

elasticsearch 基础
Elasticsearch
一个开源的分布式搜索和分析引擎。可以快速存储、搜索、分析数据。提供服务的http端口为 9200,集群间通信端口为 9300。kibana的http服务端口为 5601。
基本概念
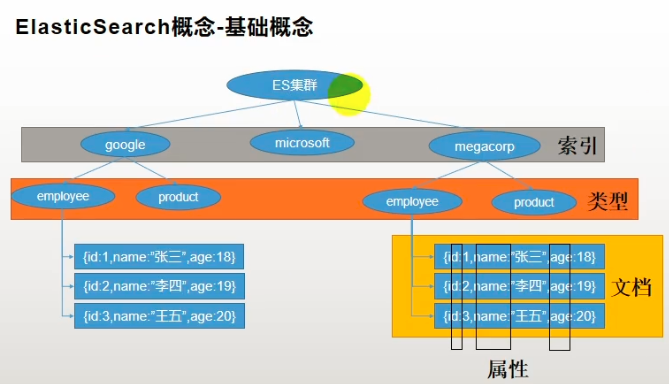
- index 索引
当动词时类似mysql的 insert,当名词类似mysql的 database。 - type 类型(被移除)
类似mysql的 table - filed 字段
- mapping 映射
- document 文档
类似mysql中的一条记录,单es中存储的是数据 - cluster 集群
- node 节点
- shards&replicas 分片和复制
倒排索引
- 正排索引:是以文档对象的唯一 ID 作为索引,以文档内容作为记录的结构。类似mysql通过id检索记录。
- 倒排索引:Inverted index,指的是将文档内容中的单词作为索引,将包含该词的文档 ID 作为记录的结构。通过记录的内容检索id。
例如一张正排索引表
| id | 年龄 | 性别 |
| 1 | 18 | 女 |
| 2 | 18 | 男 |
| 3 | 20 | 女 |
倒排索引表
年龄倒排
| 年龄 | 用户id |
| 18 | [1, 2] |
| 20 | [3] |
性别倒排
| 性别 | 用户id |
| 女 | [1, 3] |
| 男 | [2] |
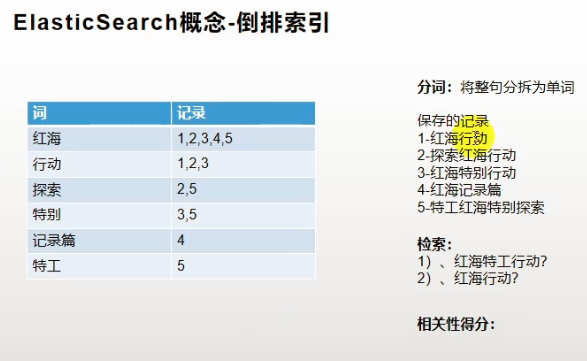
在使用es进行搜索的时候会先将目标分词,然后在倒排索引表中索引关键词获得记录id。例如检索 1) 红海特工行动 拆分为“红海”“特工”“行动”,通过检索得到12354都满足要求,但得分并不相同。
启动es前配置:
# jvm.options
-Xms128m
-Xmx128m
# elasticsearch.yml
network.host: 0.0.0.0
discovery.seed_hosts: ["127.0.0.1"]
cluster.initial_master_nodes: ["node-1"]相关命令:
查询自身信息
GET http://127.0.0.1:9200/_cat # 查询节点相关信息
GET /_cat/nodes # 查询所有节点
GET /_cat/health # 查看es健康状态
GET /_cat/master # 查看主节点
GET /_cat/indices # 查看所有索引保存
POST /customer/external/1 # 在customer索引下的external类型下保存唯一标识为1的数据
{"name": "xxx"}
POST /<index>/<type> # post 方式可以不指定id
{"data": "json"}
### 返回结果
{ # 新增
"_index": "index",
"_type": "type",
"_id": "HoZ-FYEBtZh189LgJVd1", # 自动生成的 id
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 11,
"_primary_term": 1
}修改
PUT /<index>/<type>/<id> # 使用put方式必须指定id,否则报错
POST /<index>/<type>/<id> # 这两种方式内容不用带"doc",且不会检查数据是否变化直接更新数据
POST /<index>/<type>/<id>/_update # 带有_update时,内容的"doc"一定不能少。
{ # 此时如果更新内容与原内容相同,版本号序列号不会变。
"doc": {
"key": "value"
}
}
### 返回结果
{ # 带下划线的都是元数据
"_index": "index", # 索引名
"_type": "type", # 类型名
"_id": "1", # 唯一标志
"_version": 2, # 版本,初始为1,每次修改都加1
"result": "updated", # 是 created 还是 updated
"_shards": { # 分片,集群中使用
"total": 2,
"successful": 1,
"failed": 0
},
# 这两个用于进行乐观锁操作
"_seq_no": 5,
"_primary_term": 1
}查询
GET /<index>/<type>/<id> # 通过id查询信息
{
"_index": "index",
"_type": "type",
"_id": "1",
"_version": 2,
"_seq_no": 5, # 并发控制,每次更新都会加1,用于乐观锁
"_primary_term": 1, # 同上,主分片重新分配,如重启,就会发生变化
"found": true,
"_source": {
"name": "jack"
}
}删除
DELETE /<index> # 删除索引
DELETE /<index>/<type>/<id> # 删除指定id的数据
{
"_index": "index",
"_type": "type",
"_id": "1",
"_version": 3,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 12,
"_primary_term": 1
}批量导入数据
POST /<index>/<type>/_bulk # 在指定索引指定类型做批量操作
{"index": {"_id": "1"}} # 保存索引为1的数据
{"name": "John Doe"} # 要保存的本条数据
{"index": {"_id": "2"}} # 保存索引为2的数据
{"name": "John Doe"} # 要保存的本条数据
## 语法格式
{action: {metadata}}
{request body}
### 响应
{
"took" : 109,
"errors" : false,
"items" : [ # 每条数据的操作分开统计,一个失败不会导致下一个失败
{
"index" : { # 第一条记录 index 操作
"_index" : "index",
"_type" : "type",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 13,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : { # 第二条记录 index 操作
"_index" : "index",
"_type" : "type",
"_id" : "2",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 14,
"_primary_term" : 1,
"status" : 201
}
}
]
}
POST /_bulk # 不指定index type,而是在请求体中指定。下面是4个独立的操作
{"delete": {"_index": "website", "_type": "blog", "_id": "123"}}
{"create": {"_index": "website", "_type": "blog", "_id": "123"}}
{"title": "My first blog post"}
{"index": {"_index": "website", "_type": "blog"}}
{"title": "My second blog post"}
{"update": {"_index": "website", "_type": "blog", "_id": "123"}}
{"doc": {"title": "My update blog post"}}使用官方的测试数据
https://github.com/elastic/elasticsearch/blob/v6.8.18/docs/src/test/resources/accounts.json
POST /bank/account/_bulk
{'json': "官方数据"}乐观锁操作
每条记录的 _seq_no 随着每次改变数据而变化,_primary_term 随着集群的变化而变化。保证这二者不变就是保证了数据没有被其他用户操作
# 只有当二者为预期值,即在上次请求后数据没有改变才进行更新
PUT /<index>/<type>/<id>?if_seq_no=5&if_primary_term=1
进阶检索
GET /<index>/_seatch # 检索<index>下所有信息,包括type和docs
两种检索方式:
- 通过url的请求参数检索
- 使用 request body 发送请求
使用url参数
GET bank/_search?q=*&sort=account_number:asc
请求参数:
- q=* 查询关键字为所有
- sort=account_number:asc 按照account_number递增排序
返回结果:
查询结果
{
"took": 5, // 使用5毫秒
"timed_out": false, // 没有超时
"_shards": { // 集群中分片操作
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": { // 命中记录
"total": {
"value": 12, // 命中多少
"relation": "eq"
},
"max_score": 1.0, // 最大得分
"hits": [ // 记录,默认一次返回10条记录,类似mysql的分页查询
{
"_index": "index",
"_type": "type",
"_id": "FYZzFYEBtZh189LgVFew",
"_score": 1.0,
"_source": {
"name": "jack"
}
},
{
"_index": "index",
"_type": "type",
"_id": "FoZzFYEBtZh189LgsVde",
"_score": 1.0,
"_source": {
"name": "jack"
}
},
{
"_index": "index",
"_type": "type",
"_id": "F4Z0FYEBtZh189Lg3Veq",
"_score": 1.0,
"_source": {
"name": "jack"
}
}
]
}
}使用请求体
Query DSL https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html
GET /<index>/_search
{
"query": { // 查询条件
"match_all": {}
},
"sort": [ // 排序条件
{ "attr_name": "asc" }
],
"from": 10,
"size": 10, // 从10到19号数据
}DSL 格式
{
"query": {
"match_all": {},
// 查文本使用 match
"match": {
// 查询非字符串时为精准匹配
"<field_name>": 20,
// 文本的精确匹配
"<field_name>.keyword": "xxx",
// 查询字符串时为全文检索,对检索条件分词匹配,根据匹配程度得分不尽相同
"<field_name>": "text1 text2"
},
// 不会分词,把查询条件当作一个短语,短语匹配,包含这个字符串即可
"match_phrase": {
"<field_name>": "xxx yyy"
},
// state或address字段包含xxx,对条件进行了分词
"multi_match": {
"query": "xxx",
"fields": ["state", "address"]
},
// 查数字等非文本使用 term
// 与match类似,但推荐用于精确匹配,match用于全文检索
"term": {"age": 18},
// 构造复杂查询
"bool": {
"must": [
{"match": {"address": "mill"}},
{"range":
{"age":
{
"gte": 18,
"lte": 30
}
}
}
],
"must_not": [
{"match": {"state": "ID"}}
],
"should": [
{"match": {"field_name": "xxx"}}
],
// 过滤器,与 must must_not 类似,但是不会影响相关性得分
"filter": {
{"match": {"address": "mill"}},
{"range":
{"age":
{
"gte": 18,
"lte": 30
}
}
}
}
}
},
"from": 0,
"size": 5,
"sort": [
{
"field_name": {
"order": "desc/asc"
}
}
],
"_source": ["age", "balance"] // 只返回部分字段
}
聚合 aggregations
从数据中分组和提取数据的能力,类似 sql 中的 group by 和 sql 聚合函数。es中将命中结果hits中的数据聚合,并把一个响应中所有hits分隔开的能力。
{
"query": {},
"aggs": {
"<aggregation_name>": { // 给聚合起个名
"<aggregation_type>": {
<aggregation_body>
}
[, "meta" : { [<meta_data_body>] }]? // 可以指定元数据
[, "aggregations" : { [<sub_aggregation>]+ }]? // 在聚合的基础上继续聚合
}
[, "<aggregation_name_2>" : {...}]* // 第二个聚合
}
}例子:
查看代码
GET /bank/_search
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": {
"ageAgg": {
"terms": { // 展示有多少个不同值
"field": "age",
"size": 10 // 最多展示10条
}
},
"group_by": {
"terms": {
"field": "account_number"
}
},
"avg_age": {
"avg": {
"field": "age"
}
}
},
"size": 0 // 不看查询到的结果
}
// 返回结果
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 5.4032025,
"hits": [ ] // 通过指定siz为0不查看数据
},
// 返回的聚合结果
"aggregations": {
"avg_age": {
"value": 34.0
},
"ageAgg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 38,
"doc_count": 2
},
{
"key": 28,
"doc_count": 1
},
{
"key": 32,
"doc_count": 1
}
]
},
"group_by": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 136,
"doc_count": 1
},
{
"key": 345,
"doc_count": 1
},
{
"key": 472,
"doc_count": 1
},
{
"key": 970,
"doc_count": 1
}
]
}
}
}查询不同年龄段的人的平均薪资
查看代码
// 复合聚合
{
"query": {
"match_all": {
}
},
"size": 0,
"aggs": {
"ageAgg": {
"terms":{
"field": "age",
"size": 100
},
"aggs": {
"ageAvg": {
"avg": {
"field": "balance"
}
}
}
}
}
}
// 结果
{
"took": 16,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1000,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"ageAgg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{ // 年龄为31的共有61人,平均工资 28312.918032786885
"key": 31,
"doc_count": 61,
"ageAvg": {
"value": 28312.918032786885
}
},
{
"key": 39,
"doc_count": 60,
"ageAvg": {
"value": 25269.583333333332
}
},
{
"key": 26,
"doc_count": 59,
"ageAvg": {
"value": 23194.813559322032
}
},
{
"key": 32,
"doc_count": 52,
"ageAvg": {
"value": 23951.346153846152
}
},
{
"key": 35,
"doc_count": 52,
"ageAvg": {
"value": 22136.69230769231
}
},
{
"key": 36,
"doc_count": 52,
"ageAvg": {
"value": 22174.71153846154
}
},
{
"key": 22,
"doc_count": 51,
"ageAvg": {
"value": 24731.07843137255
}
},
{
"key": 28,
"doc_count": 51,
"ageAvg": {
"value": 28273.882352941175
}
},
{
"key": 33,
"doc_count": 50,
"ageAvg": {
"value": 25093.94
}
},
{
"key": 34,
"doc_count": 49,
"ageAvg": {
"value": 26809.95918367347
}
},
{
"key": 30,
"doc_count": 47,
"ageAvg": {
"value": 22841.106382978724
}
},
{
"key": 21,
"doc_count": 46,
"ageAvg": {
"value": 26981.434782608696
}
},
{
"key": 40,
"doc_count": 45,
"ageAvg": {
"value": 27183.17777777778
}
},
{
"key": 20,
"doc_count": 44,
"ageAvg": {
"value": 27741.227272727272
}
},
{
"key": 23,
"doc_count": 42,
"ageAvg": {
"value": 27314.214285714286
}
},
{
"key": 24,
"doc_count": 42,
"ageAvg": {
"value": 28519.04761904762
}
},
{
"key": 25,
"doc_count": 42,
"ageAvg": {
"value": 27445.214285714286
}
},
{
"key": 37,
"doc_count": 42,
"ageAvg": {
"value": 27022.261904761905
}
},
{
"key": 27,
"doc_count": 39,
"ageAvg": {
"value": 21471.871794871793
}
},
{
"key": 38,
"doc_count": 39,
"ageAvg": {
"value": 26187.17948717949
}
},
{
"key": 29,
"doc_count": 35,
"ageAvg": {
"value": 29483.14285714286
}
}
]
}
}
}查看不同年龄、不同性别的人的平均工资
查看代码
{
"query": {
"match_all": {
}
},
"size": 0,
"aggs": {
"ageAgg": {
"terms":{
"field": "age",
"size": 3
},
"aggs": {
"genderAgg": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
},
"ageBalanceAvg": {
"avg": {
"field": "balance"
}
}
}
}
}
}
// 响应结果
{
"took": 32,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1000,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"ageAgg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 820,
"buckets": [
{
"key": 31,
"doc_count": 61,
"genderAgg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "M",
"doc_count": 35,
"balanceAvg": {
"value": 29565.628571428573
}
},
{
"key": "F",
"doc_count": 26,
"balanceAvg": {
"value": 26626.576923076922
}
}
]
},
"ageBalanceAvg": {
"value": 28312.918032786885
}
},
{
"key": 39,
"doc_count": 60,
"genderAgg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "F",
"doc_count": 38,
"balanceAvg": {
"value": 26348.684210526317
}
},
{
"key": "M",
"doc_count": 22,
"balanceAvg": {
"value": 23405.68181818182
}
}
]
},
"ageBalanceAvg": {
"value": 25269.583333333332
}
},
{
"key": 26,
"doc_count": 59,
"genderAgg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "M",
"doc_count": 32,
"balanceAvg": {
"value": 25094.78125
}
},
{
"key": "F",
"doc_count": 27,
"balanceAvg": {
"value": 20943.0
}
}
]
},
"ageBalanceAvg": {
"value": 23194.813559322032
}
}
]
}
}
}
Mapping 映射
定义文档和字段如何被存储和索引的。一般不指定,在第一次保存时有es推断。例如:
- 哪些字符串字段应该被全文检索
- 哪些字段包含数字、日期、地理信息
- 如何格式化字符串
查看 mapping 信息:
GET 127.0.0.1:9200/bank/_mapping
{
"bank": {
"mappings": {
"properties": {
"account_number": {
"type": "long"
},
"address": {
"type": "text",
"fields": {
"keyword": { // keyword 子属性,用于精确查询
"type": "keyword",
"ignore_above": 256
}
}
},
"age": {
"type": "long"
},
"balance": {
"type": "long"
},
"city": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"email": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
指定索引映射
创建索引时指定映射
PUT /my-index-name
{
"mappings": {
"properties": {
"age": {"type": "integer"},
"email": {"type": "keyword"},
"name": {"type": "text"}
}
}
}
// 成功创建索引,并指定索引下的映射
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "my_index"
}新增映射
PUT 127.0.0.1:9200/my_index/_mapping
{
"properties": {
"employee-id": {
"type": "keyword",
"index": false // 不被索引不能用于检索数据,默认为true
}
}
}
// 新增成功
{
"acknowledged": true
}对已创建的映射无法更新,只能删除旧索引创建新新索引。这个过程称为数据迁移。
数据迁移
// 处理新版
POST /_reindex // 固定写法
{
"source": {
"index": "old"
},
"dest": {
"index": "new"
}
}
// 带有type的旧版
{
"source": {
"index": "twitter",
"type": "tweet"
},
"dest": {
"index": "tweets"
}
}
分词
默认分词功能不支持中文
POST _analyze
{
"analyzer": "standard", // 自带的标准分词功能,对英文效果好
"text": "This is a text."
}到 https://github.com/medcl/elasticsearch-analysis-ik 下载与es版本一致的插件,解压到 ES_HOME/plugins/ik 目录下。
ik 有两种模式, ik_smart 和 ik_max_word 两种。
- ik_smart 最粗粒度的拆分,把一句话拆分
- ik_max_word 最细粒度的拆分,找到一句话中的所有单词
GET my_index/_analyze
{
"analyzer": "ik_smart",
"text": "这是一个分词器"
}
GET my_index/_analyze
{
"analyzer": "ik_max_word",
"text": "这个一个分词器"
}词库是有限的,可以自行拓展词库。在 ES_HOME/plugins/ik/config/IKAnalyzer.cfg 中配置,内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"> <!-- 本地dic文件名 --> </entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location 例如 "http://192.168.15.110" 由nginx动态提供字典 </entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
java 操作
https://www.elastic.co/guide/en/elasticsearch/client/index.html
<dependencies>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.15.1</version> <!-- 这个版本号要与es的版本一致 -->
</dependency>
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>7.15.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.12.3</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.12.3</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.12.3</version>
</dependency>
<dependency>
<groupId>jakarta.json</groupId>
<artifactId>jakarta.json-api</artifactId>
<version>2.0.1</version>
</dependency>
</dependencies>创建索引
ElasticsearchClient client = ...
client.indices().create(c -> c.index("products"));保存单个对象
Product product = new Product("bk-1", "City bike", 123.0);
IndexResponse response = esClient.index(i -> i
.index("products")
.id(product.getSku())
.document(product)
);批量保存对象
List<Product> products = fetchProducts();
BulkRequest.Builder br = new BulkRequest.Builder();
for (Product product : products) {
br.operations(op -> op
.index(idx -> idx
.index("products")
.id(product.getSku())
.document(product)
)
);
}
BulkResponse result = esClient.bulk(br.build());
// Log errors, if any
if (result.errors()) {
logger.error("Bulk had errors");
for (BulkResponseItem item: result.items()) {
if (item.error() != null) {
logger.error(item.error().reason());
}
}
}通过id获取对象
GetResponse<Product> response = esClient.get(g -> g
.index("products")
.id("bk-1"),
Product.class
);
if (response.found()) {
Product product = response.source();
logger.info("Product name " + product.getName());
} else {
logger.info ("Product not found");
}简单搜索
SearchResponse<Product> search = client.search(s -> s
.index("products")
.query(q -> q
.term(t -> t
.field("name")
.value(v -> v.stringValue("bicycle"))
)),
Product.class);
for (Hit<Product> hit: search.hits().hits()) {
processProduct(hit.source());
}String searchText = "bike";
SearchResponse<Product> response = esClient.search(s -> s
.index("products")
.query(q -> q
.match(t -> t
.field("name")
.query(searchText)
)
),
Product.class
);
TotalHits total = response.hits().total();
boolean isExactResult = total.relation() == TotalHitsRelation.Eq;
if (isExactResult) {
logger.info("There are " + total.value() + " results");
} else {
logger.info("There are more than " + total.value() + " results");
}
List<Hit<Product>> hits = response.hits().hits();
for (Hit<Product> hit: hits) {
Product product = hit.source();
logger.info("Found product " + product.getSku() + ", score " + hit.score());
}嵌套搜索
String searchText = "bike";
double maxPrice = 200.0;
// Search by product name
Query byName = MatchQuery.of(m -> m
.field("name")
.query(searchText)
)._toQuery();
// Search by max price
Query byMaxPrice = RangeQuery.of(r -> r
.field("price")
.gte(JsonData.of(maxPrice))
)._toQuery();
// Combine name and price queries to search the product index
SearchResponse<Product> response = esClient.search(s -> s
.index("products")
.query(q -> q
.bool(b -> b
.must(byName)
.must(byMaxPrice)
)
),
Product.class
);
List<Hit<Product>> hits = response.hits().hits();
for (Hit<Product> hit: hits) {
Product product = hit.source();
logger.info("Found product " + product.getSku() + ", score " + hit.score());
}聚合操作
String searchText = "bike";
Query query = MatchQuery.of(m -> m
.field("name")
.query(searchText)
)._toQuery();
SearchResponse<Void> response = esClient.search(b -> b
.index("products")
.size(0)
.query(query)
.aggregations("price-histogram", a -> a
.histogram(h -> h
.field("price")
.interval(50.0)
)
),
Void.class
);
List<HistogramBucket> buckets = response.aggregations()
.get("price-histogram")
.histogram()
.buckets().array();
for (HistogramBucket bucket: buckets) {
logger.info("There are " + bucket.docCount() +
" bikes under " + bucket.key());
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!