchange
未被路由的消息会被存在MQ中
t := amqp091.NewConnectionProperties() // t就是 map[string]interface{}
t["alternate-exchange"] = "altExg"
err = ch.ExchangeDeclare(
"myAe",
"fanout", // 如果为其他,可能因为不匹配而丢失信息
true,
false,
false,
false,
t,
)
// ...绑定队列...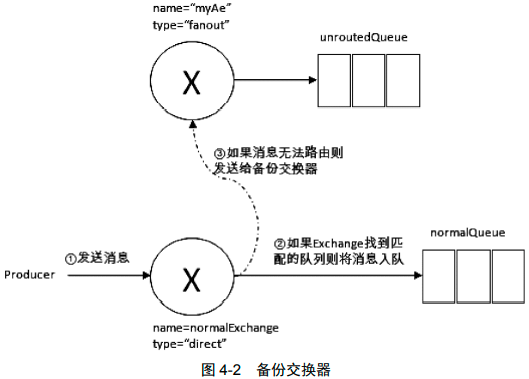
- 如果设置的备份交换器不存在,客户端和 RabbitMQ 服务端都不会有异常出现,此时消息会丢失。
- 如果备份交换器没有绑定任何队列,客户端和 RabbitMQ 服务端都不会有异常出现,此时消息会丢失。
- 如果备份交换器没有任何匹配的队列,客户端和 RabbitMQ 服务端都不会有异常出现,此时消息会丢失。
- 如果备份交换器和 mandatory 参数一起使用,那么 mandatory 参数无效。
TTL
毫秒为单位
设置消息的 TTL
- 通过队列属性设置
过期的一定在队列头部,一旦过期立即从队列中抹去
// 如果不设置 TTL,则表示此消息不会过期;如果将 TTL 设置为 0, // 则表示除非此时可以直接将消息投递到消费者,否则该消息会被立即丢弃 t := amqp091.NewConnectionProperties() t["x-message-ttl"] = 6000 q, err := ch.QueueDeclare( "tmp_queue", true, false, false, false, t) - 对消息本身进行单独设置
每条消息的过期时间不同,即使过期也不会立即抹去,是在即将投递到消费者之前判定的
err = ch.PublishWithContext( ctx, "amq.topic", topicKey, false, false, amqp091.Publishing{ ContentType: "text/plain", Body: []byte(body), Expiration: "600", // 设置超时时间 })
以两者之间较小的那个数值为准
一旦超过设置的 TTL 值时,就会变成“死信”(Dead Message)
设置队列的 TTL
控制队列被自动删除前处于未使用状态的时间。未使用的意思是队列上没有任何的消费者,队列也没有被重新声明,且在过期时间段内也未调用过 Basic.Get 命令。
RabbitMQ 会确保在过期时间到达后将队列删除,但是不保障删除的动作有多及时。在RabbitMQ 重启后,持久化的队列的过期时间会被重新计算。
t := amqp091.NewConnectionProperties()
t["x-expires"] = 1800000
q, err := ch.QueueDeclare(
"tmp_queue",
true,
false,
false,
false,
t)死信队列
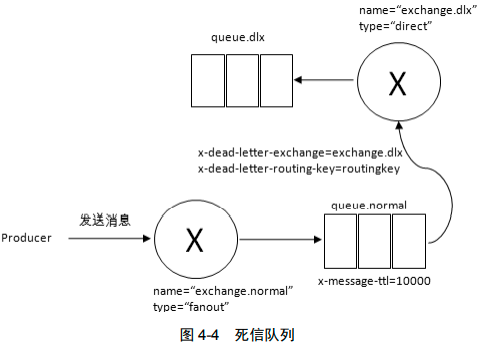
DLX,全称为 Dead-Letter-Exchange,可以称之为死信交换器。消息变为死信后发到DLX
消息变成死信一般是由于以下几种情况:
- 消息被拒绝(Basic.Reject/Basic.Nack),并且设置 requeue 参数为 false;
- 消息过期;
- 队列达到最大长度。
DLX 也是一个正常的交换器,和一般的交换器没有区别,它能在任何的队列上被指定,实际上就是设置某个队列的属性。当这个队列中存在死信时,RabbitMQ 就会自动地将这个消息重新发布到设置的 DLX 上去,进而被路由到另一个队列,即死信队列。
通过在 channel.queueDeclare 方法中设置 x-dead-letter-exchange 参数来为这个队列添加 DLX
t := amqp091.NewConnectionProperties()
t["x-message-ttl"]="10000"
t["x-dead-letter-exchange"]="dlx_exchange" // 指定死信交换机
t["x-dead-letter-routing-key"]="routingkey"
q, err := ch.QueueDeclare(
"task_queue", // name
true, // 持久的
false, // delete when unused
false, // 独有的
false, // no-wait
t, // arguments
)
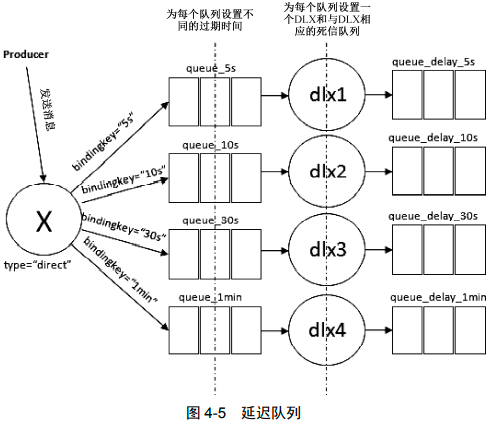
延迟队列
DLX 配合 TTL 使用还可以实现延迟队列的功能
优先级队列
通过设置队列的 x-max-priority 参数来设置队列最大优先级,每次发送消息时设置消息优先级
t := amqp091.NewConnectionProperties()
t["x-max-priority"]=10 // 设置的是队列的最大优先级
q, err := ch.QueueDeclare("task_queue",true,false,false,false,t)
err = ch.Publish(
"logs", // exchange
"", // routing key
false, // mandatory
false, // immediate
amqp091.Publishing{
ContentType: "text/plain",
Body: []byte(body),
Priority: 5, // 每次发送消息时都要设置优先级
})持久化
Exchange、Queue 通过创建时的durable参数设置。
队列的持久化能保证其本身的元数据不会因异常情况而丢失,但是并不能保证内部所存储的
消息不会丢失。消息持久化要在发送时设置。
写入磁盘非常慢,所以持久化对吞吐量影响非常大
持久化不能保证数据百分比不丢失:写入磁盘时先写入系统缓存,然后调用 fsync 同步存盘,如果此时宕机,消息将丢失。
可以使用主从复制的镜像队列机制,master挂掉,自动切到slave。仍有可能丢失数据,但是可靠多了。
只设置消息的持久化,重启之后队列消失,继而消息也丢失。单单设置消息持久化而不设置队列的持久化显得毫无意义。
err = ch.Publish(
"logs", // exchange
"", // routing key
false, // mandatory
false, // immediate
amqp091.Publishing{
ContentType: "text/plain",
Body: []byte(body),
DeliveryMode: 2, // 实现消息持久化
})生产者确认
默认情况下发送消息的操作是不会返回任何信息给生产者的,生产者是不知道消息有没有正确地到达服务器。
两种解决方案:
- 事务机制
- 发送方确认机制
事务机制
java中使用
channel.txSelect()
channel.txCommit()
channel.txRollback()go中使用
ch.Tx()
ch.TxCommit()
ch.TxRollback()事务提交
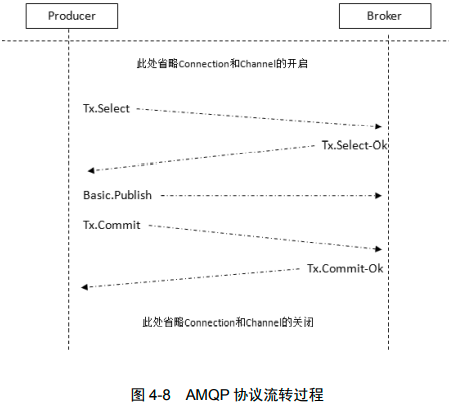
- 客户端发送 Tx.Select,将信道置为事务模式;
- Broker 回复 Tx.Select-Ok,确认已将信道置为事务模式;
- 在发送完消息之后,客户端发送 Tx.Commit 提交事务;
- Broker 回复 Tx.Commit-Ok,确认事务提交。
事务回滚
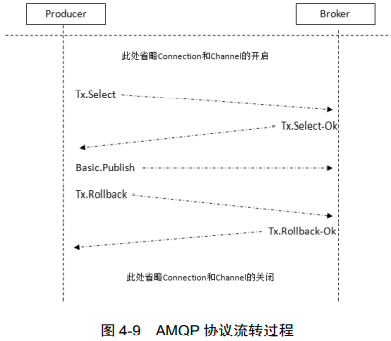
事务会大大降低性能
发送方确认机制
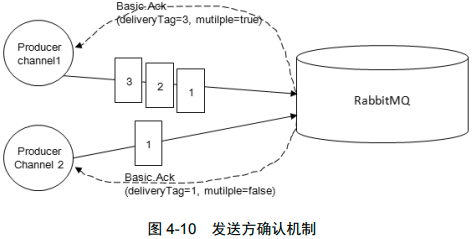
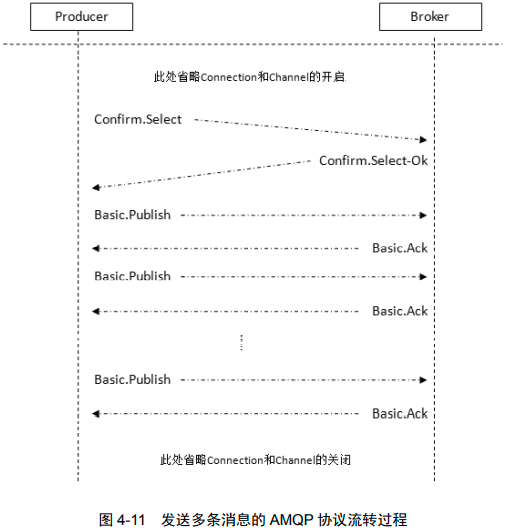
生产者将信道设置成 confirm(确认)模式,一旦信道进入 confirm 模式,所有在该信道上面发布的消息都会被指派一个唯一的 ID(从 1 开始),一旦消息被投递到所有匹配的队列之后,RabbitMQ 就会发送一个确认(Basic.Ack)给生产者(包含消息的唯一 ID),这就使得生产者知晓消息已经正确到达了目的地了。如果消息和队列是可持久化的,那么确认消息会在消息写入磁盘之后发出。RabbitMQ 回传给生产者的确认消息中的 deliveryTag 包含了确认消息的序号,此外 RabbitMQ 也可以设置 channel.basicAck 方法中的 multiple 参数,表示到这个序号之前的所有消息都已经得到了处理,可以参考图 4-10。注意辨别这里的确认和消费时候的确认之间的异同。
// 创建一个接收确认消息的chan
confirms := ch.NotifyPublish(make(chan amqp.Confirmation, 1)) // 处理确认逻辑
go func (confirms <-chan amqp.Confirmation) {
if confirmed := <-confirms; confirmed.Ack {
fmt.Printf("confirmed delivery with delivery tag: %d", confirmed.DeliveryTag)
} else {
fmt.Printf("confirmed delivery of delivery tag: %d", confirmed.DeliveryTag)
}
}(confirms)其他用于确认的函数: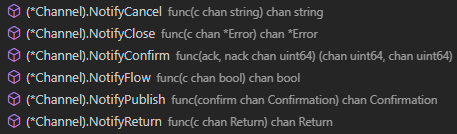
注意:
- 事务和发送确认是互斥的
- 这只能确保正确发送到Exchange
消费端
- 消息分发
- 消息顺序性
- 弃用QueueingConsumer
消息分发
默认使用轮询方法
// 限制信道上的消费者所能保持的最大未确认消息的数量
// 类比 TCP/IP 的滑动窗口
func (ch *Channel) Qos(
prefetchCount, // 所能接收的所有未确认消息的数量,为0表示没有上限
prefetchSize int, // 所能接收的所有未确认消息的总体大小上限,单位字节,为0没有上限
global bool // 为true信道Channel上所有消费者都遵从限制,否则只有新的消费者遵从
) error {消息顺序性
可能破坏顺序性的情况:
- 生产者使用事务,出现异常后回滚,使用另一线程补偿发送
- 使用延迟队列时错序
- 存在优先级
- ...
要保证消息顺序性,要业务方做进一步处理,如添加全局有序标识(Sequence ID)
消息传输保障
传输保障的3个层级:
- At most once:最多一次。消息可能会丢失,但绝不会重复传输。
无需考虑太多,但可能丢失数据 - At least once:最少一次。消息绝不会丢失,但可能会重复传输。
考虑一下几方面
- 生产者开启事务或publisher confirm
- 使用备份交换机,保证消息能到队列
- 持久化
- 手动ack
- Exactly once:恰好一次。每条消息肯定会被传输一次且仅传输一次。(不支持)
RabbitMQ管理
两个工具 rabbitmqctl 和 rabbitmq-plugins 。使用 rabbitmq -plugins list 查看所有插件,使用 rabbitmq -plugins enable rabbitmq _management 并重启打开web界面
应用管理
rabbitmq-server -detached # 启动Erlang虚拟机和应用
rabbitmqctl stop_app # 停止MQ,但不关闭Erlang虚拟机(在执行其他停止RabbitMQ的操作前使用,如 rabbitmqctl reset)
rabbitmqctl start_app # 启动应用,但前提是Erlang虚拟机已经启动
rabbitmqctl stop [pid_file] # 关闭MQ和Erlang,指定 pid_file 后阻塞至关闭结束
rabbitmqctl shutdown # 阻塞至关闭
rabbitmqctl wait [pid_file] # 等待mq的启动
rabbitmqctl reset # 重置到最初状态
rabbitmqctl force_reset # 可能损坏数据或配置
rabbitmqctl rotate_logs {suffix} # 轮换日志,用于日志分割。将已有日志更名为原文件名+后缀,以后的日志继续写入旧文件名集群管理
rabbitmqctl join_cluster {cluster_node} [--ram] # 加入集群,执行前要停止MQ并重置节点
rabbitmqctl cluster_status
rabbitmqctl change_cluster_node_type {disc|ram} # 修改节点类型
rabbitmqctl forget_cluster_node [--offline] # 从集群删除,允许离线执行
rabbitmqctl update_cluster_nodes {clusternode} # 用于再次加入同一集群时跟新状态
rabbitmqctl force_boot # 强制启动。一般,重启的第一个节点应该是最后关闭的节点,因为它可以看到其他节点所看不到的事情。
rabbitmqctl sync_queue [-p vhost] {queue} # 开启主从复制
rabbitmqctl cancel_sync_queue [-p vhost] {queue} # 关闭主从复制
rabbitmqctl set_cluster_name {name}服务端状态
rabbitmqctl list_queues [-p vhost] [queueinfoitem ...]
rabbitmqctl list_exchanges [-p vhost] [exchangeinfoitem ...]
rabbitmqctl list_bindings [-p vhost] [bindinginfoitem ...]
rabbitmqctl list_connections [connectioninfoitem ...]
rabbitmqctl list_channels [channelinfoitem ...]
rabbitmqctl list_consumers [-p vhost]
rabbitmqctl status
rabbitmqctl node_health_check
rabbitmqctl environment 显示每个运行程序环境中每个变量的名称和值
rabbitmqctl report 为所有服务器状态生成一个服务器状态报告
rabbitmqctl eval {expr} 执行任意 Erlang表达式配置
3种方式,优先级如下:
- 环境变量
- 配置文件
- 运行时参数和策略
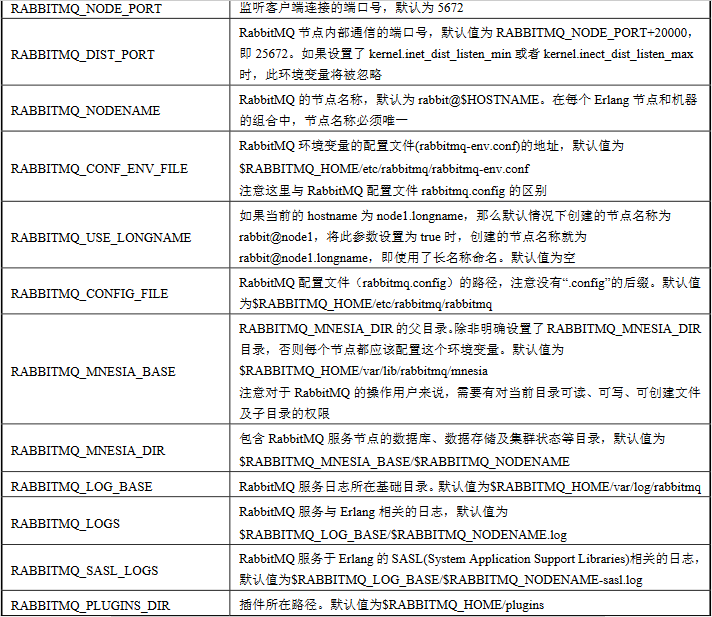
环境变量
都是以“RABBITMQ_”开头的,默认使用 rabbit@$HOSTNAME 作为名称
还可以在rabbitmq-env.conf文件种配置环境变量,只是没有了开头的 RABBITMQ_

配置文件
https://github.com/rabbitmq/rabbitmq-server/blob/stable/docs/rabbitmq.config.example
配置文件的位置取决于不同的操作系统和安装包。最有效的方法就是检查RabbitMQ 的服务日志,在启动 RabbitMQ 服务的时候会打印相关信息。如 -config /etc/rabbitmq/rabbitmq
# 一个配置文件示例,注意最后的 . 号
[
{
rabbit, [
{tcp_listeners, [5673]}
]
}
].
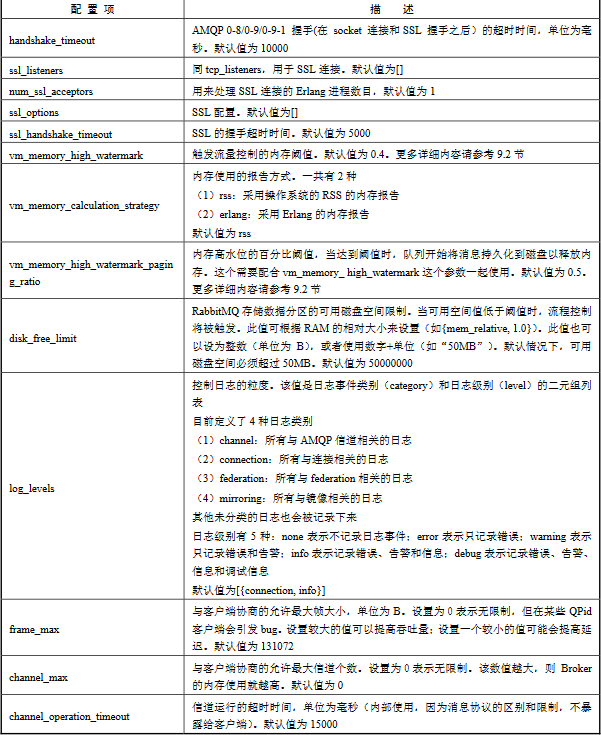
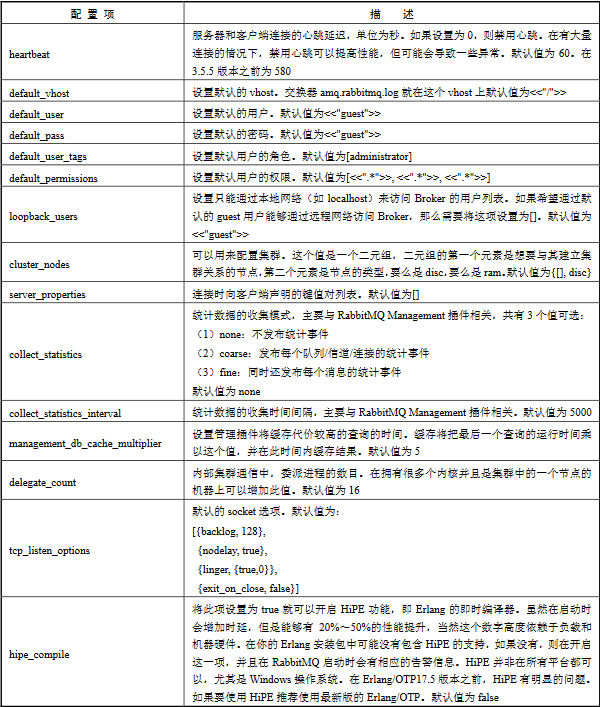
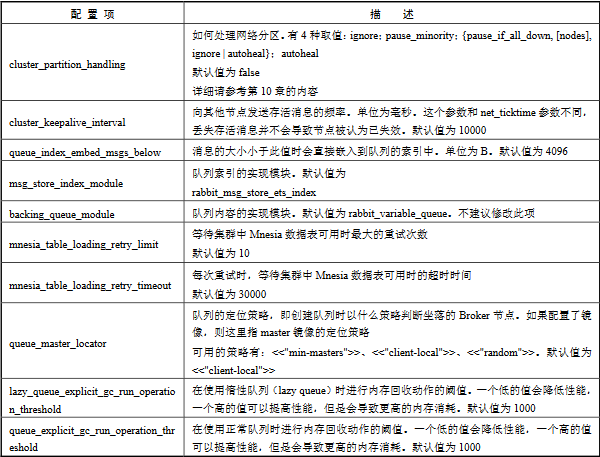
配置网络
配置网络
# 缓冲区越大,吞吐量也会越高,但是每个连接上耗费的内存也就越多
# 将 TCP 缓冲区大小设置为 192KB
[
{rabbit, [
{tcp_listen_options, [
{backlog, 128},
{nodelay, true}, # 禁用Nagles算法
{linger, {true,0}},
{exit_on_close, false},
{sndbuf, 196608},
{recbuf, 196608}
]}
]}
].
[
{kernel, [
{inet_default_connect_options, [{nodelay, true}]},
{inet_default_listen_options, [{nodelay, true}]}
]},
{rabbit, [
{tcp_listen_options, [
{backlog, 4096},
{nodelay, true},
{linger, {true,0}},
{exit_on_close, false}
]}
]}
].RabbitMQ 运维
集群搭建
单台 RabbitMQ 服务器可以满足每秒 1000 条消息的吞吐量,当集群中一个 RabbitMQ 节点崩溃时,该节点上的所有队列中的消息也会丢失。RabbitMQ 集群中的所有节点都会备份所有的元数据信息,包括以下内容。
- 队列元数据:队列的名称及属性;
- 交换器:交换器的名称及属性;
- 绑定关系元数据:交换器与队列或者交换器与交换器之间的绑定关系;
- vhost 元数据:为 vhost 内的队列、交换器和绑定提供命名空间及安全属性。
不会备份消息,但可以通过镜像队列解决。集群中只在单个节点上而不是所有节点创建和包含完整的队列信息和消息。其他非所有者节点只知道队列的元数据和指向该队列存在的那个节点的指针。因此崩溃时会丢失消息。
不同于队列那样拥有自己的进程,交换器其实只是一个名称和绑定列表。当消息发布到交换器时,实际上是由所连接的信道将消息上的路由键同交换器的绑定列表进行比较,然后再路由消息。当创建一个新的交换器时,RabbitMQ 所要做的就是将绑定列表添加到集群中的所有节点上。这样,每个节点上的每条信道都可以访问到新的交换器了。
多机多节点配置
应只在局域网使用,广域网种使用 Federation 或者 Shovel 来代替。
- 修改hosts文件,添加主机名
- 编辑 RabbitMQ 的 cookie 文件,以确保各个节点的 cookie 文件使用的是同一个值
可以读取 node1 节点的 cookie 值,然后将其复制到 node2 和 node3 节点中。
/var/lib/rabbitmq/.erlang.cookie 或者$HOME/.erlang.cookie - 配 置 集 群
三台机器:node1 node2 node3
- 分别启动机器
rabbitmq-server –detached - 以node1为基准,将node2和node3加入集群|
rabbitmqctl stop_app rabbitmqctl reset rabbitmqctl join_cluster rabbit@node1 rabbitmqctl start_app
- 分别启动机器
如果关闭了集群中的所有节点,则需要确保在启动的时候最后关闭的那个节点是第一个启动的。如果第一个启动的不是最后关闭的节点,那么这个节点会等待最后关闭的节点启动。这个等待时间是 30 秒,如果没有等到,那么这个先启动的节点也会失败。在最新的版本中会有重试机制,默认重试 10 次 30 秒以等待最后关闭的节点启动。
若因异常无法正常启动用 rabbitmqctl forget_cluster_node将其剔除集群。
使用 rabbitmqctl force_boot 强制启动
集群节点类型
内存节点将所有的队列、交换器、绑定关系、用户、权限和 vhost的元数据定义都存储在内存中,而磁盘节点则将这些信息存储到磁盘中。
单节点的集群中必然只有磁盘类型的节点,否则当重启 RabbitMQ 之后,所有关于系统的配置信息都会丢失。
不过在集群中,可以选择配置部分节点为内存节点,这样可以获得更高的性能。
rabbitmqctl join_cluster rabbit@node1 --ram # 当前节点作为内存节点加入
# 没有参数默认磁盘节点
rabbitmqctl change_cluster_node_type {disc,ram} # 切换节点类型,执行命令前后要执行 stop_app start_app内存节点速度快,磁盘节点更持久。集群要求至少一个磁盘节点,当磁盘节点崩溃后集群仍能运行但是无法修改队列、权限、用户等状态。应当保证集群至少有两个磁盘节点。节点加入或者离开集群时,它们必须将变更通知到至少一个磁盘节点。
剔除单个节点
rabbitmqctl forget_cluster_node rabbit@node2 # 在node1或node3上执行将其剔除
rabbitmqctl forget_cluster_node rabbit@node2 –offline # 上条命令要求rabbitmq服务在线,这条不需要
rabbitmqctl reset # 重置当前服务,建议这种方式集群节点的升级
如果由单节点组成,只要关闭原服务,再解压新版本即可。
集群由多个节点组成,具体步骤:
- 关闭所有节点的服务,注意采用 rabbitmqctl stop 命令关闭。
- 保存各个节点的 Mnesia 数据。
- 解压新版本的 RabbitMQ 到指定的目录。
- 指定新版本的 Mnesia 路径为步骤 2 中保存的 Mnesia 数据路径。
- 启动新版本的服务,注意先重启原版本中最后关闭的那个节点
日志
位于$RABBITMQ_HOME/var/log/rabbitmq下RABBITMQ_NODENAME-sasl.log 和RABBITMQ_NODENAME.log
可用 tail -f $RABBITMQ_HOME/var/log/rabbitmq/rabbit@$HOSTNAME.log -n 200 实时查看
rabbitmqctl rotate_logs {suffix} 轮换日志,可使用crontab
默认交换机 amq.rabbitmq.trace 就是用于收集日志的,其为topic类型,可订阅 queue.debug、queue.info、queue.warning、queue.error四个级别用于订阅不同主题,使用#可订阅所有日志。
单节点故障恢复
移除故障节点:rabbitmqctl forget_cluster_node {nodename}
节点重启后不要直接加入集群,否则会引起网络分区。要执行 rabbitmqctl forget_cluster_node {nodename} 将其剔除后再作为新节点加入。
集群迁移
扩容较为简单,直接加入新节点即可,但是新节点中没有队列创建。只有后面新建队列才会进入这个新节点。
迁移用于解决扩容和集群故障的问题。
元数据重建
在新集群中创建与旧集群相同的交换机、队列、用户等元数据。可从web管理界面下载和导入。
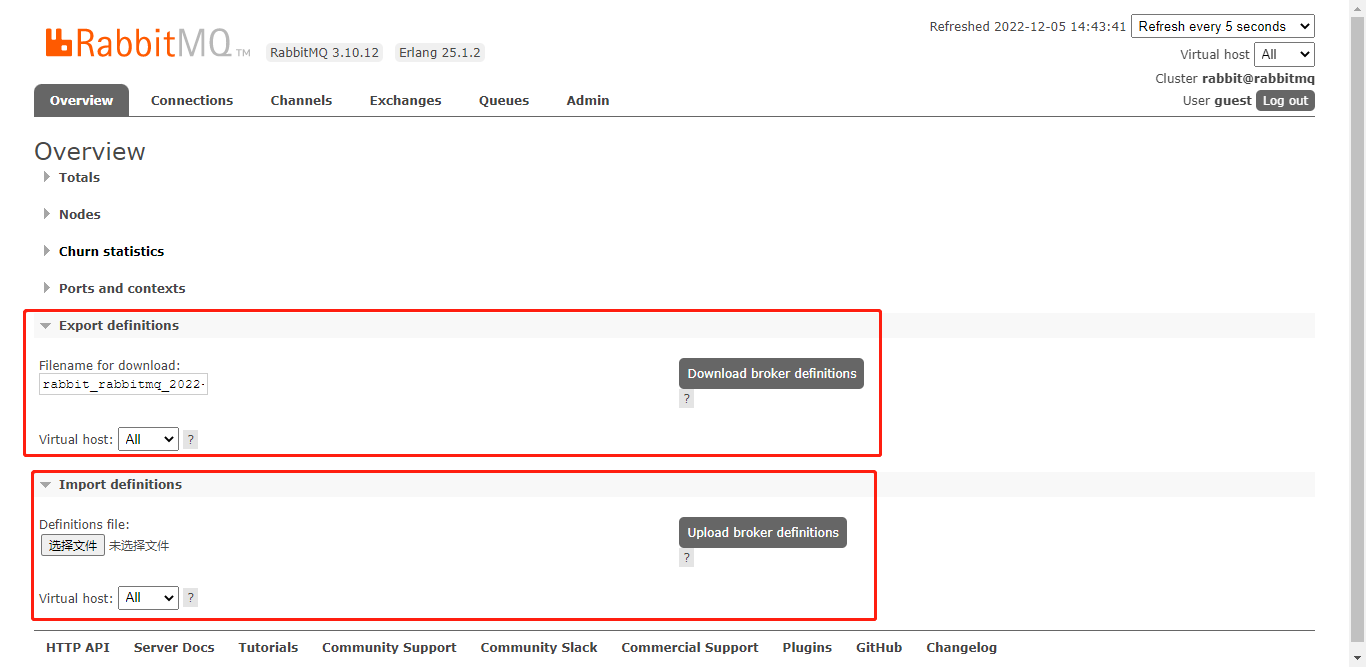
新集群有数据与 metadata.json 中的数据相冲突,对于交换器、队列及绑定关系这类非可变对象而言会报错,而对于其他可变对象如 Parameter、用户等则会被覆盖,没有发生冲突的则不受影响。如果过程中发生错误,则导入过程终止,导致 metadata.json 中只有部分数据加载成功。
有3个问题:
- 机器故障,无法获得json文件
可以采取一个通用的备份任务,在元数据有变更或者达到某个存储周期时将最新的 metadata.json 备份至另一处安全的地方。 - 新旧集群的 RabbitMQ 版本不一致
一般高版本价值低版本的没有问题
直接修改json文件内容 - 所有的队列都只会落到同一个集群节点上,而其他节点处于空置状态
通过程序(或者脚本)的方式在新集群上建立元数据,而非简单地在页面上上传元数据文件而已
数据迁移与客户端连接的切换
先将生产者客户端断开连接,然后接入新集群。
消费者客户端可直接切换也可等旧集群中消息消费完后再切换。
数据迁移原理是将原集群中消息取出再发布到新集群,RabbitMQ本身提供的 Federation 和 Shovel 插件都可以实现。也可以自己编写。
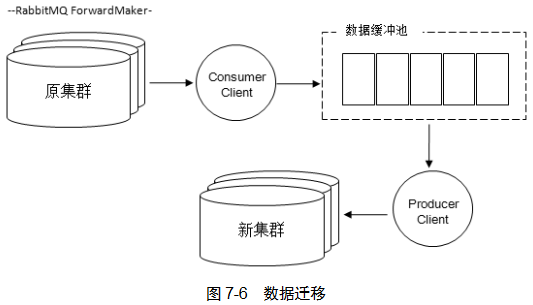
自动化迁移
在使用相关资源时就做好一些准备工作,方便在自动化迁移过程中进行无缝切换。与生产者和消费者客户端相关的是交换器、队列及集群的信息,一旦改变就要让客户端感知到,然后加载到ZooKeeper或etcd。如图,集群分为三部分:客户端、集群、ZooKeeper配置管理
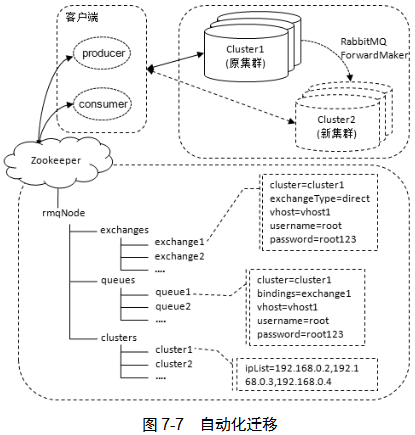
创建元数据资源时都要在Zookeeper中创建相应资源。客户端在交互时在相应的ZooKeeper节点中添加watcher,以便数据变化时相应变更。
元数据管理
元数据(如Exchange、Queue、用户)的操作应当通过元数据审核系统申请操作,申请后由专门的人审批,之后在数据库和RabbitMQ中创建相应的元数据,由专门的人审批。通过后分别保存。数据库和 RabbitMQ 集群之间会有一个元数据一致性校验程序来检测元数据不一致的地方,不同之处推上监控管理系统。然后人工修改。
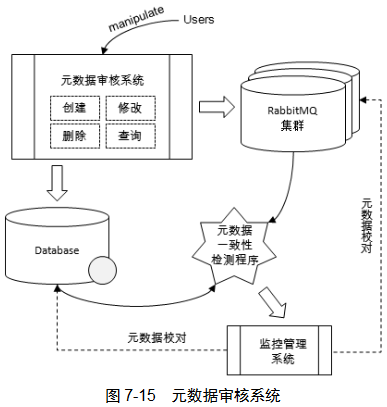
主要有queues、exchange、bindings三张表。
跨越集群界限
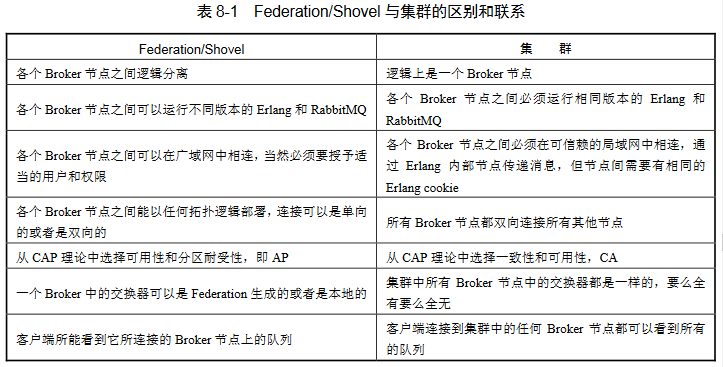
RabbitMQ有 3 种方式实现分布式部署:集群、Federation 和 Shovel。可以搭配使用
Federation
主要用于不同城市间的MQ集群通信,在不同的 Broker 节点之间进行消息传递而无须建立集群
- Federation插件能在不同域(用户、vhost、应用、Erlang)中传递消息
- 能容忍不稳定的网络连接情况
- 一个Broker节点可同时创建联邦交换器(或队列)或者本地交换器(或队列),只需要对特定的交换器(或队列)创建 Federation 连接(Federation link)
- 不需要在N个节点中创建N2个连接,意味着更容易拓展
Federation 插件可以让多个交换器或者多个队列进行联邦,联邦交换器和联邦队列可接收上游消息。
联邦交换器能够将原本发送给上游交换器的消息路由到本地的某个队列中;
联邦队列则允许一个本地消费者接收到来自上游队列(upstream queue)的消息
联邦交换器
broker1 的消息要传递给 broker3 的 exchangeA 消费,broker3 使用 Federation 插件在broker1 中创建一个新的 exchange(默认同名)、一个联邦交换机exchangeA->broker3 B、一个队列。其中broker1中exchangeA和联邦交换机绑定的key和broker3中exchangeA和Queue绑定的key一致。
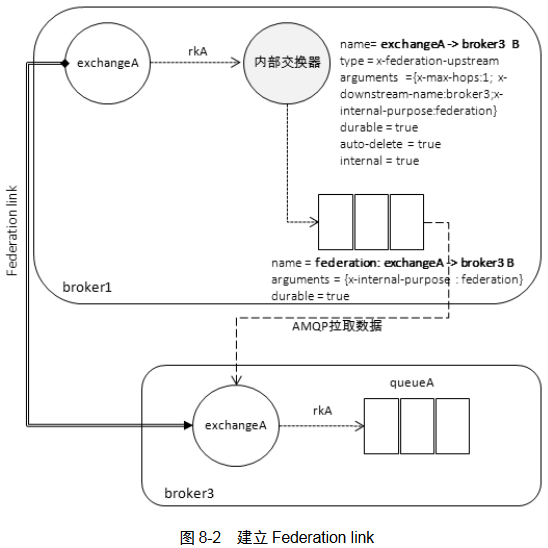
向broker1的exchangeA发送消息,转发到联邦交换机再通过联邦队列发送到broker3,可以从broker3中的队列接收到消息。
联邦交换机可以作为其他联邦交换机的上游
联邦队列
联邦队列可以在多个Broker 节点(或者集群)之间为单个队列提供均衡负载的功能。一个联邦队列可以连接一个或者多个上游队列
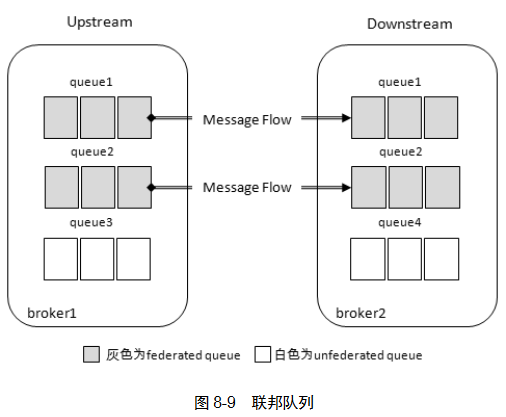
当消费者消费broker2中queue1或queue2中消息时,会先消费本地消息,没有了就到broker1中拉取。
有消费者消费broker1中queue1,又有消费者消费brker2中queue1,则实现了类似负载均衡的效果。
使用
要配置两个功能:
- 需要配置一个或多个 upstream,每个 upstream 均定义了到其他节点的 Federation link。
- 定义匹配交换器或者队列的一种/多种策略(Policy)
方法:
rabbitmq-plugins enable rabbitmq_federation开启插件,其基于AMQP拉取协议,也会开启 amqp_client 插件rabbitmq-plugins enable rabbitmq_federation_management开启管理插件
当需要在集群中使用 Federation 功能的时候,集群中所有的节点都应该开启 Federation 插件- 为下游MQ指定upstream
三种方法
-
rabbitmqctl set_parameter federation-upstream f1 \ '{"uri":"amqp://root:root123@<upstream-ip>:5672","ack-mode":"on-confirm"}' - 使用HTTP API
curl -i -u root:root123 -XPUT -d \ '{"value":{"uri":"amqp://root:root123@192.168.0.2:5672","ack-mode":"on-confirm"}}' \ http://192.168.0.4:15672/api/parameters/federation-upstream/%2f/f1 - 安装联邦管理工具后再web界面添加
-
- 定义一个 Policy 用于匹配交换器 exchangeA,并使用第二步中所创建的 upstream
-
rabbitmqctl set_policy --apply-to exchanges p1 "^exchange" '{"federation-upstream":"f1"}' - HTTP API
curl -i -u root:root123 -XPUT -d \ '{"pattern":"^exchange","definition":{"federation-upstream":"f1"},"apply-to":"exchanges"}' \ http://192.168.0.4:15672/api/policies/%2F/p1 - 再web界面的 "Admin"->"Policies"->"Add/update a policy" 中创建
-
Shovel
可靠、持续地从一个Broker中地队列拉取数据并转发至另一个Broker的交换机。源和目的地可以是一个Broker。
优势:1. 松耦合。Broker可包含不同的用户和vhost,不同的MQ和Erlang版本 2.支持广域网 3.高度定制,可配置AMQP命令
Shovel 的原理
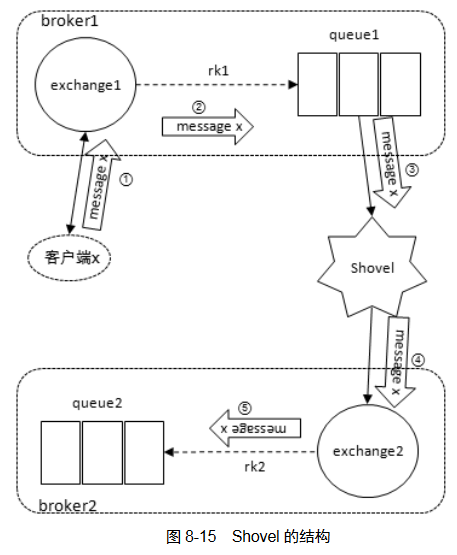

看起来像是直接从queue1发送到queue2,实际上中间经过了默认交换机。queue2中消息会被添上一些头信息。
使用
rabbitmq-plugins enable rabbitmq_shovel & rabbitmq-plugins enable rabbitmq_shovel_management 开启插件,web界面中会多出Shovel相关的选项。
两种配置方式:静态(在 rabbitmq.config)动态(通过Runtime Parameter)
# 静态配置格式,source destination queue 必须
{shovel_name, [ {sources, [ ... ]}
, {destinations, [ ... ]}
, {queue, queue_name}
, {prefetch_count, count}
, {ack_mode, a_mode}
, {publish_properties, [ ... ]}
, {publish_fields, [ ... ]}
, {reconnect_delay, reconn_delay}
]}示例
[{rabbitmq_shovel,
[{shovels,
[{hidden_shovel,
[{sources,
[{broker, "amqp://root:root123@192.168.0.2:5672"},
{declarations,
[
{'queue.declare',[{queue, <<"queue1">>}, durable]},
{'exchange.declare',[
{exchange, <<"exchange1">>},
{type, <<"direct">>},
durable
]
},
{'queue.bind',[
{exchange, <<"exchange1">>},
{queue, <<"queue1">>},
{routing_key, <<"rk1">>}
]
}]}]},
{destinations,
[{broker, "amqp://root:root123@192.168.0.3:5672"},
{declarations,
[
{'queue.declare',[{queue, <<"queue2">>}, durable]},
{'exchange.declare',[
{exchange, <<"exchange2">>},
{type, <<"direct">>},
durable
]
},
{'queue.bind',[
{exchange, <<"exchange2">>},
{queue, <<"queue2">>},
{routing_key, <<"rk2">>}
]
}]}]},
{queue, <<"queue1">>},
{ack_mode, no_ack},
{prefetch_count, 64},
{publish_properties, [{delivery_mode, 2}]},
{add_forward_headers, true},
{publish_fields, [{exchange, <<"exchange2">>},
{routing_key,<<"rk2">>}]},
{reconnect_delay, 5}]
}]
}]
}]动态配置:
- 命令行
rabbitmqctl set_parameter shovel hidden_shovel \ '{"src-uri":"amqp://root:root123@192.168.0.2:5672", "src-queue":"queue1", "dest-uri":"amqp://root:root123@192.168.0.3:5672","src-exchange-key":"rk2", "prefetch-count":64, "reconnect-delay":5, "publish-properties":[], "add-forward-headers":true, "ack-mode":"on-confirm"}' - HTTP API
curl -i -u root:root123 -XPUT -d '{"value":{"src-uri":"amqp://root:root123@192.168.0.2:5672","src-queue":"que ue1", "dest-uri":"amqp://root:root123@192.168.0.3:5672","src-exchange-key":"rk2", "prefetch-count":64, "reconnect-delay":5, "publish-properties":[], "add-forward-headers":true, "ack-mode":"on-confirm"}}' http://192.168.0.2:15672/api/parameters/shovel/%2f/hidden_shovel - web界面
消息堆积
适量的消息堆积有削峰、缓存的作用,但堆积过重会影响服务。可以丢弃数据,也可以使用Shovel将消息转移给其他集群。
当集群1中堆积严重时,将消息转发给其他集群,当堆积缓解后停止转移,合适条件下再转移回原集群
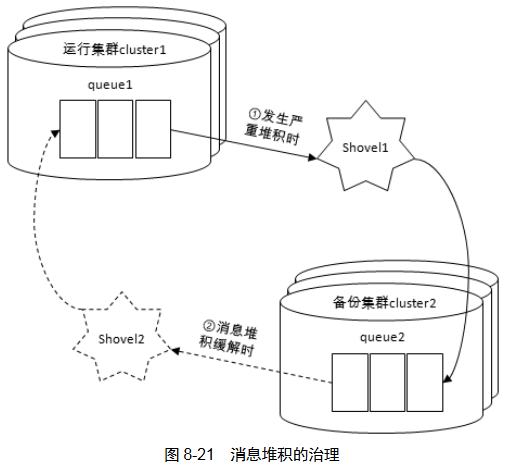
上图为“一对一”,还可以有“一对多”
RabbitMQ高阶
一个队列的内部存储其实是由 5 个子队列来流转运作的,队列中的消息可以有 4 种不同的状态
在使用 RabbitMQ 时尽量不要有过多的消息堆积,不然会影响整体服务的性能
存储机制
持久化消息到达时写入磁盘,内存充裕时写入内存,内存吃紧时从内存清除。非持久化消息只写入内存,内存不足时换入磁盘。
镜像队列
单点故障时交换机和绑定关系能幸免于难,但队列和消息不可以。镜像队列将队列复制到其他节点,一个节点失效,自动切换到其他节点。每组镜像队列都包含一个master和多个slave。
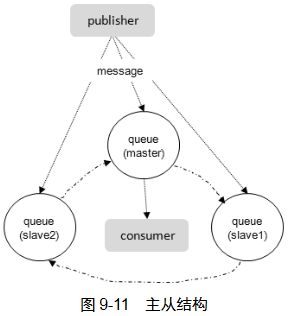
slave与master上状态相同。master失效时时间最长的slave会成为新的master。发到镜像队列的所有消息都同时发到master和所有slave。除发送消息(Basic.Public)外所有动作都发到master再由master将结果广播给slave。
消费者与slave的连接,本质是slave从master获得消息再发给消费者。并非像mysql一样的负载均衡。RabbitMQ中的master和slave是针对队列而言的,其可以均匀的分布在集群的各个节点中以达到物理机器负载均衡的目的。
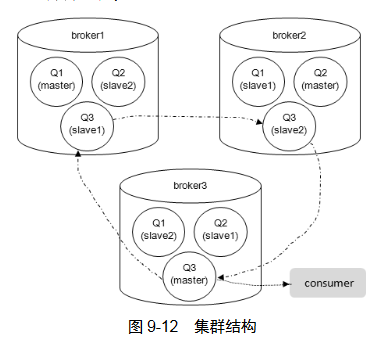
镜像队列支持发布确认和事务两种机制,只有所有节点都完成了事务或确认,生产者的当前消息才算被接收了。
网络分区
RabbitMQ的数据一致性原理:将镜像组成环形,在master上执行确认命令,之后转向B然后C、D节点,最后由D执行后返回给A,这样才确认了一条消息。这样可以保证更强的一致性。如果C阻塞,那么整个A->B->C->D->A 就会阻塞,所以要将异常节点剥离出来,确保MQ服务的可靠。
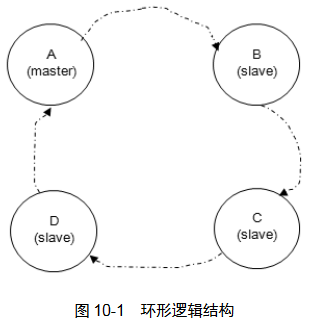
网络分区大多是由单个节点的网络故障引起的,且通常会形成一个大分区和一个单节点的分区,如果之前又配置了镜像,那么可以在不影响服务可用性,不丢失消息的情况下从网络分区的情形下得以恢复。
由 net_ticktime 决定节点间超时时间。使用 rabbitmqctl cluster_status 查看,或WEB界面,或使用HTTP API curl -i -u root:root123 -H "content-type:application/json" -X GET http://ip:15672/api/nodes
手动处理分区
- 挑选信任分区
分区中disc节点、节点数、队列数、客户端数越多越好,越靠前越重要。 - 重启非信任节点
推荐使用rabbitmqctl start_app命令 - 如果还有警告,重启信任分区中节点
注意重启节点时镜像队列的“漂移”现象:master集中到某一个节点上。可以重启之前先删除镜像队列的配置,这样能够在一定程度上阻止队列的“过分漂移”。
1:挂起生产者和消费者进程。这样可以减少消息不必要的丢失,如果进程数过多,情形又比较紧急,也可跳过此步骤。
2:删除镜像队列的配置。
3:挑选信任分区。
4:关闭非信任分区中的节点。采用 rabbitmqctl stop_app 命令关闭。
5:启动非信任分区中的节点。采用与步骤 4 对应的 rabbitmqctl start_app命令启动。
6:检查网络分区是否恢复,如果已经恢复则转步骤 8;如果还有网络分区的报警则转步骤 7。
7:重启信任分区中的节点。
8:添加镜像队列的配置。
9:恢复生产者和消费者的进程。自动处理分区
默认不开启,有3种方式:pause-minority 模式、pause-if-all-down 模式 和 autoheal 模式
# 可在 rabbitmq.config 中配置
[
{
rabbit, [
{cluster_partition_handling, ignore}
]
}
].pause-minority 模式
集群观察到有节点“down”时自动检测自己是否是“少数派”,会使用 rabbitmqctl stop_app 自动关闭这些节点。大多数节点得以继续运行。关闭节点每秒检测一次是否可连接到剩余集群中,可以则启动自身 rabbitmqctl start_app。
[
{
rabbit, [
{cluster_partition_handling, pause_minority}
]
}
].当出现2v2、3v3 这种对等分区时可能会关闭所有机器。
pause-if-all-down 模式
集群中的节点在和所配置的列表中的任何节点不能交互时才会关闭 {pause_if_all_down, [nodes], ignore|autoheal}。如下方配置,任何节点无法与 rabbot@node1 通信时会关闭自己的应用,如果是它发生故障,所有节点都关闭。直到网络恢复再重启。
注意这种模式有 ignore 和 autoheal 两种配置。ignore不会关闭节点,要配置为autoheal。
[
{
rabbit, [
{cluster_partition_handling,
{pause_if_all_down, ['rabbit@node1'], autoheal}}
]
}
].autoheal 模式
分区时自动决定一个获胜分区,重启不在分区中的节点。判断获胜的依据依次是:客户端连接数,节点数,节点名称字典序。
[
{
rabbit, [
{cluster_partition_handling, autoheal}
]
}
].各种分区处理自动模式比较
配置与不可靠网络要使用 Federation 或 Shovel。即使网络恢复了,也要防止二次分区
- ignore:发生分区时不做任何动作,要人工介入
- pause-minority:对等分区处理不够优雅,可能关闭所有节点。可用于非跨机架、奇数节点的集群
- pause-if-all-down:对受信节点的选择极为考究
- autoheal:可处理各情形下网络分区。有节点处于非运行状态时此模式失效
RabbitMQ扩展
消息追踪
Firehose
将生产者投递给 RabbitMQ 的消息,或者 RabbitMQ 投递给消费者的消息按照指定的格式发送到默认的交换器上。这个默认的交换器的名称为 amq.rabbitmq.trace,它是一个 topic 类型的交换器。发送到这个交换器上的消息的路由键为 publish.exchangename} 和 deliver.{queuename}。rabbitmqctl trace_on [-p vhost] 开启插件。
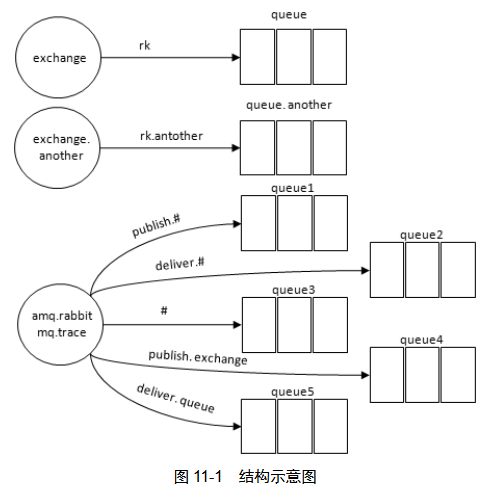
发消息给exchange,队列 1、3、4 接收到被封装的消息
发消息给exchange.another,队列 1、3 接收到被封装的消息
消费queue,队列 2、3、5 接收到被封装的消息
消费queue.another,,队列 2、3 接收到被封装的消息
rabbitmq_tracing
命令 rabbitmq-plugins enable rabbitmq_tracing 开启Firehose的GUI版本。
负载均衡
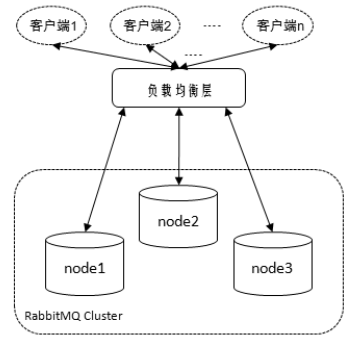
客户端内部实现
客户端在代码中实现,使用一个专门的获取连接函数
- 轮询
- 加权轮询
- 随机
- 加权随机
- 源地址哈希
- 最小连接数法
HAProxy
HAProxy 实现了一种事件驱动、单一进程模型,此模型支持非常大的并发连接数。
环境:
HAProxy 主机:192.168.0.9 5671
RabbitMQ 1:192.168.02 5672
RabbitMQ 2:192.168.03 5672
RabbitMQ 3:192.168.04 5672
#全局配置
global
#日志输出配置,所有日志都记录在本机,通过 local0 输出
log 127.0.0.1 local0 info
#最大连接数
maxconn 4096
#改变当前的工作目录
chroot /opt/haproxy-1.7.8
#以指定的 UID 运行 haproxy 进程
uid 99
#以指定的 GID 运行 haproxy 进程
gid 99
#以守护进程方式运行 haproxy #debug #quiet
daemon
#debug
#当前进程 pid 文件
pidfile /opt/haproxy-1.7.8/haproxy.pid
#默认配置
defaults
#应用全局的日志配置
log global
#默认的模式 mode{tcp|http|health}
#TCP 是 4 层,HTTP 是 7 层,health 只返回 OK
mode tcp
#日志类别 tcplog
option tcplog
#不记录健康检查日志信息
option dontlognull
#3 次失败则认为服务不可用
retries 3
#每个进程可用的最大连接数
maxconn 2000
#连接超时
timeout connect 5s
#客户端超时
timeout client 120s
#服务端超时
timeout server 120s
#绑定配置
listen rabbitmq_cluster :5671
#配置 TCP 模式
mode tcp
#简单的轮询
balance roundrobin
#RabbitMQ 集群节点配置
# 起名 指定地址 5000毫秒检测可用 故障后检查2次才被确认可用 3次检查失败后停止使用 服务权重
server rmq_node1 192.168.0.2:5672 check inter 5000 rise 2 fall 3 weight 1
server rmq_node2 192.168.0.3:5672 check inter 5000 rise 2 fall 3 weight 1
server rmq_node3 192.168.0.4:5672 check inter 5000 rise 2 fall 3 weight 1
#haproxy 监控页面地址
listen monitor :8100
mode http
option httplog
stats enable
stats uri /stats
stats refresh 5sKeepalived
HAProxy 故障后,所有MQ都无法连接。 Keepalived 能够通过自身健康检查、资源接管功能做高可用(双机热备),实现故障转移。
Keepalived 采用 VRRP(Virtual Router Redundancy Protocol,虚拟路由冗余协议),以软件的形式实现服务的热备功能。通常情况下是将两台 Linux 服务器组成一个热备组(Master 和Backup),同一时间内热备组只有一台主服务器 Master 提供服务,同时 Master 会虚拟出一个公用的虚拟 IP 地址,简称 VIP。这个 VIP 只存在于 Master 上并对外提供服务。如果 Keepalived检测到 Master 宕机或者服务故障,备份服务器 Backup 会自动接管 VIP 并成为 Master,Keepalived将原 Master 从热备组中移除。当原 Master 恢复后,会自动加入到热备组,默认再抢占成为 Master,起到故障转移的功能。
Keepalived 工作在 OSI 模型中的第 3 层、第 4 层和第 7 层。
第3层,定期用ICMP包判断热备组中机器是否异常,异常则移除
第4层,通过TCP端口判断应用是否正常,移除则移除
第7层,通过用户自定义脚本判断服务是否正常,异常则移除
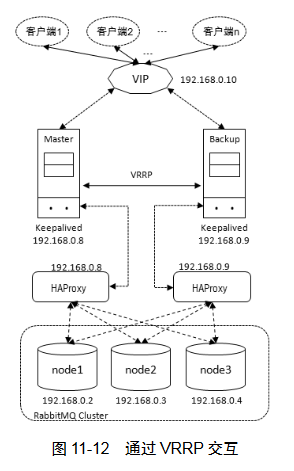
两台Keepalived通过VRRP交互,对外虚拟出一个VIP。Keepalived 与 HAProxy 部署在同一台机器上,通过 Keeaplived 实现 HAProxy 的双机热备。
client通过VIP建立通信链路,通过Keepalived的Master节点路由到HAProxy上,通过负载均衡算法分发到各个MQ节点。正常流量通过左侧,当Master挂掉时Backup提升为Master。
# Keepalived 的 Mater 配置
global_defs {
router_id NodeA #路由 ID、主/备的 ID 不能相同
}
#自定义监控脚本
vrrp_script chk_haproxy {
script "/etc/keepalived/check_haproxy.sh"
interval 5
weight 2
}
vrrp_instance VI_1 {
state MASTER #Keepalived 的角色。Master 表示主服务器,从服务器设置为 BACKUP
interface eth0 #指定监测网卡
virtual_router_id 1
priority 100 #优先级,BACKUP 机器上的优先级要小于这个值
advert_int 1 #设置主备之间的检查时间,单位为 s
authentication { #定义验证类型和密码
auth_type PASS
auth_pass root123
}
track_script {
chk_haproxy
}
virtual_ipaddress { #VIP 地址,可以设置多个:
192.168.0.10
}
}
# Backup 配置,大多数一致
global_defs {
router_id NodeB
}
vrrp_script chk_haproxy {
...
}
vrrp_instance VI_1 {
state BACKUP
...
priority 50 # 小于 100
...
}检查HAProxy服务状态的脚本
#!/bin/bash
if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ];then
haproxy -f /opt/haproxy-1.7.8/haproxy.cfg
fi
sleep 2
if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ];then
service keepalived stop
fiKeepalived + LVS
LVS 是 Linux Virtual Server 的简称,也就是 Linux 虚拟服务器。LVS 支持 TCP/UDP 的负载均衡,由3部分组成:
- 负载调度器:整个集群对外的前端机,将来自客户的请求转发到一组服务器
- 服务器池:执行请求的一组服务器,如MQ集群
- 共享存储:为服务器池提供一个共享的存储区,这样很容易使服务器池拥有相同的内容,提供相同的服务
有3中负载均衡方式:
- VS/NAT:所有的 RealServer 只需要将自己的网关指向 Director 即可。但负载有限
- VS/TUN:将一个 IP报文封装在另一个 IP 报文的技术,这可以使目标为一个 IP 地址的数据报文能够被封装和转发到另一个 IP 地址。IP 隧道技术也可以称之为 IP 封装技术
- VS/DR:通过改写报文中的MAC地址部分来实现的。Director 和 RealServer 必须在物理上有一个网卡通过不间断的局域网相连。RealServer 上绑定的 VIP 配置在各自 Non-ARP 的网络设备上(如 lo 或tunl),Director 的 VIP 地址对外可见,而 RealServer 的 VIP 对外是不可见的。RealServer的地址既可以是内部地址,也可以是真实地址
LVS 可以完全替代 HAProxy 而其他内容可以保持不变。LVS 不需要额外的配置文件,直接
集成在 Keepalived 的配置文件之中。
#Keepalived 配置文件(Master)
global_defs {
router_id NodeA #路由 ID、主/备的 ID 不能相同
}
vrrp_instance VI_1 {
state MASTER #Keepalived 的角色。Master 表示主服务器,从服务器设置为 BACKUP
interface eth0 #指定监测网卡
virtual_router_id 1
priority 100 #优先级,BACKUP 机器上的优先级要小于这个值
advert_int 1 #设置主备之间的检查时间,单位为 s
authentication { #定义验证类型和密码
auth_type PASS
auth_pass root123
}
track_script {
chk_haproxy
}
virtual_ipaddress { #VIP 地址,可以设置多个:
192.168.0.10
}
}
virtual_server 192.168.0.10 5672 { #设置虚拟服务器
delay_loop 6 #设置运行情况检查时间,单位是秒
#设置负载调度算法,共有 rr、wrr、lc、wlc、lblc、lblcr、dh、sh 这 8 种
lb_algo wrr #这里是加权轮询
lb_kind DR #设置 LVS 实现的负载均衡机制方式 VS/DR
#指定在一定的时间内来自同一 IP 的连接将会被转发到同一 RealServer 中
persistence_timeout 50
protocal TCP #指定转发协议类型,有 TCP 和 UDP 两种
#这个 real_server 即 LVS 的三大部分之一的 RealServer,这里特指 RabbitMQ 的服务
real_server 192.168.0.2 5672 { #配置服务节点
weight 1 #配置权重
TCP_CHECK {
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
connect_port 5672
}
}
real_server 192.168.0.3 5672 {
weight 1
TCP_CHECK {
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
connect_port 5672
}
}
real_server 192.168.0.4 5672 {
weight 1
TCP_CHECK {
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
connect_port 5672
}
}
}
#为 RabbitMQ 的 RabbitMQ Management 插件设置负载均衡
virtual_server 192.168.0.10 15672 {
delay_loop 6
lb_algo wrr
lb_kind DR
persistence_timeout 50
protocal TCP
real_server 192.168.0.2 15672 {
weight 1
TCP_CHECK {
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
connect_port 15672
}
}
real_server 192.168.0.3 15672 {
weight 1
TCP_CHECK {
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
connect_port 15672
}
}
real_server 192.168.0.4 15672 {
weight 1
TCP_CHECK {
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
connect_port 15672
}
}
}LVS主要的工作是提供调度算法,把客户端请求按照需求调度在 RealServer 中,Keepalived 主要的工作是提供 LVS 控制器的一个冗余,并且对 RealServer 进行健康检查,发现不健康的 RealServer就把它从 LVS 集群中剔除,RealServer 只负责提供服务。
在VS/SR模式下,LVS将client的包转发给RealServer时因为包的目的地址是VIP,会发现地址不匹配然后丢弃数据包。要将这个VIP绑到网卡下,发送应答包是RealServer会将包的源和目的地址调换回复给客户端。
为所有RealServer的 lo:0 网卡绑定VIP:
#!/bin/bash
VIP=192.168.0.10
/etc/rc.d/init.d/functions
case "$1" in
start)
/sbin/ifconfig lo:0 $VIP netmask 255.255.255.255 broadcast $VIP
/sbin/route add -host $VIP dev lo:0
echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/all/arp_announce
sysctl -p >/dev/null 2>&1
echo "RealServer Start Ok"
;;
stop)
/sbin/ifconfig lo:0 down
/sbin/route del -host $VIP dev lo:0
echo "0" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "0" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "0" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "0" >/proc/sys/net/ipv4/conf/all/arp_announce
;;
status)
islothere=`/sbin/ifconfig lo:0 | grep $VIP | wc -l`
isrothere=`netstat -rn | grep "lo:0"|grep $VIP | wc -l`
if [ $islothere -eq 0 ]
then
if [ $isrothere -eq 0 ]
then
echo "LVS of RealServer Stopped."
else
echo "LVS of RealServer Running."
fi
else
echo "LVS of RealServer Running."
fi
;;
*)
echo "Usage:$0{start|stop}"
exit 1
;;
esac

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了