
Redis实战1 - redis使用
Redis
5种结构:STRING LIST SET HASH ZSET
常用命令
https://redis.io/commands/
通用命令
DEL key
DUMP key
EXISTS key
# 过期时间相关
PERSIST key # 移除过期的键
EXPIRE key secnods
EXPIREAT key timestamp
PEXPIRE key milliseconds
PEXPIREAT key millisecond-timestamp
PTTL key # 毫秒形式返回剩余时间
TTL key # 以秒返回剩余时间
KEYS pattern
MOVE key db
RANDOMKEY
RENAME key newkey
RENAMENX key newkey # 当newkey不存在时,将key改为newkey
SCAN cursor [MATCH pattern] [COUNT count] # 迭代key
TYPE keySTRING
GET key
SET key value
SETEX key seconds value # 将value关联到key,并将过期时间设置为seconds
SETNX key value # 不存在时设置
GETRANGE key start end
SETRANGE key offset value
GETSET key value # 返回旧值并设置新值
STRLEN key
GETBIT key offset # 获取指定偏移位置的bit
SETBIT key offset value # 设置指定偏移位置的bit
BITCOUNT key [start end]
BITOP AND|OR|XOR|NOT dest-key key1 [key2...]
MGET key1 [key2...]
MSET key value [key value ...]
MSETNX key value [key value...]
PSETEX key milliseconds value
APPEND key value
INCR key
INCRBY key increment
INCRBYFLOAT key increment
DECR key
DECRBY key decrementLIST 最多包含 2^23 - 1 个元素
BLPOP key1 [key2] timeout # 获取最左边的元素,阻塞超时模式
BRPOP key1 [key2] timeout
BRPOPLPUSH src dest timeout # 从src列表弹出并插入dest列表并返回它,阻塞超时
RPOPLPUSH src dest # 移除src最后一个元素并添入另一个列表,并返回
LINDEX key index
LINSERT key BEFORE|AFTER pivot value # 例:LINSERT mylist BEFORE "World" "There"
LLEN key
LPOP key
LPUSH key value1 [value2]
LPUSHX key value # 插入已存在的列表头部
RPOP key
RPUSH key value1 [value2]
RPUSHX key value
LRANGE key start stop
LREM key count value
LSET key index value
LTRIM key start stop # trim操作,只保留指定区间元素SET
SADD key member1 [member2]
SCARD key # 获取集合成员数
SISMEMBER dest member
SMEMBERS key
SMOVE src dest member
SREM key member1 member2
SPOP key # 返回一个随机数
SRANDMEMBER key [count] # 返回count个随机数
SSCAN key cursor [MATCH pattern] [COUNT count]
SDIFF key1 [key2] # 返回差集
SDIFFSTORE dest key1 [key2] # 存储差集到 dest
SINTER key1 [key2] # 返回交集
SINTERSTORE dest key1 [key2]
SUNION key1 [key2]
SUNIONSTORE dest key1 [key2]HASH
HDEL key field1 [field2]
HEXISTS key field
HKEYS key
HLEN key
HVALS key
HGETALL key
HGET key field
HGETALL key
HSET key field value
HSETNX key field value
HMGET key field1 [field2]
HMSET key field1 value1 [field2 value2]
HINCRBY key field increment
HINCRBYFLOAT key field increment
HSCAN key cursor [MATCH pattern] [COUNT count]ZSET
ZADD key score1 member1 [score2 member2]
ZCARD key
ZCOUNT key min max
ZSCORE key member
ZINCRBY key increment member
ZINTERSTORE dest numkeys key [key...]
ZUNIONSTORE dest numkeys key [key...]
ZLEXCOUNT # 指定字典区间内成员数量
ZSCAN key cursor [MATCH pattern] [COUNT count]
ZRANGE key start stop [WITHSCORES]
ZRANGEBYLEX key min max [LIMIT offset count] # 通过字典区间返回有序集合的成员
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT] # 通过分数返回有序集合指定区间内的成员
ZRANK key member
ZREM key member [member...]
ZREMRANGEBYLEX key min max
ZREMRANGEBYRANK key start stop
ZREMRANGEBYSCORE key min max
ZREVRANGE key start stop [WITHSCORES] # 指定区间成员,通过索引,分数从高到低
ZREVRANGEBYSCORE key max min [WITHSCORES] # 返回有序集中指定分数区间内的成员,分数从高到低排序
ZREVRANK key member # 递减顺序返回所有发布订阅
listener订阅channel,publisher向channel发送二进制字符串消息。每当有消息到达channel时,对应的所有订阅者都会接收到消息。订阅者可同时收听多个电台,发送者可在任何电台发送消息。
SUBSCRIBE channel [channel1...]
UNSUBSCRIBE [channel...]
PUBLISH channel message
PSUBSCRIBE pattern [pattern...] # 订阅与给定模式相匹配的所有频道
PUNSUBSCRIBE [pattern [pattern...]]其他命令
排序
类似sql中 order by 语句
# 根据给定的选项,对输入列表、集合、zset 进行排序,然后返回或存储排序结果
SORT src-key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [ASC|DESC] [ALPHA] [STORE dst-key]
rpush sort-input 23 15 110 7
sort sort-input
# 1) "7"
# 2) "15"
# 3) "23"
# 4) "110"
hset d-7 field 5
hset d-15 field 1
hset d-23 field 9
hset d-110 field 3
sort sort-input BY d-*->field
# 1) "15"
# 2) "110"
# 3) "7"
# 4) "23"
sort sort-input BY d-*->field get d-*->field
# 1) "1"
# 2) "3"
# 3) "5"
# 4) "9"持久化
配置文件
# rdb
save 60 1000 # 60秒内1000次写入就备份
stop-writes-on-bgsave-error no
rdbcompression yes
dbfilename dump.rdb
# aof
appendonly yes
appendfsync always/everysec/no
no-appendfsync-on-rewrite no
# 当AOF体积大于64MB,且AOF文件体积比上一次重写后大了至少 100% 时,Redis执行BFREWRITEAOF命令。
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
dir ./ # 快照和AOF文件保存位置快照
某一时刻将所有数据写入硬盘
可通过客户端发送 BGSAVE SAVE 手动启动
在接收到 SHUTDOWN 命令或接收到 TERM 信号时执行一个 SAVE 命令,阻塞所有客户端不再执行任何命令,并在 SAVE 命令执行完成后关闭服务器
当一个redis-server向另一个redis-server发送 SYNC 命令后开始一次复制操作,如果不是正在执行BGSAVE 操作,则立即执行
只追加文件
执行命令时将写命令复制到硬盘,Redis在启动时将AOF文件读取并执行,会消耗时间。BGREWRITEAOF 通知移除AOF文件中冗余部分,解决AOF文件体积不断增大的问题。因为也创建一个子进程所以也会导致性能问题和内存占用问题。
复制(replication)
主从结构,master处理写请求,slave处理读请求。当从服务器连接主服务器的时候,主服务器会执行BGSAVE 操作。因此为了正确地使用复制特性,用户需要保证主服务器已经正确地设置了dir 选项和dbfilename 选项。
在slave配置文件中指定 slaveof host port 连接master,或对正在运行的redis执行 SLAVEOF host port 让其复制新主服务器;执行 SLAVEOF no one 可让slave终止复制操作。
复制启动过程
| 步骤 | master | slave |
| 1 | (等待) | 连接master,发送SYNC命令 |
| 2 | 开始执行BGSAVE,并使用缓冲区记录BGSAVE之后的命令 | 由配置项决定:使用现有数据回复client,还是返回错误 |
| 3 | BGSAVE执行完毕,向slave发送快照,并记录写命令到缓冲区 | 丢弃旧数据,加载快照 |
| 4 | 快照发送完毕,发送缓冲区记录的被执行写命令 | 加载快照文件,正常接收命令请求 |
| 5 | 缓冲区存储的写命令发送完毕;每执行一个写命令也向slave发送 | 接收master发来的写命令,并执行 |
Redis在复制时也尽可能处理命令请求。最好让master只使用50%~65%内存,剩余的用于执行BGSAVE命令和创建记录写命令缓冲区。
slave进行同步时会清空自己的所有数据,替换为master发来的数据。
多个slave连接同一个master时
| master接收到sync命令时的操作 | master的操作 |
| 步骤3未执行 | 所有slave收到相同快照和缓冲区写命令 |
| 步骤3正执行或执行完毕 | 与前一个slave完成5个步骤后再执行一次5个步骤 |
slave可以有slave,从而形成主从链。唯一的区别是子节点在执行步骤4时将断开与孙节点的连接,导致孙节点需要重新连接并重新同步。当读请求远大于写请求时同步大量slave会对master造成很大的性能影响。可以通过 (master/slave node) 中间层来分担主服务器的复制工作。
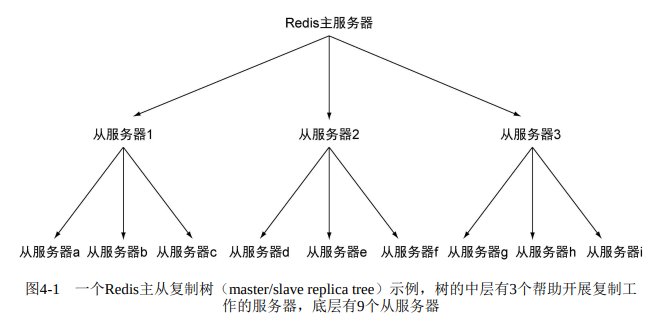
检验磁盘写入
通过向master写入一个唯一的虚构值,然后检验slave中是否存在以判断写数据是否到达slave。
判断是否保存到硬盘则难很多。检查 INFO 命令中 aof_pending_bio_fsync 属性值是否为0,如果是0则表示已知数据已保存在硬盘中。
检查是否同步
def wait_for_sync(mconn, sconn):
identifier = str(uuid.uuid4())
mconn.zadd('sync:wait', identifier, time.time()) # 将唯一的令牌添加至master
while not sconn.info()['master'] != 'up': # 如有必要,等待slave完成同步
time.sleep(.001)
while not sconn.zscore('sync:wait', identifier): # 等待从服务器接收数据更新
time.sleep(.001)
deadline = time.time() + 1.01 # 最多等待1秒
while time.time() < deadline:
if sconn.info()['aof_pending_bio_fsync'] == 0: # 检查数据是否已经更新到磁盘
break
time.sleep(.001)
mconn.zrem('sync:wait', identifier)
mconn.zremrangebyscore('sync:wait', 0, time.time()-900)通过同时使用复制和AOF持久化,用户可以增强Redis对于系统崩溃的抵抗能力。
故障处理
为了保证Redis数据完整性要多做一些工作
验证RDB和AOF
使用 redis-check-aof.exe [--fix|--truncate-to-timestamp $timestamp] <file.aof> 和 redis-check-rdb.exe <rdb-file-name> 两个工具。
aof 的 --fix 参数是当AOF文件出错时从错误命令开始进行删除,只保留正确命令。
快照文件无法修复,最好是保留多个备份,通过散列值进行验证。
更换故障主服务器
A为master,B为slave。A故障后B原地待命不会改变状态。使用新的机器C作为新的Redis master。
流程:先向B发送 SAVE 命令保存快照,然后发给C,在C上启动Redis,再让B成为C的slave。
或者将B变为master,C作为新的slave
流程:B使用 slaveof no one 变为master。启动c,然后使用 slaveof host port
注意:可能要相应的修改客户端代码,且可能要更新持久化配置
事务
多个事务同时处理一个对象通常用到二阶段提交。
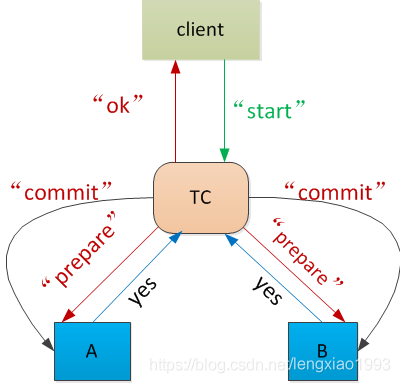
延迟执行事务有助于提升性能,很多客户端都在所有命令出现后将MULTI命令、事务中一系列命令、EXEC命令一起发送给Redis,然后等待接收回复。这称为流水线(pipelining)。
游戏商城应用
出售
用户信息的hash和用户包裹set:
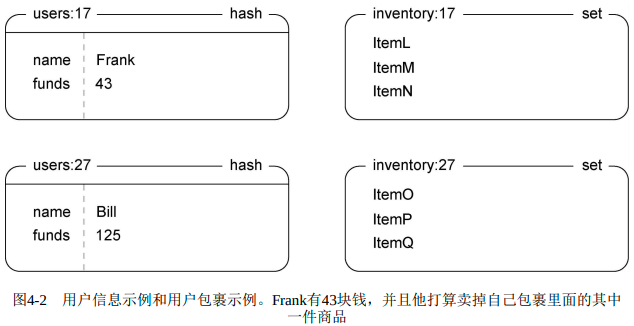
商品ID和卖家ID拼接起来放入ZSET,分值为价格。通过价格排序

WATCH
UNWATCH # 在 WATCH 和 MULTI 之间执行,对连接重置
DISCARD # 在 MULTI 和 EXEC 之间执行,对连接重置
MULTI
EXEC # 当被WATCH的key被写入后,执行EXEC时返回错误在使用WATCH监视多个键后使用MULTI开始一个新事务,并将多个命令入队到事务队列后,可通过DISCARD命令取消WATCH并清空入队的命令
出售到市场
def list_item(conn:redis.Redis, itemid, sellerid, price):
inventory = "inventory:{}".format(sellerid)
item = "{}.{}".format(itemid, sellerid)
end = time.time() + 5
pipe = conn.pipeline()
while time.time() < end:
try:
pipe.watch(inventory)
if not pipe.sismember(inventory, itemid): # 检查用户是否仍然持有将要出售的物品
pipe.unwatch()
return None
pipe.multi()
pipe.zadd("market:", {item: price})
pipe.srem(inventory, itemid)
pipe.execute()
return True
except redis.exceptions.WatchError: # 包裹发生了变化,重试
pass
return False购买
转移商品和钱
def purchase(conn:redis.Redis, buyerid, itemid, sellerid, prospective_price):
buyer = "users:%s"%buyerid
seller = "users:%s"%sellerid
item = "%s.%s"%(itemid, sellerid)
inventory = "inventory:%s"%buyerid
end = time.time() + 10
pipe = conn.pipeline()
while time.time() < end:
try:
pipe.watch("market:", buyer) # 监视市场和买家
# 检查商品价格是否发生变化,买家钱是否足够
price = int(str(pipe.zscore("market:", item)))
funds = int(str(pipe.hget(buyer, "funds")))
if price != prospective_price or price > funds:
pipe.unwatch()
return None
# 转移商品和钱
pipe.multi()
pipe.hincrby(seller, "funds", int(price))
pipe.hincrby(buyer, "funds", int(-price))
pipe.sadd(inventory, itemid)
pipe.zrem("market:", item)
pipe.execute()
return True
except redis.exceptions.WatchError:
pass
except Exception as e: # 还可能存在类型错误
print(e)
return False
return FalseRedis中基于watch的使用乐观锁,MySQL中使用悲观锁。
性能
- 使用流水线
在python中使用pipe = conn.pipeline()创建流水线时默认参数为True,客户端会使用MULTI和EXEC包裹起所有命令,如果传入False则可以在不使用事务的情况下使用流水线 - 使用连接池
python客户端默认使用连接池 - 使用正确的数据结构
降低使用内存
短结构
list、set、hash、zset有一些配置选项可以以更节约的方式存储较短的结构。在list、hash、zset较小时会使用压缩列表(ziplist)存储。ziplist以序列化方式存储数据,每次读取时要解码,写入时局部重新编码且可能移动内存数据。
ziplist

entries表示最大元素数量,value指每个节点最大体积。两个条件中任意一个被突破时会将其转换为相应的其他结构。当结构体积减小后不会再变为ziplist。
集合的整数集合编码
如果整数包含的所有成员都可以被解释为十进制整数,而这些整数又处于平台的有符号整数范围之内,并且集合成员的数量又足够少的话,那么Redis就会以有序整数数组的方式存储集合,这种存储方式又被称为整数集合 (intset)。

长压缩列表和大整数集合带来的性能问题
突破限制后,Redis将底层结构转为更典型的结构。因为随着紧凑结构的体积变得越来越大,操作这些结构的速度也会变得越来越慢。
建议ziplist长度1024之内,每个元素体积64字节之内。
此外,让键名保持简短。
分片结构
分片本质上就是基于某些简单的规则将数据划分为更小的部分,然后根据数据所属的部分来决定将数据发送到哪个位置上面。程序不再是将值X存储到键Y里面,而是将值X存储到键Y:<shardid> 里面。
对列表分片:应当使用Lua
对有序集合分片:range操作要在所有分片上进行,所以速度不快,作用不大。
分片式散列
选一个方法划分数据,可以把散列存储的键用作一个信息源,并用散列函数计算出一个数字散列值。
# 给出散列名字、存到分片散列的键、预计的元素总数、请求的分片数量
def shard_key(base, key, total_elements, shard_size):
if isinstance(key, (int, long)) or key.isdigit(): # 看上去是整数则直接分片
shard_id = int(str(key), 10) // shard_size # 使用二进制的高位
else:
shards = 2 * total_elements // shard_size # 计算分片总数量
shard_id = binascii.crc32(key) % shards # 获得分片id
return "%s:%s"%(base, shard_id) # 得到分片键
def shard_hset(conn, base, key, value, total_elements, shard_size):
shard = shard_key(base, key, total_elements, shard_size) #A
return conn.hset(shard, key, value) #B
def shard_hget(conn, base, key, total_elements, shard_size):
shard = shard_key(base, key, total_elements, shard_size) #C
return conn.hget(shard, key) #D分片集合
计算网站的唯一访客可使用一个基于set的访客计数器。对其实现分片。对每个用户生成唯一的UUID,将其前15个十六进制数转为十进制数存储,只要占用8字节内存。
def shard_sadd(conn, base, member, total_elements, shard_size):
# 使用之前的 shared_key ,因成员并非连续ID,所以先转为字符串再分片
shard = shard_key(base,
'x'+str(member), total_elements, shard_size) #A
return conn.sadd(shard, member) #B
SHARD_SIZE = 512 #B
def count_visit(conn, session_id):
# 通过当天日期生成唯一访客的键
today = date.today() #C
key = 'unique:%s'%today.isoformat()
# 获取或计算唯一访客
expected = get_expected(conn, key, today)
id = int(session_id.replace('-', '')[:15], 16)
# 如果访客不存在则加1
if shard_sadd(conn, key, id, expected, SHARD_SIZE):
conn.incr(key)
DAILY_EXPECTED = 1000000 #I
EXPECTED = {} # 本地存储一份副本
# 计算每天预计的访问客人数。Web页面的访客数量总是会随着时间发生变化,而每天都维持相同分片数量的做法将无法适应访客人数增多的情况,也无法在访客数量少于100万人次的时候缩减分片的数量。
def get_expected(conn, key, today):
# 已存在则直接获取
if key in EXPECTED: #B
return EXPECTED[key] #B
# 其他客户端已算出则直接获取
exkey = key + ':expected'
expected = conn.get(exkey) #C
if not expected:
# 获取昨天唯一访客数,不存在则用默认值
yesterday = (today - timedelta(days=1)).isoformat() #D
expected = conn.get('unique:%s'%yesterday) #D
expected = int(expected or DAILY_EXPECTED) #D
# 预计明天访客人数比今天多50%
expected = 2**int(math.ceil(math.log(expected*1.5, 2)))
# 写入redis,供其他程序使用
if not conn.setnx(exkey, expected):
# 如果已存在,使用已有的
expected = conn.get(exkey) #G
EXPECTED[key] = int(expected) #H
return EXPECTED[key] #H

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步