
Hadoop 安装
Hadoop适合海量数据分布式存储和分布式计算,适合存储大量小文件。
几个不同发行版:
- Apache Hadoop 最基础的官方开源版本
- Cloudera Hadoop(CDH)商业版本,对官方版本做了优化,提供收费服务,方便集群运维管理
- HortonWorks(HDP) 开源,提供界面操作,方便运维管理,互联网公司偏爱使用
目前Hadoop有3个版本:
再1中资源的管理计算都是由MapReduce完成的,在2中引入Yarn管理资源,在这之上可以跑包括MapReduce在内的更多程序。3中进行了一些细节优化,HDFS引入了纠删码比副本存储节省更多的时间;支持多个NameNode;MR任务级本地优化

Hadoop = HDFS + MapReduce + YARN
部署
伪分布式集群 使用一台机器
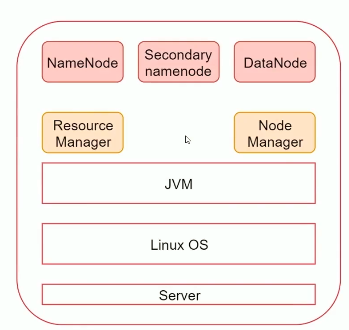
一个节点的组成如下,NameNode Secondary-namenode DataNode 都是HDFS相关进程;ResourceManager NodeManager 都是Yarn相关进程。
- 配置固定ip、主机名 、防火墙、ssh免密码登录 等
- 下载hadoop压缩包并解压到指定目录
- 配置环境变量
export HADOOP_HOME=/usr/local/hadoop-3.3.2 export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH - 修改 HADOOP_HOME/etc/hadoop 下的配置文件
# hadoop-env.sh export JAVA_HOME=/usr/local/jdk-11.0.13core-site.sh <configuration> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop/</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://ubuntu-server02:9000</value> </property> </configuration>hdfs-site.xml 单节点填1,多节点填节点数量 <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>mapred-site.xml 指定资源引擎 <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 用于处理 Could not find error --> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <!-- 用于处理 Could not find class 的 error。value的值通过 `hadoop classpath` 获得,将冒号换位逗号。 --> <property> <name>yarn.application.classpath</name> <value> /opt/module/hadoop-3.1.3/etc/hadoop, /opt/module/hadoop-3.1.3/share/hadoop/common/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/common/*, /opt/module/hadoop-3.1.3/share/hadoop/hdfs, /opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/hdfs/*, /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*, /opt/module/hadoop-3.1.3/share/hadoop/yarn, /opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/yarn/*, </value> </property> </configuration>yarn-site.xml <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hahoop.mapred.ShuffleHandler</value> </property> <!-- 用于处理 Could not find class 的 error。value的值通过 `hadoop classpath` 获得,将冒号换位逗号。 --> <property> <name>yarn.application.classpath</name> <value> /opt/module/hadoop-3.1.3/etc/hadoop, /opt/module/hadoop-3.1.3/share/hadoop/common/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/common/*, /opt/module/hadoop-3.1.3/share/hadoop/hdfs, /opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/hdfs/*, /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*, /opt/module/hadoop-3.1.3/share/hadoop/yarn, /opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/yarn/*, </value> </property> </configuration># workers # 集群节点 ubuntu-server02 - 格式化 hdfs 文件系统
hdfs namenode -format出现
common.Storage: Storage directory /data/hadoop/dfs/name has been successfully formatted.表示格式化成功。
注意:格式化只能执行一次。如果想要再次格式化必须要先把数据目录删除。 - 使用 sbin/start-all.sh 启动伪分布式集群
启动会报错,因为没有配置用户信息,向目录$HADOOP_HOME/sbin下指定文件中添加以下配置
# start-dfs.sh # stop-dfs.sh HDFS_NAMENODE_USER=root HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_SECONDARYNAMENODE_USER=root # start-yarn.sh # stop-yarn.sh YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root - 注意配置ssh免密钥登录
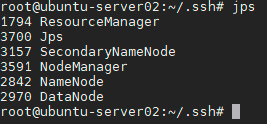
- 使用 jps 查看启动进程
- 访问 ip:9870 查看Hadoopweb界面
ip:8088 查看 yarn 服务 - stop-all.sh 关闭服务
分布式集群 建议最少三台
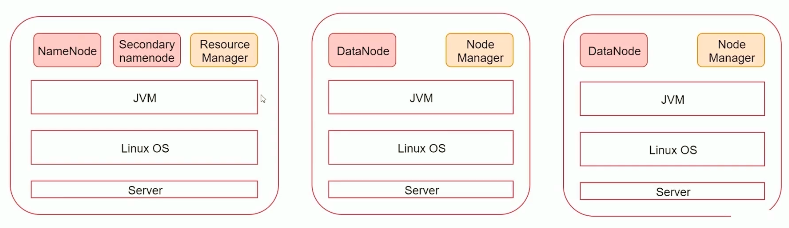
- 与伪分布式类似,要先配置ip hostname等。在下载解压hadoop文件,配置路径与配置文件。
- 为方便操作,在主节点的hosts文件中配置从节点的主机名与ip
192.168.56.150 ubuntu 192.168.56.151 ubuntu-01 192.168.56.152 ubuntu-02 - 集群内时间需要同步,安装 ntpdate 命令用于同步时间
在每个机器的 /etc/crontab 中添加
0 * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn - 配置配置文件
# hadoop-env.sh export JAVA_HOME=/usr/local/jdk-11.0.13core-site.sh <configuration> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop/</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://ubuntu-server02:9000</value> </property> </configuration>hdfs-site.xml 单节点填1,多节点填节点数量 <configuration> <property> <name>dfs.replication</name> <value>2</value> <!-- 在一主两从的结构中有两个副本,可设为1,最大为2 --> </property> <property> <name>dfs.namenode.secondary.http-address</name> <!-- 指定secondary name --> <value>ubuntu-01:50090</value> </property> </configuration>mapred-site.xml 指定资源引擎,没有变化 <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 用于处理 Could not find error --> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <!-- 用于处理 Could not find class 的 error。value的值通过 `hadoop classpath` 获得,将冒号换位逗号。 --> <property> <name>yarn.application.classpath</name> <value> /opt/module/hadoop-3.1.3/etc/hadoop, /opt/module/hadoop-3.1.3/share/hadoop/common/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/common/*, /opt/module/hadoop-3.1.3/share/hadoop/hdfs, /opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/hdfs/*, /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*, /opt/module/hadoop-3.1.3/share/hadoop/yarn, /opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/yarn/*, </value> </property> </configuration>yarn-site.xml <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hahoop.mapred.ShuffleHandler</value> </property> <property> <!-- 比伪分布式集群多了这个 --> <name>yarn.resourcemanager.hostname</name> <value>ubuntu01</value> </property> <!-- 用于处理 Could not find class 的 error。value的值通过 `hadoop classpath` 获得,将冒号换位逗号。 --> <property> <name>yarn.application.classpath</name> <value> /opt/module/hadoop-3.1.3/etc/hadoop, /opt/module/hadoop-3.1.3/share/hadoop/common/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/common/*, /opt/module/hadoop-3.1.3/share/hadoop/hdfs, /opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/hdfs/*, /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*, /opt/module/hadoop-3.1.3/share/hadoop/yarn, /opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*, /opt/module/hadoop-3.1.3/share/hadoop/yarn/*, </value> </property> </configuration># workers # 只指定从节点 ubuntu-01 ubuntu-02 - 再修改脚本,指定用户
# start-dfs.sh # stop-dfs.sh HDFS_NAMENODE_USER=root HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_SECONDARYNAMENODE_USER=root # start-yarn.sh # stop-yarn.sh YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root - 配置好一台机器后直接复制目录到其他机器
- 再格式化
hdfs namenode -format - 在主节点上运行 start-all.sh
