

Redis实战4 - 基于搜索的应用程序
基于搜索的应用程序
通常使用set和zset的交集、并集、差集。
使用redis进行搜索
基本索引原理
比起一个单词接一个单词的扫描,如何才能更快地对文档搜索?使用反向索引,set和zset都很适合。
索引结构
# 正向索引
0 : “I love you”
1 :“I love you too”
2: “I dislike you”
# 反向索引
“I” :{0, 1, 2}
“love” :{0, 1}
“you” :{0, 1, 2}
“dislike” :{2}
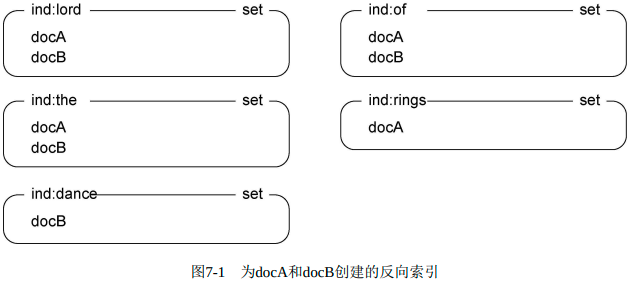
如果要检索“I dislike you ”这句话,那么就可以这么计算:{0,1,2} {2} {0, 1,2}docA标题:lord of the rings
docB标题:lord of the dance
先是对文章包含地单词进行处理,语法分析或标记话。此处认定单词只能由英文字母和单引号组成,且长于2。一个附加步骤是移除内容中非用词。
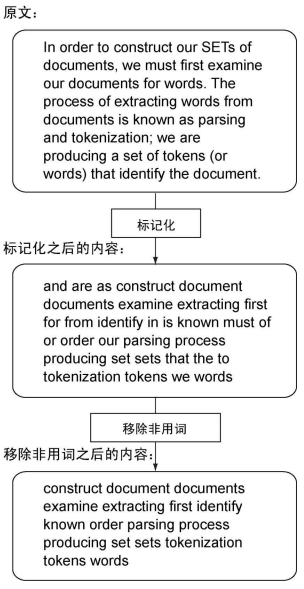
# 非用词
STOP_WORDS = set('''able about across after all almost also am among
an and any are as at be because been but by can cannot could dear did
do does either else ever every for from get got had has have he her
hers him his how however if in into is it its just least let like
likely may me might most must my neither no nor not of off often on
only or other our own rather said say says she should since so some
than that the their them then there these they this tis to too twas us
wants was we were what when where which while who whom why will with
would yet you your'''.split()) #A
WORDS_RE = re.compile("[a-z']{2,}") #B
def tokenize(content):
words = set() #C
for match in WORDS_RE.finditer(content.lower()): #D
word = match.group().strip("'") #E
if len(word) >= 2: #F
words.add(word) #F
return words - STOP_WORDS #G
def index_document(conn, docid, content):
words = tokenize(content) #H
pipeline = conn.pipeline(True)
for word in words:
# 添加反向索引,键为单词,集合元素为文章id
pipeline.sadd('idx:' + word, docid) #I
return len(pipeline.execute()) #J搜索操作
查一个词只要获得集合内文档id,查多个词时将多个文档id集合做交集SINTER SINTERSTORE。对于同义词可以使用并集操作将对应地全部文档取出SUNION SUNIONSTORE。使用SDIFF SDIFFSTORE可实现差集运算。
def _set_common(conn, method, names, ttl=30, execute=True):
id = str(uuid.uuid4()) #A
pipeline = conn.pipeline(True) if execute else conn #B
names = ['idx:' + name for name in names] #C
getattr(pipeline, method)('idx:' + id, *names) #D
# redis 自动删除集合
pipeline.expire('idx:' + id, ttl) #E
if execute:
pipeline.execute() #F
return id #G
def intersect(conn, items, ttl=30, _execute=True): #H
return _set_common(conn, 'sinterstore', items, ttl, _execute) #H
def union(conn, items, ttl=30, _execute=True): #I
return _set_common(conn, 'sunionstore', items, ttl, _execute) #I
def difference(conn, items, ttl=30, _execute=True): #J
return _set_common(conn, 'sdiffstore', items, ttl, _execute) #J分析并执行搜索
对搜索语句进行分析并搜索
QUERY_RE = re.compile("[+-]?[a-z']{2,}") #A
def parse(query):
# 存储不需要的单词
unwanted = set() #B
# 存储需要执行交集计算的单词
all = [] #C
# 存储已发现的同义词
current = set() #D
for match in QUERY_RE.finditer(query.lower()): #E
# 是否带加号或减号前缀
word = match.group() #F
prefix = word[:1] #F
if prefix in '+-': #F
word = word[1:] #F
else: #F
prefix = None #F
# 剔除单引号,略过非用词
word = word.strip("'") #G
if len(word) < 2 or word in STOP_WORDS: #G
continue #G
if prefix == '-': #H
unwanted.add(word) #H
continue #H
# 同义词非空且不带+,创建一个新同义词集合
if current and not prefix: #I
all.append(list(current)) #I
current = set() #I
current.add(word) #J
if current: #K
all.append(list(current)) #K
return all, list(unwanted) #L
def parse_and_search(conn, query, ttl=30):
all, unwanted = parse(query) #A
if not all: #B
return None #B
to_intersect = []
for syn in all: #D
if len(syn) > 1:
# 同义词不止一个则并集运算
to_intersect.append(union(conn, syn, ttl=ttl)) #E
else:
to_intersect.append(syn[0]) #F
if len(to_intersect) > 1:
# 单词不止一个则交集运算
intersect_result = intersect(conn, to_intersect, ttl=ttl) #G
else: #H
intersect_result = to_intersect[0] #H
if unwanted: #I
unwanted.insert(0, intersect_result) #I
return difference(conn, unwanted, ttl=ttl) #I
# 返回一个集合ID作为执行结果
return intersect_result对搜索结果排序
关联度计算问题:根据每个文档的重要性对其排序。使用散列表存储文章的信息:标题、创建的时间戳、最后一次更新时间戳、文档ID。

# 使用 start 和 num 实现分页
# 使用sort改变排序依据
# 用 ttl 改变 结果的缓存时间
# 通过 id 引用已有搜索结果
def search_and_sort(conn, query, id=None, ttl=300, sort="-updated", #A
start=0, num=20): #A
# 决定基于哪个属性排序,升序还是降序
desc = sort.startswith('-') #B
sort = sort.lstrip('-') #B
by = "kb:doc:*->" + sort #B
# 已数值方式还是字母方式
alpha = sort not in ('updated', 'id', 'created') #I
# 如果给定了已有搜索结果,且结果任然存在,延长生存时间
if id and not conn.expire(id, ttl): #C
id = None #C
# 如果没给定结果或结果已过期,则执行一次新的搜索操作
if not id: #D
id = parse_and_search(conn, query, ttl=ttl) #D
pipeline = conn.pipeline(True)
pipeline.scard('idx:' + id) #E
# 根据指定属性排序,只获取部分结果
pipeline.sort('idx:' + id, by=by, alpha=alpha, #F
desc=desc, start=start, num=num) #F
results = pipeline.execute()
return results[0], results[1], id # 返回搜索结果的 元素数量、搜索结果本身、搜索结果ID,结果ID可用于之后再次获取搜索结果有序索引
之前的排序只能基于字符串或数字,但不能处理排列顺序由几个不同分值组合的情况。
使用有序集合对搜索结果进行排序
使用两个有序集合来分别记录文章的更新时间以及文章获得的投票数量。这两个有序集合的成员都是知识库文章的ID,而成员的分值则分别为文章的更新时间以及文章获得的投票数量。
def search_and_zsort(conn, query, id=None, ttl=300, update=1, vote=0, #A
start=0, num=20, desc=True): #A
# 刷新已有结果的ttl
if id and not conn.expire(id, ttl): #B
id = None #B
# 标准的集合搜索操作
if not id: #C
id = parse_and_search(conn, query, ttl=ttl) #C
scored_search = {
id: 0, #I
'sort:update': update, #D
'sort:votes': vote #D
}
# 借用之前的辅助函数执行交集计算
id = zintersect(conn, scored_search, ttl) #E
pipeline = conn.pipeline(True)
pipeline.zcard('idx:' + id) # 获取结果有序集合的大小
# 从结果中获取一页
if desc: #G
pipeline.zrevrange('idx:' + id, start, start + num - 1) #G
else: #G
pipeline.zrange('idx:' + id, start, start + num - 1) #G
results = pipeline.execute()
return results[0], results[1], id #H
def _zset_common(conn, method, scores, ttl=30, **kw):
id = str(uuid.uuid4()) #A
# 通过参数决定是否使用事务流水线
execute = kw.pop('_execute', True) #J
pipeline = conn.pipeline(True) if execute else conn #B
for key in scores.keys(): #C
scores['idx:' + key] = scores.pop(key) #C
# 为操作设置参数
getattr(pipeline, method)('idx:' + id, scores, **kw) #D
# 为结果zset设置ttl
pipeline.expire('idx:' + id, ttl) #E
# 没有显式指定延迟执行则立即执行
if execute: #F
pipeline.execute() #F
return id #G
def zintersect(conn, items, ttl=30, **kw): #H
return _zset_common(conn, 'zinterstore', dict(items), ttl, **kw) #H
def zunion(conn, items, ttl=30, **kw): #I
return _zset_common(conn, 'zunionstore', dict(items), ttl, **kw) #I使用有序集合实现非数值排序
将字符进行排序,将其转换为数值格式,使用6个字节。超过的截断,不足的补全。
def string_to_score(string, ignore_case=False):
if ignore_case: #A
string = string.lower() #A
# 转换为6字节的数字
pieces = map(ord, string[:6]) #B
while len(pieces) < 6: #C
pieces.append(-1) #C
# 字符串转换,变为分值
score = 0
for piece in pieces: #D
score = score * 257 + piece + 1 #D
return score * 2 + (len(string) > 6) # 多使用一个二进制位记录字符从是否长于6广告定向
用户访问带有广告的web页面时,web服务器和浏览器向远程发送请求获取广告,广告服务器接收各种信息并找出合适广告。广告服务器接收信息包括:IP、GPS信息、os版本、浏览器信息、浏览的网页、历史记录等。
针对广告进行索引
与其他索引搜索操作类似,但是返回的是单个广告。且被索引的广告通常都拥有像位置、年龄或性别这类必须的定向参数。
首先需要确定如何以一致的方式评估广告的价格
- 计算广告价格
按展示次数计费(cost per view CPM)、按点击次数计费(cost per click CPC)、按动作执行次数计费(cost per acquisition CPA)。 - 让广告的价格保持一致
将对所有类型的广告进行转换,使得它们的价格可以基于每千次展示进行计算,产生出一个估算 CPM(estimated CPM),简称eCPM。 - 计算CPC广告的eCPM
将广告的每次点击价格乘以广告的点击通过率(click-through rate,CTR),然后再乘以1000,得出的结果就是广告的eCPM。
如果广告的每次点击价格为0.25美元,通过率为0.2%(也就是0.002),那么广告的eCPM为0.25×0.002×1000=0.5美元。 - 计算CPA广告的eCPM
将广告的点击通过率、用户在广告投放者的目标页面上执行动作的概率、被执行动作的价格这三者相乘起来,然后再乘以1000,得出的结果就是广告的eCPM。
如果广告的点击通过率为0.2%,用户执行动作的概率为10%(也就是0.1),而广告的CPA为3美元,那么广告的eCPM为0.002×0.1×3×1000=0.60美元。
# 大多数广告的动作执行次数都会明显少于点击次数,但每个动作的价格通常比每次点击的价格要高不少。 def cpc_to_ecpm(views, clicks, cpc): return 1000. * cpc * clicks / views def cpa_to_ecpm(views, actions, cpa): return 1000. * cpa * actions / views - 将广告插入索引
为了定向,广告系统接收两个定向选项:位置和内容。位置选项是必须的;广告和页面间的任何匹配单词是可选的,只作为广告附加值存在。
广告定向系统也会使用由集合和有序集合构成的反向索引来存储广告ID。必须的位置定向参数会被存储到集合里面,并且这些位置参数不会提供任何附加值。
TO_ECPM = {
'cpc': cpc_to_ecpm,
'cpa': cpa_to_ecpm,
'cpm': lambda *args:args[-1],
}
# 1. 将一个广告和任意多个定向位置关联起来
# 2. 用字典将广告平均点击次数和平均动作执行次数相关信息存储起来
# 3. 把所有能够对广告进行定向的单词都存储到集合里面
def index_ad(conn, id, locations, content, type, value):
pipeline = conn.pipeline(True)
# 添加广告id到set
for location in locations:
pipeline.sadd('idx:req:'+location, id)
# 索引广告包含的单词
words = tokenize(content)
for word in words:
pipeline.zadd('idx:' + word, id, 0)
# 为了评估新广告,使用dict存储广告每1000次平均点击次数或平均动作执行次数
rvalue = TO_ECPM[type](
1000, AVERAGE_PER_1K.get(type, 1), value)
# 记录广告类型
pipeline.hset('type:', id, type)
# 记录所有广告的eCPM到zset
pipeline.zadd('idx:ad:value:', id, rvalue)
# 记录基本价格
pipeline.zadd('ad:base_value:', id, value)
# 记录所有能对广告进行定向的单词
pipeline.sadd('terms:' + id, *list(words))
pipeline.execute()执行广告定向操作
找到匹配用户位置的广告中eCPM最高的那条。除了基于位置,程序还会记录页面内容与广告内容的匹配程度、不同匹配程度对广告点击通过率的影响等统计数据。
展示广告之前,系统不会为Web页面的任何内容设置附加值。但是当系统开始展示广告的时候,它就会记录下广告中包含的哪个单词改善或者损害了广告的预期效果,并据此修改各个可选的定向单词的相对价格。
为了执行定向操作,系统将对所有相关的位置集合执行并集计算操作,产生出最初的一组广告,并向浏览者进行展示。之后系统会分析广告所在的页面,添加相关的附加值,并最终为每个广告都计算出一个总计(total)eCPM值。在计算出每个广告的eCPM之后,系统会获取eCPM最高的那个广告的ID,记录一些关于本次定向操作的统计数据,最后返回被获取的广告。
def target_ads(conn, locations, content):
pipeline = conn.pipeline(True)
# 根据位置匹配广告,返回广告和ecpm
matched_ads, base_ecpm = match_location(pipeline, locations) #A
# 计算附加值
words, targeted_ads = finish_scoring(pipeline, matched_ads, base_ecpm, content) #B
# 获取ID,用于汇报并记录这个被定向的广告
pipeline.incr('ads:served:') #C
# 找到eCPM最高的广告ID
pipeline.zrevrange('idx:' + targeted_ads, 0, 0) #D
target_id, targeted_ad = pipeline.execute()[-2:]
# 无匹配返回空值
if not targeted_ad: #E
return None, None #E
ad_id = targeted_ad[0]
# 记录一些列定向操作的执行结果,用于学习用户行为
record_targeting_result(conn, target_id, ad_id, words) #F
# 返回本次定向操作相关id,广告id
return target_id, ad_id
# 这个函数唯一令人觉得奇怪的地方,可能就在于它向zintersect() 函数传递了一个古怪的_execute 关键字参数,这个参数可以将实际的eCPM计算操作推延到之后再执行,从而尽可能地减少客户端与Redis之间的通信往返次数。
def match_location(pipe, locations):
required = ['req:' + loc for loc in locations] #A
matched_ads = union(pipe, required, ttl=300, _execute=False) #B
return matched_ads, zintersect(pipe, #C
{matched_ads: 0, 'ad:value:': 1}, _execute=False) #C计算定向附加值
计算附加值就是基于页面内容和广告内容两者之间相匹配的单词,计算出应该给广告的eCPM价格加上多少增量。并将这些附加值存储到了每个单词对应的有序集合里面,其中有序集合的成员为广告ID,而成员的分值则是给eCPM增加的数值。
def finish_scoring(pipe, matched, base, content):
bonus_ecpm = {}
# 内容标记化处理,与广告匹配
words = tokenize(content) #A
for word in words:
# 位于定向位置内,又拥有页面内容一个单词的广告
word_bonus = zintersect( #B
pipe, {matched: 0, word: 1}, _execute=False) #B
bonus_ecpm[word_bonus] = 1 #B
if bonus_ecpm:
# 计算每个广告的最小eCPM和最大eCPM
minimum = zunion( #C
pipe, bonus_ecpm, aggregate='MIN', _execute=False) #C
maximum = zunion( #C
pipe, bonus_ecpm, aggregate='MAX', _execute=False) #C
# 广告基本价格、最小eCPM一半、最大eCPM一半相加
return words, zunion( #D
pipe, {base:1, minimum:.5, maximum:.5}, _execute=False) #D
# 无任何匹配词则返回基本eCPM
return words, base #E从用户行为中学习
如何通过记录被匹配单词以及被定向广告的相关信息来发现用户行为的基本模式,从而开发出能够为定向广告中的每个被匹配单词独立计算附加值的方法。
广告投放的效果归根结底是由上下文决定的通过对广告中的单词和Web页面内容中的单词进行匹配,程序可以简单快速地完成上下文匹配工作。
浏览记录
把那些与广告定向操作执行结果有关的信息记录下来,并在之后使用被记录的信息计算点击通过率、动作执行率以及每个单词最终的eCPM附加值。
- 被定向至给定广告的单词;
- 给定广告被定向的总次数;
- 广告中的某个单词被用于计算附加值的总次数。
def record_targeting_result(conn, target_id, ad_id, words):
pipeline = conn.pipeline(True)
# 找到内容与广告匹配的单词
terms = conn.smembers('terms:' + ad_id) #A
matched = list(words & terms) #A
if matched:
matched_key = 'terms:matched:%s' % target_id
# 有匹配的单词就记录,设置15分钟ttl
pipeline.sadd(matched_key, *matched) #B
pipeline.expire(matched_key, 900) #B
# 为每种广告分别记录它们展示次数
type = conn.hget('type:', ad_id) #C
pipeline.incr('type:%s:views:' % type) #C
# 记录广告及其包含的单词展示信息
for word in matched: #D
pipeline.zincrby('views:%s' % ad_id, word) #D
pipeline.zincrby('views:%s' % ad_id, '') #D
# 每100次更新一次eCPM
if not pipeline.execute()[-1] % 100: #E
update_cpms(conn, ad_id) #E记录点击和动作
当用户点击某个广告的时候,在将用户引导至广告的目的地之前,系统会根据广告的类型,将这次点击计入为该类型广告而设置的点击计数器里面,同时被记录下来的还有被点击的广告,以及与被点击广告相匹配的单词。
def record_click(conn, target_id, ad_id, action=False):
pipeline = conn.pipeline(True)
click_key = 'clicks:%s'%ad_id
match_key = 'terms:matched:%s'%target_id
type = conn.hget('type:', ad_id)
if type == 'cpa': #A
pipeline.expire(match_key, 900) #A
if action: # 如果是按动作计费,且单词任存在,那么刷新ttl
click_key = 'actions:%s' % ad_id #记录动作信息而非点击信息
# 维持全局点击/动作计数器
if action and type == 'cpa':
pipeline.incr('type:%s:actions:' % type) #C
else:
pipeline.incr('type:%s:clicks:' % type) #C
# 为广告及所有被定向至该广告的单词记录本次点击或动作
matched = list(conn.smembers(match_key))#D
matched.append('') #D
for word in matched: #D
pipeline.zincrby(click_key, word) #D
pipeline.execute()
# 更新所有出现的单词eCPM
update_cpms(conn, ad_id) #E更新eCPM
def update_cpms(conn, ad_id):
pipeline = conn.pipeline(True)
# 获取广告类型、价格、广告包含的单词
pipeline.hget('type:', ad_id) #A
pipeline.zscore('ad:base_value:', ad_id) #A
pipeline.smembers('terms:' + ad_id) #A
type, base_value, words = pipeline.execute()#A
# 判断广告的eCPM基于点击次数或基于动作执行次数
which = 'clicks' #B
if type == 'cpa': #B
which = 'actions' #B
# 根据广告类型,获取展示次数、点击次数、执行次数
pipeline.get('type:%s:views:' % type) #C
pipeline.get('type:%s:%s' % (type, which)) #C
type_views, type_clicks = pipeline.execute() #C
# 将点击率或动作执行率写入全局字典
AVERAGE_PER_1K[type] = ( #D
1000. * int(type_clicks or '1') / int(type_views or '1')) #D
if type == 'cpm': #E
return #E
view_key = 'views:%s' % ad_id
click_key = '%s:%s' % (which, ad_id)
to_ecpm = TO_ECPM[type]
pipeline.zscore(view_key, '') #G
pipeline.zscore(click_key, '') #G
ad_views, ad_clicks = pipeline.execute() #G
# 还没被点击过,使用已有eCPM
if (ad_clicks or 0) < 1: #N
ad_ecpm = conn.zscore('idx:ad:value:', ad_id) #N
else:
# 计算广告的eCPM并更新价格
ad_ecpm = to_ecpm(ad_views or 1, ad_clicks or 0, base_value)#H
pipeline.zadd('idx:ad:value:', ad_id, ad_ecpm) #H
for word in words:
# 获取单词暂时次数、点击次数、动作次数
pipeline.zscore(view_key, word) #I
pipeline.zscore(click_key, word) #I
views, clicks = pipeline.execute()[-2:] #I
if (clicks or 0) < 1: #J
continue #J
word_ecpm = to_ecpm(views or 1, clicks or 0, base_value) #计算eCPM
bonus = word_ecpm - ad_ecpm #计算附加值
pipeline.zadd('idx:' + word, ad_id, bonus) #重写附加值
pipeline.execute()职位搜索
逐个查找合适的职位
每个职位对应一个集合,集合里面记录了获取职位所需技能。
def add_job(conn, job_id, required_skills):
conn.sadd('job:' + job_id, *required_skills) #A
def is_qualified(conn, job_id, candidate_skills):
temp = str(uuid.uuid4())
pipeline = conn.pipeline(True)
# 把求职者拥有技能全添加到一个临时集合里,设置ttl
pipeline.sadd(temp, *candidate_skills) #B
pipeline.expire(temp, 5) #B
# 找出职位需求中,求职者不具备的,记录下来
pipeline.sdiff('job:' + job_id, temp) #C
# 如果全部具备,返回True
return not pipeline.execute()[-1] #D以搜索方式查找合适的职位
def index_job(conn, job_id, skills):
pipeline = conn.pipeline(True)
for skill in skills:
# 将职位ID添加到技能集合
pipeline.sadd('idx:skill:' + skill, job_id) #A
# 将职位所需技能数量添加到记录了所欲职位所需技能数量的zset中
pipeline.zadd('idx:jobs:req', job_id, len(set(skills))) #B
pipeline.execute()
def find_jobs(conn, candidate_skills):
skills = {} #A
for skill in set(candidate_skills): #A
skills['skill:' + skill] = 1 #A
# 求职者对每个职位的得分
job_scores = zunion(conn, skills) #B
final_result = zintersect( #C
conn, {job_scores:-1, 'jobs:req':1}) #C
return conn.zrangebyscore('idx:' + final_result, 0, 0) #D

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!