
海康威视c++实习生面试资料
- 面对对象
1. 三大特性:封装,继承,多态
2. 封装性:数据和代码捆绑在一起,避免外界干扰和不确定性访问。封装可以使得代码模块化。
3. 继承性:让某种类型对象获得另一个类型对象的属性和方法。继承可以扩展已存在的代码。
4. 多态性:同一事物表现出不同事物的能力,即向不同对象发送同一消息,不同的对象在接收时会产生不同的行为(重载实现编译时多态,虚函数实现运行时多态)。多态的目的则是为了接口重用。
5. 多态的底层实现:C++多态性是通过虚函数来实现的,虚函数允许子类重新定义成员函数,而子类重新定义父类的做法称为覆盖(override),或者称为重写。
6. 多态的底层实现:在C++中,通过基类的引用(或指针)调用虚函数时,发生动态绑定,引用(或指针)既可以指向基类也可以指向派生类,引用和指针的静态类型和动态类型可以不同,这是c++用以支持多态性的基石。
C++
1. STL(标准模板库):
(1)STL的一个重要特点是数据结构和算法的分离
(2)STL另一个重要特性是它不是面向对象的。为了具有足够通用性,STL主要依赖于模板而不是封装,继承和虚函数(多态性)——OOP的三个要素。你在STL中找不到任何明显的类继承关系。这好像是一种倒退,但这正好是使得STL的组件具有广泛通用性的底层特征。另外,由于STL是基于模板,内联函数的使用使得生成的代码短小高效。
(3)从逻辑层次来看,在STL中体现了泛型化程序设计的思想,引入了诸多新的名词。
(4)从实现层次看,整个STL是以一种类型参数化的方式实现的,这种方式基于一个在早先C++标准中没有出现的语言特性--模板(template)。
2. STL中六大组件:(1)容器(2)迭代器(3)算法(4)仿函数(5)适配器(6)分配器
3. 容器:(1)序列式容器:vector,deque,list(2)关联式容器:set/multiset,map/multimap
4. vector和list的区别:
(1)vector和数组类似,拥有一段连续的内存空间,并且起始地址不变。因此,它能够高效地进行随机存取,时间复杂度是O(1)。但是,因为其内存空间是连续的,所以在进行插入和删除操作时,会造成内存块的拷贝,因此时间复杂度为O(n)。另外,当数组内存空间不够时,会重新申请一块内动空间并进行内存拷贝。
(2)list是由双向链表实现的,因此内存空间是不连续的。其只能通过指针访问数据,所以list的随机存取效率很低,时间复杂度为O(n)。不过由于链表自身的特点,能够进行高效的插入和删除。
(3)vector和list对于迭代器的支持不同。相同点在于,vector< int >::iterator和list< int >::iterator都重载了 “++ ”操作。而不同点在于,在vector中,iterator支持 ”+“、”+=“,”<"等操作。而list中则不支持。
5. vector的risize底层实现:每个动态数组都分配有一定容量,当存储的数据达到容量的上限的时候,就重新分配内存。一般来说后面的内存已经被占用了,在后面增加是不可能的。resize是重新开辟了一个数组,把之前的值放到复制到新开辟的数组中来。
6. c++智能指针:
(1)c++里面的四个智能指针,auto_ptr,unique_ptr,shared_ptr,weak_ptr,其中后三个是c++11支持,并且第一个已经被c++11弃用
(2)使用原因:智能指针的作用是管理一个指针,因为存在以下这种情况:申请的空间在函数结束时忘记释放,造成内存泄漏。使用智能指针可以很大程度上的避免这个问题,因为智能指针是一个类,当超出了类的实例对象的作用域时,会自动调用对象的析构函数,析构函数会自动释放资源。所以智能指针的作用原理就是在函数结束时自动释放内存空间,不需要手动释放内存空间。
(3)auto_ptr:采用所有权模式。p2剥夺了p1的所有权,但是当程序运行时访问p1将会报错。所以auto_ptr的缺点是:存在潜在的内存崩溃问题。
(4)unique_ptr:实现独占式拥有或严格拥有概念,保证同一时间内只有一个智能指针可以指向该对象。它对于避免资源泄露(例如“以new创建对象后因为发生异常而忘记调用delete”)特别有用,可以通过标准库的move()函数实现指针转移。
(5)shared_ptr:实现共享式拥有概念。多个智能指针可以指向相同对象,该对象和其相关资源会在“最后一个引用被销毁”时候释放。从名字share就可以看出了资源可以被多个指针共享,它使用计数机制来表明资源被几个指针共享。
(6)weak_ptr:是一种不控制对象生命周期的智能指针, weak_ptr 设计的目的是为配合 shared_ptr 而引入的一种智能指针来协助 shared_ptr 工作, 它只可以从一个 shared_ptr 或另一个 weak_ptr 对象构造, 它的构造和析构不会引起引用记数的增加或减少。
7. Qt是一个跨平台的C++应用程序开发框架。它提供给开发者建立图形用户界面所需的功能,广泛用于开发GUI程序,也可用于开发非GUI程序。Qt是完全面向对象的,很容易扩展,并且允许真正地组件编程。Qt使用标准的C++和特殊的代码生成扩展(称为元对象编译器Meta Object Compiler, moc)以及一些宏。
8. 信号槽是 Qt 框架引以为豪的机制之一。所谓信号槽,实际就是观察者模式。当某个事件发生之后,比如,按钮检测到自己被点击了一下,它就会发出一个信号(signal)。这种发出是没有目的的,类似广播。如果有对象对这个信号感兴趣,它就会使用连接(connect)函数,意思是,将想要处理的信号和自己的一个函数(称为槽(slot))绑定来处理这个信号。也就是说,当信号发出时,被连接的槽函数会自动被回调。这就类似观察者模式:当发生了感兴趣的事件,某一个操作就会被自动触发。(这里提一句,Qt 的信号槽使用了额外的处理来实现,并不是 GoF 经典的观察者模式的实现方式。)
信号和槽是Qt特有的信息传输机制,是Qt设计程序的重要基础,它可以让互不干扰的对象建立一种联系。
槽的本质是类的成员函数,其参数可以是任意类型的。和普通C++成员函数几乎没有区别,它可以是虚函数;也可以被重载;可以是公有的、保护的、私有的、也可以被其他C++成员函数调用。
唯一区别的是:槽可以与信号连接在一起,每当和槽连接的信号被发射的时候,就会调用这个槽。
9. 常见的设计模式:
(1)工厂模式:简单工厂模式、工厂方法模式、抽象工厂模式。工厂模式的主要作用是封装对象的创建,分离对象的创建和操作过程,用于批量管理对象的创建过程,便于程序的维护和扩展。
(2)单例模式:保证一个类只有一个实例,并提供一个访问它的全局访问点,使得系统中只有唯一的一个对象实例。常用于管理资源,如日志、线程池。
(3)策略模式:策略模式定义了一系列的算法,并将每一个算法封装起来,而且使它们还可以相互替换。策略模式让算法独立于使用它的客户而独立变化。
10. c++11新特性:
(1)C++11 引入了 nullptr 关键字,专门用来区分空指针、0
(2)C++11 引入了 auto 和 decltype 这两个关键字实现了类型推导,让编译器来操心变量的类型
(3)C++11 引入了基于范围的迭代写法,我们拥有了能够写出像 Python 一样简洁的循环语句。
(4)std::array 保存在栈内存中,相比堆内存中的 std::vector,我们能够灵活的访问这里面的元素,从而获得更高的性能。std::array 会在编译时创建一个固定大小的数组,std::array 不能够被隐式的转换成指针,使用 std::array只需指定其类型和大小即可
(5)C++11 引入了两组无序容器:std::unordered_map/std::unordered_multimap 和 std::unordered_set/std::unordered_multiset。无序容器中的元素是不进行排序的,内部通过 Hash 表实现,插入和搜索元素的平均复杂度为 O(constant)。
- 数据结构
1. B+树和B树:
(1)B+树非叶子节点只存储key,只有叶子结点存储value,叶子结点包含了这棵树的所有键值,每个叶子结点有一个指向相邻叶子结点的指针,这样可以降低B树的高度。
(2)B+树相比于B树的优势:(1)B+树单一节点存储更多的元素,使得查询的IO次数更少(2)B+树所有查询都要查找到叶子节点,查询效率更加稳定(3)B+树所有叶子节点形成有序链表,便于范围查询,更有利于对数据库的扫描
2. B+树和B-树的区别:
(1)B-树的叶bai子结点不含任何信息,而B+树的叶子结点含信息
(2)B-树上的叶子结点不会指向它的兄弟结点,而B+树上的叶子结点会指向它的兄弟结点
(3)B-树只能进行分区间查找,而B+树上可以有两种查找:顺序查找和分区间查找
3. 红黑树的五大特性:
(1)节点是红色或黑色。
(2)根节点是黑色。
(3)每个叶子节点都是黑色的空节点(NIL节点)。
(4)每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
(5)从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
4. 红黑树插入删除操作的三个后续操作:变色,左旋,右旋
5. 基本的排序算法有哪些:
(1)插入排序,时间复杂度O(n^2),空间复杂度O(1),稳定
思想:将无序序列中的各元素依次插入到已经有序的线性表中,从而得到一个新的序列
(2)希尔排序,时间复杂度O(nlog2n),空间复杂度O(1),不稳定
(3)快速排序,时间复杂度O(nlog2n),空间复杂度O(log2n),不稳定
(4)冒泡排序,时间复杂度O(n^2),空间复杂度O(1),稳定
(5)简单排序,时间复杂度O(n^2),空间复杂度O(1),不稳定
(6)堆排序,时间复杂度O(nlog2n),空间复杂度O(1),不稳定
(7)归并排序,时间复杂度O(nlog2n),空间复杂度O(n),稳定
6. 快速排序的思路:通过一趟排序将待排序记录分割成独的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,再分别对这两部分记录继续进行排序,以达到整个序列有序
- 网络编程

1. socket:即套接字,用于描述地址和端口,是一个通信链的句柄。应用程序通过socket向网络发出请求或者回应。
2. sockets编程有三种:流式套接字(SOCK_STREAM),数据报套接字(SOCK_DGRAM),原始套接字(SOCK_RAW);前两种较常用。基于TCP的socket编程是采用的流式套接字。
(1)SOCK_STREAM:字节流传输,表示面向连接的数据传输方式。数据可以准确无误地到达另一台计算机,如果损坏或丢失,可以重新发送,但效率相对较慢。常用的HTTP协议就使用SOCK_STREAM传输数据,因为要确保数据的正确性,否则网页不能正常解析。
(2)SOCK_DGRAM:数据报传输,表示无连接的数据传输方式。计算机只管传输数据,不作数据校验,如果数据在传输中损坏,或者没有到达另一台计算机,是没有办法补救的。也就是说,数据错了就错了,无法重传。因为SOCK_DGRAM所做的校验工作少,所以效率比SOCK_STREAM高。
3. 服务端:建立socket,声明自身的端口号和地址并绑定到socket,使用listen打开监听,然后不断用accept去查看是否有连接,如果有,捕获socket,并通过recv获取消息的内容,通信完成后调用closeSocket关闭这个对应accept到的socket,如果不再需要等待任何客户端连接,那么用closeSocket关闭掉自身的socket。
4. 客户端:建立socket,通过端口号和地址确定目标服务器,使用Connect连接到服务器,send发送消息,等待处理,通信完成后调用closeSocket关闭socket
5. 高并发:服务器使用select函数,客户端使用多线程
6. 同步和异步的区别:
(1)同步:所有的操作都做完,才返回给用户。这样用户在线等待的时间太长,给用户一种卡死了的感觉(就是系统迁移中,点击了迁移,界面就不动了,但是程序还在执行,卡死了的感觉)。这种情况下,用户不能关闭界面,如果关闭了,即迁移程序就中断了。
(2)异步:将用户请求放入消息队列,并反馈给用户,系统迁移程序已经启动,你可以关闭浏览器了。然后程序再慢慢地去写入数据库去。这就是异步。但是用户没有卡死的感觉,会告诉你,你的请求系统已经响应了。你可以关闭界面了。
(3)同步,是所有的操作都做完,才返回给用户结果。即写完数据库之后,再响应用户,用户体验不好。异步,不用等所有操作都做完,就相应用户请求。即先响应用户请求,然后慢慢去写数据库,用户体验较好。
(4)为了避免短时间大量的数据库操作,就使用缓存机制,也就是消息队列。先将数据放入消息队列,然后再慢慢写入数据库。引入消息队列机制,虽然可以保证用户请求的快速响应,但是并没有使得我数据迁移的时间变短(即80万条数据写入mysql需要1个小时,用了redis之后,还是需要1个小时,只是保证用户的请求的快速响应。用户输入完http url请求之后,就可以把浏览器关闭了,干别的去了。如果不用redis,浏览器不能关闭)。
- 计算机网络
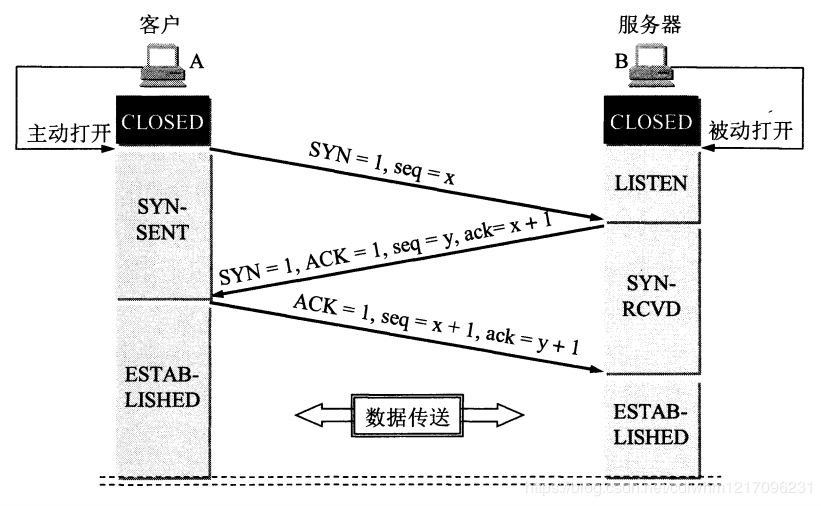
1. TCP为什么要进行三次握手:(1)因为信道不可靠,而 TCP 想在不可靠信道上建立可靠地传输,那么三次通信是理论上的最小值(2)因为双方都需要确认对方收到了自己发送的序列号,确认过程最少要进行三次通信(3)为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误。

2. TCP 为什么要进行四次挥手:
因为 TCP 是全双工模式,客户端请求关闭连接后,客户端向服务端的连接关闭(一二次挥手),服务端继续传输之前没传完的数据给客户端(数据传输),服务端向客户端的连接关闭(三四次挥手)。所以 TCP 释放连接时服务器的 ACK 和 FIN 是分开发送的(中间隔着数据传输),而 TCP 建立连接时服务器的 ACK 和 SYN 是一起发送的(第二次握手),所以 TCP 建立连接需要三次,而释放连接则需要四次。
3. 拥塞控制:

TCP的拥塞控制:(1)原因:拥塞控制就是防止过多的数据注入到网络中,可以使网络中的路由器或链路不致过载(2)解决方法:慢启动( slow-start );拥塞避免( congestion avoidance );快重传( fast retransmit );快恢复( fast recovery)
4. TCP和UDP的区别:
(1)TCP面向连接、UDP是无连接的
(2)TCP提供可靠的服务,UDP不保证可靠交付
(3)TCP连接只能是点对点的,UDP支持一对多、多对一、多对多的交互通信
(4)TCP面向字节流(可能会出现黏包问题),UDP是面向报文的(不会出现黏包问题)
(5)UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
(6)TCP首部开销20字节;UDP的首部开销小,只有8字节
5. TCP的黏包问题:
(1)原因:TCP 是一个基于字节流的传输服务,“流” 意味着 TCP 所传输的数据是没有边界的,所以可能会出现两个数据包黏在一起的情况
(2)解决办法:发送定长包;包头加上包体长度;在数据包之间设置边界,如添加特殊符号 \r\n 标记;使用更加复杂的应用层协议
6. 基本I/O模型有哪些:(1)同步阻塞I/O模型(2)同步非阻塞I/O模型(3)I/O多路复用模型(4)信号驱动I/O模型(5)异步I/O模型
7. 进程:进程是对运行时程序的封装,是系统进行资源调度和分配的基本单位,实现了操作系统的并发
- 操作系统
1. 进程:进程是对运行时程序的封装,是系统进行资源调度和分配的基本单位,实现了操作系统的并发
2. 线程:线程是进程的子任务,是CPU调度和分派的基本单位
3. 进程和线程之间的区别:(1)一个程序至少有一个进程,一个进程至少有一个线程,线程依赖于进程而存在(2)进程在执行过程中拥有独立的内存单元,而多个线程共享进程的内存
4. 进程的状态:(1)就绪状态(2)执行状态(3)阻塞状态
5. 进程间通信的几种方式:(1)管道(2)消息队列(3)共享内存(4)信号量(5)嵌套字
6. 进程调度算法:(1)先来先服务调度算法FCFS(2)最短作业优先调度算法SJF(3)高优先级调度算法HPF(4)时间片轮转调度算法(可抢占的)RR(5)多级反馈队列调度算法
7. 死锁:两个或多个进程无限期阻塞、 相互等待的一种状态
8. 死锁产生的四个必要条件:(1)互斥(2)占有并等待(3)非抢占(4)循环等待
9. 死锁处理:
(1)预防死锁:破坏产生死锁的4个必要条件中的一个或者多个;实现起来比较简单,但是如果限制过于严格会降低系统资源利用率以及吞吐量
(2)避免死锁:在资源的动态分配中,防止系统进入不安全状态
(3)监测死锁
(4)解除死锁:进程终止和资源抢占

