

Postgresql通过pg_waldump来分析pg_wal日志
一、简介
读取MySQL的binlog 并将其解析为可读的日志是一件简单的事情,mysqlbinlog 命令就可以将bin日志解析, 那postgresql是否可以将pg_wal 中的日志进行解析,并且提供一些特殊的功能,例如想查询某个时间短插入的数据量。pg_waldump 可以解决这个问题,通过pg_waldump来解析pg_wal 日志来分析和解决一些问题。
二、wal内部
WAL是自动被启用的。除了确保满足WAL日志存放所需要的磁盘空间以及一些必要的调优外,管理员无需执行任何操作。当每个新记录被写入时,WAL记录被追加到WAL日志中。 插入位置由日志序列号(LSN)描述,该日志序列号是日志中的字节偏移量, 随每个新记录单调递增。WAL日志被存放在数据目录的pg_wal目录里,它是作为一个文件段的集合存储的,通常每个段16MB大小(不过这个大小可以通过initdb配置选项--with-wal-segsize来修改)。每个段分割成多个页,通常每个页为8K。段文件的名字是不断增长的数字,从000000010000000000000001开始。目前这些数字不能回卷。
wal日志被放置在和主数据库文件不同的另外一个磁盘上会比较好。你可以通过把pg_wal目录移动到另外一个位置(当然在此期间服务器应当被关闭),然后在原来的位置上创建一个指向新位置的符号链接来实现重定位日志。
在完成一个检查点并且刷写了日志文件之后,检查点的位置被保存在文件pg_control里。因此在恢复的开始, 服务器首先读取pg_control,然后读取检查点记录; 接着它通过从检查点记录里标识的日志位置开始向前扫描执行 REDO操作。 因为数据页的所有内容都保存在检查点之后的第一个页面修改的日志里(假设full_page_writes没有被禁用), 所以自检查点以来的所有变化的页都将被恢复到一个一致的状态。
pg_control很小(比一个磁盘页小),因此它不会出现页断裂问题, 并且到目前为止还没有发现仅仅由于无法读取pg_control本身导致数据库失败的报告。 因此,尽管这在理论上是一个薄弱环节,但是pg_control看起来似乎并不是实际会发生的问题。
三、分析示例
1、展示 STARTSEG 到 ENDSEG 的事务日志
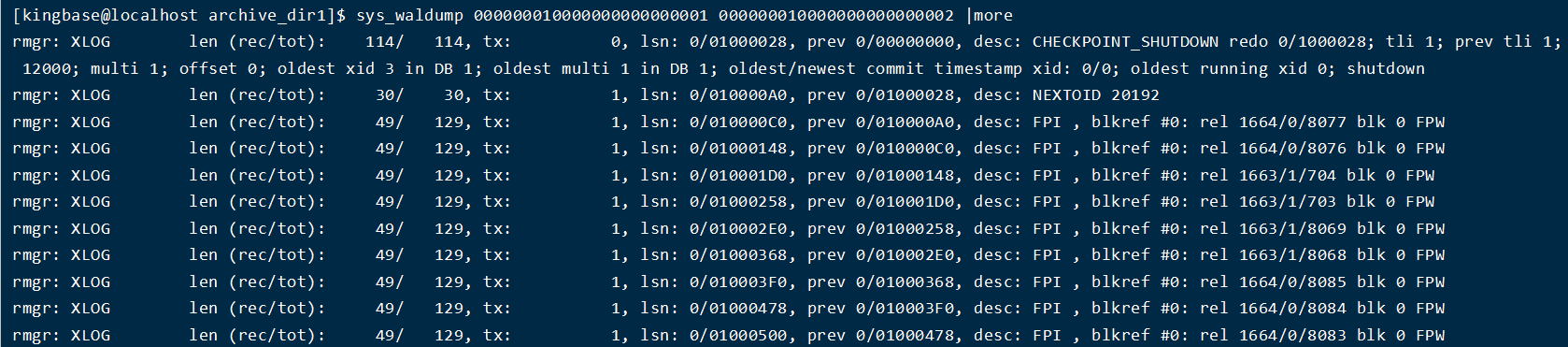
2、日志参数介绍
rmgr : 资源名称
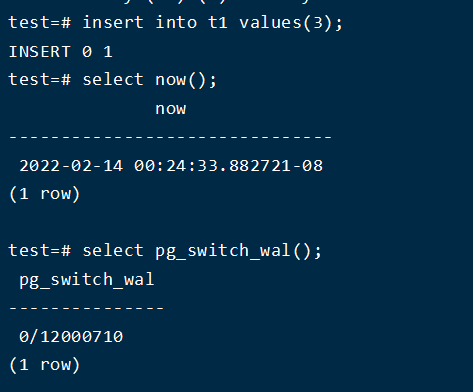
查看此时 wal 日志,如果没有日志则通过手动切换select pg_switch_wal()
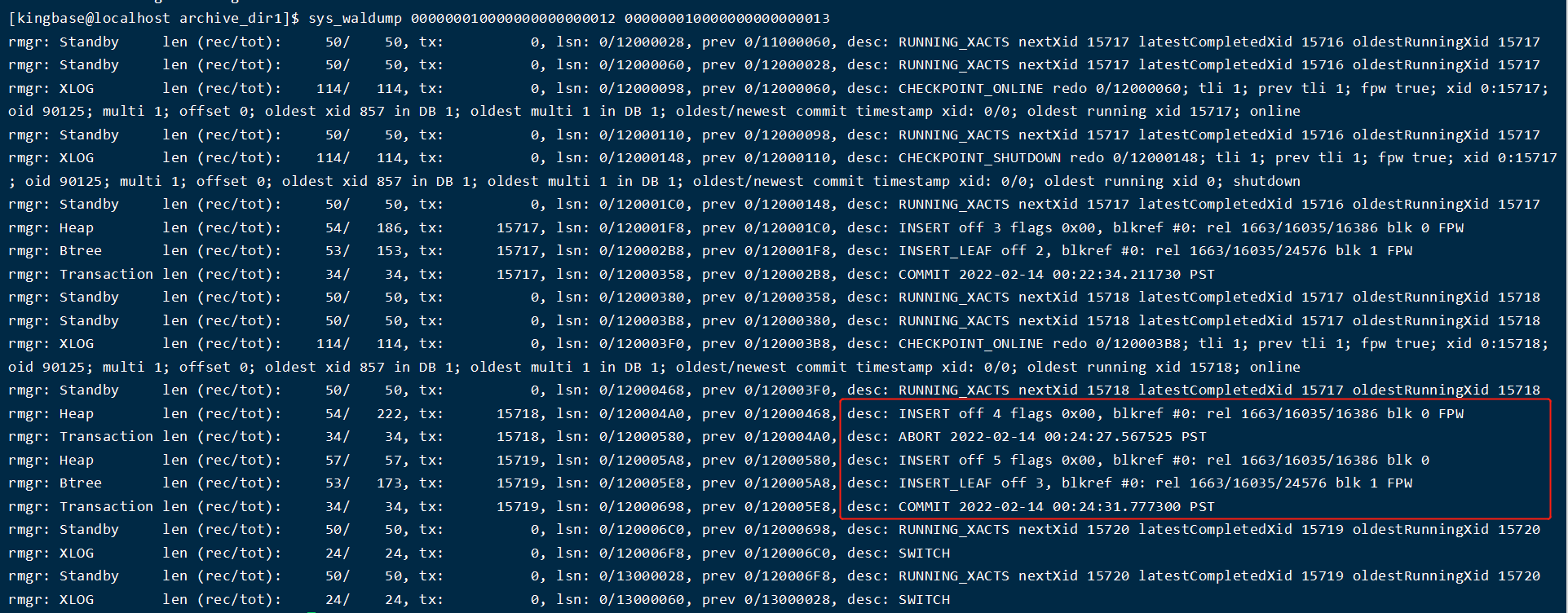
发现插入数据后,wal 日志会先进入资源等待 rmgr: Standby ,分配一个事务id 15718 ,进入rmgr: Heap,把插入事务写入到指定日志偏移位置 desc: INSERT off 5 ,进入索引资源 rmgr: Btree ,插入索引 desc: INSERT_LEAF off 3,分配下一事务id RUNNING_XACTS nextXid 15720 latestCompletedXid 15719 oldestRunningXid 15720
4、执行 update 语句
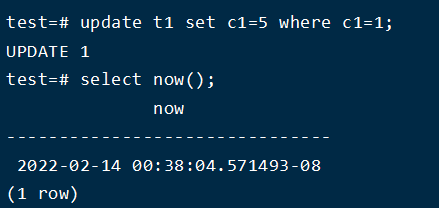
查看日志

发现此时 desc: UPDATE off 1 xmax 15725 ; 事务日志已经写入,desc: COMMIT 2022-02-14 00:37:59.569893 PST 完成提交
5、执行delete语句
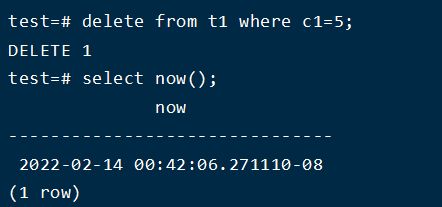
查看日志

发现此时descDELETE off 15 KEYS_UPDATED 写入日志,desc:COMMIT 2022-02-14 00:42:00.195505 PST事务提交
6、显示事务回滚
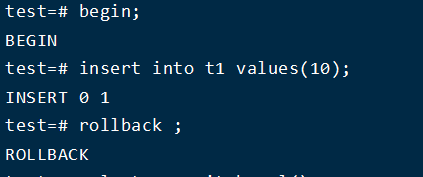
查看日志

发现此时 desc: ABORT 2022-02-14 00:46:03.515257 PST 事务已经取消
7、创建数据库
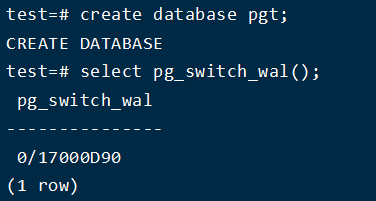
查看日志

四、pg_waldump参数
pg_waldump --help pg_waldump decodes and display
PostgreSQL write-ahead logs for debugging.
Usage: pg_waldump [OPTION]... [STARTSEG [ENDSEG]]
STARTSEG 从指定的日志段文件开始读取。这也隐含地决定了要搜索文件的路径以及 要使用的时间线。
ENDSEG 在读取指定的日志段文件后停止。
Options:
-b, --bkp-details 输出有关备份块的细节。
-e, --end=RECPTR 在指定的日志位置停止读取,而不是一直读取到日志流的末尾。
-f, --follow 在到达可用 WAL 的末尾之后,保持每秒轮询一次是否有新的 WAL 出现。
-n, --limit=N 显示指定数量的记录,然后停止。
-p, --path=PATH 要在哪个目录中寻找日志段文件。默认是在当前目录的pg_xlog 子目录中搜索。
-r, --rmgr=RMGR 只显示由指定资源管理器生成的记录。如果把list作为资源管理器名称 传递给这个选项,则打印出可用资源管理器名称的列表然后退出。
-s, --start=RECPTR 要从哪个日志位置开始读取。默认是从找到的最早的文件的第一个可用日志记录开始。
-t, --timeline=TLI 要从哪个时间线读取日志记录。默认是使用startseg(如果指定) 中的值,否则默认为 1
-V, --version 打印pg_xlogdump版本并且退出。
-x, --xid=XID 只显示用给定事务 ID 标记的记录。
-z, --stats[=record] 显示概括统计信息(记录的数量和尺寸以及全页镜像)而不是显示 每个记录。可以选择针对每个记录生成统计信息,而不是针对每个 资源管理器生成。
-?, --help show this help, then exit


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具