Spark高级
Spark
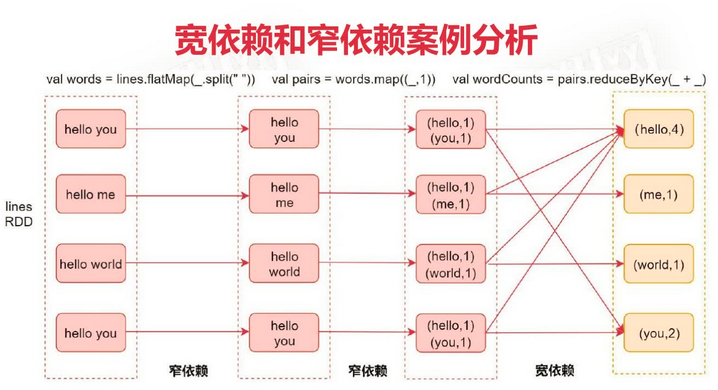
宽依赖和窄依赖
- 窄依赖(Narrow Dependency): 指父RDD的每个分区只被 子RDD的一个分区所使用, 例如map、 filter等
- 宽依赖(Shuffle Dependency): 父RDD的每个分区都可能被 子RDD的多个分区使用, 例如groupByKey、 reduceByKey。产生 shuffle 操作。
Stage
每当遇到一个action算子时启动一个 Spark Job
Spark Job会被划分为多个Stage,每一个Stage是由一组并行的Task组成的,使用 TaskSet 进行封装
Stage的划分依据就是看是否产生了Shuflle(即宽依赖),遇到一个Shuffle操作就会被划分为前后两个Stage
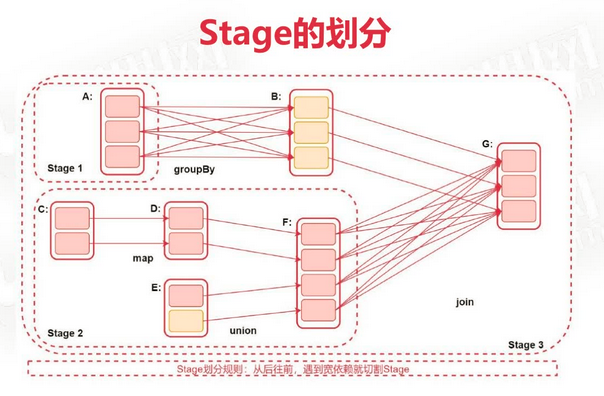
图中 ABCDEFG 都是 RDD,中间通过算子进行关联。Stage划分规则:从后向前,遇到宽依赖就切割Stage。Stage3依赖于Stage1和Stage2。
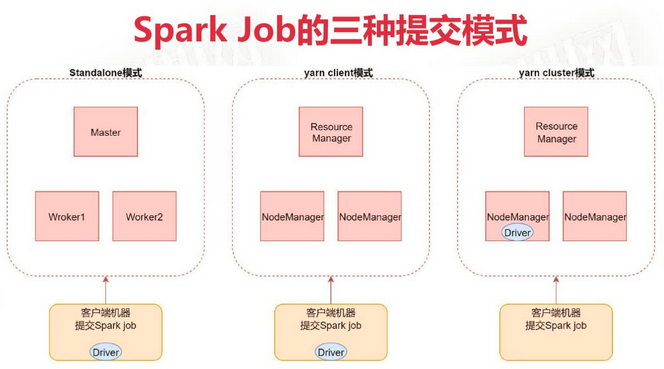
Spark Job的三种提交模式
- standalone模式
spark-submit --master spark://ubuntu-02:7077 - yarn client模式
spark-submit --master yarn --deploy-mode client
主要用于开发测试,日志会直接打印到控制台上。Driver任务只运行在提交任务的本地Spark节点,Driver调用job并与yarn集群产生大量通信,这种通信效率不高,影响效率。 - yarn cluster模式(推荐)
spark-submit --msater yarn --deploy-mode cluster
Driver 进程会运行在集群的某台机器上,日志查看需要访问集群web控制界面。
Shuffle
产生shuffle的情况:reduceByKey,groupByKey,sortByKey,countByKey,join 等操作
Spark shuffle 一共经历了这几个过程:
- 未优化的 Hash Based Shuflle
- 优化后的 Hash Based Shuffle
- Sort-Based Shuffle
https://zhuanlan.zhihu.com/p/67061627
未优化的 Hash Based Shuflle
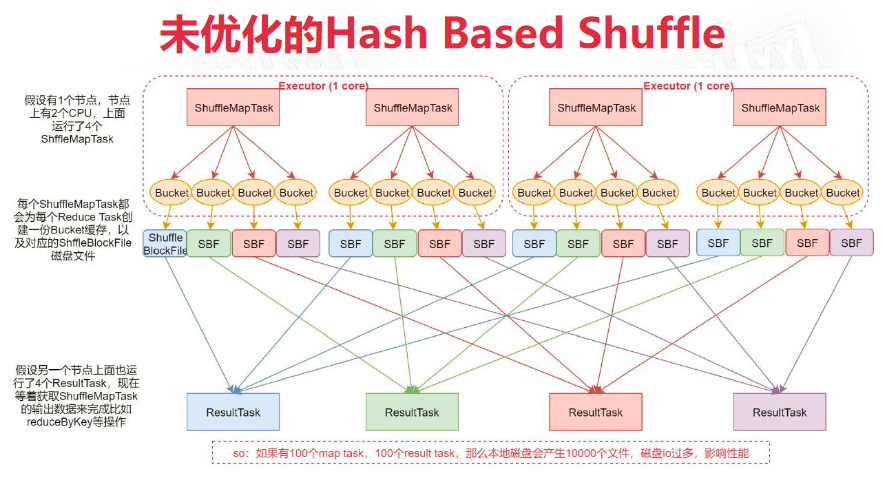
每个 MapTask 针对每一个 ResultTask 生成一个 Bucket 缓存,Bucket缓存的个数 = MapTask个数 * ResultTask个数。这样会产生频繁的磁盘IO。ShuffleMapTask会将所有数据写入Bucket缓存后再写入磁盘文件,如果MapTask数据过多会导致Bucket数据溢出。此处Bucket大小可以根据业务场景进行优化。
- 生成大量文件,消耗文件描述符和内存
- Reduce Task 合并时使用HashMap,可能造成OOM
优化后的 Hash Based Shuffle
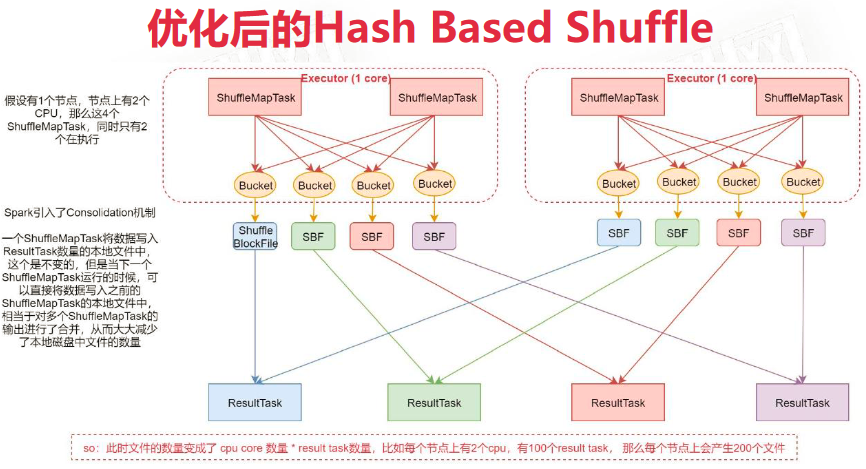
Bucket个数 = cpu核心数 * ResultTask个数。这样大大减小了IO操作次数。但仍有可能造成下游Reduce Task的OOM
Sort-Based Shuffle
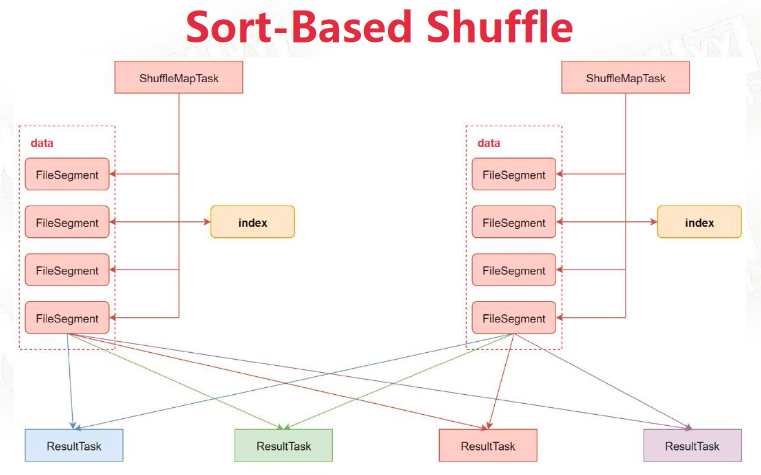
针对每个ShuffleMapTask都只创建一个文件,可以将数据写入磁盘。文件内部按照 Partition Id 排序,内部再按照 Key 进行排序。上游Task在运行期间会顺序写入不同分区的数据,并生成索引文件记录每个分区的大小和偏移。下游Task拉去并合并数据时不再采用 HashMap 而是采用 ExternalAppendOnlyMap,该数据结构在内存不足时会写磁盘,避免了OOM
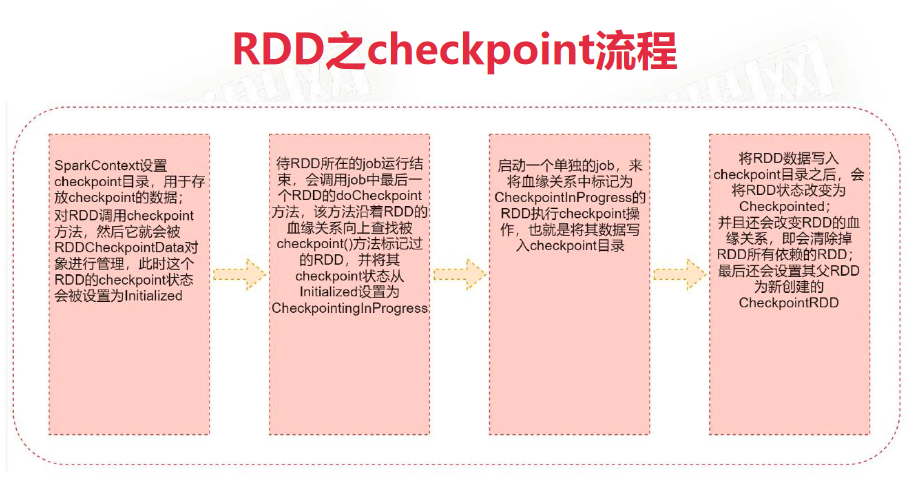
checkpoint
针对Spark Job,如果我们担心某些关键的,在后面会反复使用的RDD,因为节点故障导致数据丢失,那么可以针对该RDD启动checkpoint机制,实现容错和高可用
首先调用SparkContext的setCheckpointDir()方法,设置一个容错的文件系统目录(HDFS),然后对RDD调用checkpoint()方法。在RDD所属job结束后启动一个新的job,将checkpoint设置过的那个RDD数据写入我们之前设置的文件系统中。
checkpoint 与持久化区别
- lineage(血缘关系)是否发生改变,即RDD的依赖关系
持久化只是将数据写入磁盘,不改变RDD依赖关系;执行checkpoint后就不再有依赖的RDD - 丢失数据的可能性
持久化任然可能丢失数据,毕竟磁盘可能损坏;checkpoint通常将数据保存在高可用的文件系统。
建议:对需要checkpoint的RDD,先执行persist(StorageLevel.DISK_ONLY)。如果某个RDD设置了checkpoint却没有持久化,当Spark任务已经执行结束却由于中间的RDD没有持久化,checkpoint期间为了将这个RDD的数据写入外部存储系统,需要重新计算RDD的数据。如果进行了基于磁盘或内存的持久化,checkpoint操作时会直接从存储上读取RDD的数据,无需重新计算。
使用方法
CheckpointOpScala
package org.example
import org.apache.spark.{SparkConf, SparkContext}
object CheckpointOpScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("CheckpointOpScala").setMaster("local")
val sc = new SparkContext(conf)
// 1. 设置checkpoint目录,建议使用hdfs
sc.setCheckpointDir("hdfs://ubuntu:9000/checkpointDir")
val dataRDD = sc.textFile("hdfs://ubuntu:9000/file.txt")
.persist(StorageLevel.DISK_ONLY)
// 2. 对RDD调用checkpoint操作。在此之前先执行持久化可以大大减少时间消耗
dataRDD.checkpoint()
dataRDD.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.saveAsTextFile("hdfs://ubuntu:9000/output.txt")
sc.stop()
}
}CheckpointOpJava
package org.example;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class CheckpointOpJava {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("AccumulatorOpJava").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
// 1. 设置checkpoint目录,建议使用hdfs
sc.setCheckpointDir("hdfs://ubuntu:9000/checkpointDir");
JavaRDD<String> dataRDD = sc.textFile("hdfs://ubuntu:9000/file.txt");
// 2. 对RDD调用checkpoint操作
dataRDD.checkpoint();
dataRDD.flatMap(s -> Arrays.asList(s.split(" ")).iterator())
.mapToPair(s -> new Tuple2<String, Integer>(s, 1))
.reduceByKey(Integer::sum)
.saveAsTextFile("c://local/path");
sc.stop();
}
}Spark 性能优化
spark的运算主要在内存中进行,一般情况下性能瓶颈出现在内存上。将数据加载到内存中,对象结构本身也要占用空间,所以数据在内存中占用的资源大于其本身的大小。使用持久化操作cache()可看到对象在内存中占用的真实空间大小。
优化方法:
- 高性能java序列化库 Kryo
初始化是在Driver进行,实际工作在Worker的Executor进程进行,这之间需要网络传输。spark默认提供java默认序列化和kryo两种方式,kyro更快更节省空间,但是需要对要序列化的类预先进行注册,否则kryo保存类型的全名反而占用更多内存。spark默认在kryo注册scala常用类,其他的要手动注册
val conf = new SparkConf() // 开启kyro序列化 .set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") // 设置 kyro 的buffer .set("spark.kryoserializer.buffer.mb", "2") // 注册类到其中,注册时会默认开启 kyro .registerKryoClasses(Array(classOf[SparkContext])) - 持久化或checkpoint
对多次被transformation或action操作的RDD进行持久化,避免对一个RDD反复计算。开启checkpoint保证高可用 - JVM垃圾回收调优
- 提高并行度
可通过 testFile() parallelize() 等方法的第二个参数设置并行度,也可通过 spark.default.parallelism 设置同一并行度,建议每个cpu核2~3个task - 数据本地化
如果不能实现高等级本地化,等待空闲cpu,一段时间后仍未能得到运行几乎,降低对本地化的要求选择其他节点,等待时间可设置![]()
- 算子优化

算子优化
map vs mapPartitions & foreach vs foreachPartition
map, Transformation 算子,一次处理一条数据,运行时不断GC已处理过的数据,不会造成OOM
mapPartition, Transformation 算子,一次处理一个分区的数据,一旦元素很多而内存不足会造成OOM,适用于初始化或数据库连接,数据库链接初始化如果在Driver完成,算子在执行时是无法获得的
foreach,一次处理一条 Transformation 算子
foreachPartition,一次处理一分区 Action 算子
rdd.foreachPartition(it => {
// 获取数据库连接
it.foreach(item => {
// 使用数据库连接
})
// 关闭数据库连接
})repartition
用于RDD的重分区,会产生shuffle操作
- 调整RDD并行度
- 解决RDD数据倾斜问题
- 控制输出数据产生的文件个数
rdd.repartition(3).foreachPartition(i => {
println("====") // 循环输出3次
})
rdd.saveAsTextFile("hdfs://xxx") // 在路径下生成3个文件
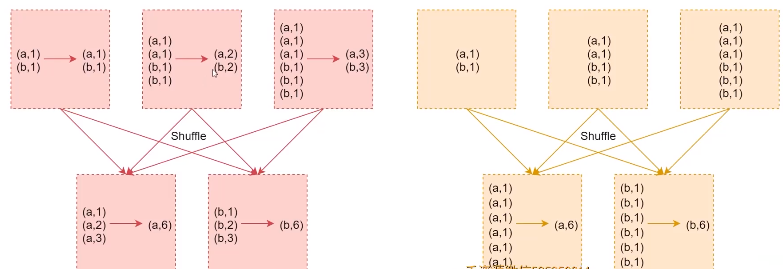
rdd.repartition(1).saveAsTextFile("hdfs://...") // 只生成一个文件reduceByKey & groupByKey
reduceByKey:shuffle前对数据进行聚合,大大减少要传输到reduce端的数据量,减少网络传输开销,优先使用
Spark SQL
Spark的一个模块,用于结构化数据处理,最核心的抽象模型就是DataFrame。DataFrame=RDD+Schema,和关系型数据库的表很类似,可通过多来源进行构建。使用Spark SQL时要先创建一个SparkSession对象,其包括SparkContext和SqlContext两部分,SqlContext用于通过Spark操作Hive。Spark2.0开始DataFrame和DataSet是一样的。
开发时要添加依赖
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.13</artifactId>
<version>3.3.2</version>
<scope>provided</scope>
</dependency>DataFrame常见算子操作
https://spark.apache.org/docs/latest/sql-getting-started.html#untyped-dataset-operations-aka-dataframe-operations
package org.example.bigdata.scala
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object SqlDemoScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local")
val session = SparkSession.builder()
.appName("SqlSessionDemo")
.config(conf)
.getOrCreate()
// 从json获取DataFrame
val dataFrame = session.read.json("hdfs://xxx/xx.json")
// 展示数据
dataFrame.select("name").show()
import session.implicits._ // 隐式转换
dataFrame.select($"name", $"age"+1).show()
dataFrame.filter($"age" > 20).show()
dataFrame.groupBy("age").count().show()
session.stop()
}
}DataFrame 的sql操作
- 将DataFrame注册为一个临时表
- 使用sparkSession中sql函数执行sql语句
object SqlDemoScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local")
val session = SparkSession.builder().appName("SqlSessionDemo").config(conf).getOrCreate()
val dataFrame = session.read.json("hdfs://xxx/xx.json")
// 创建新一张抽象表,用于进行sql操作
dataFrame.createOrReplaceTempView("student")
session.sql("select age, count(*) as num from student group by age").show()
session.stop()
}
}RDD 转换为 DataFrame
- 反射方式
适合写代码时已知具体属性,Spark SQL 的Scala接口自动隐式地将 case class 的RDD转换为DataFrame
object SqlDemoScala { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local") val session = SparkSession.builder().appName("SqlSessionDemo").config(conf).getOrCreate() val sc = session.sparkContext val dataRDD = sc.parallelize(Array(("aaa", 1), ("bbb", 2), ("ccc", 3))) import session.implicits._ // RDD 到 DataFrame 的转换 val dataFrame = dataRDD.map(tup => Student(tup._1, tup._2)).toDF() // 此处的转换方法需要导入隐式转换包 // 基于dataFrame创建一个表,然后就可以写sql了 dataFrame.createOrReplaceTempView("student") val resDF = session.sql("select name, age from student where age > 18") // DataFrame 转 RDD val resRDD = resDF.rdd resRDD.map(row => Student(row(0).toString, row(1).toString.toInt)) .collect().foreach(println) session.stop() } } - 编程方式
object SqlDemoScala { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local") val session = SparkSession.builder().appName("SqlSessionDemo").config(conf).getOrCreate() val sc = session.sparkContext val dataRDD = sc.parallelize(Array(("aaa", 18), ("bbb", 20), ("ccc", 30))) // 组装 rowRDD val rowRDD = dataRDD.map(tup => Row(tup._1, tup._2)) // 指定元数据 val schema = StructType(Array( StructField("name", StringType, true), StructField("age", IntegerType, true), )) // 组装DataFrame val dataFrame = session.createDataFrame(rowRDD, schema) dataFrame.createOrReplaceTempView("student") val resDF = session.sql("xxx") val rdd = resDF.rdd session.stop() } }
load & save
DataFrame 存储到文件,从文件加载。不指定format时,默认使用parquet格式读写,默认支持json jdbc csv等多种格式。
object SqlDemoScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local")
val session = SparkSession.builder().appName("SqlSessionDemo").config(conf).getOrCreate()
val sc = session.sparkContext
val stuDF = session.read.format("json").load("xxx.json")
stuDF.select("name", "age")
.write
.format("csv")
.mode(SaveMode.Append) // 追加,指定SaveMode
.save("hdfs://xxx/xxx.csv")
session.stop()
}
}SaveMode
目标位置已经有数据时如何处理。

TopN 主播案例
使用SQL实现 https://www.cnblogs.com/zhh567/p/16364732.html 中TopN主播问题
- 使用sparksession加载json数据
- 对这两份数据注册临时表
- 执行sql
- 打印
package org.example.bigdata.scala
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object TopN {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
.setMaster("local")
val sparkSession = SparkSession.builder().appName("TopN").config(sparkConf).getOrCreate()
val giftDF = sparkSession.read.json("D:\\tmp\\gift.json")
val videoDF = sparkSession.read.json("D:\\tmp\\video.json")
giftDF.createOrReplaceTempView("gift")
videoDF.createOrReplaceTempView("video")
val sql = """select
| t4.area,
| concat+_ws(',', collect_list(t4.topn)) as topn_list
|from (
| select
| t3.area, concat(t3.uid,':',cast(t3.gold_sum_all as int) ) as topn
| from (
| select
| t2.uid, t2.area, t2.gold_sum_all, row_numer() over (partition by area order by gold_sum_all desc) as num
| from (
| select
| t1.uid, max(t1.area) as area, sum(t1.gold_sum) as gold_sum_all
| from (
| select
| v.uid, v.area, g.gold_sum
| from
| video as v
| join (
| select
| g.vid, sum(g.gold) as gold_sum
| from
| gift as g
| group by
| g.vid
| )
| on
| v.vid = g.vid
| ) as t1
| group by t1.uid
| ) as t2
| ) as t3
| where
| t3.num <= 3
|) as t4
|group by t4.area""".stripMargin
val resDF = sparkSession.sql(sql)
resDF.foreach(println)
sparkSession.stop()
}
}
 浙公网安备 33010602011771号
浙公网安备 33010602011771号