

大数据发展历程
整理自 https://www.bilibili.com/video/BV1tF411479W
小数据时代
OLTP(增删改)OLAP(查询)二合一的系统,随着数据量的增大开始分库分表。之后大量数据的处理(min max avg ...)不易操作。
大数据
所有数据汇聚到一个中心存储,这个中心底层是“分布式”,但向上暴露的接口是“单机”的。这极大程度的降低了数据传输、存储、分析的难度。
历程:
- Hadoop
2006 年出现 Hadoop,其主要包括 1. MR(分布式计算)2. HDFS(分布式存储)。
使用方法:写3个函数: map函数、reduce函数、main函数。提交到hadoop集群由多台集群分布式计算。 - Hive
2010 年出现,是一个在Hadoop上层的sql翻译器,将sql语句翻译为代码提交到Hadoop中执行。 - Hadoop 2.0
将集群调度功能从MR中剥离,形成“分布式调度”,即Yarn(Yet Another Resource Negotiator)。Yarn的出现扩展了Hadoop生态圈,不光MR,后来的Spark、Flink也能跑在Yarn上。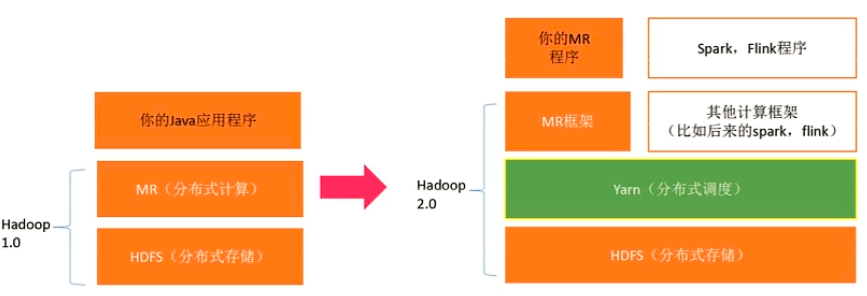
- Yarn
在没有云的时代,大数据平台使用Yarn做分布式调度;未来会逐步切换到云原生(Docker + k8s)
Yarn:管理的是一个个Container,每个Container是一个JVM虚拟机
k8s:管理的是一个个Docker,每个Docker是一个资源完全隔离的Linux进程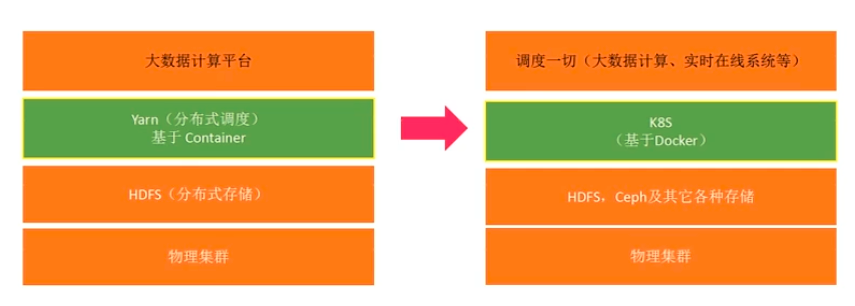
- Spark
写java spark代码比写MR更简洁方便,spark比MR计算快许多,因为所有中间结果不落地存储到hdfs,而是尽可能在内存中。
- Spark SQL
与Hive类似,用户使用上没有太大变化,都是写SQL,底层的计算引擎从MR切换到Spark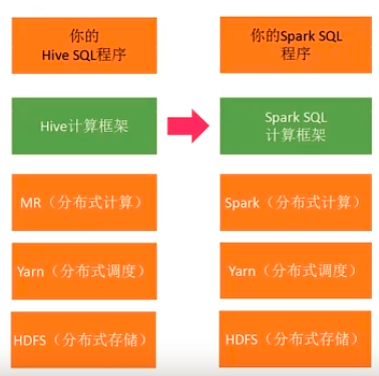
- pySpark
改写Java为写python,降低开发门槛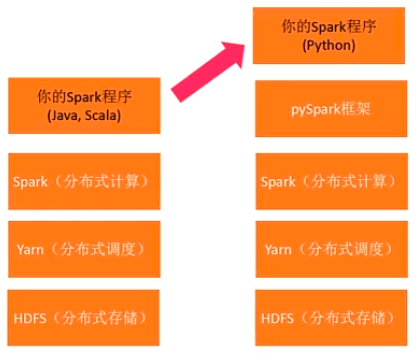
- Spark Streaming
之前的都是批处理计算,这时出现了“伪流式计算”。按照时间间隔把任务分解为一个一个的小型批处理任务,然后不断向Spark集群提交任务。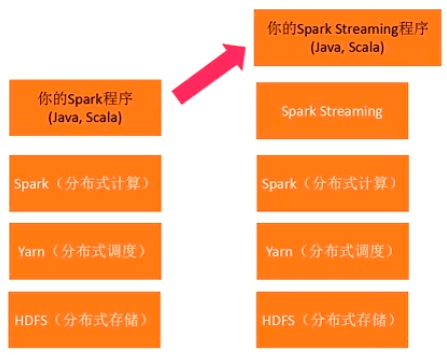
- Spark 部署方式
目前主要部署再yarn上,未来会迁移到k8s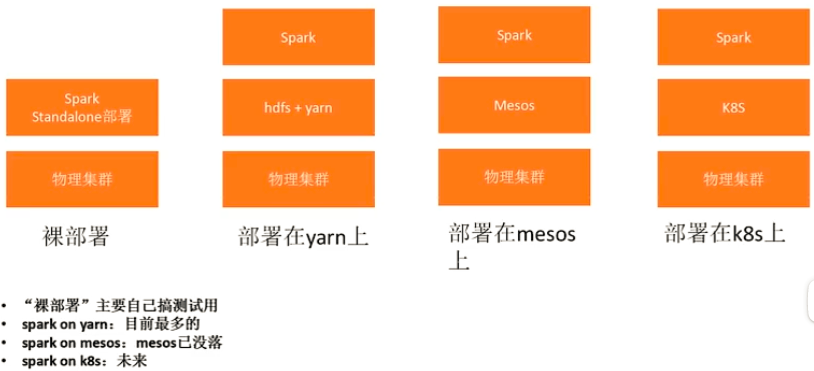
- Flink
Flink是一种流失计算框架,曾经的流失计算框架Storm已没落。其与Spark一样,都支持单机、Yarn、k8s等多种方式部署。
Spark起家于批处理,往流式方向拓展;Flink起家于流式处理,网批处理方向扩展。 - SQL只会越来越普及,因为它最简单;MR是过去时,现在基本上都是Spark/Flink;Yarn是现在,未来是k8s



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理