

MapReduce + 开启日志收集
MapReduce
hdfs用于存储海量数据,mapreduce则用于处理数据,是一种分布式计算模型。MapReduce的思想:将任务切割为多个小任务进行并行计算(Map),然后将得到的局部结果进行汇总(Reduce)。
网络io的耗时远大于磁盘io。当计算程序和数据分别在不同机器上时,将计算程序移动到数据所在节点比移动数据要快的多。所以Hadoop中的MapReduce就是将计算程序发送到各个DataNode上,每个数据节点分别计算自己所保存的数据,得到结果后汇总。
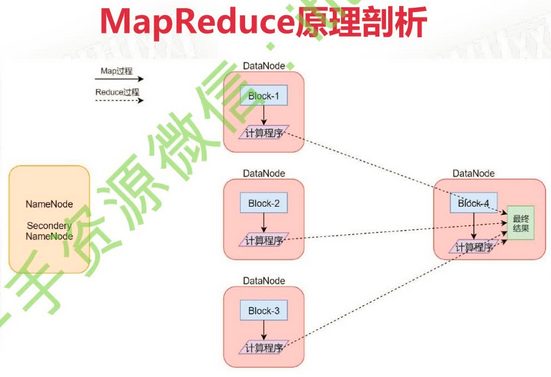
Block是对文件的物理切分,split是对文件的逻辑切分,每个split生成一个MapTask。每个ReduceTask生成一个结果,最后汇总。Map阶段对应Mapper类,Reduce阶段对应Reducer类。
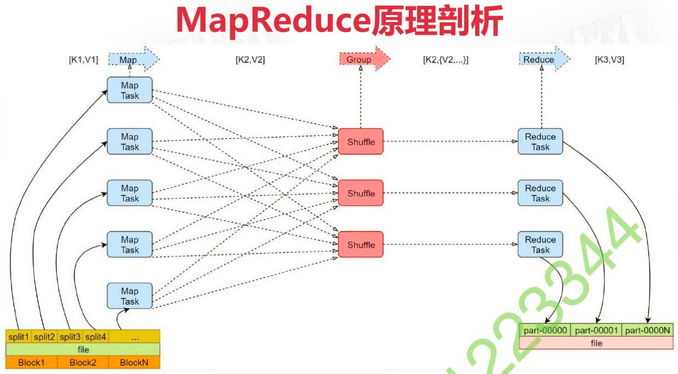
Map 阶段
当省略Reduce阶段,即只是对数据进行过滤时,只要执行到第二阶段即可,然后将数据写入本地磁盘。
- 框架会将输入文件(夹)划分为很多InputSplit,默认每个HDFS的Block对应一个InputSplit。通过RecordReader类,把每个InputSplit解析为一个个<k1, v1>。默认每行数据被拆解为一个<k1, v1>
- 框架调用Mapper类中的 map(...) 函数,map函数的输入是<k1, v1>,输出是<k2, v2>。一个InputSplit对应一个 Map Task
- 框架对map函数输出的<k2, v2>进行分区。不同分区中<k2, v2>由不同的ReduceTask处理,默认只有1个分区
- 框架对每个分区中的数据,按照k2进行排序、分组。分组指的是相同k2的v2分成一组
- 在Map阶段,框架可以执行Combiner操作(可选,默认不执行)。进行局部聚合,类似reduce的操作,可以减小后期传输数据的大小。如求平均值等操作不能使用,防止影响结果
- 框架会把Map Task输出的<k2, v2>写入到Linux的磁盘文件
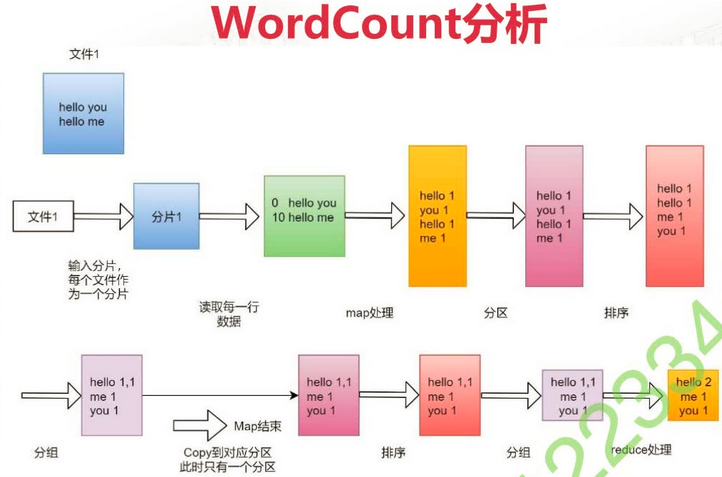
例:
对下面文件进行词频统计:
hello you
hello me-
拆分任务
<0, hello you> <10, hello me> # 10 是偏移长度 -
调用map函数
# MapTask1 <hello, 1> <you, 1> # MapTask2 <hello, 1> <me, 1> -
聚集
<hello, 1> <you, 1> <hello, 1> <me, 1> -
排序
<hello, 1> <hello, 1> <me, 1> <you, 1>分组
<hello, {1, 1}> <me, {1}> <you, {1}> - Combiner 规约, 默认不执行
<hello, {2}> <me, {1}> <you, {1}> - 写入磁盘
Reduce 阶段
有时可以省略
- 框架对多个MapTask的输出,按照不同的分区,通过网络复制到不同的Reduce节点,这个过程称作Shuffle
- 框架对Reduce节点接收到的相同分区的<k2, v2>数据进行合并、排序、分组
前一阶段的排序分组是一个MapTask内,此处是MapTask之间 - 框架调用Reduce类中的reduce方法,输入<k2, {v2...}>输出<k3, v3>。一个<k2, {v2...}>调用一次reduce函数
- 框架把Reduce的输出结果保存到HDFS中
例子:WordCount
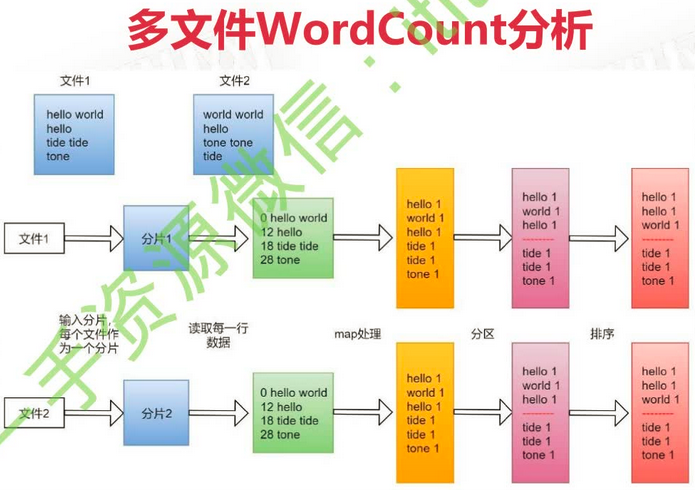
单文件词频统计
两个文件词频统计
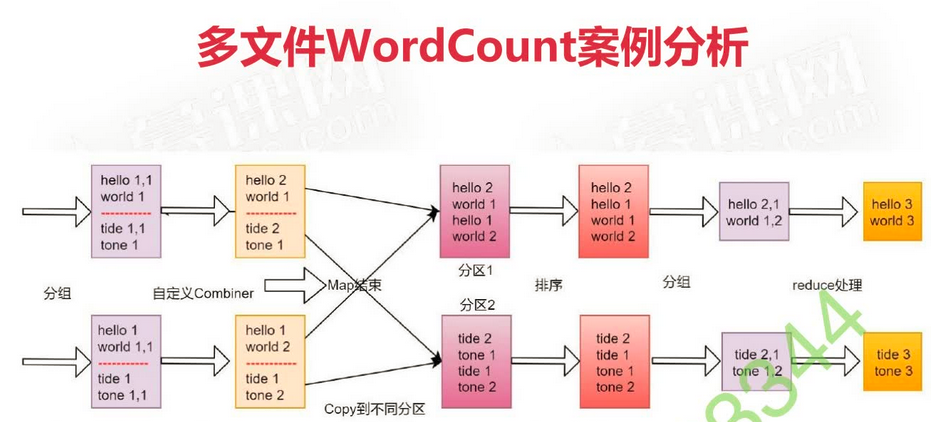
代码
打包成jar包然后上传到集群中。使用hadoop jar bigdata-1.0-SNAPSHOT.jar /hello.txt /out1执行代码。格式为hadoop/yarn jar xxx.jar [指定main方法所在类] [程序的args参数]。
package org.example.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 处理文件 hello.txt ,内容如下:
* hello you
* hello me
*
* 结果:
* hello 2
* me 1
* you 1
*/
public class WordCountJob {
/**
* 组装一个 Job 用于启动任务。
* Job = Mapper + Reducer
*/
public static void main(String[] args) {
try {
if (args.length != 2) {
System.exit(1);
}
// 创建一个配置类
Configuration conf = new Configuration();
// 创建一个任务
Job job = Job.getInstance(conf);
// 注意:这一行必须设置,否则在集群中执行时找不到 WordCountJob 这个类
job.setJarByClass(WordCountJob.class);
// 指定输入路径,可以是文件或目录。如果是目录则读取其下所有文件
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 指定一个输出目录,必须是不存在的目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 指定 mapper 类和输出的 key value
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 指定 Reducer 类和最终输出的 key value
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 提交 job
job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* map 流程,重写map函数
* 继承类 Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
*
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
/**
* 需要实现 map 函数
* 这个 map 函数可以接收 <k1, v1> 产生 <k2, v2>
* 此处对每一行数据进行切割,把单词切割出来
* @param key 每一行数据行首偏移量
* @param value 每一行内容
*/
@Override
protected void map(LongWritable key,
Text value,
Mapper<LongWritable, Text, Text, LongWritable>.Context context
) throws IOException, InterruptedException {
// 分割单词
String[] words = value.toString().split(" ");
// 迭代分出的单词
for (String word : words) {
// 把迭代出的单词封装为 <k2, v2> 的形式
Text keyOut = new Text(word);
LongWritable valueOut = new LongWritable(1L);
// 把 <k2, v2> 写出去
context.write(keyOut, valueOut);
}
}
}
/**
* Reduce 阶段
*/
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
/**
* 针对 <k2, {v2...}> 进行累加求和,并把数据转为 <k3, v3>
*/
@Override
protected void reduce(
Text key,
Iterable<LongWritable> values,
Reducer<Text, LongWritable, Text, LongWritable>.Context context
) throws IOException, InterruptedException {
// 将词频累加
long sum = 0L;
for (LongWritable value : values) {
sum += value.get();
}
// 把结果写出去
context.write(key, new LongWritable(sum));
}
}
}当只需要进行解析时,MapReduce程序中可以没有Reduce的步骤。在main函数中无需再设定reducer类,但是要输入 job.setNumReduceTasks(0);。输出结果文件为 part-m-00000
依赖:
以下都不是必需的
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.2</version>
<!-- 只在编译执行时需要,hadoop中有这个依赖,无需打包-->
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<!-- maven 打包,指定启动类。也可在启动时手动指定 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.2.2</version>
<configuration>
<archive>
<manifest>
<mainClass>org.example.mapreduce.WordCountJob</mainClass>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
</manifest>
</archive>
</configuration>
</plugin>
<!-- 指定jdk版本 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
<!-- 打包时将依赖也全部打包 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4.1</version>
<configuration>
<!--打包时,包含所有依赖的jar包-->
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
<!--生成javadoc文件-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-javadoc-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<encoding>UTF-8</encoding>
<charset>UTF-8</charset>
<docencoding>UTF-8</docencoding>
<doclint>none</doclint>
</configuration>
<executions>
<execution>
<id>attach-javadocs</id>
<goals>
<goal>jar</goal>
</goals>
</execution>
</executions>
</plugin>
<!--生成source文件-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-source-plugin</artifactId>
<version>2.4</version>
<executions>
<execution>
<id>attach-sources</id>
<goals>
<goal>jar</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>以下提示信息表示运行成功

在指定的输出目录中可见:

_SUCCESS 用于标识成功。part-r-00000 是成功的结果文件,由reduce程序产生。如果没有reduce程序则生成 part-m-00000文件;当有多个reduce任务时会生成多个part文件,结尾为00001、00002等
MapReduce任务日志查
在程序中使用 sout 输出信息无法在控制台直接看见,因为控制台只是一个客户端,不能看见服务的日志。
通过访问hdfs的web控制界面 http://NameNodeIp:8088点击 History 链接。

查看前要做两个配置然后启动相应的 historyserver 进程
- 在hosts文件中配置主机名与对应ip
- 开启日志聚合功能,把散落在NodeManager节点上的日志同一收集管理,方便查看
修改所有集群配置,在 yarn-site.xml 中添加 yarn.log-aggregation-enable 和 yarn.log.server.url 两个参数
<property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log.server.url</name> <value>http://bigdata01:19888/jobhistory/logs/</value> </property> - 启动:
mapred --daemon start historyserver所有机器执行此命令启动 historyserver 进程,然后访问 master 的 19888 端口查看log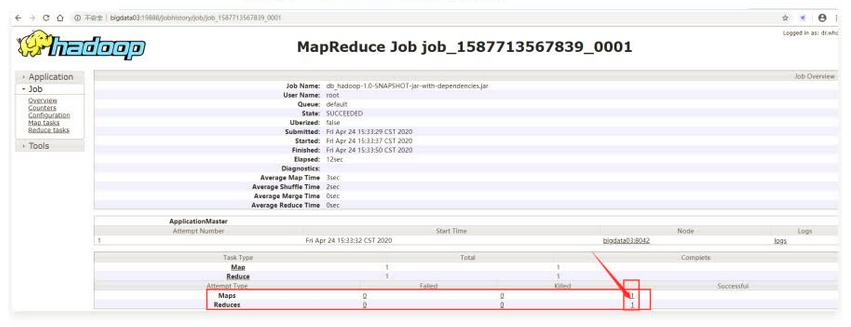

使用命令行查看日志:yarn logs -applicationId <Application ID>
停止正在运行的任务
yarn application -kill <ApplicationId>
在控制台按 ctrl+c 无法停止程序,控制台运行的是客户端程序,MapReduce程序已提交到集群中执行了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通