Redis 的简单使用
1. 引入
1. 非关系型数据库和新型比较
| 关系型数据库 | 非关系型数据库 |
|---|---|
| 增删改查都有特定的查询语句\支持事务的特性 | 也支持事务 |
| 结构固定 user-->id username | 结构松散(数据类型比较单一),可变(k,v) |
| 数据库之间的数据是有联系的 | 数据库之间的数据是无联系的 |
| 磁盘 | 内存数据库 | 持久化策略 | 存在数据丢失 |
两者常常常结合使用
从右往左:查询速度越来快,存储越来越小

2. 为什么使用NoSql
关系型数据库的瓶颈: IO瓶颈:
1)无法应对每秒上万次的读写请求,无法处理大量集中的高并发操作。关系型数据的是 IO密集的应用。硬盘 IO 也变为性能瓶颈。
2)无法简单地通过增加硬件、服务节点来提高系统性能。数据整个存储在一个数据库中的。多个服务器没有很好的解决办法,来复制这些数据。
3)关系型数据库大多是收费的,对硬件的要求较高。软件和硬件的成本花费比重较大。
3. NoSql 优势
- 大数据量 ,高性能
- 传统的数据库存在磁盘IO读写速度的瓶颈问题
- 灵活的数据模型
- 高可用
- 低成本
- Redis+SQL的方式 解决磁盘性能的问题,将经常查询的放到redis里面
*关系数据库关注在关系上,NoSQL 关注在存储上。*
清除缓存--> 增删改--> 再查询
4. NoSQl 的劣势
(1) 不支持标准的 SQL,没有公认的 NoSQL 标准
(2) 没有关系型数据库的约束,大多数也没有索引的概念
(3) 没有关系型数据库的事务机制.
(4) 没有丰富的数据类型(数值,日期,字符,二进制,大文本等)
操作的都是字符串
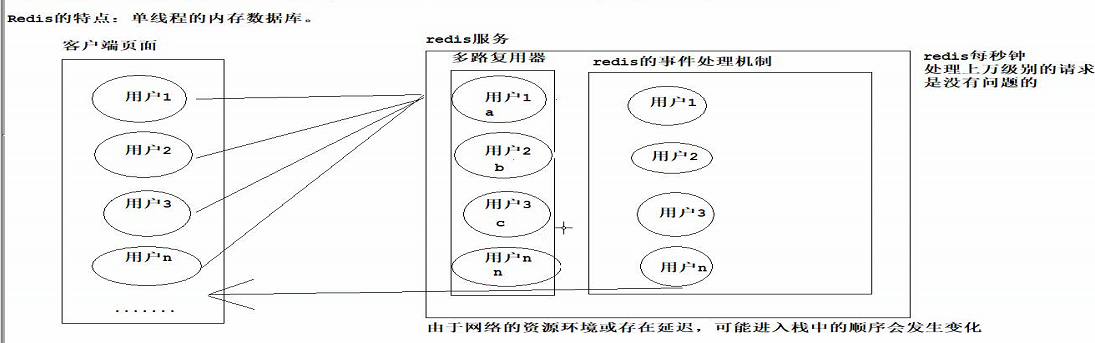
5.redis 的特点:
- 单线程内存数据库
2. Redis 基本操作命令
1.准备
- 进入客户端
在redis/src 中,输入
cd src ./redis-cli
-
测试链接畅通性
ping 结果: pong
192.168.137.135:6379> ping
PONG -
查看当前容量
- dbsize
192.168.137.135:6379> dbsize (integer) 2 -
切换数据库
select 0
exit quit
2.key的操作命令
1.存储
set k1 v1 //存储
2.获取所有键值对并返回, *表示 0 或多个字符
keys *
3.获取指定的返回---单个匹配 ?表示单个字符
keys k?
4.判断是否存在
exists k2 k1
192.168.137.135:6379[1]> exists k1 k2
(integer) 1
5.10秒之后过期
试用场景: 验证码 设置过期时间 以秒为单位
expire k1 10 (秒为单位)
192.168.137.135:6379[1]> get k1
"v1"
192.168.137.135:6379[1]> get k1
(nil)
-
查看过期时间 ttl k1
- -1 永不过期 通过set新建
-2 不存在
192.168.137.135:6379[1]> expire k1 1000 (integer) 1 192.168.137.135:6379[1]> ttl k1 (integer) 974 - -1 永不过期 通过set新建
6.查看数据类型
type k1
192.168.137.135:6379[1]> type k1
string
-
可以删除字符串 和集合
del 键名
del k1
3.五种数据类型操作
1.String 类型
字符串类型是 Redis 中最基本的数据类型,它能存储任何形式的字符串,包括二进制数据,序列化后的数据,JSON 格式数据。
1. set 和 get
set将字符串值 value 设置到 key 中,get获取 key 中设置的字符串值
语法:set key value | get key
set k1 v1
get k1
向已经存在的 key 设置新的 value,会覆盖原来的值
2.incr (desr)
incr 将 key 中储存的数字值加 1,如果 key 不存在,则 key 的值先被初始化为 0 再执行 (incr 操作(只能对数字类型的数据操作))
- 原来k4 赋值 2,经过incr变成3
192.168.137.135:6379[1]> set k4 2
OK
192.168.137.135:6379[1]> incr k4
(integer) 3
192.168.137.135:6379[1]> get k4
"3"
-
操作字符串的时候,分为数值类型,和字符串类型
-
不存在的key,初值为0,再减 1
使用场景:
incr ,decr 在实现关注人数上,文章的点击数上。
3.append
语法:
append key value
注意:
-
如果 key 存在,则将 value 追加到 key 原来旧值的末尾
-
如果 key 不存在,则将 key 设置值为 value |同 set key value
-
返回值:追加字符串之后的总长度
192.168.137.135:6379[1]> get k6
(nil)
192.168.137.135:6379[1]> append k6 11
(integer) 2
192.168.137.135:6379[1]> get k6
"11"
4.常用命令
1.获取帮助 help @String
2.获取长度 strlen k1
- key不存在,返回0
192.168.137.135:6379[1]> strlen k6
(integer) 2
192.168.137.135:6379[1]> get k6
"11"
- getrange
相当于字符串的截取
语法:getrange key start end
作用:获取 key 中字符串值从 start 开始到 end 结束的子字符串,包括 start 和 end, 负数表示从字符串的末尾开始,-1 表示最后一个字符
返回值:截取的子字符串。
192.168.137.135:6379> set k1 xiaobaishizhigou
OK
192.168.137.135:6379> get k1
"xiaobaishizhigou"
192.168.137.135:6379> getrange k1 0 6
"xiaobai"
4.setrange
语法:setrange key offset value
说明:用 value 覆盖(替换)key 的存储的值从 offset 开始,不存在的 key 做空白字符串。
返回值:修改后的字符串的长度
"xiaobaishizhigou"
192.168.137.135:6379> setrange k1 0 xiahei
(integer) 16
192.168.137.135:6379> get k1
"xiaheiishizhigou"
- 不存在就创建
- 原有的长度不够也会扩大
5.mset 批量插入 和mget 批量获取
192.168.137.135:6379> mset tv 998 iphone 5999
OK
192.168.137.135:6379> mget tv iphone
1) "998"
2) "5999"
6.flushall
清空所有
2.Hash类型
- redis hash是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
- 存储用户的订单
- field 用户唯一标示
- key 是每一个订单号
1.基本操作
key : key value(jsonString)
基本命令
1.设置和获取
语法:hset hash 表的 key field value 设置
192.168.7.136:6379> hset 10010 001 iPhoneXPlus 002 xiaomiTV
(integer) 2
192.168.7.136:6379> hget 10010 001
"iPhoneXPlus"
192.168.7.136:6379> hset 10011 a iPhoneXPlus b xiaomiTV
(integer) 2
192.168.7.136:6379> hget 10011 a
"iPhoneXPlus"
返回值:field 域的值,如果 key 不存在或者 field 不存在返回 nil
192.168.7.136:6379> hget 10011 c
(nil)
2.设置多个和获取多个
hset 和hmset 一致的
192.168.7.136:6379> hmget 1024 k1 k2
1) "v1"
2) "v2"
注意 : 当 hmset 的 key 类型不是 hash,产生错误;
hmget: 如果 field 不存在,返回 nil
3.获取所有 一个用户下的所有 hgetall
hmset 1024 k1 v1 k2 v2 // 设置值
192.168.7.136:6379> hgetall 1024
1) "k1"
2) "v1"
3) "k2"
4) "v2"
4.获取所有键
192.168.7.136:6379> hkeys 1024
1) "k1"
2) "k2"
5.获取所有值
192.168.7.136:6379> hvals 1024
1) "v1"
2) "v2"
6.判断是否存在
- hexists
192.168.7.136:6379> hexists 1024 001
(integer) 0
192.168.7.136:6379> hexists 1024 k1
(integer) 1
7.删除
-
删除指定的一个或多个
作用:删除哈希表 key 中的一个或多个指定域 field,不存在 field 直接忽略
192.168.7.136:6379> hdel 1024 k1 (integer) 1 192.168.7.136:6379> hgetall 1024 1) "k2" 2) "v2" -
删除所有
192.168.7.136:6379> hgetall 1026
1) "k1"
2) "v1"
3) "k2"
4) "v2"
5) "k3"
6) "v3"
192.168.7.136:6379> del 1026 整个集合干掉
(integer) 1
192.168.7.136:6379> hgetall 1026
(empty array)
3.list
- help @list
- 可以存储重复值
- Redis 列表是简单的字符串列表,按照插入顺序排序。可以添加一个元素到列表的头部(左边)或者尾部(右边)
1.实际操作:
1.左压栈 后进先出 lpush
语法:lpush key value [value…]
作用:将一个或多个值 value 插入到列表 key 的表头(最左边),从左边开始加入值,从左到右的顺序依次插入到表头
192.168.7.136:6379[2]> lpush k1 v1 v2 v3
(integer) 3
192.168.7.136:6379[2]> lrange k1 0 -1
1) "v3"
2) "v2"
3) "v1"
2.右压栈 -先进后出rpush
lpush k2 v1 v2 v3
192.168.7.136:6379[2]> rpush k2 v1 v2 v3
(integer) 3
192.168.7.136:6379[2]> lrange k2 0 -1
1) "v1"
2) "v2"
3) "v3"
3.lrange
作用:获取列表 key 中指定区间内的元素,
语法:lrange key start stop
注意: -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。start ,stop 超出列表的范围不会出现错误。
192.168.7.136:6379[2]> lrange k2 0 -1
1) "v1"
2) "v2"
3) "v3"
192.168.7.136:6379[2]> lrange k2 -3 -1
1) "v1"
2) "v2"
3) "v3"
192.168.7.136:6379[2]> lrange k2 -2 -1
1) "v2"
2) "v3"
4.lindex
语法:lindex key index
作用:获取列表 key 中下标为指定 index 的元素,列表元素不删除,只是查询。0
192.168.7.136:6379[2]> lindex k2 2
"v3"
5.llen
语法:llen key
作用:获取列表 key 的长度
192.168.7.136:6379[2]> llen k2
(integer) 3
2.常用命令
1.lrem
-
语法:lrem key count value
-
作用:根据参数 count 的值,移除列表中与参数 value 相等的元素,
- count >0 ,从列表的左侧向右开始移除;
- count < 0 从列表的尾部开始移除;
- count = 0 移除表中所有与 value 相等的值。
返回值:数值,移除的元素个数
2.获取总个数
- llen key
llen k2
3.删除
删除k2 中 v1元素2次
192.168.7.136:6379[2]> lrem k2 2 v1
(integer) 1
4.lset
语法:lset key index value
作用:将列表 key 下标为 index 的元素的值设置为 value。
返回值:设置成功返回 ok ; key 不存在或者 index 超出范围返回错误信息
192.168.7.136:6379[2]> lset k2 1 vv3
OK
192.168.7.136:6379[2]> lrange k2 0 -1
1) "v2"
2) "vv3"
5.linsert
语法:linsert key BEFORE|AFTER pivot value
作用:将值 value 插入到列表 key 当中位于值 pivot 之前或之后的位置。key 不存在,pivot不在列表中,不执行任何操作。
- before
192.168.7.136:6379[2]> lrange k2 0 -1
1) "v2"
2) "vv3"
在v2 之前插入 v1
192.168.7.136:6379[2]> linsert k2 BEFORE v2 v1
(integer) 3
192.168.7.136:6379[2]> lrange k2 0 -1
1) "v1"
2) "v2"
3) "vv3"
- after
192.168.7.136:6379[2]> lrange k2 0 -1
1) "v1"
2) "v2"
3) "vv3"
192.168.7.136:6379[2]> linsert k2 after v2 v2.5
(integer) 4
192.168.7.136:6379[2]> lrange k2 0 -1
1) "v1"
2) "v2"
3) "v2.5"
4) "vv3"
4.set
特点:无序 唯一
redis 的 Set 是 string 类型的无序集合,集合成员是唯一的,即集合中不能出现重复的数据
1.基本命令
1.sadd
语法:sadd key member [member…]
作用:将一个或多个 member 元素加入到集合 key 当中,已经存在于集合的 member 元素将被忽略,不会再加入。
返回值:加入到集合的新元素的个数。不包括被忽略的元素。
192.168.7.136:6379[3]> sadd k1 v1 v2 v3 v1
(integer) 3
192.168.7.136:6379[3]> smembers k1
1) "v1"
2) "v3"
3) "v2"
2.查看成员
语法:smembers key
作用:获取集合 key 中的所有成员元素,不存在的 key 视为空集合
3.判断元素是否在set中
语法:sismember key member
作用:判断 member 元素是否是集合 key 的成员
192.168.7.136:6379[3]> SISMEMBER k1 v1
(integer) 1
192.168.7.136:6379[3]> SISMEMBER k1 v10
(integer) 0
返回值:member 是集合成员返回 1,其他返回 0 。
4.获取元素个数
语法:scard key
作用:获取集合里面的元素个数
返回值:数字,key 的元素个数。其他情况返回 0 。
192.168.7.136:6379[3]> scard k1
(integer) 3
5.srem
语法:srem key member [member…]
作用:删除集合 key 中的一个或多个 member 元素,不存在的元素被忽略。
返回值:数字,成功删除的元素个数,不包括被忽略的元素。
6.del key
删除整个
2.常用命令
- srandmember
语法:srandmember key [count]
作用:只提供 key,随机返回集合中一个元素,元素不删除,依然在集合中;提供了 count时,count 正数, 返回包含 count 个数元素的集合,集合元素各不相同。count 是负数,返回一个 count 绝对值的长度的集合,集合中元素可能会重复多次。
返回值:一个元素;多个元素的集合
192.168.7.136:6379[3]> srandmember k1
"v2"
192.168.7.136:6379[3]> srandmember k1 2
1) "v1"
2) "v3"
重复多次
192.168.7.136:6379[3]> SRANDMEMBER k1 -3
1) "v2"
2) "v1"
3) "v1"
- spop
语法:spop key [count]
作用:随机从集合中删除一个元素, count 是删除的元素个数。
返回值:被删除的元素,key 不存在或空集合返回 nil
spop k2 2 // 随机删除指定个数
5.zset (sorted set)
redis 有序集合zset和集合set一样也是string类型元素的集合,且不允许重复的成员。
不同的是 zset 的每个元素都会关联一个分数(分数可以重复),redis 通过分数来为集合中的成员进行从小到大的排序。
help@sorted
使用场景: 排名| 排行榜
1.基本命令
1.zadd
语法:zadd key score member [score member…]
作用:将一个或多个 member 元素及其 score 值加入到有序集合 key 中,如果 member存在集合中,则更新值;score 可以是整数或浮点数
返回值:数字,新添加的元素个数
zadd k1 100 数学
zadd k1 90 语文
zadd PHB 1000 zhangasn 1000 李四 500 wangwu
- 查询 zrange
语法:zrange key start stop [WITHSCORES]
作用:查询有序集合,指定区间的内的元素。集合成员按 score 值从小到大来排序。start,stop都是从 0 开始。0 是第一个元素,1 是第二个元素,依次类推。以 -1 表示最后一个成员,-2 表示倒数第二个成员。WITHSCORES 选项让 score 和 value 一同返回。
返回值:自定区间的成员集合
zrange PHB 0 -1
zrange PHB 0 -1 withscores
zrange PHB 0 0 withscores 查询第一名
倒顺序
zrevrange re 0 -1 with score
3.移除 zrem
zrem PHB w1 w2
4.zcard 获取当前个数
zcard key
192.168.7.136:6379[3]> zcard PHB
(integer) 3
2.常用命令
- zrangebyscore 介于区间进行查寻找
语法:zrangebyscore key min max [WITHSCORES ] [LIMIT offset count]
作用:获取有序集 key 中,所有 score 值介于 min 和 max 之间(包括 min 和 max)的成员,有序成员是按递增(从小到大)排序。
min ,max 是包括在内,使用符号( 表示不包括。 min, max 可以使用 -inf ,+inf 表示最小和最大limit 用来限制返回结果的数量和区间。 withscores 显示 score 和 value返回值:指定区间的集合数据
zadd PHB 10000 zhangsan 9999 王五
zrangebyscore PHB 0 10000
zrangebyscore PHB 1001 10000 withscore
zrangebyscore PHB (100001 10000 withscore
- 显示整个集合的所有数据
zrangebyscore PHB -inf +inf (100001 10000 withscore
- 限制
zrangebyscore PHB -inf +inf (100001 10000 withscore limit 0 2
- zrevrangebyscore
语法:zrevrangebyscore key max min [WITHSCORES ] [LIMIT offset count]

zcount re 0 10000
zcount re 1000 10000 2 个
语法:zrevrangebyscore key max min [WITHSCORES ] [LIMIT offset count]
作用:返回有序集 key 中, score 值介于 max 和 min 之间(默认包括等于 max 或 min )的所有的成员。有序集成员按 score 值递减(从大到小)的次序排列。其他同 zrangebyscore
- zcount
语法:zcount key min max
作用:返回有序集 key 中, score 值在 min 和 max 之间(默认包括 score 值等于 min 或 max )的成员的数量
zcount salary 300 500
4. 高级话题
事务是指一系列操作步骤,这一系列的操作步骤,要么完全地执行,要么完全地不执行。
Redis 中的事务(transaction)是一组命令的集合,至少是两个或两个以上的命令,redis事务保证这些命令被执行时中间不会被任何其他操作打断。
1.事务操作的命令
(1) multi 开启事务
语法: multi
作用:标记一个事务的开始。事务内的多条命令会按照先后顺序被放进一个队列当中。
返回值:总是返回 ok
(2) exec 提交事务
语法:exec
作用:执行所有事务块内的命令
返回值:事务内的所有执行语句内容,事务被打断,返回 nil
(3) discard 放弃事务
语法:discard
./redis-cli -h 192.168.137.100作用:取消事务,放弃执行事务块内的所有命令
返回值:总是返回 ok
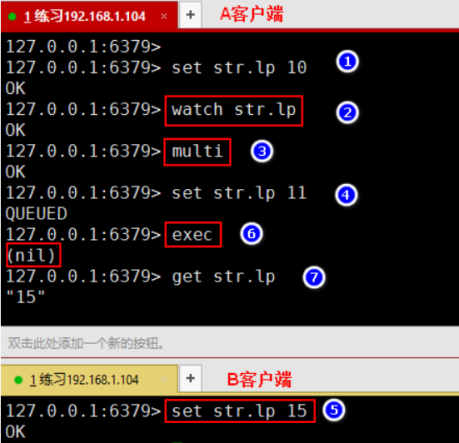
(4) watch
语法:watch key [key ...] 只要k 发生改变就取消事务
作用:监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。
返回值:总是返回 ok./redis-cli -h 192.168.137.100./redis-cli -h 192.168.137.100
(5) unwatch
语法:unwatch
作用:取消 WATCH 命令对所有 key 的监视。如果在执行 WATCH 命令之后, EXEC 命令或 DISCARD 命令先被执行了的话,那么就不需要再执行 UNWATCH 了
返回值:总是返回 ok
简单事务演示
./redis-cli -h 192.168.137.100
multi 开始事务
set k1 v2
set k2 v2
exec 提交事务
//---------
查看是否提交成功
keys *
/*-----
multi
set k4 v5
discard 放弃事务执行
keys
./redis-cli -h 192.168.137.100
错误演示
- 语句错误
192.168.137.100:6379[4]> multi
OK
192.168.137.100:6379[4]> set k10 v20
QUEUED
192.168.137.100:6379[4]> set k10 v30
QUEUED
192.168.137.100:6379[4]> set k10 v30 v20 // 语法错误 之后语句也会正常执行
QUEUED
192.168.137.100:6379[4]> set k20 v20
QUEUED
192.168.137.100:6379[4]> exec
1) OK
2) OK
3) (error) ERR syntax error
4) OK
- 下表越界
192.168.137.100:6379[4]> set k30 v20
QUEUED
192.168.137.100:6379[4]> set k40 v40
QUEUED
192.168.137.100:6379[4]> incr k40 #字符串不能进行自增操作
QUEUED
192.168.137.100:6379[4]> set k50 v50
QUEUED
192.168.137.100:6379[4]> exec
1) OK
2) OK
3) (error) ERR value is not an integer or out of range
4) OK
192.168.137.100:6379[4]>
watch的简单用法
- 应用: 查看登录人数
2.持久化
不仅仅是放到内存,序列化到磁盘中
持久化可以理解为存储,就是将数据存储到一个不会丢失的地方,如果把数据放在内存中,电脑关闭或重启数据就会丢失,所以放在内存中的数据不是持久化的,而放在磁盘就算是一种持久化。
Redis 的数据存储在内存中,内存是瞬时的,如果 linux 宕机或重启,又或者 Redis 崩溃或重启,所有的内存数据都会丢失,为解决这个问题,Redis 提供两种机制对数据进行持久化存储,便于发生故障后能迅速恢复数据。
两种持久化机制
- RDB:
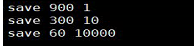
redis database ,在某个时间点,以时间戳记录当前快照的所有数据, 二进制 .rdb,若60秒 有10000key改变,就存一rdb快照到磁盘中
-
默认文件 配置文件 dump.rdb ,默认的开启的 ./ 当前目录 src下
-
当前目录看怎么执行的 启动的当前的目录
-
默认开启的持久化策略
-
配置文件
-
dbfilename dump.rdb
-
dir ./ 默认保存路径,当前目录,若启动的是src目录,就会保存到src目录
-

- AOF
append only file 增量本分 ,将你操作的语句保存到.aof 文件中,以redis的协议保存的语句,可以查看
- 配置文件
- appendonly 更改为yes
- appendfilename "appendonly.aof"
- appendfsync everysec
- no 不开启策略
- always 只要有改变的语句都会被记录到aof 文件中 ,吃性能
- everysec 将每秒钟的执行语句,记录到aof文件中 --< 最优 默认
redis 在启动的时候,都会先读取持久化数据,然后去恢复
- 开启aof
修改配置文件
appendonly 更改为yes
存储几个键值对之后
set k1 v2
exit
查看文件 cat appendonly.aof
*2 执行几条,有几步操作
$ 占用字符 6
cat appendonly.aof
64M
同时使用
优先加载AOF

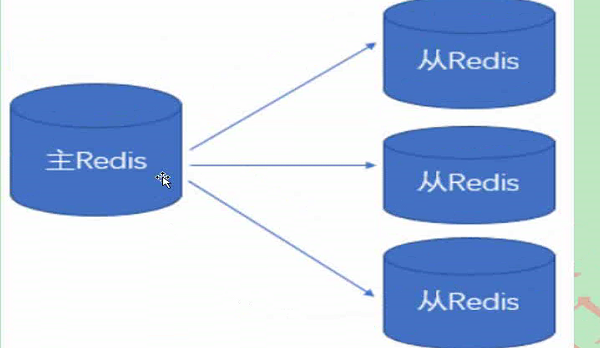
5. 主从复制
- 读写分离
1.一主多从
- 集群
通过持久化功能,Redis 保证了即使在服务器重启的情况下也不会丢失(或少量丢失)数据,但是由于数据是存储在一台服务器上的,如果这台服务器出现故障,比如硬盘坏了,也会导致数据丢失。
为了避免单点故障,我们需要将数据复制多份部署在多台不同的服务器上,即使有一台服务器出现故障其他服务器依然可以继续提供服务。
这就要求当一台服务器上的数据更新后,自动将更新的数据同步到其他服务器上,那该怎么实现呢?Redis的主从复制。
演示: 复制 redis.conf 搞四次
cp redis.conf redis-6380.conf 并修改 6382 6384
第一种,在原有文件基础上做修改
daemonize yes
port 6380
pidfile /var/run/redis_6380.pid
logfile 6380.log
dbfilename dump6380.rdb
appendfilename "appendonly-6380.aof"
第二种 新建文件 touch
include /usr/local/redis-4.0.13/redis.conf
daemonize yes
port 6380
pidfile /var/run/redis_6380.pid
logfile 6380.log
dbfilename dump6380.rdb
appendfilenanme "appendonly-6380.aof"
主节点不用做任何配置
从节点需要在配置上加上一条
slaveof 127.0.0.1 6380
整体
include /usr/local/redis-4.0.13/redis.conf
daemonize yes
port 6380
pidfile /var/run/redis_6380.pid
logfile 6380.log
dbfilename dump6380.rdb
appendfilenanme "appendonly-6380.aof"
slaveof 127.0.0.1 6380
6380 是主 6382 6384 是从
- 启动
启动父节点
./redis-server ../redis-6380.conf
./redis-server ../redis-6382.conf
./redis-server ../redis-6384.conf
防火墙要开发端口
- 查看当前节点的信息
连接指定端口 ./redis-cli -p 6380
查看详细
info replication
注意:
从节点只能读不能写
- 模拟故障
2.容灾处理
主节点关闭( showdown 模拟故障)
1.升级 6382--->
slaveof no one----> info replication
2. 原有的从节点 挂在到6382
6384 : slaveof 127.0.0.1 6382
3.若主机修复好了
6380: slaveof 127.0.0.1 6382
是一种 手动进行切换
主从复制 , 读写分离
手动切换故障: 效率低
手动停掉6380节点
选择一个新的主节点 6382
变更节点信息,将6384 从属节点进行变更,变为6382的从节点
重新启动6380节点,将其挂载到 6382 主节点上
- 手动切换故障
2. 高可用sentinel 哨兵模式,自动故障切换和转移
为了避免手动切换故障,使用哨兵模式;进行操作,自动进行故障切换以及转移
-
Sentinel 哨兵是 redis 官方提供的高可用方案,可以用它来监控多个 Redis 服务实例的运行情况。Redis Sentinel 是一个运行在特殊模式下的 Redis 服务器。Redis Sentinel 是在多个Sentinel 进程环境下互相协作工作的。
-
Sentinel 系统有三个主要任务:
- 监控:Sentinel 不断的检查主服务和从服务器是否按照预期正常工作。
- 提醒:被监控的 Redis 出现问题时,Sentinel 会通知管理员或其他应用程序。
- 自动故障转移:监控的主 Redis 不能正常工作,Sentinel 会开始进行故障迁移操作。将一个从服务器升级新的主服务器。让其他从服务器挂到新的主服务器。同时向客户端提供新的主服务器地址。
-
哨兵知道所有redis 的节点的状态信息,若有一台redis 出现故障,那么哨兵就会差距,通过选择方式

1. 哨兵模式的配置sentnel.conf
端口 port
目录 dir /tmp
哨兵监控那个主节点 sentinel monitor mymaster 127.0.0.1 6382(主节点端口) 2 (投票数)
cp sentnel.conf sentnel-26380.conf 82 84 都要该
- 修改配置文件
修改端口
port 26380
修改监控的master
sentinel monitor mymaster 127.0.0.1 6382(主节点端口) 2(投票数)
- 启动哨兵
./redis-sentinel ../sentinel-26380.conf
./redis-sentinel ../sentinel-26382.conf
./redis-sentinel ../sentinel-26384.conf
之间相互通讯
- 假设主节点宕机
- 停掉 6382

- 修复成功后: 自动就挂在上去了 还要改正下 指定父节点

3个哨兵+3个redis
3. 安全设置
为配置文件添加密码信息 redis.conf 去掉注释
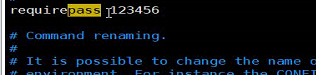
重启启动 redis服务器
客户端 -a 登录密码
./redis-cli -p 6379 -a 123456
set
---
进入系统之后
auth 123456

6. Jedis
使用 Redis 官方推荐的 Jedis,在 java 应用中操作 Redis。Jedis 几乎涵盖了 Redis 的所有命令。
实践:
1.导入依赖
archetypeCatalog
archertyper_Catalog internal
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.3.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-pool2 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.8.1</version>
</dependency>
2.实际操作
- 第一个
public static void main(String[] args) {
//创建Jedis对象,指定redis的链接地址
Jedis jedis = new Jedis("192.168.8.128",6379);
//Jedis提供的方法,大多数都是基于redis的命令操作的
jedis.select(0);
jedis.flushAll();
jedis.set("k4","v4");
jedis.set("k5","v5");
String k4 = jedis.get("k4");
String k5 = jedis.get("k5");
System.out.println("k4 : [ "+k4+" ]");
System.out.println("k5 : [ "+k5+" ]");
}
- 第二个 线程池 满足安全需要 连接池创建密码
public static void main(String[] args) {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(10);
jedisPoolConfig.setMaxIdle(3);
jedisPoolConfig.setTestOnBorrow(true);
//创建连接池对象
//GenericObjectPoolConfig poolConfig, String host, int port, int timeout, String password
//参数1:连接池的配置
//参数2:host地址
//参数3:端口号
//参数4:超时时间
//参数5:连接密码
JedisPool jedisPool = new JedisPool(jedisPoolConfig, "192.168.8.128", 6379, 5, "123456");
//通过连接池获取Jedis对象
Jedis jedis = jedisPool.getResource();
//开启事务
Transaction transaction = jedis.multi();
String k1 = jedis.get("k1");
String k4 = jedis.get("k4");
String k5 = jedis.get("k5");
//TODO 自行练习String类型List类型Hash类型Set类型
//TODO 自行练习ZSet类型
//提交事务
transaction.exec();
//取消事务
// transaction.discard()
System.out.println("[ " + k1 + " " + k4 + " " + k5 + " ]");
//关闭资源
// jedis.close();
jedisPool.close();
}

