
c++STL
容器
课程中使用了 gcc 2.9,旧版本中继承关系更少,代码更简洁。更容易阅读,且原理相同
-
容器 Containers
序列容器 Sequence Containers
Array
Vector 尾端可扩充的数组
Deque 双端可扩充的数组
List 双向队列
Forward-List 单向队列关联容器 Associative Containers 通过红黑树实现的有序容器
Set key不可重复
Multiset key可重复
Map
Multimap无序容器 Unordered Containers 哈希表实现的容器,使用拉链法
Unordered Set Multiset
Unordered Map Multimap -
分配器 Allocators
-
算法 Algorithms
-
迭代器 Iterators
-
适配器 Adapters
-
仿函数 Functors
int ia[6] = {1,2,3,4,5,6};
vector<int, allocator<int>> vi(ia, ia+6); // vector的第二个参数是空间分配器
count << count_if(vi.begin(), vi.end(),
not1(bind2nd(less<int>(), 40)));//统计大于等于40的个数
STL中使用“左闭后开”表示数据范围。c.begin()表示第一个元素,c.end()表示最后一个元素后面的位置。
Container<T>::iterator c;
for (auto c = vec.begin; c != vec.end(); ++c);
for (auto& c : vec);
分配器
每个容器有个默认分配器,可以在尖括号内指定。分配器底层还是调用了malloc
// vector 的定义,可见模板参数中有指定内存分配器的参数,且此参数有默认值
template <typename _Tp, typename _Alloc=std::allocator<_Tp>>
class vector : protected _Vector_base<_Tp, _Alloc>
gcc 下的拓展分配器,不同编译器下不同。
#ifdef __GNUC__
#include <ext\array_allocator.h>
#include <ext\mt_allocator.h>
#include <ext\debug_allocator.h>
#include <ext\pool_allocator.h>
#include <ext\bitmap_allocator.h>
#include <ext\malloc_allocator.h>
#include <ext\new_allocator.h>
#endif
void fun() {
// 其定义在非std命名空间
list<string, __gnu_cxx::malloc_allocator<string>> c2; //3110
list<string, __gnu_cxx::new_allocator<string>> c3; //3156
list<string, __gnu_cxx::__pool_alloc<string>> c4; //4922
list<string, __gnu_cxx::__mt_alloc<string>> c5; //3297
list<string, __gnu_cxx::bitmap_allocator<string>> c6; //4781
// 分配器也是一个类,可以直接使用。其只有allocate和deallocate两个方法。一般没必要使用,而是使用new delete malloc free
int* p;
allocator<int> alloc1;
p = alloc1.allocate(1);
alloc1.deallocate(p,1);
__gnu_cxx::malloc_allocator<int> alloc2;
p = alloc2.allocate(1);
alloc2.deallocate(p,1);
__gnu_cxx::new_allocator<int> alloc3;
p = alloc3.allocate(1);
alloc3.deallocate(p,1);
__gnu_cxx::__pool_alloc<int> alloc4;
p = alloc4.allocate(2); // 分配两个int大小的空间
alloc4.deallocate(p,2); // 释放两个int大小的空间,释放空间时与free delete不同,需要指定大小
__gnu_cxx::__mt_alloc<int> alloc5;
p = alloc5.allocate(1);
alloc5.deallocate(p,1);
__gnu_cxx::bitmap_allocator<int> alloc6;
p = alloc6.allocate(3);
alloc6.deallocate(p,3);
}
OOP 面向对象编程 与 GP 泛型编程
OOP将data与methods包装在一起,GP则是将二者分开。
OOP
所有工作都由类开发者完成
class Class<typename T> {
...
T min(const T& a, const T& b) {
return a < b ? a : b;
}
}
GP
容器团队与算法团队可以分工合作
class Class<typename T> {}
template<typename _Tp>
const _Tp& min(const _Tp& __a, const _Tp& __b) {}
list 的 sort 方法
一般容器在排序时都使用全局排序方法 ::sort() ,而双向队列 list 的排序方法在自己内部定义。
全局排序方法中需要对指针或泛化指针进行加减乘除等操作,这就要求是随机指针,而list是双向链表。
以下都是 gcc2.9 版本的源代码
lists
在尾端多添加了一个空白节点,以实现“左闭右开”区间。底层是一个循环双向链表。
template<typename _Tp, typename _Alloc = alloc >
class list {
protected:
typedef __list_node<T> list_node; // node节点
public:
typedef list_node* link_type;
typedef __list_iterator<T, T&, T*> iterator; // 迭代器本质上是一个指针
protected:
link_type node; // 指向节点的指针,2.9版本占4字节
// 4.9版本占8字节,因为其父类拥有一个链表节点__List_node_base,其包含了两个指针
// ...
};
template <class T>
struct __list_node {
typedef void* void_pointer;
void_pointer prev; // 指向前后的指针,没增加一个元素都会多占用的空间
void_pointer next; // 在4.9中不再使用void*
T data;
};
template<class T, class Ref, class Ptr> // 新版中只传入一个参数 T
struct __list_iterator { // 类似指针的类
typedef __list_iterator<T, Ref, Ptr> self;
typedef __list_node<T>* link_type;
/*每个容器的 iterator 都一定要有以下5个 typedef*/
typedef bidirectional_iterator_tag iterator_category; // 迭代器的种类:只能向前/可以后退/每次只能加1/每次可以增加大于1的值
typedef T value_type;
typedef Ptr pointer;
typedef Ref reference;
typedef ptrdiff_t difference_type; // 表示两个元素的距离的变量类型 unsigned int/
link_type node;
// ...
reference operator*() const {
return (*node).data;
}
pointer operator->() const {
return &(operator*());
}
self& operator++() { // ++i
node = (link_type) ((*node).next);
return *this;
}
self operator++(int) { // i++
// 此处调用copy ctor用于创建tmp,并以*this为初值,不会唤起operator*操作符
// 因为*this已被解释为ctor的参数
self tmp = *this;
++*this; // 使用到了已重载的 operator++()
return tmp;
}
__list_iterator(const iterator& x) : node(x.node) {}
// ...
};
vector
|+++++++++++++++++++++++++++|----------------|
start finish end_of_storage
<-----------size------------>
<------------------capacity------------------>
当空间使用完时申请一个2倍大小的空间,然后将旧数据复制过去
template <class T, class Alloc = alloc>
class vector {
public:
typedef T value_type;
typedef value_type* iterator_pointer; // 直接将 native pointer 当作迭代器
typedef value_type& iterator_reference;
typedef size_t size_type;
protected:
// 容器vector的大小就是这三个指针的大小,为12或24
iterator start;
iterator finish;
iterator end_of_storage;
public:
iterator begin() { return start; }
iterator end() {return finish; }
size_type size() const {
return size_type(end() - begin());
}
size_type capacity() const {
return size_type(end_of_storage - begin());
}
bool empty() const { return begin() == end(); }
reference operator[](size_type n) { return *(begin() + n); }
reference front() { return *begin(); }
reference back() { return *(end() - 1); }
void push_back(const T& x) {
if (finish != end_of_storage) {
// 当空间充足时向 finish 位置加入元素
construct(finish, x);
++finish;
}
else
// 空间不足时申请双倍空间在添入元素
insert_aux(end(), x);
}
template <class T, class Alloc>
void vector<T, Alloc>::insert_aux(iterator position, const T& x) {
if (finish != end_of_storage) {
// 与vector中操作类似,因为这个方法不仅仅被某一个容器调用
construct(finish, x);
++finish;
T x_copy = x;
copy_backward(position, finish - 2, finish - 1);
*position = x_copy;
}
else {
const size_type old_size = size();
const size_type len = old_size != 0 ? 2 * old_size : 1;
iterator new_start = data_allocator::allocate(len);
iterator new_finish = new_start;
// 复制元素,期间涉及每个元素的拷贝构造函数与析构函数,空间的销毁
try {
} catch () {
}
destory(begin(), end());
deallocate();
start = new_start;
finish = new_finish;
end_of_storage = new_start + len;
}
}
void
push_back(const value_type& __x)
{
if (this->_M_impl._M_finish != this->_M_impl._M_end_of_storage)
{
_GLIBCXX_ASAN_ANNOTATE_GROW(1);
_Alloc_traits::construct(this->_M_impl, this->_M_impl._M_finish, __x);
++this->_M_impl._M_finish;
_GLIBCXX_ASAN_ANNOTATE_GREW(1);
}
else
_M_realloc_insert(end(), __x);
}
};
array
将一个数组包装成类,然后它就遵循一定的规则,需要提供迭代器、特殊成员变量等,也可以适应算法库。
template <typename _Tp, std::size_t _Nm>
struct array {
typedef _Tp value_type;
typedef _Tp* pointer;
typedef value_type* iterator;
value_type _M_instance[_Nm ? _Nm : 1];//没有 ctor dtor
iterator begin() { return iterator(&_M_instance[0]); }
iterator end() { return iterator(&_M_instance[_Nm]); }
};
forward_list
线性单项链表
deque
使用了分段存储的思想,一个大数组元素是各个子数组,也称buffer。具体数据存储在buffer中。
每次扩充时新建一个buffer并插入到父数组中,当父数组空间不足时父数组也扩容。
子数组大小不变,扩容阔的是父数组,父数组为vector。
每次扩容时将旧数据复制到数组的中段,为的是左右端都有相同空间。
|------|------|------|------| | | => 增长方向
| | | |1|2|3|4|5|6|7|8|9| |
| | |1|2|3|4|5|6|7|8|9|10| |
| |1|2|3|4|5|6|7|8|9|10| finish[end()返回的尾指针]指向此处
| | | |4|5|6|7|8|9|10|
|
start[begin()返回的头指针]指向此处
iterator包含4个元素
cur 指向当前元素
first 指向当前buffer中第一个元素
last 指向当前buffer中最后一个元素
node 指向父数组中的当前节点
template <class T, class Alloc = alloc, size_t BufSiz = 0>//旧版本可以指定buffer大小,新版不可以
class deque {
public:
typedef T value_type;
typedef __deque_iterator<T> iterator;
protected:
typedef prointer* map_pointer; // T**
iterator start;
iterator finish;
map_pointer map;
size_type map_size;
public:
iterator begin() {return start;}
iterator end() {return finish;}
size_type size const {return finish - start;}
iterator insert(iterator position, const value_type& x) {
if (position.cur == start.cur) {//插到最前端交给 push_front 做
push_front(x);
return start;
} else if (position.cur == finish.cur) {//插到最后段交给 push_back 做
push_back(x);
iterator tmp = finish;
--tmp;
return tmp;
} else {
return insert_aux(position, x);
}
}
template <class T, class Alloc, size_t BufSize>
typename deque<T, Alloc, BufSize>::iterator
deque<T, Alloc, BufSize>::insert_aux(iterator pos, const value_type& x) {
differenct_type index = pos - start; // 安插点之前的元素个数
value_type x_copy = x;
if (index < size() / 2) { // 如果安插点之前的元素较少
push_front(front()); // 在最前端加入与第一个元素相同的元素
// ...
copy(front2, pos1, font1); // 元素搬移
} else { // 如果安插点之后的元素较少
push_back(back()); // 在最后端加入与最后一个元素相同的元素
// ...
copy_backward(pos, back2, back1); // 元素搬移
}
*pos = x_copy; // 安插点设置新值
return pos;
}
/****************** 如何模拟连续空间? 依靠迭代器,对操作符进行了重载 **********************/
reference operator[](size_type n) {
return start[difference_type(n)];
}
reference front() { return *start; }
reference back() {
iterator tmp = finish;
--tmp;
return *tmp;
}
size_type size() const { return finish - start; }
bool empty() const { return finish == start; }
// ...
};
template <class T>
struct __deque_iterator {
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef T* pointer;
typedef T& reference;
typedef ptrdiff_t difference_type;
typedef size_t size_type;
typedef T** map_potinter;
typedef __deque_iterator self;
// 迭代器大小为 16 或 32
T* cur;
T* first;
T* last;
map_pointer node;
reference operator*() const {
return *cur;
}
pointer operator->() const {
return &(operator*());
}
difference_type
operator-(const self& x) const {
return difference_type(buffer_size()) * (node - x.node - 1) +//buffer_size函数用于获取buffer大小
(cur - first) + (x.last - x.cur);
// 当前buffer的元素量 被减数buffer元素量
}
self& operator++() {
++cur;
if (cur == last) {
set_node(node + 1);
cur = first;
}
return *this;
}
self operator++() {
self tmp = *this;
++*this;
return tmp;
}
// 切换到父数组中下一个元素
void set_node(map_pointer new_node) {
node = new_node;
first = *new_node;
last = first + difference_type(buffer_size());
}
self& operator--() {
if (cur == first) {
set_node(node - 1);
cur = last;
}
--cur;
return *this;
}
self operator--(int) {
self tmp = *this;
--*this;
return tmp;
}
self& operator+=(difference_type n) {
difference_type offset = n + (cur - first);
if (offset >= 0 && offset < difference_type(buffer_size())) {
cur += n;
} else {
difference_type node_offset =
offset > 0 ?
offset / difference_type(buffer_size())
: -differnece_type((-offset - 1) / buffer_size() - 1);
set_node(node + node_offset);
cur = first + (offset - node_offset * difference_type(buffer_size()));
}
return *this;
}
self operator+(difference_type n) const {
self tmp = *this;
return tmp += n;
}
// ...
};
queue stack
内部包含一个deque,用自己的队列 / 栈方法封装对deque的操作。
都不允许遍历,也不提供 iterator。
都可以选择使用list作为底层结构。
queue不可选择vector当作底层结构,stack可选择vector当底层结构。
Iterator 的设计原则
迭代器作为算法与容器间的桥梁。
template<typename _Tp>
struct _List_iterator {
/**
* 每个容器的 iterator 都一定要有以下5个 typedef
*/
// 迭代器的种类:只能向前/可以后退/每次只能加1/每次可以增加大于1的值
// bidirectional_iterator_tag 代表可以双向迭代
typedef bidirectional_iterator_tag iterator_category;
typedef T value_type;
typedef T* pointer;
typedef T& reference;
typedef ptrdiff_t difference_type; // 表示两个元素的距离的变量类型 unsigned int 等
};
template<typename I>
inline void
algorithm(I first, I last) {
// 在算法中会直接使用以上的5中自定义类型
I::iterator_category;
I::pointer;
I::reference;
I::value_type;
I::difference_type;
}
iterator traits 迭代器萃取机
/*
算法库不仅可以作用于 class pointer(泛化的指针) 还可以作用于 native pointer(退化的迭代器)
使用 iterator traits 进行分辨:这个traits必须有能力分辨 iterator 是 class iterator T 还是 native pointer to T
利用 partial specialization 可以达到目标
*/
template <class T>
struct iterator_traits { // I 为 class iterator
typedef typename I::iterator_category iterator_category;
typedef typename I::value_type value_type;
typedef typename I::difference_type difference_type;
typedef typename I::pointer pointer;
typedef typename I::reference reference;
};
// 利用 partial specialization
template <class T>
struct iterator_traits<T*> { // I 为 pointer to T
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef T* pointer;
typedef T& reference;
};
template <class T>
struct iterator_traits<const T*> { // I 为 pointer to const T
typedef random_access_iterator_tag iterator_category;
typedef T value_type;// 注意不是 const T,这里加上const后无法初始化赋值
typedef ptrdiff_t difference_type;
typedef T* pointer;
typedef T& reference;
};
template<typename I, ...>
void algorithm(...) {
// 算法获取I的value type时可使用这种方法
typename iterator_traits<I>::value_type v1;
}
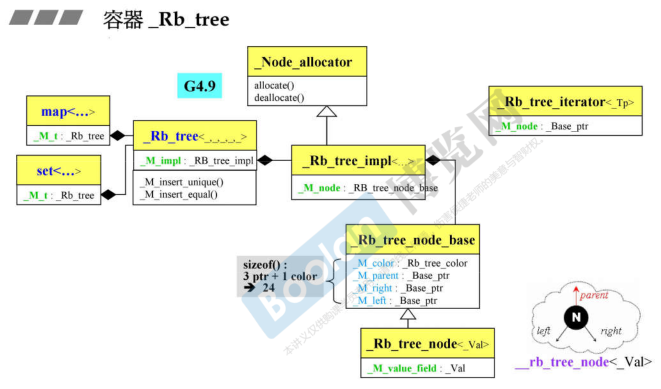
RB_tree 红黑树
C++中rb-tree 可以使用迭代器改变元素的值,但不应用其改变key的值,使用场景是在map结构中改变value的值。rb-tree提供两种insert操作:1. insert_unique() key不可以重复 2. insert_equal() key可以重复
begin() 返回指向最左下角的元素的迭代器,end() 返回指向最右下角的元素的迭代器。在root节点之前有一个header指针指向的一个哑节点,这个节点还指向 begin() end()
template <class Key,
class Value, // 键值对合并后的数据
class KeyOfValue, // 如何从键值对中拿到key
class Compare,
class Alloc=alloc>
class rb_tree {
protected:
typedef __rb_tree_node<Value> rb_tree_node;
...
public:
typedef rb_tree_node* link_type;
...
protected:
size_type node_count; // rb_tree的大小 节点个数
link_type header;
Compare key_compare; // 模板参数,一个 function object
...
};
// 使用方法
rb_tree<int,
int, // 意味着只有键没有值
identity<int>, // 这个identity是gcc独有的
less<int>,
alloc> myTree;
template<class T>
struct identity : public unary_function<T, T> {
const T& operator() (const T& x) const {
return x;
}
};
template<class T>
struct less : public binary_function<T, T, bool> {
bool operator() (const T& x, const T& y) const {
return x < y;
}
};
set multiset
无法使用迭代器改变元素值,set multiset的迭代器底部就是RBtree的 const iterator,就是禁止对元素赋值。
set使用 insert_uniqui(); multiset 使用 inert_equal()
set map 都是一种 container adapter。
template <class Key,
class Compare = less<Key>,
class Alloc = alloc>
class set {
public:
typedef Key key_type;
typedef Key value_type;
typedef Compare key_compare;
typedef Compare value_compare;
private:
typedef rb_tree<key_type, value_type,
identity<value_type>, key_compare, Alloc> rep_type;
rep_type t; // 具体工作都调用rbtree实现
public:
typedef typename rep_type::const_iterator iterator; // 此处迭代器不允许改变
// ...
};
// 使用方法
set<int> iset;
// 等于
set<int, less<int>, alloc> iset;
// 底层使用
template<int, int, identity<int>, less<int>, alloc>
class rb_tree;
map multimap
与set类似,value包括key加data。
template <class Key, class T,
class Compare = less<Key>, class Alloc=alloc>
class map {
public:
typedef Key key_type;
typedef T data_type;
typedef T mapped_type;
typedef pair<const Key, T> value_type;// const Key 保证了key不可以改变
typedef Compare key_compare;
private:
typedef rb_tree<key_type, value_type,
select1st<value_type>, // select1st与identify类似都是gcc独有的
key_compare, Alloc> rep_type;
rep_type t;
public:
typedef typename rep_type::iterator iterator;//map的迭代器就是红黑树的迭代器
// 通过key取得data,如果key不存在则使用默认值创建键值对
mapped_type& operator[] (const key_type& k) {
// 二分查找获取位置,不存在时返回应该处于的位置
iterator i = lower_bound(k);
if (i == end() || key_comp()(k, (*i).first))
i = insert(i, value_type(k, mapped_type()));
return (*i).second;
}
// ...
};
// 使用
map<int, string> imap;
map<int, string, less<int>, alloc> imap;
// 底层
template <int, pair<const int, string>, // const Key 保证了key不可以改变
select1st<value_type>, less<int>, alloc>
class rb_tree
hashtable
template <class Value, class Key, class HashFcn, // 哈希函数
class ExtractKey, class EqualKey, class Alloc=alloc>
class hashtable {
public:
typedef HashFcn hasher;
typedef EqualKey key_equal;
typedef size_t size_type;
private://三个函数对象(1*3) + 一个vector(4*3) + 元素总数(4) = 19,对齐调整为20
hasher hash;
key_equal equals;
ExtractKey get_key;
typedef __hashtable_node<Value> node;
vector<node*, Alloc> buckets;
size_type num_elements;
public:
size_type bucket_count() const {
return buckets.size();
}
template <class Value, class Key, class HashFcn, class ExtractKey,
class EqualKey, class Alloc=alloc>
struct __hashtable_iterator {
// ...
node* cur;
hashtable* ht;
};
template<class Value>
struct __hashtable_node {
__hashtable_node* next;
Value val;
};
// ...
};
// 使用
hashtable<const char*, const char*, hash<const char*>, // hash模板可能需要用户自己自定义偏特化场景
identity<const char*>, eqstr, alloc> // 标准库没有提供 hash<std::string>
ht(50, hash<const char*>(), eqstr());
ht.insert_unique("kiwi");
// cstring使用strcmp判断是否相等但它返回-1 0 1,而不是bool,需要一层转换。
struct eqstr {
bool operator()(const char* s1, const char* s2) const {
return strcmp(s1, s2) == 0;
}
};
// 拓展出的 set unordered_set map unordered_multimap
template <typename T,
typename Hash = hash<T>,
typename EqPred = equal_to<T>,
typename Allocator = allocator<T>>
class unordered_set;
template <typenaem Key, typename T,
typename Hash = hash<T>,
typename EqPred = equal_to<T>,
typename Allocator = allocator<pair<cosnt Key, T>>>
class unordered_multimap;
写出对象的hash函数
当对用于hashtable的key时必须要有hash函数
template<>
struct hash<string>
: public __hash_base<size_t, string>
{
size_t operator()(const string& ...s) const noexcept {
return std::Hash_impl::hash(__s.data(), __s.length());
}
};
算法
是一种 function template,不会直接接触到容器,而是通过迭代器简介处理容器。只有迭代器满足算法的调用才能正常编译。
迭代器分类
使用 struct 表示不同的种类,而不是通过int类型。原因:1. 可以通过模板参数与偏特化进行高效的处理
struct input_iterator_tagstruct output_iterator_tagstruct forward_iterator_tag : public input_iterator_tag
Forward_List 单链表实现的 HashTablestruct bidirectional_iterator_tag : public forward_iterator_tag
List RB_tree 双链表实现的 HashTablestruct random_access_iterator_tag : public bidirectional_iterator_tag
Array Vector Deque
template<typename I>
void display(I itr) {
cout << typeid(itr).name() << endl;
}
int main() {
display(array<int, 3>::iterator());
display(vector<int>::iterator());
display(list<int>::iterator());
display(forward_list<int>::iterator());
display(deque<int>::iterator());
display(set<int>::iterator());
display(multiset<int>::iterator());
display(map<int, int>::iterator());
display(multimap<int, int>::iterator());
// Pi
// N9__gnu_cxx17__normal_iteratorIPiSt6vectorIiSaIiEEEE
// St14_List_iteratorIiE
// St18_Fwd_list_iteratorIiE
// St15_Deque_iteratorIiRiPiE
// St23_Rb_tree_const_iteratorIiE
// St23_Rb_tree_const_iteratorIiE
// St17_Rb_tree_iteratorISt4pairIKiiEE
// St17_Rb_tree_iteratorISt4pairIKiiEE
exit(EXIT_SUCCESS);
}
迭代器对算法的影响
判断处迭代器的分类,然后对于不同的迭代器进行不同的操作从而获得更高的效率。
template<class InputIterator>
inline iterator_traits<InputIterator>::difference_type
__distance(InputIterator first, InputIterator last,
input_iterator_tag) { // 获得迭代器种类
iterator_traits<InputIterator>::difference_type n = 0;
while (first != last) { // 通过循环遍历得到长度
++first; ++n;
}
return n;
}
template<class RandomAccessIterator>
inline iterator_traits<RandomAccessIterator>::difference_type
__distance(RandomAccessIterator first, RandomAccessIterator last,
random_access_iterator_tag) { // 获得迭代器种类
return last - first; // 对于随机存取直接对指针进行相减
}
// 给其他算法库调用的算法,不直接暴露给用户
template <class InputIterator>
inline iterator_traits<InputIterator>::difference_type
distance(InputIterator first, InputIterator last) {
typedef typename iterator_traits<InputIterator>::iterator_category category;
return __distance(first, last, category());//不同情况调用不同的函数求差值
}
accumulate
template<class InputIterator, class T>
T accumulate(InputIterator first, InputIterator last, T init) {
for (; first != last; ++first)
init += *first;
return init;
}
template<class InputIterator, class T, class BinaryOperator>
T accumulate(InputIterator first, InputIterator last, T init, BinaryOperator binary_op) {
for (; first != last; ++first)
init = binary_op(init, *first);
return init;
}
// 符合 BinaryOperator 的可调用类
int fun(int x, int y) { return x + y; }
struct func {
int operator()(int x, int y) { return x + y; }
} obj;
// obj 就可以作为可调用对象传递,称为 仿函数
for_each
template<class InputIterator, class Function>
Function for_each(InputIterator first, InputIterator last, Function f) {
for (; first != last; ++first)
f(*first);
return f;
}
仿函数 functor
注意:写出的functor必须要继承 binary_funcation 才可以正常用于库算法的运行。
-
算术类
-
逻辑运算类 && || ~
-
相对关系类 == < >
template<class T> struct equal_to : public binary_funcation<T, T, bool> { bool operator()(const T& x, const T& y) { return x == y; } }
identity select1st select2nd 等都是gcc独有的非标准库函数。
Adapters 适配器
多种适配器,改造容器的叫 Container Adapters,改造迭代器的叫 Iterator Adapters,改造仿函数的叫 Functor Adaptors。把内容包装起来,让底层结构提供功能,适配器向外开放统一接口。
-
迭代器适配器
针对 Iterator Adapterstypedef x1 iterator_category; typedef x2 value_type; typedef x3 pointer; typedef x4 reference; typedef x5 difference_type; -
仿函数适配器
针对 Functor Adaptorstypedef Arg argument_type; typedef Result result_type; typedef Arg1 first_argument_type; typedef Arg2 second_argument_type; typedef Result result_type; -
容器适配器
stack queue
functors 可适配(adaptable)的条件
STL 规定每个 Adaptable Function 都应当挑选适当的类继承,Adapt 使用辅助函数中定义的类型别名声明变量进行操作:
/* 选择适当的一个继承 */
// 一个操作数的仿函数
template <class Arg, class Result>
struct unary_function {
typedef Arg argument_type;
typedef Result result_type;
};
// 两个参数的仿函数
template <class Arg1, class Arg2, class Result>
struct binary_function {
typedef Arg1 first_argument_type;
typedef Arg2 second_argument_type;
typedef Result result_type;
};
FunctorAdapters函数适配器
function adaptor 通过继承 unary_function bunary_function 获得对于参数、返回值类型的重命名。
bind2nd() (被抛弃,使用 bind)
绑定一个函数或函数对象的第二个参数
/*
将类函数函数 less 绑定第二个参数 40
判断 40 是否合法的方式是将其强转为 `typedef typename Operation::second_argument_type arg2_type` 类型
*/
bind2nd(less<int>(), 40);
// 辅助函数,让用户方便使用 binder2nd<Op>,编译器自动推导Op的type
template <class Operation, class T>
inline binder2nd<Opertation> bind2nd(const Operation& op, const T& x) {
// typename Operation::second_argument_type 要求 Operation
// 必须要有 second_argument_type 类型,即继承 bunary_function
typedef typename Operation::second_argument_type arg2_type;
//创建一个 binder2nd 对象,这是一个简化对象创建的方法
return binder2nd<Operation>(op, arg2_type(x));// 将第二个参数转为 arg2_type 类型
}
// 将某个接受两个参数的 Adaptable Bunary function 转换为 Unary Function
template<class Operation>
class binder2nd : public unary_function<
typename Operation::first_argument_type,
typename Operation::result_type>
{
protected:
Operation op;
typename Operation::second_argument_type value;
public:
// 构造函数
binder2nd(const Operation& x, // 第一个参数就是两个参数的函数
const typename Operation::second_argument_type& y) // 第二个参数
: op(x), value(y){}
typename Operation::result_type
operator()(const Operation::first_argument_type& x) const {
return op(x, value);
}
};
conut_if
template <class InputIterator, class Predicate>
typename iterator_traits<InputIterator>::difference_type
count_if(InputIterator first, InputIterator last,
Predicate pred) {//保持条件判断类函数
typename iterator_traits<InputIterator>::difference_type n = 0;
for (; first != last; ++first) {
if (pred(*first)) // 每次判断时执行类函数
++n;
}
return n;
}
not1
template<class Predicate>
class unary_negate : public unary_function<typename Predicate::argument_type, bool> {
protected:
Predicate pred;
public:
explicit unary_negate(const Predicate& x) : pred(x) {}
bool operator()(typename Predicate::argument_type& x) const {
return !pred(x);
}
};
bind
可以绑定:
- functions
- function objects
- member functions,_1 必须是某个 object 地址
- data members,_1 必须是某个 object 地址
返回一个function object ret,调用 ret 相当于调用上述 1,2,3或相当于取出 4
// binding functions
std::divides<double> my_divide;
bind(my_divide, 10, 2); // return 10/2 , 5
bind(my_divide, placeholders::_1, 2); // return x/2
bind(my_divide, placeholders::_1, placeholders::_2); // return x/y
bind<int>(my_divide, placeholders::_2, placeholders::_1); // return int(y/x)
// binding members
struct MyPair {
double a, b;
double multiply() {return a * b;}
};
MyPair ten_two {10, 2};
// member function (即类的成员函数MyPair::multiply) 第一个参数是指向对象本身的指针参数 this
auto bound_memfn = bind(&MyPair::multiply, placeholders::_1); // return x.multiply()
bound_memfn(ten_two); // 20
auto bound_memdata = bind(&MyPair::a, ten_two); // return ten_two.a
bound_memdata(); // 10
auto bound_memdata2 = bind(&MyPair::b, placeholders::_1);//使用占位符表示暂时不绑定this指针 return x.b
bound_memdata2(ten_two); // 2
auto fn = bind(less<int>(), _1, 50); // bind2nd(less<int>(), 50)
count_if(vec.cbegin(), vec.end(), fn);
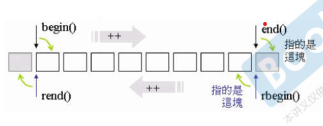
Iterator Adapters 迭代器适配器
reverse_iterator
reverse_iterator
rbegin() {
return reverse_iterator(end());
}
reverse_iterator
rend() {
return reverse_iterator(begin());
}
template <class Iterator>
class reverse_iterator {
protected:
Iterator current; // 对应正向迭代器
public:
// 逆向迭代器的5种 associated types 都和其对应的正向迭代器相同
typedef typename iterator_traits<Iterator>::iterator_category iterator_category;
typedef typename iterator_traits<Iterator>::value_type value_type;
typedef Iterator iterator_type; 正向迭代器
typedef reverse_iterator<Iterator> self; 逆向迭代器
explicit reverse_iterator(iterator_type x) : current(x) {}
reverse_iterator(const self& x) : current(x.current) {}
iterator_type base() const { return current; }
// 对逆向迭代器取值,就是将对应正向迭代器退一位取值
reference operator*() const { Iterator tmp = current; return *--tmp; }
pointer operator->() const { return &(operator*()); }
self& operator++() { --current; return *this; }
self& operator--() { ++current; return *this; }
self operator+(differnece_type n) const { return self(current - n); }
self operator-(differnece_type n) const { return self(current + n); }
};
inserter
auto it = foo.begin();
advance(it, 3); // 迭代器向前走3步
copy(bar.begin(), bar.end(), inserter(foo, it));//这种写法本质上是不断插入
foo : 1 2 3 4 5
bar : 7 8 9
=> 1 2 3 7 8 9 4 5
template<class InputIterator, class OutputIterator>
OutputIterator copy (InputIterator first, InputIterator last, OutputIterator result) {
while (first != last) {
*result = *first; // inserter重载了操作符,所以在赋值时不是单纯的拷贝,而是申请空间再拷贝
++reslut; first;
}
}
// 辅助函数,帮用户获取 insert_iterator
template<class Container>
inline insert_iterator<Container>
inserter(Container& x, Iterator i) {
typedef typename Container::iterator iter;
return insertor<Container>(x, iter(i));
}
// 这个adapter将迭代器的赋值操作改为insert操作,并且移动迭代器。如此实现表面赋值,实际上insert
template<class Container>
class insert_iterator {
protected:
Container* constainer; // 底层容器
typename Container::iterator iter;
public:
typedef output_iterator_tag iterator_category; // 标出迭代器类型
insert_iterator(Container& x, typename Container::iterator i)
: container(&x), iter(i) {}
insert_iterator<Container>&
operator==(const typename Container::value_type& value) {
iter = container->insert(iter, value); // 插入元素
++iter; // 令迭代器永远跟着target移动
return *this;
}
}
copy 函数只是按照指针位置逐个空间赋值,inserter 保证每个插入的元素都存储在新申请的空间
ostream_iterator
重写了 operator== 方法
vector<int> myvector{1,2,3,4,5};
ostream_iterator<int> out_it(cout, ",");
copy(myvector.begin(), myvector.end(), out_it);
// 输出 "1,2,3,4,5,"
template<class T, class charT=char, class traits=char_traits<charT>>
class ostream_iterator : public iterator<output_iterator_tag, void, void, void, void> {
basic_ostream<charT, traits> *out_stream;
const charT *delim;
public:
typedef charT char_type;
typedef traits traits_type;
typedef basic_ostream<charT, traits> ostream_type;
ostream_iterator(ostream_type& s) : out_stream(&s), delim(0) {}
ostream_iterator(ostream_type& s, const charT *delimiter)
: out_stream(&s), delim(delimiter) {}
ostream_iterator(const ostream_iterator<T, charT, traits>& x)
: out_stream(x.out_stream), delim(x.delim) {}
~ostream_iterator() {}
// 操作符重载使得赋值变为输出
ostream_iterator<T, charT, traits>& operator= (const T& value) {
*out_stream << value;
if (delim != 0)
*out_stream << delim;
return *this;
}
ostream_iterator<T, charT, traits>& operator*() { return *this; }
ostream_iterator<T, charT, traits>& operator++() { return *this; }
ostream_iterator<T, charT, traits>& operator++(int) { return *this; }
};
istream_iterator
istream_iterator<double> eos; // 没有参数的空istream用于作标兵
// 初始化调用++操作,读取数据
istream_iterator<double> iit(cin);
if (iit != eos)
value1 = *iit;
// 读取数据
++iit;
if (iit != eos)
value2 = *iit;
istream_iterator<int> iit(cin), eos;
copy(iit, eos, inserter(c, c.begin()));
template<class T, class charT=char, class traits=char_traits<charT>, class Distance=ptrdiff_t>
class istream_iterator : public iterator<input_iterator_tag, T, Distance, const T*, const T&> {
basic_istream<charT, traits> *in_stream;
T value;
public:
typedef charT char_type;
typedef traits traits_type;
typedef basic_istream<charT, traits> istream_type;
istream_iterator() : in_stream(0) {}
istream_iterator(istream_type& s) : in_stream(&s) { ++*this; }
istream_iterator(const istream_type<T, charT, traits, Distance>& x)
: in_stream(x.in_stream), value(x.value) {}
~istream_iterator() {}
const T& operator*() const { return value; }
const T* operator->() const { return &value; }
// ++ 操作会导致读取数据
istream_iterator<T, charT, traits, Distance>& operator++() {
if (in_stream && !(*in_stream >> vlaue))
in_stream = 0;
return *this;
}
istream_iterator<T, charT, traits, Distance> operator++(int) {
istream_iterator<T, charT, traits, Distance> tmp = *this;
++*this;
return tmp;
}
};
标准库之内 STL之外
万用 Hash Function
class CustomerHash {
public:
// 自定义求hash的类函数
size_t operator()(const Customer& c) const {
return hash_val(c.xxx, c.yyy, c.zzz);//没有传入 seed,调用下方第一个函数
}
};
/************ 万能的哈希函数 ***********/
template<typename... Type>
inline size_t hash_val(const Types&... args) {
size_t seed = 0;
hash_val(seed, args...);
return seed; // 返回值为 seed
}
template<typename T, typename... Type>//逐一取出 value,将n个变为 1 + (n-1) 个 variadic templates
inline size_t hash_val(size_t& seed, const Types&... args) {
hash_combine(seed, val);
hash_val(seed, args...);
}
template<typename T>//处理只有一个 value 的情况
inline void hash_val(size_t& seed, const T& val) {
hash_combine(seed, val);
}
template<typename T>
inline void hash_combine(size_t& seed, const T& val) {
seed ^= std::hash<T>()(val) + 0x9e377b9 + (seed<<6) + (seed>>2);
}
标准库提供
#include <hash_fun.h>
hash 类函数
Tuple
一组类型数据的组成的元组,重写了 < = 等操作符
使用:
tuple<string, int, int, complex<double>> t;
sizeof(t); // 32
tuple<int, float, string> t1(41, 6.3, "nico");
cout << "t1: " << get<0>(t1) << get<1>(t1) << get<2>(t2) << endl;
auto t2 = make_tuple(22, 44, "str");
get<1>(t1) = get<1>(t2);
int i; float f; string s;
tie(i, f, s) = t1; // 一次性将tuple的元素拿出,赋值到各个变量
实现
template<typename... Values> class tuple;
template<> class tuple<> {};
template<typename Head, typename... Tail>
class tuple<Head, Tail> : private tuple<Tail...> {
typedef tuple<Tail...> inherited;
public:
tuple() {}
tuple(Head v, Tail... vtail) : m_head(v), inherited(vtail...) {}
typename Head::type head() { return m_head; }
inherited& tail() { return *this; } // 通过强转去除头元素
protected:
Head m_head; // 在初始化时赋值头元素
};
tuple<int, float, string> -继承-> tuple<float, string> -继承-> tuple<string> -继承-> tuple<>
type traits
类型萃取 在编译期计算、查询、判断、转换和选择,增强了泛型编程的能力,使得我们在编译期就能做到优化改进甚至排错
template<typename type>//泛化
struct __type_traits {
typedef __true_type this_dummy_member_must_be_first;
typedef __false_type has_trival_default_constructor;
typedef __false_type has_trival_copy_constructor;
typedef __false_type has_trival_assignment_operator;
typedef __false_type has_trival_destructor;
typedef __false_type is_POD_type; // POD Plain Old Data,c语言种struct,只有数据没有函数
};
template<>//特化
struct __type_traits<int> {
typedef __true_type has_trival_default_constructor;//表示默认构造函数不重要
typedef __true_type has_trival_copy_constructor;
typedef __true_type has_trival_assignment_operator;
typedef __true_type is_POD_type; // POD Plain Old Data
};
// 对于自定义类需要自定义特化模板
// 通过获取 __type_traits<Foo>::has_trival_destructor 的值得知类的析构函数是否重要,并决定出最佳的操作
is_void 源码
template<typaname>
struct __is_void_helper : public false_type {};
template<>
struct __is_void_helper<void> : public true_type {};
template<typename _Tp>
struct is_void : public __is_void_helper<typename remove_cv<_Tp>::type>::type {};
// remove_cv
template<typename _Tp>
struct remove_cv {
typedef typename remove_const<typename remove_volatile<_Tp>::type>::type type;
};
// remove_const
template<typename _Tp>
struct remove_const { typedef _Tp type; };
template<typename _Tp>
struct remove_const<_Tp const> { typedef _Tp type; };
// remove_volatile
template<typename _Tp>
struct remove_volatile { typedef _Tp type; };
template<typename _Tp>
struct remove_volatile { typedef _Tp type; };
// add_const
template<typename _Tp>
struct add_const { typedef _Tp const type; };
