

Postgresql索引浅析
一、摘要
1、索引是提高数据库性能的常用途径。比起没有索引,使用索引可以让数据库服务器更快找到并获取特定行。但是索引同时也会增加数据库系统的日常管理负担,因此我们应该聪明地使用索引。
2、索引其实就是一种数据结构,将数据库中的数据以一定的数据结构算法进行存储。当表数据量越来越大时查询速度会下降,建立合适的索引能够帮助我们快速的检索数据库中的数据,快速定位到可能满足条件的记录,不需要遍历所有记录。
3、索引自身也占用存储空间、消耗计算资源,创建过多的索引将对数据库性能造成负面影响(尤其影响数据导入的性能,建议在数据导入后再建索引)。postgresql里的所有索引都是“从属索引”,也就是索引在物理上与它描述的表文件分离。索引是一种数据库对象,每个索引在pg_class里都有记录。不同种类的索引有着不同的访问方法和内部构造。PG里所有的索引访问方法都通过页面来组织索引的内部结构。从本质来讲,索引是一些数据的键值和元组标识符(TID)之间的映射。在查询数据时如果一个page中的每条数据都能有助于定位数据记录的位置,这将会减少磁盘I/O次数,提高查询效率。
二、简介
一旦一个索引被创建,就不再需要进一步的干预:系统会在表更新时更新索引,而且会在它觉得使用索引比顺序扫描表效率更高时使用索引。但我们可能需要定期地运行ANALYZE命令来更新统计信息以便查询规划器能做出正确的决定。索引也会使带有搜索条件的UPDATE和DELETE命令受益。此外索引还可以在连接搜索中使用。因此,一个定义在连接条件列上的索引可以显著地提高连接查询的速度。
在一个大表上创建一个索引会耗费很长的时间。默认情况下,PostgreSQL允许在索引创建时并行地进行读(SELECT命令),但写(INSERT、UPDATE和DELETE)则会被阻塞直到索引创建完成。在生产环境中这通常是不可接受的。这时需要并发构建索引,创建索引可能会干扰数据库的常规操作。通常 PostgreSQL会锁住要被索引的表,让它不能被写入, 并且用该表上的一次扫描来执行整个索引的构建。其他事务仍然可以读取表 , 但是如果它们尝试在该表上进行插入、更新或者删除,它们会被阻塞直到索引 构建完成。如果系统是一个生产数据库,这可能会导致严重的后果。索引非常 大的表可能会需要很多个小时,而且即使是较小的表,在构建索引过程中阻塞 写入者一段时间在生产系统中也是不能接受的。PostgreSQL支持构建索引时不阻塞写入。这种方法通过 指定CREATE INDEX的CONCURRENTLY选项 实现。当使用这个选项时,PostgreSQL必须执行该表的 两次扫描,此外它必须等待所有现有可能会修改或者使用该索引的事务终止。因此这种 方法比起标准索引构建过程来说要做更多工作并且需要更多时间。不过,由于它 允许在构建索引时继续普通操作,这种方式对于在生产环境中增加新索引很有用。 当然,由索引创建带来的额外 CPU 和 I/O 开销可能会拖慢其他操作。
如果在扫描表示出现问题,例如死锁或者唯一索引中的唯一性被违背, CREATE INDEX将会失败,但留下一个“不可用” 的索引。这个索引会被查询所忽略,因为它可能不完整。不过它仍将消耗更新 开销。psql的\d命令将把这类索引报告为 INVALID。这种情况下推荐的恢复方法是删除该索引并且尝试再次执行CREATE INDEX CONCURRENTLY。
常规索引构建允许在同一个表上同时构建其他常规索引,但是在一个表上同时 只能有一个并发索引构建发生。
三、索引类型
PostgreSQL提供了多种索引类型: B-tree、Hash、GiST、SP-GiST 、GIN 和 BRIN。每一种索引类型使用了一种不同的算法来适应不同类型的查询。默认情况下, CREATE INDEX命令创建适合于大部分情况的B-tree 索引。
pg_am存储关于关系访问方法的信息。系统支持的每种访问方法在这个目录中都有一行。
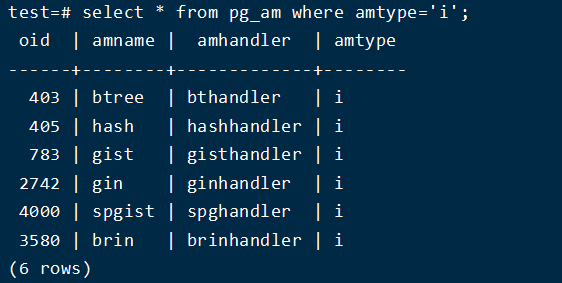
pg_am为每一种索引方法都包含一行(内部被称为访问方法)。PostgreSQL中内建了对表 常规访问的支持,但是所有的索引方法则是在pg_am中描述。可以通过编写必要的代码并且 在pg_am中创建一项来增加一种新的索引访问方法. 一个索引方法的例程并不直接了解它将要操作的数据类型。而是由一个操作符类标识索引方法用来操作一种特定数据类型的一组操作。
1、B-tree
B-tree索引是最常见的索引并且适合处理等值查询和范围查询的索引,可以在可排序数据上的处理等值和范围查询。特别地,PostgreSQL的查询规划器会在任何一种涉及到以下操作符的已索引列上考虑使用B-tree索引:<、<=、=、>=、>。将这些操作符组合起来,例如BETWEEN和IN,也可以用B-tree索引搜索实现。同样,在索引列上的IS NULL或IS NOT NULL条件也可以在B-tree索引中使用。
优化器也会将B-tree索引用于涉及到模式匹配操作符LIKE和~ 的查询,前提是如果\模式是一个常量且被固定在字符串的开头—例如:col LIKE 'foo%'或者col ~ '^foo', 但在col LIKE '%bar'上则不会。
PostgreSQL的B-tree索引与Oracle的B-tree索引区别比较大,主要是以下4点:
- PostgreSQL中索引会存储NULL,而Oracle不会;
- PostgreSQL中建立索引时,可以使用where来建立部分索引,而Oracle不能;
- PostgreSQL中可以对同一列建立两个相同的索引,而Oracle不能;
- PostgreSQL中可以使用concurrently关键字达到创建索引时不阻塞表的DML的功能,Oracle也有online参数实现类似的功能。
注意点:
- 此选项只能指定一个索引的名称。
- 普通CREATE INDEX命令可以在事务内执行,但是CREATE INDEX CONCURRENTLY不可以在事务内执行。
- 列存表、分区表和临时表不支持CONCURRENTLY方式创建索引。
2、Hash
适用场景:hash索引存储的是被索引字段VALUE的哈希值,只支持简单的等值查询。hash索引特别适用于字段VALUE非常长(不适合b-tree索引,因为b-tree一个PAGE至少要存储3个ENTRY,所以不支持特别长的VALUE)的场景,例如很长的字符串,并且用户只需要等值搜索,建议使用hash index。
在pg10之前是不提倡使用hash索引的,因为hash索引不会写wal日志。不过从pg10开始解决了这一问题,并且对hash索引进行了一些加强hash索引其主要目的就是对于某些数据类型(索引键)的值,我们的任务是快速找到匹配的行的ctid。
Hash索引只能处理简单等值比较。不论何时当一个索引列涉及到一个使用了=操作符的比较时,查询规划器将考虑使用一个Hash索引。Hash索引只能处理简单的等值查询。下面的命令将创建一个Hash索引:
CREATE INDEX name ON table USING HASH (column);
3、GiST
GiST索引即通用搜索树。和btree一样,也是平衡的搜索树。和btree不同的是,btree索引常常用来进行例如大于、小于、等于这些操作中,而在实际生活中很多数据其实不适用这种场景,例如地理数据、图像等等。如果我们想要查询在某个地方是否存在某一点,即判断地理位置的"包含"那么我们就可以使用gist索引了。
Gist索引的使用场景有哪些。
因为gist是一个通用的索引接口,所以可以使用GiST实现b-tree, r-tree等索引结构。
不同的类型,支持的索引检索也各不一样。例如:
- 几何类型,支持位置搜索(包含、相交、在上下左右等),按距离排序。
- 范围类型,支持位置搜索(包含、相交、在左右等)。
- IP类型,支持位置搜索(包含、相交、在左右等)。
- 空间类型(PostGIS),支持位置搜索(包含、相交、在上下左右等),按距离排序。
- 标量类型,支持按距离排序。
示例:创建一个存放几何数据的表:
create table t_gist (id int, pos point);
insert into t_gist select generate_series(1,100000), point(round((random()*1000)::numeric, 2), round((random()*1000)::numeric, 2));
select * from t_gist limit 5;
在pos列上创建gist索引:create index idx_t_gist_1 on t_gist using gist (pos);
4、GIN
GIN(Generalized Inverted Index, 通用倒排索引) 是一个存储对(key、posting list)集合的索引结构,其中key是一个键值,posting list是一组出现过key的位置。如‘hello', '14:2 23:4'中,表示hello在14:2和23:4这两个位置出现过,这些位置实际上就是元组的tid(行号,包括数据块ID,大小为32 bit;以及item point,大小为16 bit)。通过这种索引结构可以快速的查找到包含指定关键字的元组,因此GIN索引特别适用于多值类型的元素搜索。
GIN索引常用于查询索引字段中的部分元素值,如在text类型和json类型字段中检索某个关键字。在PG中,GIN索引会为每一个键建立一个B-tree索引,这会导致GIN索引的更新速度非常慢,因为插入或更新一条记录,所有相关键值的索引都会被更新。
PG提供gin_pending_list_limit参数来控制GIN索引的更新速度,适当将maintenance_work_mem参数增大,可以加快GIN索引的创建过程。如果查询返回的结果集特别大,则可以用gin_fuzzy_search_limit参数来控制返回的行数,默认为0,不限制,一般建议设置为5000~20000比较合适。
5、BRIN
BRIN 索引是块级索引,有别于B-TREE等索引,BRIN记录并不是以行号为单位记录索引明细,而是记录每个数据块或者每段连续的数据块的统计信息。因此BRIN索引空间占用特别的小,对数据写入、更新、删除的影响也很小。BRIN属于LOSSLY索引,当被索引列的值与物理存储相关性很强时,BRIN索引的效果非常的好。例如时序数据,在时间或序列字段创建BRIN索引,进行等值、范围查询时效果很好。
6、SP-GiST索引
SP-Gist是Space-Partition Gist(空间分区Gist索引)的简写。和Gist索引一样,它也是一个索引框架,但是相比较于Gist,它优化了索引算法,提高了索引的性能。
三、索引方式
1、多列索引
一个索引可以定义在表的多个列上,目前,只有 B-tree、GiST、GIN 和 BRIN 索引类型支持多列索引,最多可以指定32个列。多列索引应该较少地使用。在绝大多数情况下,单列索引就足够了且能节约时间和空间。具有超过三个列的索引不太有用,除非该表的使用是极端程式化的。
2、索引和ORDER BY
除了简单地查找查询要返回的行外,一个索引可能还需要将它们以指定的顺序传递。这使得查询中的ORDER BY不需要独立的排序步骤。在PostgreSQL当前支持的索引类型中,只有B-tree可以产生排序后的输出,其他索引类型会把行以一种没有指定的且与实现相关的顺序返回。
默认情况下,B-tree索引将它的项以升序方式存储,并将空值放在最后(表TID被处理为其它相等条目之间的分线器列)。这意味着对列x上索引的一次前向扫描将产生满足ORDER BY x(或者更长的形式:ORDER BY x ASC NULLS LAST)的结果。索引也可以被后向扫描,产生满足ORDER BY x DESC(ORDER BY x DESC NULLS FIRST, NULLS FIRST是ORDER BY DESC的默认情况)。我们可以在创建B-tree索引时通过ASC、DESC、NULLS FIRST和NULLS LAST选项来改变索引的排序。
3、组合索引
也叫复合索引,只有查询子句中在索引列上使用了索引操作符类中的操作符并且通过AND连接时才能使用单一索引。例如,给定一个(a, b) 上的索引,查询条件WHERE a = 5 AND b = 6可以使用该索引,而查询WHERE a = 5 OR b = 6不能直接使用该索引。幸运的是,PostgreSQL具有组合多个索引(包括多次使用同一个索引)的能力来处理那些不 能用单个索引扫描实现的情况。
在所有的应用(除了最简单的应用)中,可能会有多种有用的索引组合,数据库开发人员必须做出权衡以决定提供哪些索引。有时候多列索引最好,但是有时更好的选择是创建单独的索引并依赖于索引组合特性。在查询使用时,最好将条件顺序按找索引的顺序,这样效率最高。如:
create index idx1 on table1(col2,col3,col5);
"select * from table1 where col2=A and col3=B and col5=D" 索引效果明显
如果是"select * from table1 where col3=B and col2=A and col5=D"
或者是"select * from table1 where col3=B"将不会使用索引,或者效果不明显
4、唯一索引
索引也可以被用来强制列值的唯一性,或者是多个列组合值的唯一性。当前,只有B-tree能够被声明为唯一。空值被视为不相同。
5、表达式索引
一个索引列并不一定是底层表的一个列,也可以是从表的一列或多列计算而来的一个函数或者标量表达式。这种特性对于根据计算结果快速获取表中内容是有用的。
索引表达式的维护代价较为昂贵,因为在每一个行被插入或更新时都得为它重新计算相应的表达式。然而,索引表达式在进行索引搜索时却不\需要重新计算,因为它们的结果已经被存储在索引中了。表达式索引对于检索速度远比插入和更新速度重要的情况非常有用。
6、部分索引
一个部分索引是建立在表的一个子集上,而该子集则由一个条件表达式定义。如:CREATE INDEX access_log_client_ip_ix ON access_log (client_ip) WHERE NOT (client_ip > inet '192.168.100.0' AND client_ip < inet '192.168.100.255');
7、索引和排序规则
一个索引在每一个索引列上只能支持一种排序规则。如果需要多种排序规则,你可能需要多个索引。
可以创建一个额外的支持"y"排序规则的索引CREATE INDEX test1c_content_y_index ON test1c (content COLLATE "y");
8、检查索引使用
尽管PostgreSQL中的索引并不需要维护或调优,但是检查真实的查询负载实际使用了哪些索引仍然非常重要。检查一个独立查询的索引使用情况可以使用EXPLAIN命令,也可以在一个运行中的服务器上收集有关索引使用的总体统计情况。
9、索引存储参数
可选的WITH子句为索引指定存储参数。每一种 索引方法都有自己的存储参数集合。B-树、哈希、GiST以及SP-GiST索引方法都接受这个参数:
fillfactor (integer)
索引的填充因子是一个百分数,它决定索引方法将尝试填充索引页面的充满程度。如果页面后来被完全填满,它们就会被分裂,导致索引的效率逐渐退化。B-树使用了默认的填充因子 90,但是也可以选择为 10 到 100 的任何整数值。如果表是静态的,那么填充因子 100 是最好的,因为它可以让索引的物理尺寸最小化。但是对于更新负荷很重的表,较小的填充因子有利于最小化对页面分裂的需求。其他索引方法以不同但是大致类似的方式使用填充因子,不同方法的默认填充因子也不相同。
四、性能优化
对于大多数索引方法,索引的创建速度取决于 maintenance_work_mem的设置。较大的值将会减少 索引创建所需的时间,当然不要把它设置得超过实际可用的内存量。
PostgreSQL可以在构建索引时利用多个CPU以更快地处理表行。这种特性被称为并行索引构建。对于支持并行构建索引的索引方法(当前只有B-树),maintenance_work_mem指定每次索引构建操作整体可用的最大内存量,而不管启动了多少工作者进程。一般来说,一个代价模型(如果有)自动判断应该请求多少工作者进程。
增加maintenance_work_mem可以让并行索引构建受益,而等效的串行索引构建将无法受益或者得到很小的益处。注意maintenance_work_mem可能会影响请求的工作者进程的数量,因为并行工作者必须在总的maintenance_work_mem预算中占有至少32MB的份额。还必须有32MB的份额留给领袖进程。增加max_parallel_maintenance_workers可以允许使用更多的工作者,这将降低索引创建所需的时间,只要索引构建不是I/O密集型的。当然,还需要有足够的CPU计算能力,否则工作者们会闲置。 通过ALTER TABLE为parallel_workers设置一个值直接控制着CREATE INDEX会对表请求多少并行工作者进程。这会完全绕过代价模型,并且防止maintenance_work_mem对请求多少并行工作者产生影响。通过ALTER TABLE将parallel_workers设置为0将禁用所有情况下的并行索引构建。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)