

Professional Linux Kernel Architecture(一)
基于linux内核2.6.24版本,书籍:Professional Linux Kernel Architecture英文版(可在https://github.com/welldef/os_books.git下载)
1 一些概念
1.1 微内核和单体内核
微内核:只有最基本的功能直接在中央内核(微内核)中实现。所有其他功能都委托给各自独立的进程,这些进程通过通信接口与微内核通信,例如各种文件系统、内存管理等。理论上,这是一种非常优雅的方法,因为各个部分明显相互隔离,这迫使程序员使用“精益”编程技术。这种方法的其他好处是动态可扩展性和在运行时交换重要组件的能力。然而,由于需要额外的CPU时间来支持组件之间的复杂通信,微内核在实践中并没有真正建立起来
单体内核:内核的整个代码(包括其所有子系统,如内存管理、文件系统或设备驱动程序)都打包到一个文件中。每个函数都可以访问内核的所有其他部分
linux使用的是单体内核,但其模块化特性确实在一定程度上借鉴了微内核的理念
1.2 内核组成

进程、任务切换和调度
在Unix下运行的应用程序、服务和其他程序被称为进程。各个进程的地址空间是完全独立的。
linux是多任务系统,多任务系统中,内核将负责进程的切换。既然是多任务系统,则该系统必须给每个单独的进程一种CPU始终可用的错觉。这是通过在CPU资源被回收并且进程被置于空闲状态之前保存进程的所有状态来实现的。当该进程被重新激活时,恢复保存的状态。
内核还必须决定如何分配CPU时间。重要进程被分配了更大的CPU时间份额,而不太重要的进程则被分配了更小的份额。决定哪个进程运行多长时间被称为进程的调度
2 进程管理
进程的状态
- Running: 进程当前正在执行。
- Waiting: 进程能够运行,但不允许运行,因为CPU被分配给了另一个进程。如果调度器愿意,它可以在下一次任务切换时选择进程。
- Sleeping: 进程正在休眠,无法运行,因为它正在等待外部事件。调度程序无法在下一次任务切换时选择进程。
- zombie: 僵尸状态,指的是子进程已经终止,但是父进程还未调用wait4(wait for)系统调用的临时状态
系统存储所有进程到一个进程表里,处于Sleeping状态的进程被特殊标记出来,以便调度器知道它不能被调度。同时系统中还有几个队列来分组这些Sleeping状态的进程以便在某个事件发生时唤醒这些队列中的进程
有关zombie状态:一个进程终止有两个条件:1 程序必须被另一个进程或用户终止(这通常通过发送SIGTERM或SIGKILL信号来完成,这相当于正常终止进程);2 父进程必须调用wait4(wait for)系统调用,向内核确认父进程已经知晓子进程的终止。这个系统调用允许内核释放子进程预留的资源。;当只有第一个条件(程序已终止)成立而第二个条件(wait4)不成立时,就会出现僵尸进程。一个进程在终止和从进程表中移除其数据之间,总是会短暂地切换到僵尸状态。在某些情况下(例如,如果父进程编程不当且没有发出wait调用),僵尸进程会牢固地停留在进程表中,并一直保持在那里,直到下一次重新启动。这可以通过读取如ps或top等进程工具的输出结果来看到。由于残留数据在内核中占用的空间很小,所以这几乎不是问题。
2.1 抢占式多任务处理
抢占式进程切换是有好处的,抢占式多任务切换对良好的交互行为和低系统延迟是有益的。比如编辑器收到期待已久的键盘输入,即使当前进程正在正常执行,调度器可以决定立即执行编辑器进程。
如果系统处于内核态并且正在处理系统调用,则系统中没有其他进程能够导致CPU时间的占用。调度器必须等待系统调用执行完毕,然后才能选择另一个进程。但是,中断可挂起系统调用。
中断具有最高优先级,因为当中断发生时,必须尽快处理中断。中断可以挂起处理内核态和用户态的进程。
2.2 创建新进程
Linux采用树形结构管理进程之间的关系,称之为进程树,其中每个进程都依赖于一个父进程。内核启动时会初始化1号进程-init进程,init进程作为所有用户进程的根,它负责进一步的系统初始化工作以及显示登录提示等等功能。(新版本的内核1号进程已经变为systemd了)
影响进程树结构的关键因素fork和exec
- fork:生成当前进程的精确副本,该副本与父进程完全相同,只有PID不同。创建之初共享同一代码段和数据段,当子进程或父进程需要写时(写时复制方式),进程的代码段和数据段才真正分开。
- exec:在当前进程中执行新的程序实体,旧的内存页被新的内存页替换。
线程(也叫轻量级进程):共享相同的数据(代码段和数据段)和资源,但是执行不同的代码分支(比如java,一个java虚拟机是一个进程,但是我们可以创建多线程,其共享同一java代码,但是执行代码中的不同分支,有时执行同一分支但是可作并发控制措施)。因为有了线程,执行多任务时比创建新进程更快、更简便。使用clone创建线程(轻量级进程)
- clone:clone()是一个更通用、更灵活的版本,它允许调用者指定哪些资源应该被新进程共享,哪些应该被复制。通过使用clone(),可以创建所谓的线程(轻量级进程),这些线程共享相同的地址空间和其他资源,但每个线程都有自己的执行流(都可参与CPU时间片分配)。
2.2.1 COW(写时复制)技术
传统上,每当一个进程(父进程)通过fork系统调用创建一个新进程(子进程)时,整个进程的地址空间(包括数据、代码等)都需要被复制到子进程中。然而,这种做法非常耗时且效率低下,特别是当进程占用大量内存时。
为了解决这个问题,内核采用了一个巧妙的方法:不是复制整个进程的地址空间,而是仅复制进程的页表(Page Tables)。页表是操作系统用于将进程的虚拟地址空间映射到物理内存中的物理页面上的数据结构。在进程fork时,只复制页表意味着父进程和子进程会共享相同的物理页面,直到它们中的任何一个尝试修改那些页面为止。
当任何一个进程尝试修改共享的物理页面时,会触发一个写时复制(Copy-on-Write, COW)的操作。此时,内核会复制被修改的页面到新的物理内存中,并更新页表,使得父进程和子进程各自指向自己的物理页面副本。这样,只有在需要时才会复制内存,大大提高了fork操作的效率。
进程尝试写入其内存空间中被标记为只读或未分配(即被复制但尚未明确赋予写权限)的页面时,会触发一种称为“页面错误”(Page Fault)的访问错误。这种错误由处理器捕获并报告给操作系统的内核进行处理。操作系统对应的异常处理例程将会被执行,然后执行内存页换入和换出逻辑
2.2.2 系统调用的执行过程
fork、vfork、clone这三个系统调用分别是通过sys_fork、sys_vfork、sys_clone函数调用的。这三个函数的作用是从处理器的寄存器中提取用户空间提供的信息,然后调用与体系结构相关的 do_fork 函数来负责进程的复制。这些函数的实现是与CPU架构强相关的,因为不同架构用户空间和内核空间的传参方式不同。下面以x86架构为例:
asmlinkage int sys_fork(struct pt_regs regs) { return do_fork(SIGCHLD, regs.esp, ®s, 0, NULL, NULL);//这里只传递了SIGCHLD表示子进程结束时会向父进程发送SIGCHLD信号;第二个参数是父进程用户栈地址,说明起初子进程和父进程共享用户栈,但是COW机制会保证子进程有独立的用户栈空间 }
sys_clone

asmlinkage int sys_clone(struct pt_regs regs) { unsigned long clone_flags;//和sys_fork相比,不再是固定的,而是根据ebx寄存器指定 unsigned long newsp;//和sys_fork相比,不再共享父进程的栈,这对于线程非常重要,多个线程可共享地址空间但是有自己独立的栈空间 int __user *parent_tidptr, *child_tidptr; clone_flags = regs.ebx;//在x86架构(以及许多其他架构)中,系统调用的参数传统上是通过特定的寄存器传递的。ebx:用于传递clone_flags;ecx:用于传递newsp;edx:指向父进程用户空间中的位置,用于存储新进程的PID;edi:指向子进程用户空间中的位置,用于存储子进程的PID newsp = regs.ecx; parent_tidptr = (int __user *)regs.edx; child_tidptr = (int __user *)regs.edi; if (!newsp) newsp = regs.esp; return do_fork(clone_flags, newsp, ®s, 0, parent_tidptr, child_tidptr); }
do_fork原型
long do_fork(unsigned long clone_flags, unsigned long stack_start, struct pt_regs *regs, unsigned long stack_size, int __user *parent_tidptr, int __user *child_tidptr)
它允许用户通过一系列参数定制新进程或线程的行为。下面是对你提供的参数的详细解释:
- clone_flags:用于指定复制过程的特性。这个参数的低字节(最低8位)通常用来指定子进程终止时发送给父进程的信号编号(不过,在大多数实现中,这一功能并不常用)。而高字节则包含了一系列的标志位,用于控制各种复制行为,比如是否共享内存空间(CLONE_VM)、是否共享文件描述符表(CLONE_FILES)、是否共享信号处理器(CLONE_SIGHAND)等。这些标志位允许在进程创建时实现精细的控制,包括创建轻量级线程(如 POSIX 线程)的能力。
- stack_start:这是用户栈的起始地址。在创建新进程时,需要为其分配一个新的栈空间,stack_start 就是这个栈空间的起始地址。这个地址通常是在用户空间中分配的一块连续内存区域的起始位置。
- regs:这是一个指向 pt_regs 结构体的指针,pt_regs 是架构相关的结构体,用于在系统调用或异常发生时保存寄存器的状态。在 do_fork 的上下文中,regs 包含了调用 do_fork 时的寄存器状态,这些状态可能会被复制到新进程中,以便新进程能够继续执行。
- stack_size:这个参数指定了用户模式栈的大小。然而,在大多数实现中,这个参数并不被直接使用,而是被设置为 0。这是因为 Linux 内核通常会自己管理栈的大小,而不是依赖于这个参数。
- parent_tidptr 和 child_tidptr:这两个参数是指向用户空间地址的指针,分别用于存储父进程和子进程的线程ID(TID)。这两个参数是 NPTL(Native POSIX Threads Library)线程实现的一部分,允许库在创建线程时获取线程ID,并将其存储在用户指定的位置。这对于线程间的同步和通信非常重要。
do_fork定义
long do_fork(unsigned long clone_flags, unsigned long stack_start, struct pt_regs *regs, unsigned long stack_size, int __user *parent_tidptr, int __user *child_tidptr) { struct task_struct *p; int trace = 0; long nr; p = copy_process(clone_flags, stack_start, regs, stack_size, child_tidptr, NULL);
if (!IS_ERR(p)) { struct completion vfork; nr = (clone_flags & CLONE_NEWPID) ? //是否clone_flags中设置了创建新的PID名称空间,处理逻辑不同 task_pid_nr_ns(p, current->nsproxy->pid_ns) : task_pid_vnr(p); if (clone_flags & CLONE_PARENT_SETTID) put_user(nr, parent_tidptr); if (clone_flags & CLONE_VFORK) { p->vfork_done = &vfork; init_completion(&vfork); }
这里着重说明以下几点:
- copy_process函数完成实际的子进程的创建,并返回新进程结构的指针,稍后会介绍这个函数
- 因为涉及到名称空间的存在,如果clone_flags中设置了创建新的PID名称空间,则获取新进程PID的逻辑有所不同,见上面注释
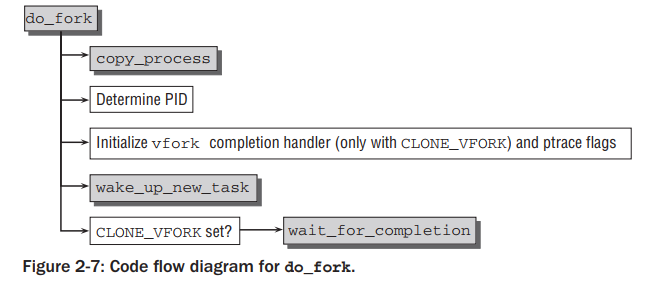
copy_process函数
- 每种CPU架构基本上都会将虚拟地址0-4kb(至少到4kb)的空间作为预留区域,内核使用这个范围的指针区域来编码错误码
- 如果返回的指针落到这个范围内,则说明copy_process调用失败了,失败原因则可以由指针指向的数值来决定。
- ERR_PTR是一个宏,用于进行特定的转换(转换细节还未搞清楚)
- CLONE_THREAD和CLONE_SIGHAND必须同时传递。意思是线程组必须共享信号量
- CLONE_VM和CLONE_SIGHAND必须同时传递。意思是如果虚拟地址设置为共享,那么信号处理也必须共享
- 经过上面的一些校验后,会调用 dup_task_struct 函数进行task_struct结构的复制。
- 新旧进程只有两处不同:
- 新进程会被分配一个新的内核栈(task_struct->stack,和thread_info使用同一个union)
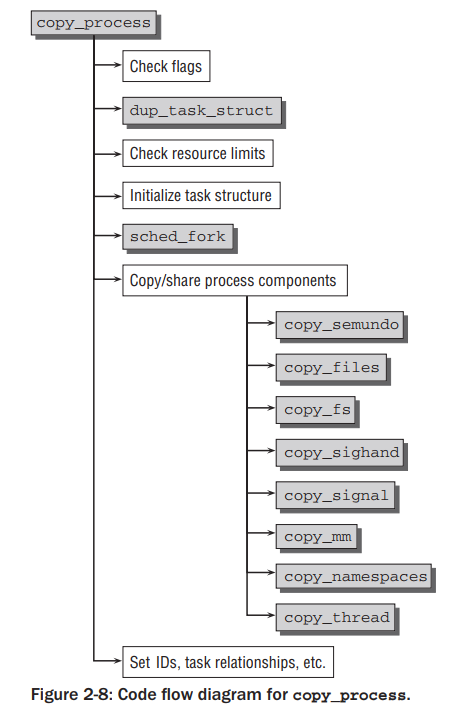
static struct task_struct *copy_process(unsigned long clone_flags, unsigned long stack_start, struct pt_regs *regs, unsigned long stack_size, int __user *child_tidptr, struct pid *pid) { struct task_struct *p; if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS)) //处理一些异常情况,比如clone_flags不能同时配置为CLONE_NEWNS(创建一个新的名称空间)和CLONE_FS(共享所有文件系统信息) return ERR_PTR(-EINVAL);//每种CPU架构基本上都会将虚拟地址0-4kb(至少到4kb)的空间作为预留区域,内核使用这个范围的指针区域来编码错误码 if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND)) //CLONE_THREAD和CLONE_SIGHAND必须同时传递。意思是线程组必须共享信号量 return ERR_PTR(-EINVAL); if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM)) //如果虚拟地址设置为共享,那么信号处理也必须共享 return ERR_PTR(-EINVAL); p = dup_task_struct(current); //进行实际task_struct结构的拷贝 if (!p) goto fork_out; if ((retval = copy_files(clone_flags, p))) goto bad_fork_cleanup_semundo; if ((retval = copy_signal(clone_flags, p))) goto bad_fork_cleanup_sighand; if ((retval = copy_mm(clone_flags, p))) goto bad_fork_cleanup_signal; if ((retval = copy_keys(clone_flags, p))) goto bad_fork_cleanup_mm; if ((retval = copy_namespaces(clone_flags, p))) goto bad_fork_cleanup_keys; p->pid = pid_nr(pid); p->tgid = p->pid; //线程组id就是创建者的PID if (clone_flags & CLONE_THREAD) p->tgid = current->tgid; //对于线程(传递了CLONE_THREAD参数)来说,线程的parent不是创建者,而是创建者的parent。同理,对创建进程时传递了CLONE_PARENT参数也是如此 if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) //对于线程来说,线程的parent不是创建者,而是创建者的parent p->real_parent = current->real_parent; else p->real_parent = current; p->parent = p->real_parent; if (clone_flags & CLONE_THREAD) { p->group_leader = current->group_leader; //如果是线程,那么线程的group_leader是当前进程的group_leader list_add_tail_rcu(&p->thread_group, &p->group_leader->thread_group); } }
多处调用了copy_xyz函数,用来拷贝或共享内核子系统的相关资源,比如copy_files,如果我们传递了CLONE_FILES标识,那么新进程和旧进程的文件描述符的引用计数都将会增1
static int copy_files(unsigned long clone_flags, struct task_struct * tsk) { struct files_struct *oldf, *newf; int error = 0; if (clone_flags & CLONE_FILES) { atomic_inc(&oldf->count);//旧进程引用计数加1 goto out; } /* * Note: we may be using current for both targets (See exec.c) * This works because we cache current->files (old) as oldf. Don't * break this. */ tsk->files = NULL; newf = dup_fd(oldf, &error); if (!newf) goto out; tsk->files = newf;//新进程引用计数也加1 error = 0; out: return error; }
如上所述,内核栈存储在thread_union共用体中
<sched.h> union thread_union { struct thread_info thread_info; unsigned long stack[THREAD_SIZE/sizeof(long)]; };
大部分架构下,使用1到2个内存页来存储thread_union实例,比如在IA-32架构下,默认使用2页,因为thread_info占用一部分空间,因此可用内核栈大小比8KiB稍小一点。
内核提供了一个参数4KSTACKS用来设置stack大小为4KiB(1页),这在有大量进程运行的情况下是有益的,因为每个进程都节省了1页内存。
虽然内核的核心部分已经设计为能够在较小的栈大小下运行,但外部驱动程序(特别是仅提供二进制的驱动程序)可能未经过优化,可能会占用大量栈空间。这可能导致在使用较小栈大小时出现兼容性问题,因为驱动程序可能会超出分配的栈空间。
下面是stack和thread_info之间的关系示意图

2.3 Namespace
名称空间可以分离系统资源。可以给系统资源多个视图。
通过名称空间实现容器来创建系统的多个视图,而不是为每个客户设置一台物理机器,每个容器是相互分离的,看起来都像一台运行Linux的机器。这有助于更有效地利用资源。
与KVM等完全虚拟化解决方案相比,名称空间方式实现的容器只需要一个内核在机器上运行,并负责管理所有容器。
通过名称空间的隔离,允许将一组进程放入一个容器中,并且一个容器与其他容器是隔离的。这种隔离可以使得一个容器中的成员与其他容器没有任何联系。然而,也可以通过允许容器共享其生命周期的某些方面来放宽容器之间的隔离。例如,可以设置容器使用自己的PID集,但仍共享文件系统的部分内容。
命名空间本质上创建了系统的不同视图。全局的资源都必须封装在容器数据结构中,名称空间+资源组成的元组才是全局唯一的。
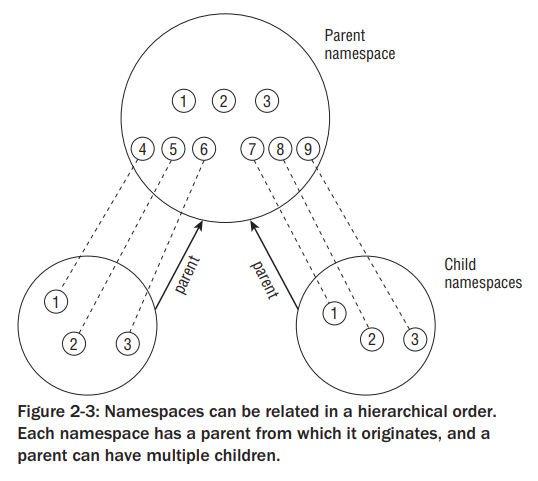
例子:如下图,有3个名称空间,一个命名空间是父命名空间,它产生了两个子命名空间。假设容器被用于单独主机,其中每个容器必须看起来像一台Linux机器。因此,它们中的每一个都有自己的PID为1的初始化任务。两个子命名空间都有一个PID为1的init任务,以及两个PID分别为2和3的进程。由于具有相同值的PID在系统上出现多次,因此这些数字不是全局唯一的。两个子容器感知不到其他容器的存在,但是父容器可以看到子容器中执行的所有进程(它们被映射到父容器的PID号:4-9)
UTS(UNIX Timesharing System)名称空间是namespace的一个子系统,通过它,不同的进程或容器可以拥有独立的主机名和域名信息,从而实现运行环境的隔离。UTS名称空间是扁平化的结构,不同的命名空间之间没有层级关系。每个容器或进程都对应一个自己的UTS名称空间,用于隔离其内核名称、版本和主机名等信息。在容器技术(如Docker)中,UTS名称空间被广泛应用来实现容器的隔离。每个容器都运行在自己的UTS名称空间中,拥有独立的主机名和域名信息,从而实现了轻量级、可移植和可扩展的应用程序打包和部署。
2.3.1 创建名称空间的2种方式
- fork或clone系统调用创建新进程时,通过传递特殊的选项控制名称空间是否创建或者是否和父进程共享
- 通过unshare系统调用,将当前进程的一些属性和父进程剥离,其中就包含名称空间属性
2.3.2 命名空间的实现方式如下所示
需要几个特殊的数据结构:nsproxy、uts_namespace、ipc_namespace、mnt_namespace、pid_namespace、user_namespace、net
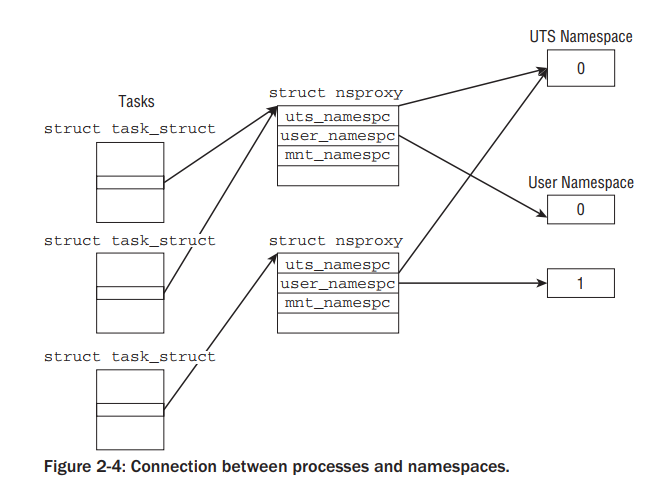
在task_struct中的定义
struct task_struct { ... /* namespaces */ struct nsproxy *nsproxy; ... }
nsproxy的定义
struct nsproxy { atomic_t count; struct uts_namespace *uts_ns; struct ipc_namespace *ipc_ns; struct mnt_namespace *mnt_ns; struct pid_namespace *pid_ns; struct user_namespace *user_ns; struct net *net_ns; };
- struct ipc_namespace UTS 命名空间包含正在运行的内核的名称、版本、底层架构类型等信息。UTS 是 Unix Timesharing System(Unix 分时系统)的缩写。
- 所有与进程间通信(IPC)相关的信息都存储在 struct ipc_namespace 中。
- struct mnt_namespace 提供了已挂载文件系统的视图。
- struct pid_namespace 提供了有关进程标识符的信息。
- struct user_namespace 用于保存每个用户的信息,这些信息允许限制单个用户的资源使用。
- struct net_ns 包含所有与网络相关的命名空间参数。
命名空间的支持需要在编译操作系统内核时针对每个命名空间类型进行启用。这意味着开发者可以根据需要选择性地启用或禁用特定类型的命名空间支持。
这种设计允许系统在不同使用场景下进行优化,比如在一个不需要复杂隔离的环境中,可以禁用某些命名空间以节省资源。
尽管命名空间支持是按需启用的,但内核总是包含处理命名空间概念的通用代码和框架。这意味着即使某个特定的命名空间类型没有被启用,内核也能够处理与命名空间相关的逻辑。
这种设计使得内核能够以一种统一的方式处理不同的系统配置,无论是否启用了命名空间。
每个进程都关联了一个默认的命名空间,除非明确指定使用其他命名空间。这个默认命名空间为进程提供了一个全局的、未隔离的环境。
当命名空间支持没有被编译进内核时,所有进程都将在这个默认命名空间中运行,此时所有的属性和资源都是全局的,就像传统的没有命名空间支持的系统一样。
命名空间感知代码可以在任何系统上运行,无论是否启用了命名空间支持。
如果命名空间支持被禁用,这些代码将自动回退到使用默认命名空间,其行为将与没有命名空间的系统相同。
2.3.3 nsproxy的初始化
<kernel/nsproxy.c>
struct nsproxy init_nsproxy = INIT_NSPROXY(init_nsproxy);
其中INIT_NSPROXY在liclude/linux/init_task.h中定义
#define INIT_NSPROXY(nsproxy) { \ .pid_ns = &init_pid_ns, \ .count = ATOMIC_INIT(1), \ .uts_ns = &init_uts_ns, \ .mnt_ns = NULL, \ INIT_NET_NS(net_ns) \ INIT_IPC_NS(ipc_ns) \ .user_ns = &init_user_ns, \ }
上面结构中的UTS名称空间得初始化init_uts_ns
struct uts_namespace init_uts_ns = { .kref = { .refcount = ATOMIC_INIT(2), }, .name = { .sysname = UTS_SYSNAME, .nodename = UTS_NODENAME, .release = UTS_RELEASE, .version = UTS_VERSION, .machine = UTS_MACHINE, .domainname = UTS_DOMAINNAME, }, };
其中uts_namespace定义如下:
struct uts_namespace { struct kref kref; struct new_utsname name; };
new_utsname定义
struct new_utsname { char sysname[65]; char nodename[65]; char release[65]; char version[65]; char machine[65]; char domainname[65]; };
2.3.4 创建新的UTS名称空间
在Linux内核中,创建一个新的UTS命名空间是进程隔离和资源管理的一个重要方面。也是Docker等容器技术的基础。以下是关于如何创建新的UTS命名空间的详细过程:
1. 调用fork或clone系统调用
当进程需要创建一个新的子进程,并且希望这个子进程拥有独立的UTS命名空间时,它会在调用fork或clone系统调用时设置CLONE_NEWUTS标志。这个标志告诉内核,在创建新进程时,需要为其分配一个新的UTS命名空间。
2. 调用copy_utsname函数
一旦设置了CLONE_NEWUTS标志,内核就会调用copy_utsname函数。这个函数的职责是创建一个当前UTS命名空间的副本,并将这个副本与新创建的进程相关联。具体来说,copy_utsname会执行以下操作:
- 分配一个新的uts_namespace结构体,用于存储新的UTS命名空间的信息。
- 从当前进程的UTS命名空间中复制必要的信息到新的uts_namespace结构体中。这些信息可能包括系统名(虽然通常不会更改)、节点名(可能需要根据需要进行修改)等。
- 将新的uts_namespace结构体的指针安装到当前任务的nsproxy实例中。nsproxy是内核中用于管理命名空间的结构体,它包含了指向各种命名空间的指针。
3. 隔离UTS命名空间
一旦新的UTS命名空间被创建并与新进程相关联,内核就会确保该进程在读取或设置UTS值时总是操作其特定的uts_namespace实例。这意味着,对当前进程所做的UTS更改不会反映到其父进程中,同样,父进程对UTS的更改也不会传播到子进程中。这种隔离机制是实现容器化技术(如Docker)和命名空间隔离的基础。
Linux内核通过copy_utsname函数和CLONE_NEWUTS标志实现了UTS命名空间的创建和隔离。这种机制为进程提供了独立的UTS视图,从而实现了对系统标识信息的精细控制和管理。
2.3.5 User名称空间
一个用户对应一个user_namespace结构体,不同名称空间中的root用户对应的user_namespace实例是不同的
User名称空间的处理和上面提到的UTS名称空间的处理方式相同,当需要一个新的User名称空间时,会生成当前用户命名空间的副本,并将其与当前任务的nsproxy实例相关联。然而,用户命名空间本身的表示稍微复杂一些
struct user_namespace { struct kref kref; //kref是一个引用计数器,用于跟踪user_namespace实例被引用的次数 struct hlist_head uidhash_table[UIDHASH_SZ]; struct user_struct *root_user; //当前用户的引用计数、打开的文件数、拥有的进程数等资源统计 };
2.4 进程标识
- PID:每个进程在系统中都有一个唯一的进程ID
- TGID:线程组由具有相同线程组ID(TGID)的多个进程(或更准确地说是线程)组成。如果一个进程不使用线程(即它是单线程的),那么它的PID和TGID是相同的。
- pgrp:进程组。进程组中所有进程的task_struct中的pgrp元素都具有相同的值,这个值就是进程组leader的PID
- Session:会话中的所有进程都有相同的会话ID(SID),这个SID存储在每个进程的task_struct中的session元素里。
2.5 内核线程
内核线程(Kernel threads)是由内核自身直接启动的进程。可以说0号(idel进程)、1号(init进程)、2号(kthreadd进程)进程都是内核线程,除此之外,还有几个常见的内核线程:
kthreadd:
作用:kthreadd是内核中负责管理其他内核线程的父进程。它在系统启动时由0号进程(idle进程)创建,负责调度和管理其他内核线程。
数量:通常只有一个。
migration:
作用:每个处理器核对应一个migration内核线程,主要用于执行进程迁移操作。当进程需要从一个CPU迁移到另一个CPU时,migration线程会负责处理这些迁移请求。
数量:与处理器核的数量相对应。
watchdog:
作用:watchdog线程用于监视系统的运行状态,以防止系统出现死锁或软件故障。如果系统在一定时间内没有响应,watchdog会尝试重启系统。
数量:每个处理器核对应一个watchdog线程。
ksoftirqd:
作用:ksoftirqd线程用于处理软中断。由于硬件中断处理需要快速响应,但中断处理过程中可能需要进行大量计算或等待,因此将部分中断处理任务移交给软中断处理线程ksoftirqd。
数量:通常与处理器核的数量相对应。
比如,我们看看真实系统中的watchdog线程,可以看到其父进程是2号进程(kthreadd),且其数量和CPU个数对应
$ ps -ef|grep watchdog root 11 2 0 5月14 ? 00:01:07 [watchdog/0] root 12 2 0 5月14 ? 00:00:57 [watchdog/1] root 17 2 0 5月14 ? 00:00:55 [watchdog/2] root 22 2 0 5月14 ? 00:00:56 [watchdog/3] root 27 2 0 5月14 ? 00:00:56 [watchdog/4] root 32 2 0 5月14 ? 00:00:56 [watchdog/5] root 37 2 0 5月14 ? 00:00:57 [watchdog/6] root 42 2 0 5月14 ? 00:00:56 [watchdog/7] root 59 2 0 5月14 ? 00:00:00 [watchdogd] root 2521 2 0 5月14 ? 00:00:00 [lc_watchdogd] P_bc_qs+ 21097 15974 0 09:34 pts/0 00:00:00 grep --color=auto watchdog
2.5.1 内核线程的创建
旧方式
内核调用函数kernel_thread创建内核线程。其定义和cpu架构有关,以x86架构为例。
pt_regs是一个结构体,用于保存CPU的寄存器状态。在kernel_thread中,首先会构造一个pt_regs实例,并为其成员设置适当的值,以模拟一个来自系统调用的调用环境。这样做是为了让新线程在启动时能够表现得像是一个从系统调用返回的进程。
然后,调用do_fork函数来实际创建新线程
int kernel_thread(int (*fn)(void *), void * arg, unsigned long flags) { struct pt_regs regs; memset(®s, 0, sizeof(regs)); regs.ebx = (unsigned long) fn; regs.edx = (unsigned long) arg; regs.xds = __USER_DS; regs.xes = __USER_DS; regs.xfs = __KERNEL_PERCPU; regs.orig_eax = -1; regs.eip = (unsigned long) kernel_thread_helper; regs.xcs = __KERNEL_CS | get_kernel_rpl(); regs.eflags = X86_EFLAGS_IF | X86_EFLAGS_SF | X86_EFLAGS_PF | 0x2; /* Ok, create the new process.. */ return do_fork(flags | CLONE_VM | CLONE_UNTRACED, 0, ®s, 0, NULL, NULL); }
内核线程和用户线程有一个区别,就是task_struct中的mm被设置为NULL
<sched.h> struct task_struct { ... struct mm_struct *mm, *active_mm; ... }
mm_struct它代表了进程的内存描述符(Memory Descriptor)。每个进程在Linux中都有一个与之对应的内存描述符,用于管理该进程所拥有的内存资源,包括代码段、数据段、堆栈段以及通过系统调用如 mmap() 分配的内存区域等。
在Linux系统中,TLB(Translation Lookaside Buffer,转换后援缓冲器,或简称为“快表”)是一个关键的硬件组件,它负责加速虚拟地址到物理地址的转换过程。因为不论内核态还是用户态中运行的程序,都会涉及到虚拟地址到物理地址的转换,转换时需要根据页表定位到虚拟地址对应的物理地址,有时需要经过多级映射才能找到物理地址。TLB提供了一个硬件缓存,缓存了最近最常用虚拟地址和物理地址间的映射关系,极大地提高了内存访问的效率。
对于内核线程来说,它们主要在内核空间运行,不直接访问用户空间。然而,内核线程仍然需要访问物理内存,以执行各种内核任务,如系统调用处理、中断处理、设备驱动等。在这些过程中,内核线程会生成虚拟地址,并通过TLB和页表来查找对应的物理地址。值得注意的是,内核线程在地址转换时可能会采用一种称为“懒惰模式”(Lazy Mode)的优化策略。由于内核线程不直接访问用户空间,且Linux系统中所有进程的内核部分页面映射是相同的,因此当内核线程运行时,如果它之前运行的用户进程的TLB条目仍然有效(即没有发生页表更改或进程切换),那么内核线程可以继续使用这些TLB条目,而无需立即刷新TLB。这种策略可以减少不必要的TLB刷新操作,从而提高系统性能。
上面已经提到task_struct中的mm被设置为NULL,它们不访问用户空间,因此自然而然地成为了这种优化策略的应用对象。总结一句话:内核线程执行期间不会进行TLB的更新,因而可以提高系统性能。
那为什么还需要active_mm呢?active_mm指针保存了一个指向当前活动用户进程的mm_struct的指针,该结构体描述了用户空间的虚拟地址空间布局。极特殊情况下,当内核线程需要访问与用户空间相关的数据时,它可以通过active_mm来获取必要的信息
有时,内核可能会以一种特殊的方式创建内核线程,即利用现有的用户进程上下文来创建内核线程。这种情况下,内核线程会继承用户进程的一些资源(尽管这些资源在内核线程的执行过程中通常是不需要的)。为了避免这些资源被长期占用,内核线程需要执行daemonize()函数来释放这些资源,并将自己从用户进程的上下文中完全脱离出来,成为一个真正的内核守护进程(daemon)
daemonize函数执行以下处理
- 释放用户进程资源:由于内核线程是作为某个用户进程的子进程启动的,但内核线程本身不访问用户空间,因此daemonize会释放该用户进程的所有资源(如内存上下文、文件描述符等)。如果不这样做,这些资源将一直被占用,直到线程结束,这通常是不希望的,因为守护进程通常运行直到系统关闭。
- 阻塞信号接收:守护进程通常不需要处理来自外部的信号,因此daemonize会修改内核线程的信号掩码,以阻塞所有信号的接收。这有助于确保守护进程的稳定运行,避免不必要的信号干扰。
- 设置父进程为init:在Linux中,init是所有进程的祖先。通过daemonize,内核线程会将其父进程更改为init(进程ID为1)。这样做有几个好处:首先,它确保了即使在原始父进程结束后,守护进程也能继续运行;其次,它简化了孤儿进程的处理,因为所有孤儿进程最终都会由init进程收养;最后,它有助于系统管理和监控,因为所有守护进程都可以很容易地通过查找init进程的子进程来找到。
新方式
kthread_create 函数是用来创建新的内核线程的。这个函数允许你指定线程的名字(通过namefmt格式化字符串及其后的可变参数)、线程将要执行的函数(threadfn)以及传递给该函数的参数(data)。然而,创建后的线程默认是停止状态,需要通过wake_up_process函数来启动它。kthread_create函数的原型为:
struct task_struct *kthread_create(int (*threadfn)(void *data), void *data, const char namefmt[], ...);
另外两个包装函数
- kthread_run宏:会在创建线程后立即通过wake_up_process唤醒它,无需手动启动。
- kthread_create_cpu:对于需要将内核线程绑定到特定CPU的情况,可以使用kthread_create_cpu
在ps命令的输出中,内核线程会被放在方括号[]中,以区别于用户空间进程。
如果线程被绑定到了特定CPU,该CPU编号会显示在斜杠之后
$ ps -ef UID PID PPID C STIME TTY TIME CMD root 1 0 0 5月14 ? 01:03:51 /usr/lib/systemd/systemd --switched-root --system --deserialize 22 root 2 0 0 5月14 ? 00:00:03 [kthreadd] root 6 2 0 5月14 ? 00:01:21 [ksoftirqd/0] root 7 2 0 5月14 ? 00:00:54 [migration/0] root 8 2 0 5月14 ? 00:00:00 [rcu_bh] root 9 2 0 5月14 ? 01:03:07 [rcu_sched] root 10 2 0 5月14 ? 00:00:00 [lru-add-drain] root 11 2 0 5月14 ? 00:01:07 [watchdog/0] root 12 2 0 5月14 ? 00:00:57 [watchdog/1] root 13 2 0 5月14 ? 00:01:05 [migration/1] root 14 2 0 5月14 ? 00:00:17 [ksoftirqd/1] root 16 2 0 5月14 ? 00:00:00 [kworker/1:0H] root 17 2 0 5月14 ? 00:00:55 [watchdog/2] root 18 2 0 5月14 ? 00:01:02 [migration/2]
2.6 进程调度
在早期的内核代码中,进程调度使用轮询方式分配固定时间片的方式进行进程调度;现在操作系统调度方式更加多元化(先来先服务、短作业优先、多级反馈队列),考虑最大公平的情况下,多使用最大等待时间的任务优先获取CPU使用权。
如果不考虑实时调度,调度系统需要尽量使得所有任务都尽量公平的被分配CPU使用权。内核使用红黑树结构存储可运行任务。如果您不熟悉红黑树,只需在这里知道,这种数据结构可以有效地管理它所包含的条目,并且查找、插入和删除操作所需的时间只会随着树中存在的进程数量而适度增加。
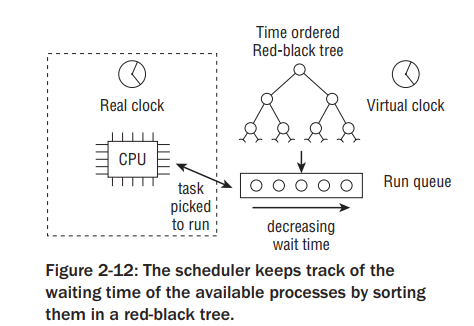
一个进程不能够切换的太频繁,也不能占用cpu时间过长。如果进程切换过于频繁,会花大量时间用在进程切换上,这样会降低系统的吞吐量,过多的上下文切换还可能增加系统的延迟,因为任务可能需要等待更长时间才能获得CPU资源;如果任务间的切换间隔太长,不公平性值可能会积累到很大的程度。这意味着某些任务可能会长时间等待CPU资源,而其他任务则可能过度占用CPU资源。这种不公平性会导致系统响应时间的增加和整体性能的下降。特别是对于多媒体系统来说,过大的延迟是不可接受的。
为了实现高效的任务调度,操作系统需要在上下文切换的开销和任务间不公平性的积累之间找到平衡。操作系统需要根据系统的具体需求和性能目标来选择合适的调度算法和参数设置。
task_struct中和进程调度相关的字段如下
<sched.h> struct task_struct { ... int prio, static_prio, normal_prio; //优先级 unsigned int rt_priority; //表示一个real-time的优先级,取值范围为0-99 struct list_head run_list; const struct sched_class *sched_class; //是一个指针,任务分类,不同的任务被分配到不同的类别 struct sched_entity se; //调度器除了可以调度进程外,还可以调度其他实体(比如按照进程组进行调度,这样CPU时会首先在各个进程组之间进行分配,然后各个进程组内部在对时间进行更详细的分配),调度实体用内嵌在task_struct中的sched_entity结构体表示 unsigned int policy; cpumask_t cpus_allowed; unsigned int time_slice; ... }
通用调度器调度过程示意图
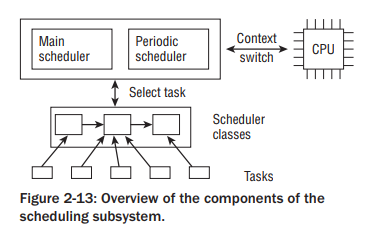
调度类其实就是所调度实体的分类划分,操作系统将调度实体分为各种各样的调度类,比如实时调度类和完全公平调度类等等。通用调度器在选择要调度的任务时,完全委托给调度类去做的。选择出接下来要执行的任务后接下来会进行上下文切换。
2.6.1 调度类
我们将可调度任务进行归类处理,用sched_class结构体表示
<sched.h> struct sched_class { const struct sched_class *next; void (*enqueue_task) (struct rq *rq, struct task_struct *p, int wakeup); //向run queue添加一个新的task void (*dequeue_task) (struct rq *rq, struct task_struct *p, int sleep); //比如任务状态变为不可运行态时,从run queue去除这个task void (*yield_task) (struct rq *rq); //当当前进程决定主动放弃CPU使用权时,会触发sched_yield系统调用,进而yield_task函数被调用 void (*check_preempt_curr) (struct rq *rq, struct task_struct *p); struct task_struct * (*pick_next_task) (struct rq *rq); void (*put_prev_task) (struct rq *rq, struct task_struct *p); void (*set_curr_task) (struct rq *rq); void (*task_tick) (struct rq *rq, struct task_struct *p); void (*task_new) (struct rq *rq, struct task_struct *p); };
用户空间程序不会直接和scheduling classes交互,用户空间程序只会识别SCHED_NORMAL, SCHED_BATCH, SCHED_IDLE, SCHED_RR 和 SCHED_FIFO。
其中SCHED_NORMAL, SCHED_BATCH, 和 SCHED_IDLE对应于fair_sched_class,而SCHED_RR 和 SCHED_FIFO 对应于 rt_sched_class。
fair_sched_class 和 rt_sched_class 都是 sched_class 的实例
实时任务是最重要的,它将优先被调度;完全公平任务次之;当没有其他任务要执行时idle进程将会被执行。
2.6.2 运行队列Run Queues
每个CPU都有自己的运行队列,每个运行队列有两个子队列cfs(完全公平调度队列)和rt(实时调度队列)
运行队列的定义:
kernel/sched.c struct rq { unsigned long nr_running; //在该CPU运行队列上可运行进程数 #define CPU_LOAD_IDX_MAX 5 unsigned long cpu_load[CPU_LOAD_IDX_MAX]; //这个数组用于记录CPU的负载信息,索引值代表不同的时间窗口或采样周期 ... struct load_weight load; //表示当前CPU上所有可运行任务的总体负载权重。负载权重是一个重要的概念,用于公平地分配CPU资源给不同的任务,考虑到任务的优先级和“重量”。 struct cfs_rq cfs; //表示CFS(Completely Fair Scheduler,完全公平调度器)的运行队列 struct rt_rq rt; //表示RT(实时)任务的运行队列 struct task_struct *curr, *idle; //curr指向当前正在CPU上运行的任务(进程或线程)的task_struct结构。idle指向该CPU的空闲任务的task_struct结构。当没有其他任务可以运行时,CPU将运行这个空闲任务 u64 clock; ... };
在Linux内核的调度器实现中,runqueues 数组包含了系统中每个CPU对应的运行队列(struct rq实例)
kernel/sched.c static DEFINE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);
2.6.3 调度实体
因为调度器除了可以调度任务外,还可以调度其他实体,也就是这里我们要讲的内容
<sched.h> struct sched_entity { struct load_weight load; /* 这个字段用于表示实体的负载权重。在负载均衡时,调度器会考虑这个权重来决定哪个实体应该获得更多的 CPU 时间。 */ struct rb_node run_node; // 是一个红黑树节点的引用。调度器使用它来管理可运行的实体。这个节点使得调度器能够高效地找到下一个应该运行的实体。 unsigned int on_rq; // 如果 on_rq 被设置,表示该实体是可运行的,并且正在等待 CPU 时间 u64 exec_start; // 记录了实体当前运行周期的起始时间 u64 sum_exec_runtime; // 累计了实体从调度器开始跟踪它以来总共的执行时间 u64 vruntime; u64 prev_sum_exec_runtime; ... }
2.6.4 核心调度器
调度器(Scheduler)的实现通常基于两个主要函数:周期性调度器(Periodic Scheduler)和主调度器函数(Main Scheduler Function)。
周期性调度器主要在时钟中断发生时被调用以更新进程的时间片并设置重新调度标志,而主调度器则在多种情况下被调用以进行实际的进程切换。这两个调度器共同协作,确保了Linux内核能够高效地管理任务并分配处理器资源。总的来说,周期性调度器和主调度器函数共同协作,实现了操作系统中的任务调度功能。周期性调度器负责定期检查系统的状态,而主调度器函数则负责根据当前的状态来选择合适的任务来执行。这两个函数的紧密配合,确保了操作系统能够高效地管理任务,提高系统的整体性能和响应速度。
周期性调度器(Periodic Scheduler):
功能:周期性调度器的主要任务是按照一定的时间间隔定期检查系统中的任务或线程状态,并根据需要调整它们的执行顺序或优先级。这通常涉及到检查是否有新的任务需要被执行,是否有任务已经完成了执行并需要被移除,以及是否需要重新分配CPU资源等。
实现方式:周期性调度器通常利用时钟中断(Timer Interrupt)或硬件定时器(Hardware Timer)来实现其周期性。每当定时器达到预设的时间间隔时,就会触发一个中断,该中断随后会调用周期性调度器的代码来执行上述的检查和调整任务。
周期调度器在scheduler_tick中实现。如果系统活动正在进行,内核会自动以HZ的频率调用该函数。如果没有进程等待调度,也可以关闭周期调度,这在一些笔记本电脑或小型嵌入式系统中电力是稀缺资源的情况下很有必要。
scheduler_tick主要有两个功能:
管理内核调度相关的统计信息:这部分功能涉及更新整个系统和单个进程的调度统计信息,主要是递增一些计数器。
激活当前进程所属调度类的周期性调度方法:这是scheduler_tick函数的核心职责之一。
void scheduler_tick(void) { int cpu = smp_processor_id(); //获取当前cpu struct rq *rq = cpu_rq(cpu); //获取该cpu的运行队列 struct task_struct *curr = rq->curr; //正在当前cpu上运行的进程 ... __update_rq_clock(rq) //更新当前运行队列的时钟时间戳 update_cpu_load(rq); //更新运行队列的cpu_load[]历史数组。这包括将先前存储的负载值向前移动一个数组位置,并将当前的运行队列负载插入到第一个位置 if (curr != rq->idle) //如果当前任务不是idle任务 curr->sched_class->task_tick(rq, curr); //当前任务所属调度类的task_tick函数。例如,在完全公平调度器(CFS)中,task_tick方法会检查一个进程是否已经运行了太长时间,以避免大延迟。需要注意的是,这与旧的时间片(time slice)基于的调度方法不同,因为在CFS中不存在时间片的概念。 }
如果当前任务需要重新调度,调度类的task_tick方法会在任务结构中设置TIF_NEED_RESCHED标志,内核会在下一个合适的时候处理这个请求
主调度器(Main Scheduler)
功能:主调度器函数是调度器的核心,它负责决定下一个要执行的任务或线程。这通常涉及到对系统中所有可运行任务的优先级进行评估,并选择优先级最高的任务来执行。此外,主调度器还需要处理任务间的上下文切换(Context Switch),即保存当前任务的执行状态并加载下一个任务的执行状态,以确保任务能够无缝地继续执行。
实现方式:主调度器函数的实现可能比较复杂,因为它需要考虑到多种因素,如任务的优先级、任务的类型(如I/O密集型、计算密集型等)、系统的硬件资源等。在实现时,通常会使用各种数据结构(如队列、堆等)来高效地管理任务,并使用各种算法(如优先级调度算法、轮转调度算法等)来选择合适的任务来执行。
主调度函数(schedule)在内核中的许多点被直接调用,以将CPU分配给当前活动进程以外的进程。从系统调用返回后,内核会检查当前进程的reschedule标志TIF_NEED_RESCHED是否已设置(例如前面小节中该标志是由scheduler_tick设置的)。如果是,内核将调用schedule函数。然后当前活动的任务将会被另一个任务替换。
asmlinkage void __sched schedule(void) { struct task_struct *prev, *next; struct rq *rq; int cpu; need_resched: cpu = smp_processor_id(); //当前CPU rq = cpu_rq(cpu); //当前CPU的运行队列 prev = rq->curr; //将当前CPU运行队列中的当前进程赋值给prev ... __update_rq_clock(rq); //更新当前cpu任务队列的时钟。这个时钟用于跟踪时间的流逝,对于调度决策至关重要。 clear_tsk_need_resched(prev); //表示清除之前运行的任务 prev 的重新调度需求标志 ... if (unlikely((prev->state & TASK_INTERRUPTIBLE) && unlikely(signal_pending(prev)))) { //当前任务处于可中断的睡眠状态且收到一个信号,那么必须将其激活 prev->state = TASK_RUNNING; } else { deactivate_task(rq, prev, 1); //任务会被停用 } ... prev->sched_class->put_prev_task(rq, prev); //通知调度类,当前任务即将被另一个任务替换。这并不是说任务会立即从运行队列中被移除,而是提供了一个机会来更新一些统计信息、执行一些记账操作,或者执行与任务即将不再运行相关的其他任何必要操作 next = pick_next_task(rq, prev); //选择下一个要执行的任务 ... if (likely(prev != next)) { //如果被选中的进程不是当前进程 rq->curr = next; //任务队列的curr指向这个新进程 context_switch(rq, prev, next); //上下文切换 } ... if (unlikely(test_thread_flag(TIF_NEED_RESCHED))) //就像前面说的内核会检查当前进程的reschedule标志TIF_NEED_RESCHED是否已设置,如果是,内核将跳转到need_resched处,相当于重新调用schedule函数。然后当前活动的任务将会被另一个任务替换 goto need_resched; }
2.6.5 上下文切换
context_switch 函数在 Linux 内核中负责在两个进程(或线程)之间切换上下文,包括保存当前进程(prev)的状态并恢复下一个进程(next)的状态,以便 CPU 能够继续执行下一个进程
kernel/sched.c static inline void context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next) { struct mm_struct *mm, *oldmm; //新进程和旧进程的内存信息 mm = next->mm; oldmm = prev->active_mm; //注意,这里使用的是active_mm而不是mm,因为当进程处于内核态时,它可能并不直接使用自己的mm_struct(例如,内核线程就没有自己的mm_struct) ... switch_mm(oldmm, mm, next); //更新进程所使用的页表;刷新转换后备缓冲区(TLB),并向内存管理单元(MMU)提供新的信息 ... /* Here we just switch the register state and the stack. */ switch_to(prev, next, prev); //切换cpu的寄存器内容和内核栈。因为在发生上下文切换时其内核有一套机制保存用户空间的寄存器内容到内核栈中,因此这里不需要显式的再保存他们。 ... //下面的代码将不会再执行,会在此进程再次获得cpu时才执行 barrier(); finish_task_switch(this_rq(), prev); }
3 内存管理
在0.11版本的内核中,实模式下,我们经常看到如下的内存表示方式:逻辑地址:ds:si = 0x07c0:0x0000 = 0x07c00(物理地址),因为386处理器只有20位地址线,因此只能寻址2^20=1M内存,段寄存器用于存储段基址(0x07c0)。实模式下,逻辑地址到物理地址的表示方式是段基址+偏移量。实模式下的地址都是真实的物理地址,不存在虚拟地址一说。
在内核启动的过程中,地址空间的低位地址将被替换为用户空间代码,将内核代码移动到高位部分。
切换到用户空间之后,内存的表示方式发生变化,段寄存器不再存放段基址,而是存放段选择符,且有了页目录和页表的概念。此时才有虚拟地址的概念。
言归正传。Linux内核通常将处理器的虚拟地址空间划分为两部分。其中,较低且较大的部分可供用户进程使用,而较高部分则保留给内核。在上下文切换(两个用户进程之间)期间,虽然较低部分会被修改,但虚拟地址空间的内核部分始终保持不变。
3.1 页框
在Linux系统中,物理内存(RAM)被划分为固定大小的块,这些块被称为页框。内核以页框为基本单位来管理物理内存,确保内存资源的有效利用
页框的大小通常是4KB。
页框与虚拟内存之间通过页表建立映射关系
当物理内存不足时,内核会选择一些不常用的页框将其内容写入磁盘(称为换出),以释放内存空间供其他页框使用。当需要访问这些被换出的页框时,再将它们从磁盘读回内存(称为换入)。
内核会定期扫描内存中的页框,回收不再使用的内存资源(比如引用计数为0时)
3.2 页表
页表是一种数据结构,用于在用户进程的虚拟地址空间和系统物理内存(RAM)之间建立映射关系
虚拟地址空间:这是操作系统为每个进程提供的逻辑内存布局。尽管在物理内存中它可能并不是连续的,但是在虚拟地址空间中内存被视为一个连续的地址范围。虚拟地址空间使得每个进程可以认为自己独占整个内存空间,从而简化了内存管理并提高了安全性。
物理内存(RAM,页框Page Frames):物理内存是计算机中实际的内存硬件,用于存储正在执行的程序和数据。在内存管理中,物理内存被划分为固定大小的块,称为页框(Page Frames)。每个页框可以存储一个虚拟内存页的内容。
在内核代码中,页表项被分为4级,如下图
页全局目录索引(PGD Index)
页上级目录索引(PUD Index)
页中间目录索引(PMD Index)
页表索引(PT Index)
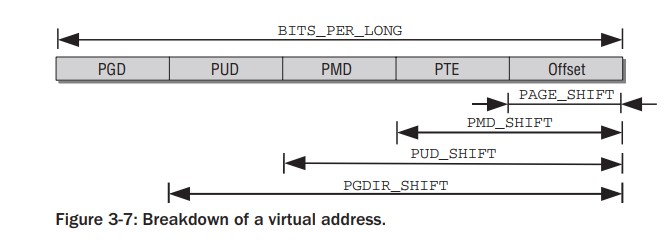
需要注意的是,目前的很多架构只使2级用页表结构。但是为了更广泛的兼容性,内核中会将2级页表结构模拟为4级页表结构。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通