
Redis实战3 - 使用Redis构建应用程序组件
使用Redis构建应用程序组件
自动补全
搜索框中输入几个字符后给出相关提示
自动补全最近联系人
给出以输入字符为起始的用户名。服务器上数百万用户每人都有一个属于自己的联系人列表存储最近联系过的100个人,为了在快速写入的前提下尽量减少内存消耗,使用Redis的列表以有序方式存储元素。但是Redis没有提供自动补全的功能,所以使用python进行过滤工作。
构建最新联系人列表:
- 如果已存在于最近联系人列表,那么移除他。使用
LREM - 将指定联系人添加到列表最前端。使用
LPUSH - 如果数量超过100,进行修剪。使用
LTRIM
def add_update_contact(conn, user, contact):
ac_list = 'recent:' + user
pipeline = conn.pipeline(True) #A
pipeline.lrem(ac_list, contact) #B
pipeline.lpush(ac_list, contact) #C
pipeline.ltrim(ac_list, 0, 99) #D
pipeline.execute() #E
def remove_contact(conn, user, contact):
conn.lrem('recent:' + user, contact)对获取的用户数据进行过滤,可在服务端也可在客户端进行
def fetch_autocomplete_list(conn, user, prefix):
candidates = conn.lrange('recent:' + user, 0, -1) #A
matches = []
for candidate in candidates: #B
if candidate.lower().startswith(prefix.lower()): #B
matches.append(candidate) #C
return matches #D因为已经明确限制了列表最多存储100人,所以此处没有问题。但是不适合处理非常大的列表。如果要处理“最常使用列表”可以使用带有时间戳的有序集合。
通讯录自动补全
只允许用户向属于同一“公会”的其他玩家发送邮件。使用有序集合在Redis内部完成自动补全的前缀工作。将zset的分值设置为0,根据成员的名字顺序排列。为了实现补全操作,程序以小写字母方式插入联系人名字,且只能包含英文字母,这样就不用处理数字或符号了。
如何实现补全功能?用户名类似 [abc, abca, abcd, ..., abd] ,查找abc前缀的单词就是查找介于abbz...之后和abd之前的字符串。在ASCII编码中,z之后的字符为{,a之前的为`。abc...位于abb{和abc{之间;aba...位于ab`{和aba{之间
确定查找范围后将起始、结束元素插入然后查看排名,取出一些元素后再移除这两个元素,最多取10个。为了防止自动补全程序在多个用户同时向同一个公会成员发送消息时,将多个相同的起始结束元素重复添加到zset,或错误地移除一个由其他程序添加的起始结束元素,程序将一个UUID添加到起始结束元素后。通过 WATCH MULTI EXEC 确保有序集合不会在范围查找和范围取值期间发生变化。
valid_characters = '`abcdefghijklmnopqrstuvwxyz{' #A
def find_prefix_range(prefix):
posn = bisect.bisect_left(valid_characters, prefix[-1:]) #B
suffix = valid_characters[(posn or 1) - 1] #C
return prefix[:-1] + suffix + '{', prefix + '{' #D
def autocomplete_on_prefix(conn, guild, prefix):
start, end = find_prefix_range(prefix) #A
identifier = str(uuid.uuid4()) #A
start += identifier #A
end += identifier #A
zset_name = 'members:' + guild
conn.zadd(zset_name, start, 0, end, 0) #B
pipeline = conn.pipeline(True)
while 1:
try:
pipeline.watch(zset_name)
sindex = pipeline.zrank(zset_name, start) #C
eindex = pipeline.zrank(zset_name, end) #C
erange = min(sindex + 9, eindex - 2) #C
pipeline.multi()
pipeline.zrem(zset_name, start, end) #D
pipeline.zrange(zset_name, sindex, erange) #D
items = pipeline.execute()[-1] #D
break
except redis.exceptions.WatchError: #E
continue #E
return [item for item in items if '{' not in item] #F
# 加入离开公会
def join_guild(conn, guild, user):
conn.zadd('members:' + guild, user, 0)
def leave_guild(conn, guild, user):
conn.zrem('members:' + guild, user)分布式锁
由不同机器的Redis客户端获取和释放。使用 SETNX 命令和其他操作。Redis提供的WATCH是乐观锁失败后会反复重试,并发情况下资源消耗严重无法拓展。
简易锁
实现简单,可能存在问题。一些不正确的原因和症状:
- 进程长时间持有锁导致锁被自动释放,进程不知道并释放其他进程持有的锁
- 持有锁并打算执行长时间操作的进程崩溃,其他进程不知道也无法检测,只能浪费时间等待
- 多个进程同时尝试获取锁,且都获得
- 情况一、三同时出现,多个进程得到了锁,每个进程都以为自己是唯一获得锁的进程
使用SETNX设置不存在的键,使用UUID作为值。使用UUID防止锁被其他进程获得。如果程序在获取锁时失败将不断重试,直到成功或超时。
在程序持有锁时其他客户端可能擅自对锁进行修改,释放锁也要谨慎:使用WATCH监视代表锁的键,检查值是否是加锁时的值,确定无误后删除键。这样可以防止释放同一个锁多次。
def acquire_lock(conn, lockname, acquire_timeout=10):
identifier = str(uuid.uuid4()) #A
end = time.time() + acquire_timeout
while time.time() < end:
# 尝试获取锁
if conn.setnx('lock:' + lockname, identifier): #B
return identifier
time.sleep(.001)
return False
def release_lock(conn, lockname, identifier):
pipe = conn.pipeline(True)
lockname = 'lock:' + lockname
# 之后会实现带超时版本的上锁,混合使用后可能引起解锁事务的失败,导致上锁时间延长
while True:
try:
pipe.watch(lockname) #A
# 键对应的值与加锁时一致才解锁
if pipe.get(lockname) == identifier: #A
pipe.multi() #B
pipe.delete(lockname) #B
pipe.execute() #B
return True #B
pipe.unwatch()
break
except redis.exceptions.WatchError: #C
pass #C
return False #D
def purchase_item_with_lock(conn, buyerid, itemid, sellerid):
buyer = "users:%s" % buyerid
seller = "users:%s" % sellerid
item = "%s.%s" % (itemid, sellerid)
inventory = "inventory:%s" % buyerid
# 获取锁,锁住交易市场'market:'
locked = acquire_lock(conn, 'market:') #A
if not locked:
return False
pipe = conn.pipeline(True)
try:
# 检查商品是否仍在出售,买家钱是否足够
pipe.zscore("market:", item) #B
pipe.hget(buyer, 'funds') #B
price, funds = pipe.execute() #B
if price is None or price > funds: #B
return None #B
# 钱和商品转移
pipe.hincrby(seller, 'funds', int(price)) #C
pipe.hincrby(buyer, 'funds', int(-price)) #C
pipe.sadd(inventory, itemid) #C
pipe.zrem("market:", item) #C
pipe.execute() #C
return True
finally:
# 释放锁
release_lock(conn, 'market:', locked) #D如果要提升效率,可以使用更细粒度的锁。但是需要锁住多个小部分数据、数据不止一份、锁住结构的多个部分时就很困难,可能出现死锁。
带超时限制的死锁
防止持有者崩溃后不自动释放锁。可使用 SETNX 和 EXPIRE 组合,如果在这两条命令之间奔溃则非常糟糕,这种情况下请求锁的客户端取锁失败后要设置超时时间。或 SET key val NX EX time
def acquire_lock_with_timeout(
conn, lockname, acquire_timeout=10, lock_timeout=10):
identifier = str(uuid.uuid4()) #A
lockname = 'lock:' + lockname
lock_timeout = int(math.ceil(lock_timeout)) #D
end = time.time() + acquire_timeout
while time.time() < end:
if conn.setnx(lockname, identifier): #B
conn.expire(lockname, lock_timeout) #B
return identifier
elif conn.ttl(lockname) < 0: #C
conn.expire(lockname, lock_timeout) #C
time.sleep(.001)
return False计数信号量
与锁类似,也要获取与释放。client获取、执行、释放。获取锁失败时client进行等待,获取信号量失败时立即返回失败结果。
情景:每个游戏账号最多只能有5个进程同时访问市场
基本计数信号
Redis实现超时限制通常有两种方法:
- EXPIRE超时命令
- 使用 zset 结构
这里使用zset结构。程序为每个尝试获取信号量的进程生成唯一标识符,其对应分值为时间戳。获取信号量时将标识符添加到zset中,接着检查自己的排名。如果低于可获取的信号量总数则表示成功,否则表示失败并移除自己的标识符。为了处理过期信号量,程序每次都会先清除超时的标识符。

def acquire_semaphore(conn, semname, limit, timeout=10):
identifier = str(uuid.uuid4()) #A
now = time.time()
pipeline = conn.pipeline(True)
# 清理过期信号
pipeline.zremrangebyscore(semname, '-inf', now - timeout) #B
# 尝试获取
pipeline.zadd(semname, identifier, now) #C
pipeline.zrank(semname, identifier) #D
if pipeline.execute()[-1] < limit: #D
return identifier
# 添加失败
conn.zrem(semname, identifier) #E
return None
def release_semaphore(conn, semname, identifier):
return conn.zrem(semname, identifier)问题:当每个进程访问到的系统时间不一致时,如多主机环境下,存在问题。系统A的时间比B快10毫秒,当A取得最后一个信号量的10毫秒内,B可以在A不知情的情况下“偷走”A已取得的信号量。对少部分应用,这是个确实存在的问题。
公平信号量
对主机间时差要求在一两秒内
每当锁或者信号量因为系统时钟的细微不同而导致锁的获取结果出现剧烈变化时,这个锁或者信号量就是不公平的 (unfair)。不公平的锁和信号量可能会导致客户端永远也无法取得它原本应该得到的锁或信号量。
为了防止系统时间不一致,增加一个counter和一个zset。counter保证先操作它的客户端能获得信号量,将从counter得到的值用作zset的分值。再通过检查标识符判断是否取得信号量。

def acquire_fair_semaphore(conn, semname, limit, timeout=10):
identifier = str(uuid.uuid4()) #A
czset = semname + ':owner'
ctr = semname + ':counter'
# 移除过期元素
now = time.time()
pipeline = conn.pipeline(True)
pipeline.zremrangebyscore(semname, '-inf', now - timeout) #B
# 将超时集合和拥有者集合做交集,保存到拥有者集合
pipeline.zinterstore(czset, {czset: 1, semname: 0}) #B
# 对计数器自增操作
pipeline.incr(ctr) #C
counter = pipeline.execute()[-1] #C
# 加到zset中
pipeline.zadd(semname, identifier, now) #D
pipeline.zadd(czset, identifier, counter) #D
# 检查排名,及是否成功获得锁
pipeline.zrank(czset, identifier) #E
if pipeline.execute()[-1] < limit: #E
return identifier #F
# 获取失败则移除
pipeline.zrem(semname, identifier) #G
pipeline.zrem(czset, identifier) #G
pipeline.execute()
return None
def release_fair_semaphore(conn, semname, identifier):
pipeline = conn.pipeline(True)
pipeline.zrem(semname, identifier)
pipeline.zrem(semname + ':owner', identifier)
return pipeline.execute()[0]刷新信号量
默认超时时间是一致的,但有些任务耗时较长。这就需要更新超时时间。
def refresh_fair_semaphore(conn, semname, identifier):
if conn.zadd(semname, identifier, time.time()): #A
# 丢失信号量,通常是因为超时
release_fair_semaphore(conn, semname, identifier) #B
return False #B
return True消除竞争条件
可能存在情况:剩最后一个信号量,A先对counter做自增B随后,但是B先将标识符添加到两个zset中成功获得信号量。A再添加到zset且位于B前,检查到自己的排名在规定限额内,于是A也获得了信号量。
为此,在获取信号量时还要尝试获取一个带有短暂超时时间的锁。
def acquire_semaphore_with_lock(conn, semname, limit, timeout=10):
identifier = acquire_lock(conn, semname, acquire_timeout=.01)
if identifier:
try:
return acquire_fair_semaphore(conn, semname, limit, timeout)
finally:
release_lock(conn, semname, identifier)应用锁和信号量到不同场景中
任务队列
FIFO
场景:使用队列异步发送邮件。使用Redis的BLPOP、RPUSH
程序将邮件序列化为json格式用RPUSH推入队列,然后用BLPOP拉取邮件信息,BLPOP的最大阻塞时间为30秒。

def send_sold_email_via_queue(conn, seller, item, price, buyer):
data = {
'seller_id': seller, #A
'item_id': item, #A
'price': price, #A
'buyer_id': buyer, #A
'time': time.time() #A
}
conn.rpush('queue:email', json.dumps(data)) #B
def process_sold_email_queue(conn):
while not QUIT:
# 尝试获取,没有则重试
packed = conn.blpop(['queue:email'], 30) #A
if not packed: #B
continue #B
to_send = json.loads(packed[1]) #C
try:
# 从json对象解码出信息并发送
fetch_data_and_send_sold_email(to_send) #D
except EmailSendError as err:
log_error("Failed to send sold email", err, to_send)
else:
log_success("Sent sold email", to_send)上面展示的队列只能处理发送邮件这一种任务,一般每种任务都单独使用一个队列。也可将回调函数和参数添加到json数据中以实现一个队列处理多种任务。
def worker_watch_queue(conn, queue, callbacks):
while not QUIT:
packed = conn.blpop([queue], 30) #A
if not packed: #B
continue #B
name, args = json.loads(packed[1]) #C
if name not in callbacks: #D
log_error("Unknown callback %s"%name) #D
continue #D
# callback为字典类型,保存了name-func键值对
callbacks[name](*args) #E延迟任务
3种思路
- (浪费时间)任务信息包含执行时间,客户端发现拉取的任务未到执行时间,短暂等待后把任务重新推入队列
- (进程崩溃会丢失信息)使用一个本地等待队列记录未来执行的任务,每次循环时检查
- (采用此方法)所有未来执行的任务添加到一个zset,执行时间设置为分值,用另一个进程查找,如果有则将其添加到适当队列
每个延迟任务都是一个有4个值的json列表:唯一标识符UUID、处理任务队列的名字、回调函数的名字、传给回调函数的参数。
def execute_later(conn, queue, name, args, delay=0):
identifier = str(uuid.uuid4()) #A
item = json.dumps([identifier, queue, name, args]) #B
if delay > 0:
conn.zadd('delayed:', item, time.time() + delay) #C
else:
# 无需延迟则直接推入任务队列
conn.rpush('queue:' + queue, item) #D
return identifier #E
# 因为Redis的zset没有阻塞弹出机制,所以使用死循环
def poll_queue(conn):
while not QUIT:
item = conn.zrange('delayed:', 0, 0, withscores=True)
# 没有延时任务或时间未到
if not item or item[0][1] > time.time(): #B
time.sleep(.01) #B
continue #B
# 解码任务并放入相应任务队列
item = item[0][0] #C
identifier, queue, function, args = json.loads(item) #C
# 为了移动任务而获取锁,失败则跳过后续步骤
locked = acquire_lock(conn, identifier) #D
if not locked: #E
continue #E
if conn.zrem('delayed:', item): #F
conn.rpush('queue:' + queue, item) #F
release_lock(conn, identifier, locked) #G消息拉取
消息推送:Redis提供的PUBLISH/SUBSCRIBE的缺陷在于客户端必须一致在线才能接收消息,断线可能导致客户端丢失信息;旧版Redis可能因订阅者处理信息不够快而不稳定甚至被杀死。
消息拉取:接收者主动去获取邮箱中的消息。
单接收者
场景:应用发送或接收类似短信、彩信的消息。每条消息发送至一个客户端。
每个client在redis中使用一个列表存储消息,发送者将消息放到对应列表中,接收者通过发送请求获得最新消息。发送者只要检查接收者的未读消息队列就可知道最近是否上线、是否接收到消息、是否有太多消息未处理。

多接收者
实现群组聊天功能。因为客户端可能在任何时候连接或断开,故不能使用内置PUBLICSH/SUBSCRIBE。
每个新建群组都有初始用户,每个用户都可以参加或离开群组。
参加群组用户使用zset,成员为用户名字,分值为接收到最大消息ID。
用户用zset记录参加的群组,成员为群组ID,分值为接收到最大消息ID。
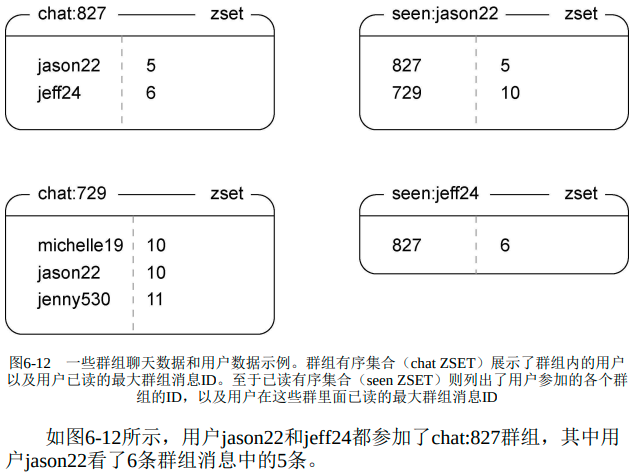
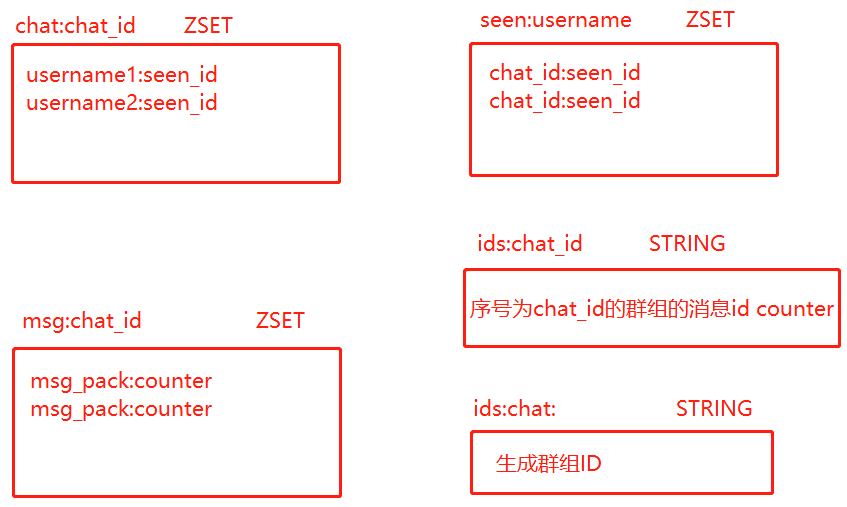
seen_id是用户查看的最后一条消息id,两个表中seen_id相同,都是某一条msg的counter编号。群组与用户是多对多关系。除ids:chat:表以外,每张表多有多张,分别对应不同的群组或用户。
创建群组聊天会话
以消息为成员、消息ID为分值。创建新群组时通过全局计数器获得新群组ID,
之后将初始用户添加到有序集合,将最大已读消息初始化为0,
还把新群组ID添加到记录用户已参加的zset中。
最后发送一条初始化消息到群组zset中
chat ZSET (群组内用户,已读最大群组消息ID)
seen ZSET(用户参加的群组ID,在群组内已读最大消息ID)
def create_chat(conn, sender, recipients, message, chat_id=None):
chat_id = chat_id or str(conn.incr('ids:chat:')) # 新群组ID
# 存到 chat zset 的元素(用户名,最新已读消息ID)
recipients.append(sender) #E
recipientsd = dict((r, 0) for r in recipients) #E
pipeline = conn.pipeline(True)
pipeline.zadd('chat:' + chat_id, **recipientsd) # 添加用户到 chat ZSET
for rec in recipients: #
pipeline.zadd('seen:' + rec, chat_id, 0) # 初始化 seen ZSET
pipeline.execute()
return send_message(conn, chat_id, sender, message) # 发消息发送消息
想群组发送消息需要一个新消息ID,并将消息添加到chat ZSET。这存在竞争条件,要使用Redis分布式锁。
def send_message(conn, chat_id, sender, message):
# 锁住相应的 chat zset
identifier = acquire_lock(conn, 'chat:' + chat_id)
if not identifier:
raise Exception("Couldn't get the lock")
try:
mid = conn.incr('ids:' + chat_id)
ts = time.time()
packed = json.dumps({
'id': mid, # 在序号为chat_id的群组中 msg_id
'ts': ts, # 发送时间
'sender': sender,
'message': message,
})
# 发送消息
conn.zadd('msgs:' + chat_id, packed, mid)
finally:
release_lock(conn, 'chat:' + chat_id, identifier)
return chat_id获取消息
对 seen-zset 执行ZRANGE得到群组ID和已读消息ID,对用户参与的所有群组的消息有序集合执行ZRANGEBYSCORE,得到用户在各个群组内未读消息。取得消息ID后对 seen-zset chat-zset里用户记录进行更新。最后查找并清除被所有人接收的消息。
def fetch_pending_messages(conn, recipient):
# 获取最后接收到的消息ID
seen = conn.zrange('seen:' + recipient, 0, -1, withscores=True) #A
pipeline = conn.pipeline(True)
# 获取所有未读消息
for chat_id, seen_id in seen: #B
pipeline.zrangebyscore('msgs:' + chat_id, seen_id+1, 'inf') #B
chat_info = zip(seen, pipeline.execute()) #C
# 将数据返回给函数调用者
for i, ((chat_id, seen_id), messages) in enumerate(chat_info):
if not messages:
continue
messages[:] = map(json.loads, messages)
# 更新 chat:chat_id 和 seen:user_name 结构中 seen_id 值
seen_id = messages[-1]['id'] #D
conn.zadd('chat:' + chat_id, recipient, seen_id) #D
pipeline.zadd('seen:' + recipient, chat_id, seen_id) #F
# 找到被所有人阅读过的消息
min_id = conn.zrange('chat:' + chat_id, 0, 0, withscores=True)
if min_id:
# 清除被所有人阅读过的消息
pipeline.zremrangebyscore('msgs:' + chat_id, 0, min_id[0][1]) #G
chat_info[i] = (chat_id, messages)
pipeline.execute()
return chat_info获取未读消息的工作就是遍历用户参与的所有群组,取出每个群组的未读消息,并顺便清理那些已经被所有群组用户看过的消息。
加入离开群组
# 是在用户和群组之间以及群组和用户的已读消息有序集合之间,建立起正确的引用信息
def join_chat(conn, chat_id, user):
message_id = int(conn.get('ids:' + chat_id)) #A
pipeline = conn.pipeline(True)
pipeline.zadd('chat:' + chat_id, user, message_id) #B
pipeline.zadd('seen:' + user, chat_id, message_id) #C
pipeline.execute()
# 从群组有序集合里面移除用户的ID,并从用户的已读消息有序集合里面移除给定群组的相关信息。
# 如果群组已经没有任何成员存在,那么群组的消息有序集合以及消息ID计数器将被删除。如果群组还有成员存在,那么程序将再次查找并清除那些已经被所有成员阅读过的群组消息。
def leave_chat(conn, chat_id, user):
pipeline = conn.pipeline(True)
pipeline.zrem('chat:' + chat_id, user) #A
pipeline.zrem('seen:' + user, chat_id) #A
pipeline.zcard('chat:' + chat_id) #B
if not pipeline.execute()[-1]:
pipeline.delete('msgs:' + chat_id) #C
pipeline.delete('ids:' + chat_id) #C
pipeline.execute()
else:
oldest = conn.zrange('chat:' + chat_id, 0, 0, withscores=True)
conn.zremrangebyscore('msgs:' + chat_id, 0, oldest[0][1])文件分发
根据地理位置聚合用户数据
实现执行聚合计算所需的回调函数,并用它们实时分析日志数据。为了高效处理日志,程序对Redis更新前先将聚合数据缓存到本地来减少执行所需通信往返次数。
程序将日志行传递给聚合计算的回调函数,回调函数对相应的国家计数器自增,结果写入Redis
# 本地聚合数据字典
aggregates = defaultdict(lambda: defaultdict(int))
def daily_country_aggregate(conn, line):
if line:
line = line.split()
ip = line[0]
day = line[1]
country = find_city_by_ip_local(ip)[2]
aggregates[day][country] += 1 # 本地聚合数据递增
return
# 将聚合数据写入redis
for day, aggregate in aggregates.items():
conn.zadd('daily:country:' + day, **aggregate)
del aggregates[day]发送日志文件
根据指定键名将日志文件存储到redis中,再使用之前的群组聊天功能,将存储日志的键名发到群组中,等待分析操作执行完成的通知到来
def copy_logs_to_redis(conn, path, channel, count=10,
limit=2**30, quit_when_done=True):
bytes_in_redis = 0
waiting = deque()
# 用于发送消息的群组
create_chat(conn, 'source', map(str, range(count)), '', channel) #I
count = str(count)
for logfile in sorted(os.listdir(path)): #A
full_path = os.path.join(path, logfile)
fsize = os.stat(full_path).st_size
# 如果需要更多空间则清除已处理完毕的文件
while bytes_in_redis + fsize > limit: #B
cleaned = _clean(conn, channel, waiting, count)#B
if cleaned: #B
bytes_in_redis -= cleaned #B
else: #B
time.sleep(.25) #B
# 上传文件到redis
with open(full_path, 'rb') as inp: #C
block = ' ' #C
while block: #C
block = inp.read(2**17) #C
conn.append(channel+logfile, block) #C
send_message(conn, channel, 'source', logfile) #D
# 更新redis内存占用量
bytes_in_redis += fsize #E
waiting.append((logfile, fsize)) #E
# 日子上传完毕,向监听者发消息
if quit_when_done: #F
send_message(conn, channel, 'source', ':done') #F
# 清理无用日志
while waiting: #G
cleaned = _clean(conn, channel, waiting, count) #G
if cleaned: #G
bytes_in_redis -= cleaned #G
else: #G
time.sleep(.25) #G
def _clean(conn, channel, waiting, count): #H
if not waiting: #H
return 0 #H
w0 = waiting[0][0] #H
# 等待处理进程完成处理
if conn.get(channel + w0 + ':done') == count: #H
conn.delete(channel + w0, channel + w0 + ':done') #H
return waiting.popleft()[1] #H
return 0 #H接收日志文件
使用一组函数和生成器,从群组中获得日志文件名,再对存在Redis中的日志文件处理,之后更新复制进程正在等的键。使用回调函数处理每个日志行,更新聚合数据。
def process_logs_from_redis(conn, id, callback):
while 1:
# 获取文件列表
fdata = fetch_pending_messages(conn, id) #A
for ch, mdata in fdata:
for message in mdata:
logfile = message['message']
# 所有日志处理完毕
if logfile == ':done': #B
return #B
elif not logfile:
continue
# 选择一个块处理器
block_reader = readblocks #C
if logfile.endswith('.gz'): #C
block_reader = readblocks_gz #C
# 遍历并处理日志
for line in readlines(conn, ch+logfile, block_reader):#D
callback(conn, line)
# 强制刷新聚合数据缓存
callback(conn, None) #F
# 向日志发送者报告这一信息
conn.incr(ch + logfile + ':done') #G
if not fdata:
time.sleep(.1)处理日志文件
def readlines(conn, key, rblocks): # rblocks 为块迭代回调函数
out = ''
for block in rblocks(conn, key):
out += block
posn = out.rfind('\n') #A
if posn >= 0: #B
for line in out[:posn].split('\n'): #C
yield line + '\n' #D
out = out[posn+1:] # 将不完整的行追加到下一个块
if not block: #F
yield out
break
# 块读取器的封装保证以后可以使用其他读取器代替,如文件系统读取器、memcached读取器
# 直接返回被读取的块
def readblocks(conn, key, blocksize=2**17):
lb = blocksize
pos = 0
# 一直读到出现不完成读操作
while lb == blocksize: #A
# 获取数据块
block = conn.substr(key, pos, pos + blocksize - 1) #B
yield block #C
# 为下一次遍历做准备
lb = len(block) #C
pos += lb #C
yield ''
# 自动解压gzip格式压缩文件
def readblocks_gz(conn, key):
inp = ''
decoder = None
for block in readblocks(conn, key, 2**17): #A
if not decoder:
inp += block
try:
# 分析头信息以得到被压缩的信息
if inp[:3] != "\x1f\x8b\x08": #B
raise IOError("invalid gzip data") #B
i = 10 #B
flag = ord(inp[3]) #B
if flag & 4: #B
i += 2 + ord(inp[i]) + 256*ord(inp[i+1]) #B
if flag & 8: #B
i = inp.index('\0', i) + 1 #B
if flag & 16: #B
i = inp.index('\0', i) + 1 #B
if flag & 2: #B
i += 2 #B
# 程序读取的头信息并不完整
if i > len(inp): #C
raise IndexError("not enough data") #C
except (IndexError, ValueError): #C
continue #C
else:
# 找到头信息准备解压
block = inp[i:] #D
inp = None #D
decoder = zlib.decompressobj(-zlib.MAX_WBITS) #D
if not block:
continue
# 所有数据处理完毕,向调用者返回最后剩下的数据块
if not block: #E
yield decoder.flush() #E
break
# 返回数据块
yield decoder.decompress(block)
