
浅析Postgresql cache hit ratio
一、查找cache hit ratio
查看cache hit ratio 这个东西其实放到其他数据库也是一样,如果你的内存对于系统的缓冲支持不足,需要的数据无法驻留在内存,经常会产生 fault page (有些数据库对于读取的数据不在内存中的一种叫法), 那就必须要要查看你的一个系统参数 cache hit ratio ,大部分建议最低不要低于95%,如果达到99% 才是一个令人满意的数字。
不同的在于每种数据库对于查询的方便些和便捷性,从我掌握的数据库来说,PG获取 cache hit ratio的方法比较简单。
select sum(heap_blks_read) as heap_read,
sum(heap_blks_hit) as heap_hit,
sum(heap_blks_hit),
(sum(heap_blks_hit) + sum(heap_blks_read)) as ratio
from pg_statio_user_tables;
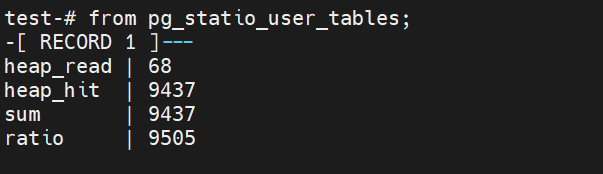
也可以通过pg_statio_uer_tables 这张表,可以很容易发现通过pg_statio_user_tables 这张表可以变化出多种系统的指标参数。
SELECT pg_statio_all_tables.relid,
pg_statio_all_tables.schemaname,
pg_statio_all_tables.relname,
pg_statio_all_tables.heap_blks_read,
pg_statio_all_tables.heap_blks_hit,
pg_statio_all_tables.idx_blks_read,
pg_statio_all_tables.idx_blks_hit,
pg_statio_all_tables.toast_blks_read,
pg_statio_all_tables.toast_blks_hit,
pg_statio_all_tables.tidx_blks_read,
pg_statio_all_tables.tidx_blks_hit
FROM pg_statio_all_tables
WHERE (pg_statio_all_tables.schemaname <> ALL (ARRAY['pg_catalog'::name, 'information_schema'::name])) AND pg_statio_all_tables.schemaname !~ '^pg_toast'::text;
二、什么会引起 cache hit ratio 比较低的问题
1 设计的表中存储了比较大的字段或者存储其他方式的不适合存储在传统数据库的数据,例如大型的图片,或者大量的文字,并且经常调用
2 由于vacuum 的问题,dead tuple 没有及时被清理,
3 查询并未被优化,大量的走了 sequential scans 的方式
4 你缺乏足够的内存来进行目前面对的查询活动
三、查找问题
寻到底哪个表可能会存在问题,可以先看一下pg_stat_database 这个系统表,这样表可以很清楚的给出如下信息:
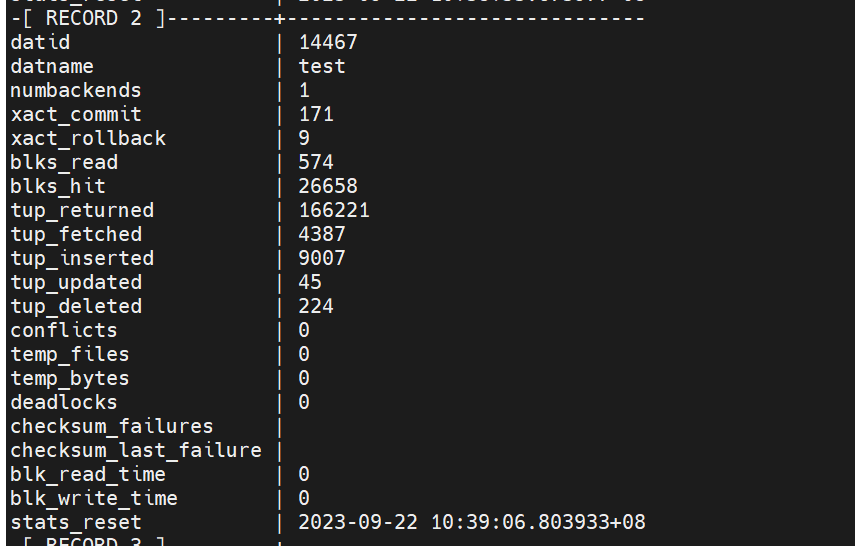
1 单独每个数据库产生的事务多少
2 回滚事务有多少,(从这点就可以看出某些问题)
3 整体数据库的读写比 , tup_fetched 与 tup_inserted, tup_updated, tup_deleted 和的比率
4 查询数据回馈与实际数据的搜索的比率,也就是查找多少数据返回的行数与对应到底数据库检索了多少行 tup_fetched tup_returned
5 是否数据库有死锁
等等以上信息。应该可以确认至少那个数据库是热的,或者对比历史同期数据指标,指标不大对,那就可以继续针对这个数据库进行问题的查找.
四、确认问题
在确认了数据库后,下一步就可以开始针对这个数据库的表进行问题的确认了。
select * from pg_stat_all_tables where relname not like 'pg%' and relname not like 'sql%' and schemaname='aa';
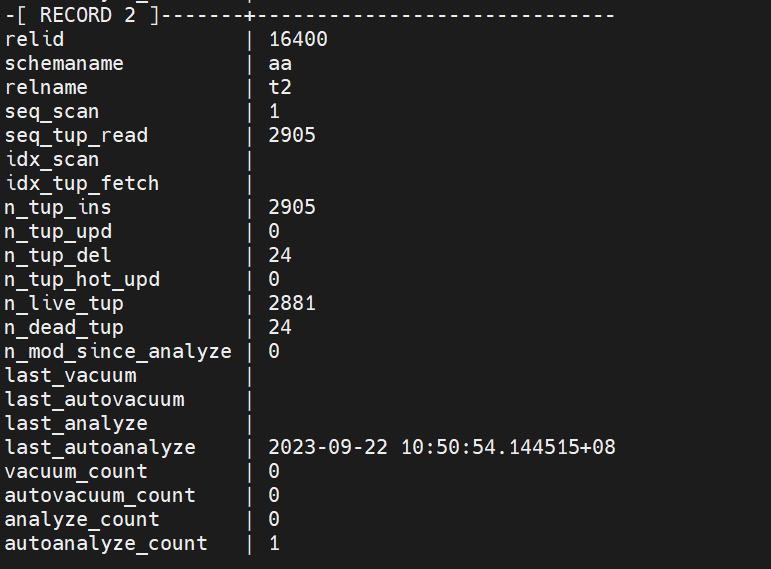
通过pg_stat_all_tables 可以将当前数据库中的表进行一个梳理,例如某个表的数据的 insert ,update del ,以及查询中使用的到的,以及查询的比率,还有了解到一个表最后一次 autovacuum的时间,等等有用的信息,尤其可以通过n_dead_tup 这个参数的跟踪,得到某个表是否有事务没有commit 制造了大量的 dead_tup 或者长事务,造成某个时间段的 dead_tup急剧上升等等,问题。
五、PG_STAT_DATABASE字段
|
高速缓存中已经发现的磁盘块的次数, 这样读取是不必要的(这只包括PostgreSQL缓冲区高速缓存,没有操作系统的文件系统缓存)。 |
||
|
由于数据库恢复冲突取消的查询数量(只在备用服务器发生的冲突)。请参见PG_STAT_DATABASE_CONFLICTS获取更多信息。 |
||
|
通过数据库查询创建的临时文件数量。计算所有临时文件, 不论为什么创建临时文件(比如排序或者哈希), 而且不管log_temp_files设置。 |
||
|
通过数据库查询写入临时文件的数据总量。计算所有临时文件,不论为什么创建临时文件,而且不管log_temp_files设置。 |
||

 浙公网安备 33010602011771号
浙公网安备 33010602011771号