
Spark
Spark
一个用于大规模数据处理的统一计算引擎,相当于Hadoop中的MapReduce。但除最终计算结果外其他数据都保存在内存,且任务切分比单一的Map+Reduce更加灵活。
基于内存计算,它的速度可以达到MapReduce的上百倍
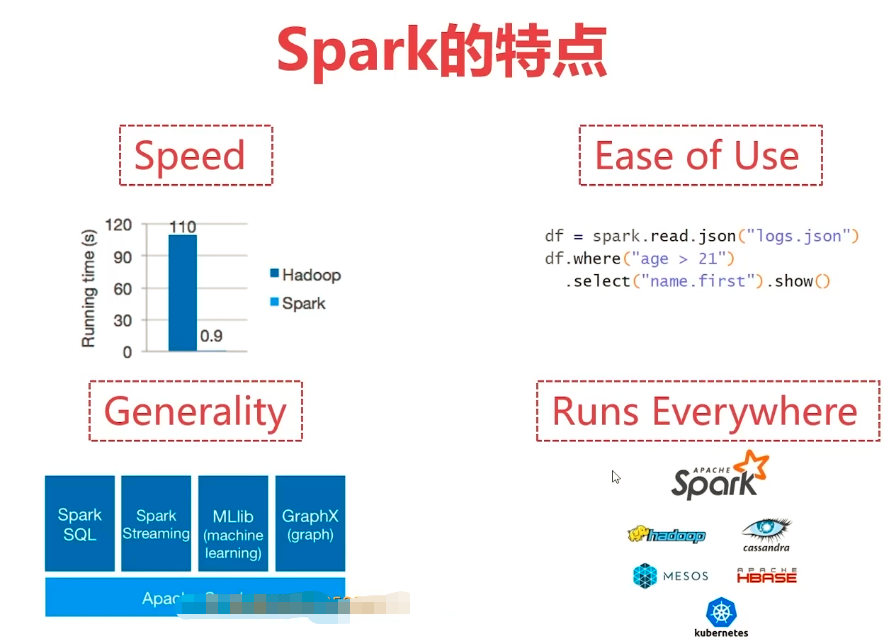
Spark vs Hadoop
综合能力:Spark是一个综合性质的计算引擎,Hadoop既包含MapReduce(计算)还包含HDFS(存储)和YARN(资源管理)
计算模型:Spark任务可以包含多个计算操作,轻松实现复杂迭代计算,Hadoop中MapReduce任务值包含Map和Reduce两个阶段,不够灵活
处理速度:Spark任务的数据存在内存中,而Hadoop中MapReduce任务基于磁盘
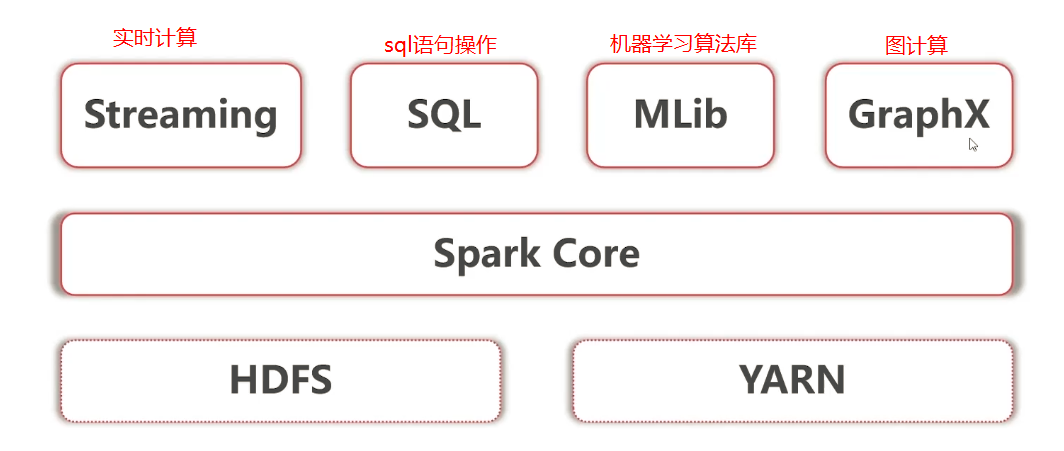
应用场景
- 低延时的海量数据计算需求 (Spark Core)
- 低延时SQL交互查询需求(Spark SQL)
- 准实时(秒级)海量数据计算需求i(Spark Streaming)
安装
Spark Standalone 集群安装部署
要提前配置好网络、jdk 等配置
- 下载安装包到主节点并解压,进入conf目录
- 重命名 spark-env.sh.template 为 spark-env.sh 并添加
JAVA_HOMESPARK_MASTER_HOST - 重命名 slaves 文件,添加从节点网络地址
启动:sbin/start-all.sh 使用命令 jps 可看见表示主节点的 Master 或表示从节点的 Worker。通过 8080 端口可以看见 web 控制界面
# 提交任务
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \ # 任务类
--master spark://192.168.56.152:7077 \
examples/jars/spark-examples_2.12-3.1.3.jar \
3 # 计算多少次
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://192.168.56.152:7077 examples/jars/spark-examples_2.12-3.1.3.jar 3Spark ON YARN 集群安装部署(推荐)
依赖Hadoop集群,spark节点需要也是Hadoop节点。不需要启动spark进程
- 下载解压
- 将 spark-env.sh.template 改名为 spark-env.sh,添加
export JAVA_HOME=xxx export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
提交任务
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster examples/jars/spark-examples_2.12-3.1.3.jar
# 结果见于 http://hadoop-master:8088/cluster/apps原理
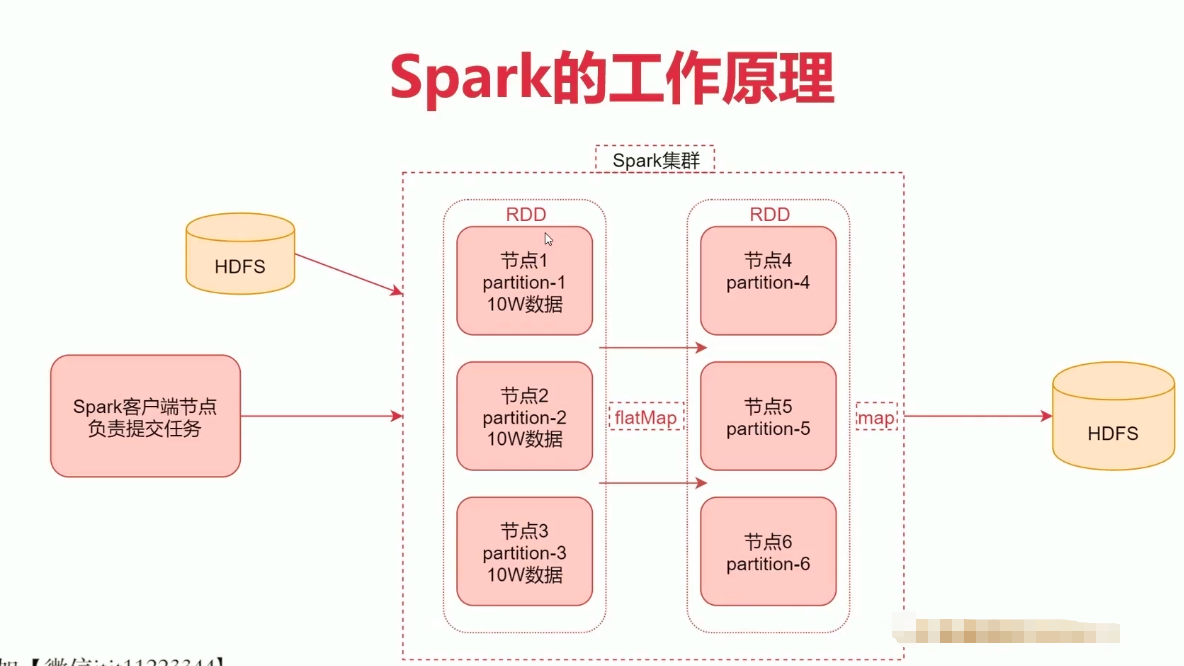
提交任务后,Spark 从HDFS中读取数据进行计算,加载到RDD中,RDD是一种弹性计算框架具有分区能力并将数据放置在内存中。RDD中数据在经过计算后会一一对应地传递到新的RDD,没有shuffle过程。这个过程中可以多次调用高阶函数,如 map flatMap。
什么是RDD?
- RDD通常通过Hadoop上文件创建,也可以通过程序中地集合来创建
- RDD是Spark提供地核心抽象,全称为 Rdsillient Distributed Dataset,即弹性分布式数据集
- 三个特点:
- 弹性:RDD数据默认情况下存放在内存中,但是在内存资源不足时,Spark也会自动将RDD数据写入磁盘
- 分布式:RDD 在抽象上来说是一种元素数据地集合,它是被分区的,每个分区分布在集群的不同节点上,从而让RDD中数据可以被并行操作
- 容错性:RDD 最重要的特性就是提供了容错性,可以自动从节点失败中恢复过来,从数据源中重新加载数据
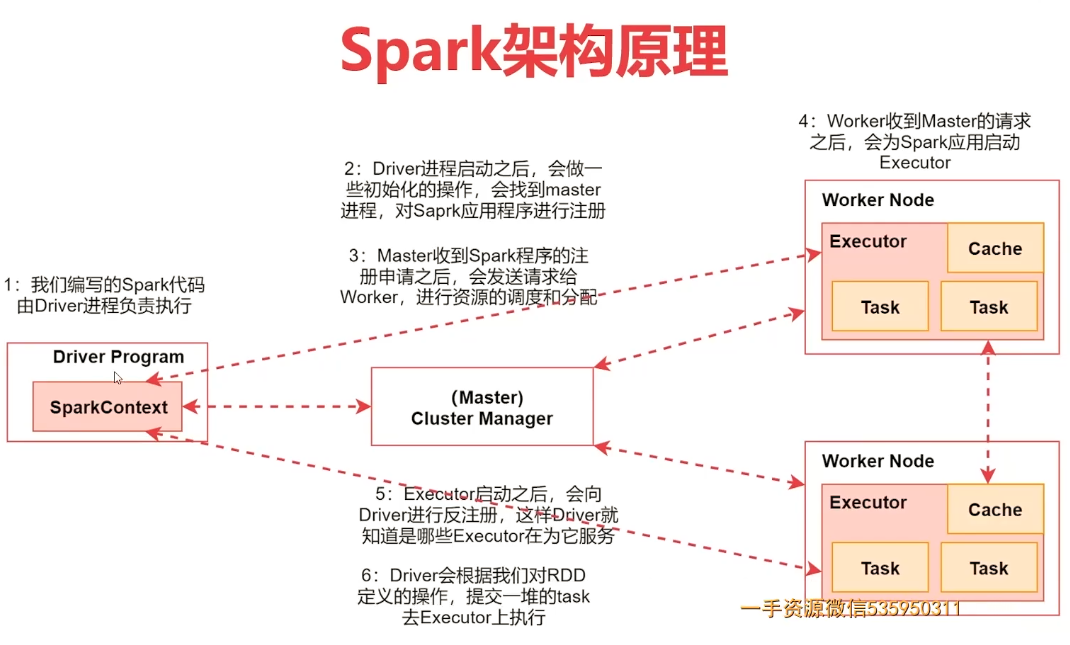
Spark 架构相关进程
- Driver:编写出的Spark程序由Driver进程负责执行
- Master:集群的主节点中启动的进程,集群资源管理与分配、集群的监控
- Worker:集群的从节点中启动的进程,负责启动其他进程来启动任务
- Executor:Worker负责启动,用于数据处理和数据计算
- Task:由Executor负责启动的线程,它是真正干活的,处理、计算数据
开发Spark计算任务
Q:读取文件中所有内容,计算每个单词出现的次数?
创建环境:新建一个java的maven项目,添加scala模块依赖,在maven中添加spark-core依赖。注意spark、scala与maven依赖的版本要适配
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.3</version>
<scope>provided</scope>
</dependency>scala 实现词频统计
package org.example
import org.apache.spark.{SparkConf, SparkContext}
object WordCountScala {
def main(args: Array[String]): Unit = {
// 1. 创建一个 SparkContext
val conf = new SparkConf()
conf.setAppName("WordCount") // 任务起名
.setMaster("local") // 表示在本地执行,方便调试。真正执行任务还需提交到spark集群
val sparkContext = new SparkContext(conf)
// 2. 加载数据
/*
* linesRDD 数据如下:
* hello world
* hello scala
* hello world
*/
val linesRDD = sparkContext.textFile("C:\\data\\tmp.txt")
// 3. 切割字符串,将数据切成单词
/*
* wordsRDD 数据如下:
* hello
* world
* hello
* scala
* hello
* world
*/
val wordsRDD = linesRDD.flatMap(_.split(" "))
// 4. 迭代words,将每个word转换为 (word, 1) 这种形式
/*
* pairRDD 数据如下:
* (hello, 1)
* (world, 1)
* (hello, 1)
* (scala, 1)
* (hello, 1)
* (world, 1)
*/
val pairRDD = wordsRDD.map((_, 1))
// 5. 根据key进行分组聚合统计
/*
* (hello, 3)
* (world, 2)
* (scala, 1)
*/
val wordCountRDD = pairRDD.reduceByKey(_ + _) // 相同的key分为一组,一组中数字进行累加
// 6. 打印结果
/*
scala : 1
hello : 3
world : 2
*/
wordCountRDD.foreach(wordsRDD => println(wordsRDD._1 + " : " + wordsRDD._2))
// 7. 停止SparkContext
sparkContext.stop()
}
}java 实现词频统计
package org.example;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Iterator;
import java.util.List;
public class WordCount {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("WordCount").setMaster("local");
JavaSparkContext sparkContext = new JavaSparkContext(conf);
JavaRDD<String> linesRDD = sparkContext.textFile("c:\\data\\tmp.txt");
// 以下可以使用 lambda 表达式简化
// 参数中泛型,第一个是输入数据类型(待分割的字符串),第二个是输出数据类型(被分割后的单词)
linesRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return List.of(s.split(" ")).iterator();
}
// PairFunction 的参数分别为: 1. 输入数据类型 2. 输出tuple的第一个参数类型 3. 输出tuple的第二个参数类型
// 注意:如果后面耀荣 xxxByKey 操作,前面都需要用 mapToPair 处理
}).mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<>(s, 1);
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer + integer2;
}
}).foreach(tuple2 -> System.out.println(tuple2._1 + " : " + tuple2._2));
sparkContext.stop();
}
}开启 Spark history server 服务
任意一台 Spark 节点上启动 historyServer 服务
- 将 spark-defaults.conf.template 重命名为 spark-defaults.conf
- 在 spark-defaults.conf 中添加
spark.eventLog.enabled=true spark.eventLog.compress=true spark.eventLog.dir=hdfs://ubuntu:9000/logs/spark # hdfs 中日志位置 spark.history.fs.logDirectory=hdfs://ubuntu:9000/logs/spark spark.yarn.historyServer.address=http://ubuntu-02:18080 # 在启动 spark history server 的节点上指定ui端口 - 在 spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://ubuntu:9000/logs/spark" - 启动
${SPARK_HOME}/sbin/start-history-server.sh
访问 ubuntu-02:18080 可看见 spark 日志管理界面
在执行spark任务时可以在hadoop的yarn的管理界面看到任务详情,其中有spark的log管理界面链接
任务提交
- 直接idea执行,方便本地环境调试
- 使用spark-submit提交到集群中执行(实际工作中使用)
- 修改代码,注释掉
.setMaster("local"),将读取文件的路径改为动态指定,要从hdfs中读取文件 - 修改pom.xml
pom.xml
<plugins> <!-- java 编译插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <encoding>UTF-8</encoding> </configuration> </plugin> <!-- scala 编译插件 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>4.5.3</version> <executions> <execution> <id>scala-compile-first</id> <phase>process-resources</phase> <goals> <goal>add-source</goal> <goal>compile</goal> </goals> </execution> <execution> <id>scala-test-compile</id> <phase>process-test-resources</phase> <goals> <goal>add-source</goal> <goal>testCompile</goal> </goals> </execution> </executions> <configuration> <args> <!-- 编译时使用 libs 目录下的 jar 包,通过 mvn scala:help 查看说明 --> <arg>-extdirs</arg> <arg>${project.basedir}/libs</arg> </args> <scalaCompatVersion>2.12</scalaCompatVersion> <scalaVersion>2.12.16</scalaVersion> </configuration> </plugin> <!-- 打包插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.2.0</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <mainClass></mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> - 打包成jar文件,并提交到spark节点
- 提交任务
https://spark.apache.org/docs/latest/submitting-applications.html
./spark-submit \ --class org.example.WordCountScala \ # 指定任务启动类 --master yarn \ --deploy-mode client \ --executor-memory 1G \ --num-executors 1 \ ~/bigdata/learnScala-1.0-SNAPSHOT-jar-with-dependencies.jar \ # jar包位置 hdfs://ubuntu:9000/get-docker.sh # 使用命令行参数指定文件
- 修改代码,注释掉
- 使用 spark-shell,方便在集群环境调试代码
bin/spark-shell启动shell环境,会在本地启动一个 spark standalone 集群。spark-shell --master yarn --deploy-mode client启动 on yarn 模式的 spark
然后在scala的交互命令下执行程序
交互环境提供了 SparkContext 变量可以直接使用,默认提供:
Spark context Web UI available at http://ubuntu-02:4040 Spark context available as 'sc' (master = local[*], app id = local-1654939862172). Spark session available as 'spark'.
如果使用 on yarn 模式则无法在控制台看见结果,结果输出到 yarn 中,需要到 yarn history 中查看
创建 RDD
RDD 是 Spark 编程的核心, 在进行 Spark 编程时, 首要任务是创建一个初始的 RDD
三种创建方式:
- 集合:用于测试
- 本地文件:临时处理
- HDFS 文件:生产环境
使用集合创建 RDD
如果要通过集合来创建 RDD , 需要针对程序中的集合, 调用 SparkContext 的 parallelize() 方法。 Spark 会 将集合中的数据拷贝到集群上, 形成一个分布式的数据集合, 也就是一个 RDD 。 相当于, 集合中的部分数据会到一个节点上, 而另一部分数据会到其它节点上。 然后就可以用并行的方式 来操作这个分布式数据集合了。
调用 parallelize() 时, 有一个重要的参数可以指定, 就是将集合切分成多少个 partition 。 Spark 会为每一个 partition 运行一个 task 来进行处理。 Spark 默认会根据集群的配置来设置 partition 的数量。 我们也可以在调用 parallelize() 方法时, 传入第二个 参数, 来设置 RDD 的 partition 数量, 例如: parallelize(arr, 5)
package org.example
import org.apache.spark.{SparkConf, SparkContext}
/**
* 使用集合创建 RDD
*/
object CreateRDDByArrayScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("CreateRDDByArray").setMaster("local")
val sc = new SparkContext(conf)
val arr = Array(1, 2, 3, 4, 5)
val rdd = sc.parallelize(arr)
// 只有这个调用 spark 的方法才会真正到spark集群上执行,其余都是在drive上执行
val sum = rdd.reduce(_ + _)
println(sum)
}
}package org.example;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
public class CreateRDDByArrayJava {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("CreateRDDByArrayJava").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
Integer sum = rdd.reduce((i, i2) -> i + i2);
System.out.println("sum = " + sum);
}
}使用本地文件或HDFS文件创建RDD
通过 SparkContext 的 textFile() 方法, 可以针对本地文件或 HDFS 文件创建 RDD , RDD 中的每个元素就是文 件中的一行文本内容 textFile() 方法支持针对目录、 压缩文件以及通配符创建
RDD Spark 默认会为 HDFS 文件的每一个 Block 创建一个 partition , 也可以通过 textFile() 的第二个参数手动设置 分区数量, 只能比 Block 数量多, 不能比 Block 数量少, 比 Block 数量少的话你的设置是不生效的
使用 val rdd = sc.textFile(path)获取rdd,具体代码见前文词频统计案例。
Transformation 和 Action
spark 对于rdd的操作总体可以分为两类:
- Transformation:这里的 Transformation 可以翻译为转换,表示是针对 RDD 中数据的转换操作,主要会针对已有的 RDD 创建一个新的 RDD:常见的有 map 、 flatMap 、 filter 等等
- Action:Action 可以翻译为执行,表示是触发任务执行的操作,主要对 RDD 进行最后的操作,比如遍历、 reduce 、 保存到文件等,并且还可以把结果返回给 Driver 程序
无论是哪种操作都会被称为算子,如:map算子、reduce算子。
Transformation算子有一个特性:lazy,即懒加载。
Action 的特性: 执行 Action 操作才会触发一个 Spark 任务的运行, 从而触发这个 Action 之前所有的 Transformation 的执行
sc.textFile("/hello.txt")
// 前几步都是 Transformation 操作,只是进行逻辑记录,没有真正执行
.flatMap(_.split("\\s+"))
.map((_, 1))
.reduceByKey(_ + _)
// 这一步是 Action 操作,触发之前所有 Transformation 算子的执行,这些算子被拆分成多个task到多个节点上执行
// 只有执行到这一行代码时,任务才计算,如果没有这个Action,前面算子不进行执行
.foreach(wordsRDD => println(wordsRDD._1 + " : " + wordsRDD._2))Transformation
https://spark.apache.org/docs/latest/rdd-programming-guide.html#transformations
常见算子

Transformation 操作
package org.example
import org.apache.spark.{SparkConf, SparkContext}
object TransformationOpScala {
def mapOp(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array(1, 2, 3, 4))
rdd.map(_ * 2).foreach(println(_))
}
def filterOp(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array(1, 2, 3, 4))
rdd.filter(_ % 2 == 0).foreach(println(_))
}
def flatMapOp(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array("hello world", "hello scala"))
rdd.flatMap(_.split("\\s+")).foreach(println(_))
}
def groupByKeyOp(sc: SparkContext): Unit = {
// 数据为主播id与所处的大区号
val rdd = sc.parallelize(Array((150001, "US"), (150002, "CN"), (150003, "CN")))
// 因为要按照大区号进行分组,所以tuple中的元素要调换位置
// 注意:在使用类似 groupByKey 这种基于key的算子时,要提前包rdd中数据组装成tuple2这种形式
rdd.map(tup => (tup._2, tup._1)).groupByKey().foreach(tup => {
print(tup._1 + " : ")
for (uid <- tup._2) {
print(uid + " ")
}
println()
})
}
def groupByKeyOp2(sc: SparkContext): Unit = {
// 数据为主播id与所处的大区号
val rdd = sc.parallelize(Array((150001, "US", "male"), (150002, "CN", "female"), (150003, "CN", "male")))
// 如果tuple中数据超过2列怎么办?
// 要把key作为tuple2的第一列,剩下的可以再使用一个tuple2
// 此时map生产新数据为 ("US", (150001, "male"))
rdd.map(tup => (tup._2, (tup._1, tup._3))).groupByKey().foreach(tup => {
print(tup._1 + " : ")
for ((uid, gender) <- tup._2) {
print("< " + uid + ", " + gender + " >")
}
println()
})
}
def reduceByKeyOp(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array((150001, "US"), (150002, "CN"), (150003, "CN")))
rdd.map(tup => (tup._2, 1)).reduceByKey(_ + _).foreach(println(_))
}
def sortByKeyOp(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array((150001, 400), (150002, 200), (150003, 300)))
rdd.map(tup => (tup._2, tup._1))
.sortByKey(false) // 默认升序,使用false指定降序
.foreach(println(_))
rdd.sortBy(_._2, false).foreach(println(_)) // 当元素数量为3时,返回值为 (key, (val1, val2, val3))
}
def joinOp(sc: SparkContext): Unit = {
val rdd1 = sc.parallelize(Array((150001, "US"), (150002, "CN"), (150003, "CN")))
val rdd2 = sc.parallelize(Array((150001, 400), (150002, 200), (150003, 300)))
val rdd = rdd1.join(rdd2)
rdd.foreach(tup => {
println(tup._1 + "\t" + tup._2._1 + "\t" + tup._2._2)
})
}
def distincOp(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array((150001, "US"), (150002, "CN"), (150003, "CN")))
rdd.map(_._2).distinct().foreach(println(_))
}
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TransformationOpScala").setMaster("local")
val sc = new SparkContext(conf)
// map : 对集合中每个元素乘以 2
mapOp(sc)
// filter : 过滤出集合中的偶数
filterOp(sc)
// flatMap : 将行拆分为单词
flatMapOp(sc)
// groupByKey : 对每个大区的主播进行分组
groupByKeyOp(sc)
groupByKeyOp2(sc)
// reduceByKey : 统计每个大区的主播数量
reduceByKeyOp(sc)
// sortByKey : 对主播的音浪收入排序
sortByKeyOp(sc)
// join : 打印每个主播的大区信息和音浪收入
joinOp(sc)
// distinct : 统计当天开播的大区信息
distincOp(sc)
}
}Action
https://spark.apache.org/docs/latest/rdd-programming-guide.html#actions

Action 操作
package org.example
import org.apache.spark.{SparkConf, SparkContext}
object ActionOpScala {
def reduceOp(sc: SparkContext) = {
val rdd = sc.parallelize(Array(1, 2, 3, 4))
println(rdd.reduce(_ + _))
}
def collectOp(sc: SparkContext) = {
val rdd = sc.parallelize(Array(1, 2, 3, 4))
// collect 返回的是一个Array数组
// 注意:如果RDD中数据过大,不建议使用collect,因为数据最终会返回给Driver进程所在节点
val res = rdd.collect()
for (item <- res) {
println(item)
}
}
def takeOp(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array(1, 2, 3, 4))
println(rdd.take(2))
}
def countOp(sc: SparkContext) = {
val rdd = sc.parallelize(Array(1, 2, 3, 4))
println(rdd.count())
}
def saveAsTextFileOp(sc: SparkContext) = {
val rdd = sc.parallelize(Array(1, 2, 3, 4))
rdd.saveAsTextFile("hdfs://ubuntu:9000/deleteMe")
}
def countByKeyOp(sc: SparkContext) = {
val rdd = sc.parallelize(Array(("A", 1), ("B", 2), ("A", 3), ("C", 4)))
val res = rdd.countByKey()
for ((k, v) <- res) {
println(k + " : " + v)
}
}
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TransformationOpScala").setMaster("local")
val sc = new SparkContext(conf)
// reduce : 聚合计算
reduceOp(sc)
// collect : 获取元素集合
collectOp(sc)
// take(n) : 获取前 n 个元素
takeOp(sc)
// count : 获取元素总数
countOp(sc)
// saveAsTextFile : 保存文件
saveAsTextFileOp(sc)
// countByKey : 统计相同的 key 出现多少次
}
}共享变量
默认情况下,一个算子函数中使用到了某个外部变量,那么这个变量会被拷贝到每个task中,此时每个task只能操作自己的那份数据。Spark 提供了两种变量:
- BroadcastVariable 广播变量
- Accumulator 累加器
BroadcastVariable
广播变量将为每个节点拷贝一份而非为每个task,好处是优化性能,减少网络传输及内存消耗。
通过调用 SparkContext 的 broadcast() 方法,针对某个变量创建只读的广播变量,可以通过广播变量的 value() 方法获取值
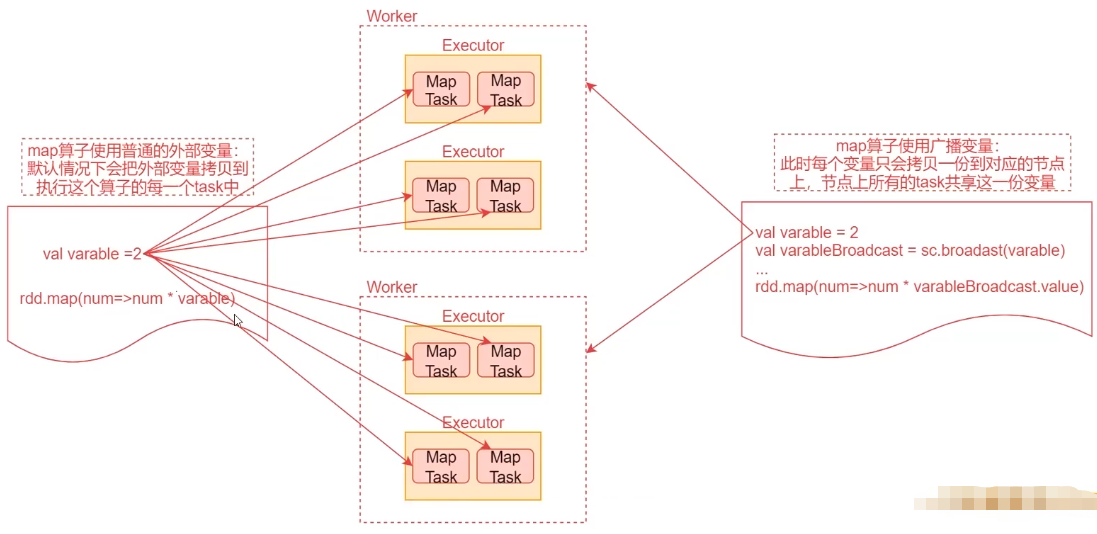
当使用的变量为一个庞大的集合等需要占用庞大的空间,广播变量就非常有用。
package org.example
import org.apache.spark.{SparkConf, SparkContext}
object BroadcastVariableScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("BroadcastVariableScala").setMaster("local")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(Array(1, 2, 3, 4, 5))
val varable = 2
rdd.map(_ * varable) // 此时每个task都会复制一个变量
val varableBroadcast = sc.broadcast(varable)
rdd.map(_ * varableBroadcast.value) // 此时只在每个节点上复制一份
sc.stop()
}
}Accumulator
累加器,主要用于多个节点对一个变量进行共享性的操作。正常情况下,一个算子内部可能产生多个task并行,所以task内部的聚合操作都是局部的;要实现多个task全局聚合计算时就要使用 Accumulator 这个共享累加变量。
注意:Accumulator 只提供了累计功能,再task中只能对 Accumulator 进行累计操作,不能读取它的值。只有Driver 进程才能读取。
package org.example
import org.apache.spark.{SparkConf, SparkContext}
object AccumulatorOpScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("AccumulatorOpScala").setMaster("local")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(Array(1, 2, 3, 4, 5))
var total = 0 // 在 Driver 进程上定义此变量
rdd.foreach(i => total += i) // 局部累加,每个task内部各自累加分到自己节点的数字
println(total) // total仍然0,因为前一个foreach是在各个RDD节点上累加的,而此处打印的total是在Driver上的
// 使用 Accumulator 实现累加
val sumAccumulator = sc.longAccumulator
rdd.foreach(i => sumAccumulator.add(i)) // 此处只能累加,不能获取值
println(sumAccumulator.value) // 获取值
sc.stop()
}
}package org.example;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.util.LongAccumulator;
import java.util.Arrays;
public class AccumulatorOpJava {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("AccumulatorOpJava").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
// 注意:此处sc为JavaSparkContext,sc.sc()获得SparkContext
LongAccumulator accumulator = sc.sc().longAccumulator();
rdd.foreach(i -> accumulator.add(i));
System.out.println("accumulator = " + accumulator);
sc.stop();
}
}RDD 持久化
当使用持久化后第二次计算的耗时将远小于第一次,文件越大效果越明显
package org.example
import org.apache.spark.{SparkConf, SparkContext}
object PersistRddScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("PersistRddScala").setMaster("local")
val sc = new SparkContext(conf)
// 注意 cache 的用法和位置
// cache 默认是基于内存的持久化
// cache() = persist(StorageLevel.MEMORY_ONLY)
val rdd = sc.textFile("C:\\data\\tmp.txt").cache()
var startTime = System.currentTimeMillis()
var count = rdd.count()
var endTime = System.currentTimeMillis()
println(count)
println("第一次耗时: " + endTime - startTime)
startTime = System.currentTimeMillis()
count = rdd.count()
endTime = System.currentTimeMillis()
println(count)
println("第二次耗时: " + endTime - startTime)
sc.stop()
}
}
综合案例:TopN主播统计
Q: 计算一款直播app的每个大区当天金币收入 TopN 的主播,不同国家的主播划分到不同大区。
日志数据:
gift_record.log
gift_record.log
{"uid": 720123141001, "vid": 14943445328940001, "good_id": "223", "gold": 9, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141002, "vid": 14943445328940001, "good_id": "223", "gold": 11, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141003, "vid": 14943445328940002, "good_id": "223", "gold": 47, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141004, "vid": 14943445328940002, "good_id": "223", "gold": 36, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141005, "vid": 14943445328940003, "good_id": "223", "gold": 30, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141006, "vid": 14943445328940003, "good_id": "223", "gold": 21, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141007, "vid": 14943445328940004, "good_id": "223", "gold": 4, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141008, "vid": 14943445328940004, "good_id": "223", "gold": 28, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141009, "vid": 14943445328940005, "good_id": "223", "gold": 14, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141010, "vid": 14943445328940005, "good_id": "223", "gold": 40, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141011, "vid": 14943445328940006, "good_id": "223", "gold": 10, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141012, "vid": 14943445328940006, "good_id": "223", "gold": 39, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141013, "vid": 14943445328940007, "good_id": "223", "gold": 46, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141014, "vid": 14943445328940007, "good_id": "223", "gold": 31, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141015, "vid": 14943445328940008, "good_id": "223", "gold": 3, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141016, "vid": 14943445328940008, "good_id": "223", "gold": 47, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141017, "vid": 14943445328940009, "good_id": "223", "gold": 49, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141018, "vid": 14943445328940009, "good_id": "223", "gold": 7, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141019, "vid": 14943445328940010, "good_id": "223", "gold": 20, "timestamp": 1494344574, "type": "gift_record"}
{"uid": 720123141020, "vid": 14943445328940010, "good_id": "223", "gold": 28, "timestamp": 1494344574, "type": "gift_record"}video_info.log
video_info.log
{"uid": 840717325101, "vid": 14943445328940001, "area": "US", "status": "1", "watch_num": 257, "share_num": 729, "type": "video_info"}
{"uid": 840717325102, "vid": 14943445328940002, "area": "CN", "status": "1", "watch_num": 58, "share_num": 271, "type": "video_info"}
{"uid": 840717325103, "vid": 14943445328940003, "area": "CN", "status": "1", "watch_num": 533, "share_num": 399, "type": "video_info"}
{"uid": 840717325104, "vid": 14943445328940004, "area": "CN", "status": "1", "watch_num": 312, "share_num": 293, "type": "video_info"}
{"uid": 840717325105, "vid": 14943445328940005, "area": "ID", "status": "1", "watch_num": 416, "share_num": 88, "type": "video_info"}
{"uid": 840717325106, "vid": 14943445328940006, "area": "ID", "status": "1", "watch_num": 355, "share_num": 654, "type": "video_info"}
{"uid": 840717325107, "vid": 14943445328940007, "area": "CN", "status": "1", "watch_num": 397, "share_num": 383, "type": "video_info"}
{"uid": 840717325108, "vid": 14943445328940008, "area": "CN", "status": "1", "watch_num": 425, "share_num": 873, "type": "video_info"}
{"uid": 840717325109, "vid": 14943445328940009, "area": "ID", "status": "1", "watch_num": 80, "share_num": 124, "type": "video_info"}
{"uid": 840717325110, "vid": 14943445328940010, "area": "CN", "status": "1", "watch_num": 96, "share_num": 740, "type": "video_info"}A:
- 首先获取两份数据中的核心字段,使用fastjson包解析数据
主播开播记录(video_info.log):主播ID uid,直播间ID vid,大区 area
(vid, (uid, area))
用户送礼记录(gift_info.log):直播间ID vid,金币数量 gold
(vid, gold)
这样可以把这两份数据关联到一起 - 对送礼记录进行聚合,对相同vid的数据求和 (vid, gold_sum)
- 将两份数据join 到一起, vid 作为 join 的 key
(vid, ((uid, area), gold_sum)) - 使用 map 迭代 join 后的数据,最后获取到 uid area gold_sum 字段
由于一个主播一天可能开播多次,后面要基于 uid 和 area 再做一次聚合,uid 和 area 是一一对应的
((uid, area), gold_sum) - 使用 reduceByKey 算子对数据进行聚合
((uid, area), gold_sum_all) - 接下来针对大区进行分组,先用map 转换形式,再使用 groupByKey 对数据分组
(area, (uid, gold_sum_all))
area, [(uid, gold_sum_all),(uid, gold_sum_all),(uid, gold_sum_all)] - 使用map迭代每个分组内数据,按照金币数量倒序排序,取前N个,最后输出 (area, TopN)。TopN 就是主播id与金币数量拼成的字符串
- 使用 foreach 进行打印
package org.example
import com.alibaba.fastjson.JSON
import org.apache.spark.{SparkConf, SparkContext}
object TopNScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TopNScala").setMaster("local")
val sc = new SparkContext(conf)
// 1. 首先获取两份数据中的核心字段,使用fastjson包解析数据
val videoInfoRDD = sc.textFile("C:\\code\\video_info.log")
val giftRecordRDD = sc.textFile("C:\\code\\gift_record.log")
val videoInfoFieldRDD = videoInfoRDD.map(line => {
val jsonObj = JSON.parseObject(line)
val vid = jsonObj.getString("vid")
val uid = jsonObj.getString("uid")
val area = jsonObj.getString("area")
(vid, (uid, area))
})
val giftRecordFieldRDD = giftRecordRDD.map(line => {
val jsonObj = JSON.parseObject(line)
val vid = jsonObj.getString("vid")
val gold = jsonObj.getInteger("gold")
(vid, gold)
})
// 2. 对送礼记录进行聚合,对相同vid的数据求和 (vid, gold_sum)
val giftRecordFieldAggRDD = giftRecordFieldRDD.reduceByKey(_ + _)
// 3. 将两份数据join 到一起, vid 作为 join 的 key
// (vid, ((uid, area), gold_sum))
val rdd = videoInfoFieldRDD.join(giftRecordFieldAggRDD)
// 4. 使用 map 迭代 join 后的数据,最后获取到 uid area gold_sum 字段
// ((uid, area), gold_sum)
val joinMapRDD = rdd.map(tup => {
// tup: (vid, ((uid, area), gold_sum))
val uid = tup._2._1._1
val area = tup._2._1._2
val gold_sum = tup._2._2
((uid, area), gold_sum)
})
// 5. 使用 reduceByKey 算子对数据进行聚合
val reduceRDD = joinMapRDD.reduceByKey(_ + _)
// 6. 接下来针对大区进行分组,先用map 转换形式,再使用 groupByKey 对数据分组
// map: (area, (uid, gold_sum_all))
// groupByKey: area, [(uid, gold_sum_all),(uid, gold_sum_all),(uid, gold_sum_all)]
val groupRDD = reduceRDD.map(tup => (tup._1._2, (tup._1._1, tup._2))).groupByKey()
// 7. 使用map迭代每个分组内数据,按照金币数量倒序排序,取前N个,最后输出 (area, TopN)。TopN 就是主播id与金币数量拼成的字符串
val top3RDD = groupRDD.map(tup => {
val area = tup._1
// uid:gold_sum_all,uid:gold_sum_all,uid:gold_sum_all
val top3 = tup._2
.toList // 把 iterable 转为list
.sortBy(_._2)
.reverse // 默认升序,这里反转为降序
.take(3)
.map(tup => tup._1 + ":" + tup._2).mkString(",")
(area, top3)
})
// 8. 打印
top3RDD.foreach(tup => println(tup._1 + "\t" + tup._2))
sc.stop()
}
}
sortByKey 如何实现全局排序?
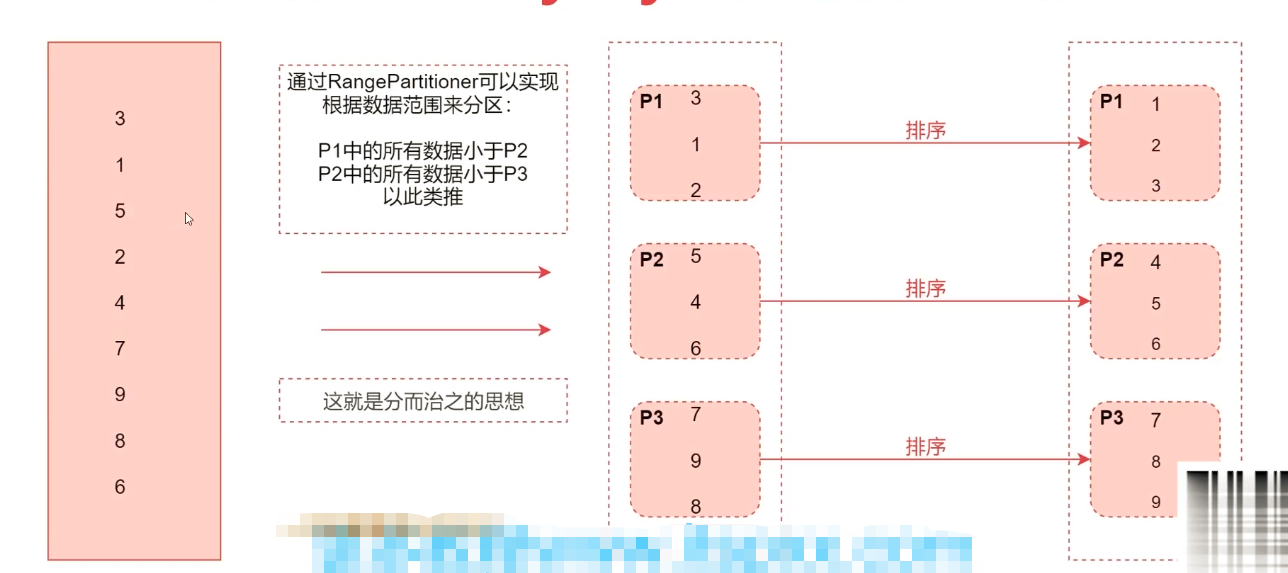
如何使用32G内存的服务器排序1T数据?
将数据按照大小分为32G,每份在内存内排序然后按序输出到文件中,排序后的文件就是有序数据。
