
Shuffle
Shuffle
将数据从map端拷贝到reduce端的过程。
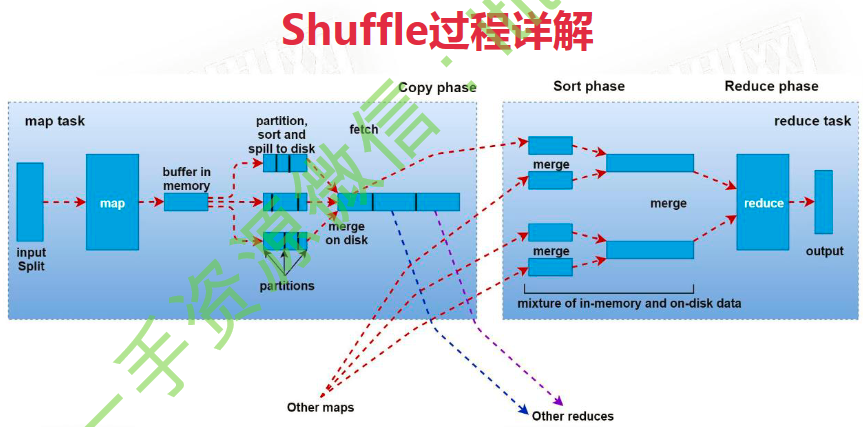
- map生成的数据会放入内存缓冲区,大小为100M,当达到80M时溢写到磁盘中。直到map把数据计算完,然后将缓存中数据也保存到磁盘中。当map生成的数据存在分区时,磁盘中保存的数据也会分区。
- 本地文件合并,图中存在3个分区。
- 这3个分区会被shuffle线程分别复制到不同reduce节点上。不同Map节点的相同分区的数据会合并到一个Reduce节点上。
Hadoop 序列化
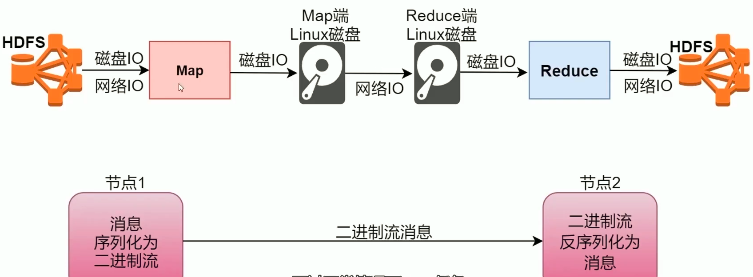
Map程序从HDFS读取数据、写入本地磁盘,Shuffle程序拷贝数据,Reduce程序读取数据、写入HDFS 都会涉及到磁盘IO 甚至网络IO。可见IO占用的比重非常高。IO步骤无法省略,所以为了加速而优化序列化操作。
默认情况下,java会把整个对象的信息以及父类的信息进行保存,这样会额外消耗性能。Hadoop为了效率自己设计了一套序列化机制
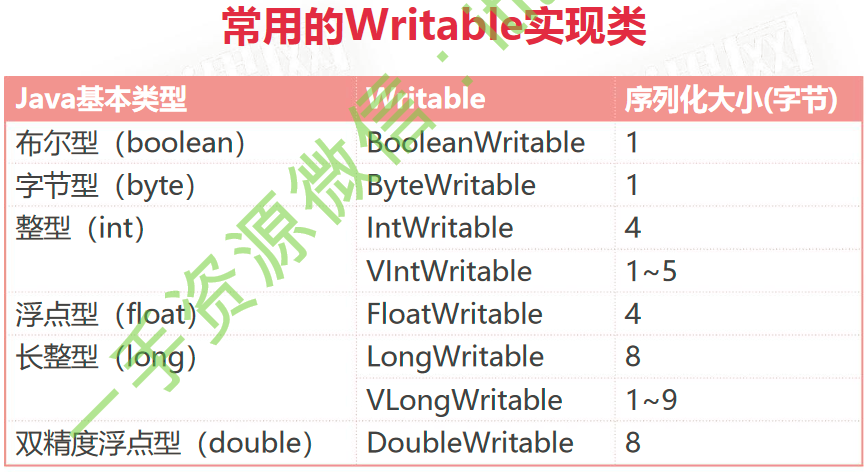
补充:
- Text 等价于 java.lang.String 的Writable,针对 UTF-8 序列
- NullWritable 是单例,获取实例使用 NullWritable.get()
这些类都实现了这个接口
public interface WritableComparable<T> extends Writable, Comparable<T> {
}Hadoop 序列化特点:
- 紧凑 高效利用空间
- 快速 读写数据额外开销小
- 可拓展 可透明地读取老格式地数据
- 互操作 支持多语言地交互
java 序列化地不足:
- 不精简,附加信息多,不太适合随机访问
- 存储空间大,递归地输出类的父类描述,直到不再有父类
/**
* 分别使用java自带的序列化方法和hadoop自定义的序列化方法,比较二进制文件的大小
*/
package org.example.mapreduce;
import org.apache.hadoop.io.Writable;
import java.io.*;
public class TestSerialize {
public static void main(String[] args) {
SerializeJava java = new SerializeJava();
java.setId(1L);
java.setName("123");
try(FileOutputStream fileOutputStream = new FileOutputStream("C:\\code\\java");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream)) {
objectOutputStream.writeObject(java);
} catch (Exception e) {
e.printStackTrace();
}
SerializeHadoop hadoop = new SerializeHadoop();
hadoop.setId(1L);
hadoop.setName("123");
try(FileOutputStream fileOutputStream = new FileOutputStream("C:\\code\\hadoop");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream)) {
hadoop.write(objectOutputStream);
} catch (Exception e) {
e.printStackTrace();
}
}
}
@Data
class SerializeJava implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;
private String name;
}
@Data
class SerializeHadoop implements Writable { // 如果需要排序则实现 WritableComparable
private Long id;
private String name;
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(this.id);
out.writeUTF(this.name);
}
@Override
public void readFields(DataInput in) throws IOException {
// 注意:读取属性的顺序要与写属性的顺序一致
this.id = in.readLong();
this.name = in.readUTF();
}
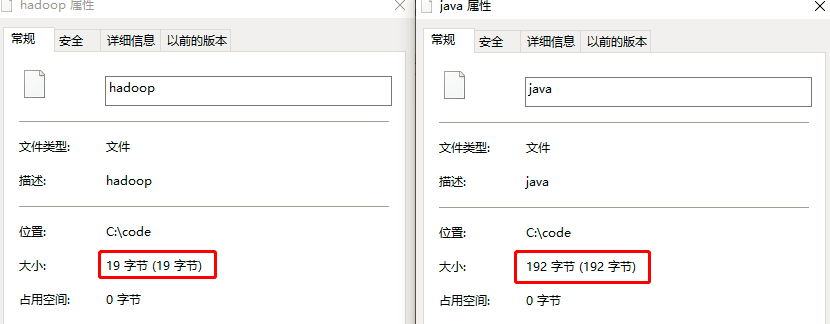
}可见使用 Writable 序列化的文件远小于 java 原生的序列化
InputFormat 分析
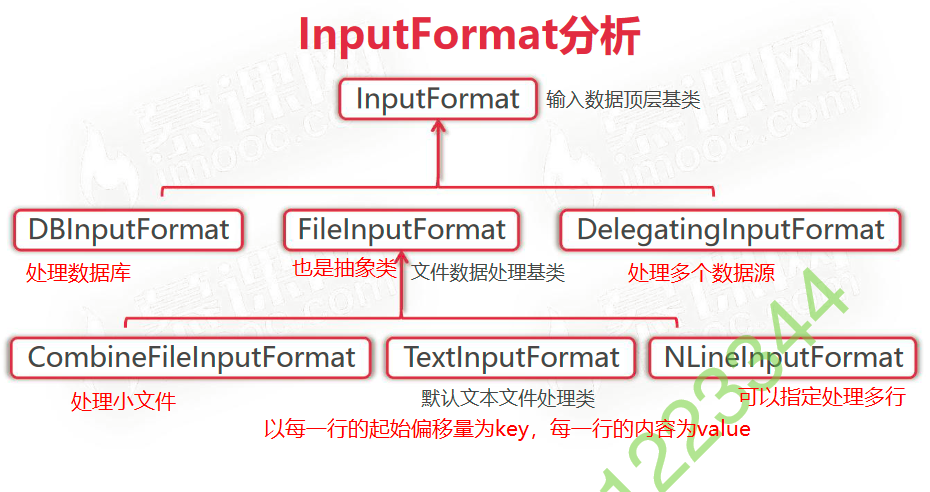
这是一个抽象类,是MapReduce输入数据的顶层基类。
@Public
@Stable
public abstract class InputFormat<K, V> {
public InputFormat() {
}
// 逻辑切分输入文件
public abstract List<InputSplit> getSplits(JobContext var1) throws IOException, InterruptedException;
// 为每一行创建一个行阅读器。在开始分割之前会调用 RecordReader 的 initialize(InputSplit, TaskAttemptContext) 方法
// 每一个InputSplit都有一个RecordReader,作用是把InputSplit中的数据解析成Record,即<k1, v1>
public abstract RecordReader<K, V> createRecordReader(InputSplit var1, TaskAttemptContext var2) throws IOException, InterruptedException;
}FileInputFormat 对getSplits 的实现如下:
public class FileInputFormat {
/**
* Generate the list of files and make them into FileSplits.
* @param job the job context
* @throws IOException
*/
public List<InputSplit> getSplits(JobContext job) throws IOException {
StopWatch sw = new StopWatch().start();
// 获取分割任务的最小最大值
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
// 创建List,用于保存生成的 InputSplit
List<InputSplit> splits = new ArrayList<InputSplit>();
// 获取输入文件列表
List<FileStatus> files = listStatus(job);
// 标记是否忽略目录
boolean ignoreDirs = !getInputDirRecursive(job)
&& job.getConfiguration().getBoolean(INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS, false);
// 迭代输入文件列表
for (FileStatus file: files) {
// 是否忽略子目录,默认不忽略
if (ignoreDirs && file.isDirectory()) {
continue;
}
// 获取文件或目录的路径
Path path = file.getPath();
// 获取文件或目录的长度
long length = file.getLen();
// 如果是文件
if (length != 0) {
// 用于保存文件Block块所在位置的数组
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
// 判断文件是否支持切割,默认为true
if (isSplitable(job, path)) {
// 获取文件Block大小,默认128M
long blockSize = file.getBlockSize();
// 计算split大小,默认split逻辑切片的大小和Block size相等
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
// 待处理的文件剩余字节大小,也就是这个文件的原始大小
long bytesRemaining = length;
// SPLIT_SLOP=1.1,当剩余文件的大小与splitSize的比值还大于1.1时旧继续切分,否则直接作为下一个InputSplit
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
// 生成split并添加到数组中
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
// 处理最后一块数据
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // 如果是压缩文件,不支持切割
if (LOG.isDebugEnabled()) {
// Log only if the file is big enough to be splitted
if (length > Math.min(file.getBlockSize(), minSize)) {
LOG.debug("File is not splittable so no parallelization "
+ "is possible: " + file.getPath());
}
}
// 不支持切割,则把整个文件作为一个InputSplit
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits;
}
}TextInputFormat中的createRecordReader的实现
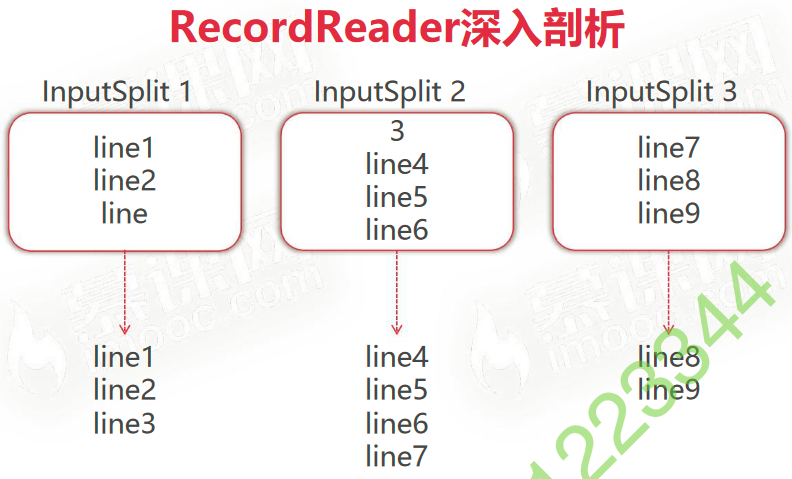
/*
Q 文件会被切分为block块,如果一行文本被分割到了不同的block,如何处理?由哪一个InputSplit处理?
A 会被前一个InputSplit处理
*/
public class TextInputFormat extends FileInputFormat<LongWritable, Text> {
// 针对每一个InputSplit都会创建一个RecordReader
@Override
public RecordReader<LongWritable, Text>
createRecordReader(InputSplit split,
TaskAttemptContext context) {
// 获取换行符,默认没有配置
String delimiter = context.getConfiguration().get(
"textinputformat.record.delimiter");
byte[] recordDelimiterBytes = null;
if (null != delimiter)
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
// 创建一个阅读器
return new LineRecordReader(recordDelimiterBytes);
}
}
public class LineRecordReader extends RecordReader<LongWritable, Text> {
// 初始化方法,框架再调用split之前调用
public void initialize(InputSplit genericSplit,
TaskAttemptContext context) throws IOException {
// 获取传来的InputSplit,将其转为子类FileSplit
FileSplit split = (FileSplit) genericSplit;
Configuration job = context.getConfiguration();
// MAX_LINE_LENGTH 默认没有配置,所以默认会取 Integer.MAX_VALUE
this.maxLineLength = job.getInt(MAX_LINE_LENGTH, Integer.MAX_VALUE);
// 获取起始位置
start = split.getStart();
// 获取结束位置
end = start + split.getLength();
// 获取 InputSplit 的路径
final Path file = split.getPath();
// open the file and seek to the start of the split
final FutureDataInputStreamBuilder builder =
file.getFileSystem(job).openFile(file);
FutureIOSupport.propagateOptions(builder, job,
MRJobConfig.INPUT_FILE_OPTION_PREFIX,
MRJobConfig.INPUT_FILE_MANDATORY_PREFIX);
fileIn = FutureIOSupport.awaitFuture(builder.build());
// 获取文件的压缩信息
CompressionCodec codec = new CompressionCodecFactory(job).getCodec(file);
// 如果是压缩文件,则执行以下语句
if (null!=codec) {
isCompressedInput = true;
decompressor = CodecPool.getDecompressor(codec);
if (codec instanceof SplittableCompressionCodec) {
final SplitCompressionInputStream cIn =
((SplittableCompressionCodec)codec).createInputStream(
fileIn, decompressor, start, end,
SplittableCompressionCodec.READ_MODE.BYBLOCK);
in = new CompressedSplitLineReader(cIn, job,
this.recordDelimiterBytes);
start = cIn.getAdjustedStart();
end = cIn.getAdjustedEnd();
filePosition = cIn;
} else {
if (start != 0) {
// So we have a split that is only part of a file stored using
// a Compression codec that cannot be split.
throw new IOException("Cannot seek in " +
codec.getClass().getSimpleName() + " compressed stream");
}
in = new SplitLineReader(codec.createInputStream(fileIn,
decompressor), job, this.recordDelimiterBytes);
filePosition = fileIn;
}
} else { // 如果是非压缩文件则跳转到此处
fileIn.seek(start);
// 针对未压缩文件,创建一个阅读器读取一行一行的数据
in = new UncompressedSplitLineReader(
fileIn, job, this.recordDelimiterBytes, split.getLength());
filePosition = fileIn;
}
// If this is not the first split, we always throw away first record
// because we always (except the last split) read one extra line in
// next() method. 因为 next() 会多读取一行,所以一行数据被拆分到两个InputSplit中也没有问题
// 如果 start 不等于0,表示不是第一个InputSplit,所以把start的值重置为第二行的起始位置
if (start != 0) {
start += in.readLine(new Text(), 0, maxBytesToConsume(start));
}
this.pos = start;
}
// 核心方法,会被框架调用,没调用一次,就会读取一行数据,返回true表示最终获取到 <k1, v1>
public boolean nextKeyValue() throws IOException {
if (key == null) {
key = new LongWritable();
}
// k1 就是每一行的起始位
key.set(pos);
if (value == null) {
value = new Text();
}
int newSize = 0;
// We always read one extra line, which lies outside the upper
// split limit i.e. (end - 1)
while (getFilePosition() <= end || in.needAdditionalRecordAfterSplit()) {
if (pos == 0) {
newSize = skipUtfByteOrderMark();
} else {
// 读取一行数据,赋值给value,也就是v1
newSize = in.readLine(value, maxLineLength, maxBytesToConsume(pos));
pos += newSize;
}
if ((newSize == 0) || (newSize < maxLineLength)) {
break;
}
// line too long. try again
LOG.info("Skipped line of size " + newSize + " at pos " +
(pos - newSize));
}
if (newSize == 0) {
key = null;
value = null;
return false;
} else {
return true;
}
}
}当一个InputSplit中最后一行不完整时,会从下一个InputSplit读取到完整的一行数据。
OutputFormat 分析
OutputFormat:输出数据顶层基类(抽象类)
FileOutputFormat:文件数据处理基类(抽象类,继承自 OutputFormat,重写了 checkOutputSpecs 和 getOutputCommitter )
TextOutputFormat:默认文本文件处理类(实现类,继承自 FileOutputFormat,重写了 getRecordWriter )
public abstract class OutputFormat<K, V> {
/**
* Get the {@link RecordWriter} for the given task.
*/
public abstract RecordWriter<K, V> getRecordWriter(TaskAttemptContext context)
throws IOException, InterruptedException;
/**
* Check for validity of the output-specification for the job.
*
* <p>This is to validate the output specification for the job when it is
* a job is submitted. Typically checks that it does not already exist,
* throwing an exception when it already exists, so that output is not
* overwritten.</p>
*
* Implementations which write to filesystems which support delegation
* tokens usually collect the tokens for the destination path(s)
* and attach them to the job context's JobConf.
*/
public abstract void checkOutputSpecs(JobContext context)
throws IOException, InterruptedException;
/**
* Get the output committer for this output format. This is responsible
* for ensuring the output is committed correctly.
*/
public abstract
OutputCommitter getOutputCommitter(TaskAttemptContext context)
throws IOException, InterruptedException;
}
一个1G的文件,会产生多少个map任务?
1G / 128M = 8 所以会产生8个map任务。
1000个文件,每个文件100KB,会产生多少个map任务?
一个文件再小都会占用一个block块,1000个InputSplit和map任务。
一个140M的文件,会产生多少个map任务?
140 / 128 < 1.1 只会产生一个InputSplit,生成一个Map任务。
