Linux 或 Windows 安装 Kafka,示例实现生产与消费消息(一)
官网:https://kafka.apache.org/
下载:wget https://downloads.apache.org/kafka/3.3.1/kafka_2.12-3.3.1.tgz
注意:kafka正常运行,必须配置zookeeper,kafka安装包已经包括zookeeper服务
解压:tar -zxvf kafka_2.12-3.3.1.tgz
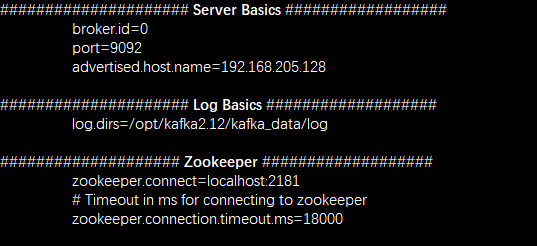
修改config 目录下 server.properties文件
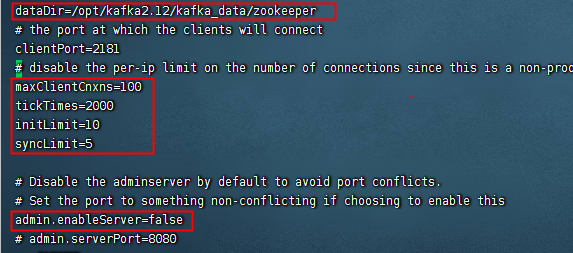
修改config 目录下 zookeeper.properties 文件
启动Kafka,kafka2.12目录下运行 zookeeper 和 kafka
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
nohup bin/kafka-server-start.sh config/server.properties &
或
./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
./bin/kafka-server-start.sh -daemon config/server.properties
检查是否启动成功:
ps -ef|grep kafka 或 lsof -i:2181
创建一个 topic 命名为:my-topic
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic my-topic
查看已创建的topic信息:
bin/kafka-topics.sh --describe --topic my-topic --bootstrap-server localhost:9092
查询已经创建的topic:kafka-topics.sh --list --bootstrap-server localhost:9092

命令行的工具生产消息:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-topic
This is a message

消费工具消费消息:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my-topic --from-beginning

使用Ctrl-C停止生产者和消费者客户端。
【啰嗦一下】:
若要模拟分布式可以复制多个server.properties 文件,并修改 broker.id,port,log.dirs
再一一启动时指定不同的server.properties文件启动即可
Windos 环境启动kafka:
与linux相同的压缩包,解压后修改server.properties 文件,zookeeper.properties文件
到bin/windows目录下执行cmd 打开两个窗口,再分别执行以下两个命令,具体目录根据自己的文件目录修改
zookeeper-server-start.bat D:/ProgramFiles/kafka2.12/config/zookeeper.properties
kafka-server-start.bat D:/ProgramFiles/kafka2.12/config/server.properties
其创建生产消费等命令与linux类似,把sh文件换成bat文件执行命令
API地址:https://kafka.apache.org/documentation/#api
引入依赖包:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.3.1</version>
</dependency>生产消息代码:
public class KafkaMyProducer {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
Producer<String, String> producer = new KafkaProducer<>(props);
//生产数据
for (int i = 0; i < 5; i++) {
// topic: 消息队列的名称,也可以提前在kafka服务中用命令进行创建。如果kafka中并未创建该topic,那么便会自动创建!
// key:键值,value:要发送的数据,数据格式为String类型的。
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("mytopic", Integer.toString(i), "Hello kafka A" + i);
producer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception e) {
if (Objects.nonNull(e)) {
System.out.println("发送消息失败:" + e.getMessage());
}
if (Objects.nonNull(metadata)) {
System.out.println("同步发送消息结果:topic-" + metadata.topic() + "|partition-" + metadata.partition()
+ "|offset-" + metadata.offset());
}
}
});
}
producer.close();
}
}消费消息代码:
public class KafkaMyConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "group1");//组名,不同组名可以重复消费
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList("mytopic")); //需要先订阅一个topic,也就是指定消费哪一个topic,可指定多个
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(20));
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}常用配置介绍:
| 消费者配置: | https://kafka.apache.org/documentation/#producerconfigs | |
| bootstrap.servers | 用于建立到Kafka集群的初始连接的主机/端口对列表。host1:port1,host2:port2,… | |
| acks | 在认为请求完成之前,生产者要求领导接收到的确认数量。 acks=0,如果设置为0,那么生产者将根本不等待来自服务器的任何确认。 acks=1,这意味着leader会将记录写入本地日志,但不会等待所有追随者的完全确认。 acks=all,这意味着leader将等待完整的同步副本来确认该记录。 acks=-1,等同于acks=all; |
|
| batch.size | 每一批消息的最大大小。 | |
| linger.ms | 请求延迟时间,单位毫秒 | |
| retries | 消息发送失败重试次数,与acks配合可实现不同的消息传递语义,至多一次:acks=0或acks=1,至少一次:acks=-1 & retries>0, | |
| request.timeout.ms | 配置控制客户端等待请求响应的最大时间。 如果在超时之前没有收到响应,客户端将在必要时重新发送请求,或者在重试次数用尽时失败请求。 |
|
| buffer.memory | 生产者可以用来缓冲等待发送到服务器的记录的内存总字节数。 | |
| key.serializer | 键的序列化器类 | |
| value.serializer | 值的序列化器类 | |
| 生产者配置: |
https://kafka.apache.org/documentation/#consumerconfigs | |
| bootstrap.servers | 用于建立到Kafka集群的初始连接的主机/端口对列表。host1:port1,host2:port2,… | |
| group.id | 标识此使用者所属的使用者组的唯一字符串。 | |
| session.timeout.ms | 当使用Kafka的组管理功能时,用来检测客户端故障的超时。 | |
| request.timeout.ms | 配置控制客户端等待请求响应的最大时间。 如果在超时之前没有收到响应,客户端将在必要时重新发送请求,或者在重试次数用尽时失败请求。 |
|
| key.deserializer | 键的反序列化类 | |
| value.deserializer | 值的反序列化类 | |
消息传递语义:
至多一次:acks=0或acks=1,可能成功一次,或可能失败;
至少一次:acks=-1 & retries>0,可能成功一次,也可能重复多次;
精确一次:
需要生产者和消费者共同来保障;
生产者实现精确一次:需要启动 enable.idempotence=true,retries=Integer.MAX_VALUE,acks=all;
当启用 enable.idempotence 后 retries 会自动设置成最大值,所以可以省略不写;
消费者实现精确一次:
通过offset来防止重复消费不是一个好的办法;
通常在消息中加入唯一ID(例如:流水ID,订单ID),在处理业务时通过判断 ID 来防止重复处理;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号