

深入理解linux网络技术内幕
1 系统初始化
1.1 通知链
为什么需要通知链?书中给出了一个例子,如果网络中一个子网不可达,必须更新路由器的路由表,而更新这个路由表就需要通知链。然后给出结论:In any case, the routing subsystem that manages the tables must be informed of the relevant information by some other subsystem, demonstrating the need for notification chains。在任何情况下,管理表的路由子系统都必须由其他子系统通知相关信息,这表明需要通知链。
通知链简单说就是给定事件发生时要执行的函数列表。通知链只用于内核子系统之间。内核和用户空间之间的通知采用其他机制。
其定义如下,也就是一串notifier_block组成的链表。
struct notifier_block { int (*notifier_call)(struct notifier_block *self, unsigned long, void *); //要执行的函数 struct notifier_block *next; //链中的下一个节点 int priority; //优先级 };
notifier_block实例的常见名称为xxx_chain、xxx_notifier_chain和xxx_notiifier_list
1.1.1 订阅通知
当一个kernel模块对一个指定的通知链感兴趣,那么它可以使用通用的notifier_chain_register函数来进行订阅(注册)它。
int notifier_chain_register(struct notifier_block **list, struct notifier_block *n) { write_lock(¬ifier_lock); while(*list) { if(n->priority > (*list)->priority) break; list= &((*list)->next); } n->next = *list; *list=n; write_unlock(¬ifier_lock); return 0; }
除了这个通用的注册函数,还有一些包装函数可供我们使用,如下列出了订阅和取消订阅相关的包装函数
Registration:
int notifier_chain_register(struct notifier_block **list, struct notifier_block *n)
Wrappers:
inetaddr_chain register_inetaddr_notifier //其中register_inetaddr_notifier是注册函数,执行该注册函数后将向inetaddr_chain这个通知链添加一个元素。
inet6addr_chain register_inet6addr_notifier
netdev_chain register_netdevice_notifier
Unregistration:
int notifier_chain_unregister(struct notifier_block **nl, struct notifier_block *n)
Wrappers:
inetaddr_chain unregister_inetaddr_notifier
inet6addr_chain unregister_inet6addr_notifier
netdev_chain unregister_netdevice_notifier
Notification
int notifier_call_chain(struct notifier_block **n, unsigned long val, void *v)
1.1.2 通知链上的事件
通知是通过函数notifier_call_chain生成的。此函数会按优先级顺序调用所有链上注册的notifier_block节点中的回调例程(notifier_call)。
比如某个内核子模块某个task中调用了notifier_call_chain函数,导致通知链上的回调例程被调用,继而唤醒其他正在监听该回调例程的Task。
int notifier_call_chain(struct notifier_block **n, unsigned long val, void *v) // val为事件类型 { int ret = NOTIFY_DONE; struct notifier_block *nb = *n; while (nb) { ret = nb->notifier_call(nb, val, v); if (ret & NOTIFY_STOP_MASK) { return ret; } nb = nb->next; } return ret; }
回调函数会返回NOTIFY_OK,NOTIFY_DONE,NOTIFY_BAD,NOTIFY_STOP等值。注意看函数中,当出现NOTIFY_BAD,NOTIFY_STOP时将跳出循环并return ret;也就是说当通知链上某个事件回调函数执行异常时,将中止执行链上其他事件回调函数。
还有就是对于同一通知链,不同CPU同一时间执行notifier_call_chain函数,这时回调函数就要做好并发控制了。
1.1.3 网络子系统所用的通知链
内核定义了至少10种通知链,我们这里只关心网络中的通知链
inetaddr_chain:在本地接口上发送有关插入、删除和更改IP地址的通知。
netdev_chain:发送有关网络设备注册状态的通知
2 PCI层和NIC卡
PCI(Peripheral Component Interconnect)全称为外围组件互连。也就是许多外围组件通过PCI总线连接在一起。常见的设备都是PCI设备:NIC卡、声卡等。
2.1 三个主要结构体
pci_device_id
PCI设备的id,每个PCI设备对应一个pci_device_id,其是一个结构体,由几个字段组成:供应商,设备编号,类别(比如:NETWORK)等。
struct pci_device_id { unsigned int vendor, device; unsigned int subvendor, subdevice; unsigned int class, class_mask; unsigned long driver_data; };
pci_dev
每个PCI设备都对应一个pci_dev实例
struct pci_dev { struct list_head global_list; /* node in list of all PCI devices */ struct list_head bus_list; /* node in per-bus list */ struct pci_bus *bus; /* bus this device is on */ struct pci_bus *subordinate; /* bus this device bridges to */ void *sysdata; /* hook for sys-specific extension */ struct proc_dir_entry *procent; /* device entry in /proc/bus/pci */ unsigned int devfn; /* encoded device & function index */ unsigned short vendor; unsigned short device; unsigned short subsystem_vendor; unsigned short subsystem_device; unsigned int class; /* 3 bytes: (base,sub,prog-if) */ u8 hdr_type; /* PCI header type (`multi' flag masked out) */ u8 rom_base_reg; /* which config register controls the ROM */ struct pci_driver *driver; /* which driver has allocated this device */ u64 dma_mask; /* Mask of the bits of bus address this device implements. Normally this is 0xffffffff. You only need to change this if your device has broken DMA or supports 64-bit transfers. */ pci_power_t current_state; /* Current operating state. In ACPI-speak, this is D0-D3, D0 being fully functional, and D3 being off. */ struct device dev; /* Generic device interface */ /* device is compatible with these IDs */ unsigned short vendor_compatible[DEVICE_COUNT_COMPATIBLE]; unsigned short device_compatible[DEVICE_COUNT_COMPATIBLE]; int cfg_size; /* Size of configuration space */ /* * Instead of touching interrupt line and base address registers * directly, use the values stored here. They might be different! */ unsigned int irq; struct resource resource[DEVICE_COUNT_RESOURCE]; /* I/O and memory regions + expansion ROMs */ /* These fields are used by common fixups */ unsigned int transparent:1; /* Transparent PCI bridge */ unsigned int multifunction:1;/* Part of multi-function device */ /* keep track of device state */ unsigned int is_enabled:1; /* pci_enable_device has been called */ unsigned int is_busmaster:1; /* device is busmaster */ u32 saved_config_space[16]; /* config space saved at suspend time */ struct bin_attribute *rom_attr; /* attribute descriptor for sysfs ROM entry */ int rom_attr_enabled; /* has display of the rom attribute been enabled? */ struct bin_attribute *res_attr[DEVICE_COUNT_RESOURCE]; /* sysfs file for resources */ #ifdef CONFIG_PCI_NAMES #define PCI_NAME_SIZE 255 #define PCI_NAME_HALF __stringify(43) /* less than half to handle slop */ char pretty_name[PCI_NAME_SIZE]; /* pretty name for users to see */ #endif };
pci_driver
pci_driver定义了PCI层和PCI设备驱动之间的接口,如何理解呢?一个pci_driver实例可管理多个PCI设备,其可管理的设备列表由其结构体的id_table数组指定。比如一个网卡驱动,其可以管理多个不同类型的网卡,只要其在硬件上兼容。其定义:
struct pci_driver { struct list_head node; char *name; struct module *owner; const struct pci_device_id *id_table; /* must be non-NULL for probe to be called */ int (*probe) (struct pci_dev *dev, const struct pci_device_id *id); /* New device inserted */ void (*remove) (struct pci_dev *dev); /* Device removed (NULL if not a hot-plug capable driver) */ int (*suspend) (struct pci_dev *dev, pm_message_t state); /* Device suspended */ int (*resume) (struct pci_dev *dev); /* Device woken up */ int (*enable_wake) (struct pci_dev *dev, pci_power_t state, int enable); /* Enable wake event */ void (*shutdown) (struct pci_dev *dev); struct device_driver driver; struct pci_dynids dynids; };
2.2 PCI设备的注册
在模块加载时调用pci_register_driver实现的注册
int pci_register_driver(struct pci_driver *drv) { int error; /* initialize common driver fields */ drv->driver.name = drv->name; drv->driver.bus = &pci_bus_type; drv->driver.probe = pci_device_probe; drv->driver.remove = pci_device_remove; /* FIXME, once all of the existing PCI drivers have been fixed to set * the pci shutdown function, this test can go away. */ if (!drv->driver.shutdown) drv->driver.shutdown = pci_device_shutdown, drv->driver.owner = drv->owner; drv->driver.kobj.ktype = &pci_driver_kobj_type; pci_init_dynids(&drv->dynids); /* register with core */ error = driver_register(&drv->driver); if (!error) pci_populate_driver_dir(drv); return error; }
PCI总线架构的一个巨大优势是它的探测机制,当PCI设备连接到总线时,系统BIOS或者PCI驱动就会执行总线扫描以检测新设备的存在
2.3 NIC驱动注册实例
我们以 Intel PRO/100 Ethernet driver 为例说明设备驱动的注册过程。
在内核启动或模块加载时,module_init宏被调用,它然后会执行pci_module_init(旧版本内核,新内核对应上面提到的pci_register_driver),这个函数注册驱动,初始化所有可管辖的网卡列表(pci_driver的id_table向量)
#define INTEL_8255X_ETHERNET_DEVICE(device_id, ich) { PCI_VENDOR_ID_INTEL, device_id, PCI_ANY_ID, PCI_ANY_ID, PCI_CLASS_NETWORK_ETHERNET << 8, 0xFFFF00, ich } static struct pci_device_id e100_id_table[] = { //pci_device_id结构体组成的一个向量,第一个元素固定为PCI_VENDOR_ID_INTEL,第3和第4个元素为通配符PCI_ANY_ID, INTEL_8255X_ETHERNET_DEVICE(0x1029, 0), INTEL_8255X_ETHERNET_DEVICE(0x1030, 0), ... }
2.4 PCI总线的工作过程
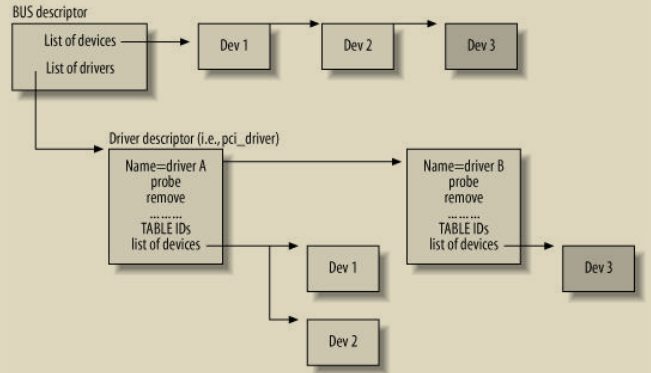
当系统启动时,它会创建一种数据库,该数据库将每条总线与检测到的设备列表关联起来。PCI总线对应一个描述符,PCI总线的描述符除了包含其他参数外,还包括检测到的PCI设备列表。
- PCI总线检测到所有连接到该总线的设备,并存储在一个数据库DB1中
- PCI设备驱动(对应pci_driver结构)初始化后,其内部有一个id_tables向量,存储了其能够驱动的所有设备列表。
- 每个PCI设备驱动遍历id_tables列表,找到DB1中是否有该类型的设备,如果找到,则添加到自己维护的一个设备列表里面
比如下图所示,总线检测到3个设备Dev1-Dev3.总线有两个驱动driverA和driverB,driverA驱动了两个设备Dev1,Dev2,driverB驱动了一个设备Dev3
3 支持组件初始化的内核结构
本章着重介绍在组件初始化时将要使用到的一些数据结构和例程,下一章才会具体讲组件的初始化。
3.1 启动时参数
当内核启动时,引导程序(如GRUB,LILO)可以传递参数到内核(比如 LILO: linux ether=5,0x260,eth0 ether=15,0x300,eth1),然后内核执行start_kernel,它会执行一些初始化,见下图所示,其中之一是执行init内核线程,它进行剩下的初始化工作,我们关注的是其中的do_basic_setup,它会执行driver_init()和sock_init()。
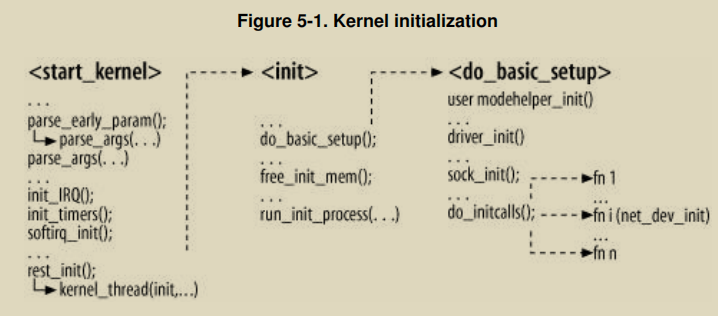
处理启动时参数的例程为parse_args(),它会解析引导过程中传递进来的参数(比如:LILO: linux ether=5,0x260,eth0 ether=15,0x300,eth1),它会解析传递过来的关键字key并调用相应的参数处理程序,关键字和参数处理程序的对应关系由专门例程进行注册,见下一小结(3.2 注册关键字)。
3.2 注册关键字
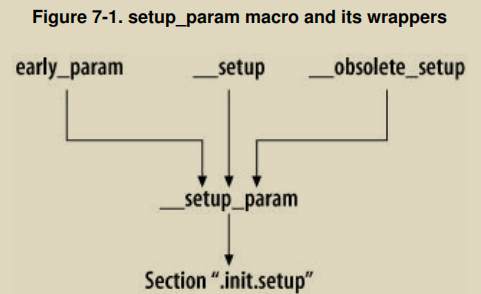
使用_ _setup宏注册关键子以及其关联的处理函数,比如:
_ _setup("netdev=", netdev_boot_setup); _ _setup("ether=", netdev_boot_setup);
注意:__setup宏只在内核引导时起作用,如果内核已经启动,在模块热加载的情况下,__setup宏将被忽略
3.3 两次parse_args调用
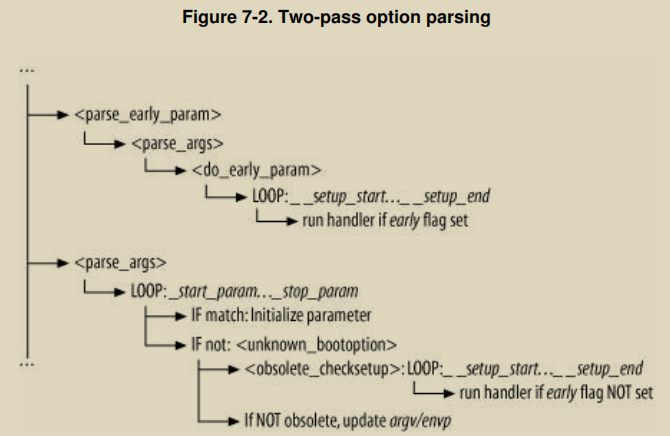
start_kernel 调用 parse_args 两次,原因是什么呢?因为引导时参数其实是分两类的:一类是Early参数,另一类是默认参数。内核调用两次parse_args分别处理这两类参数。
内核使用early_param宏来声明Early参数,而不是使用__setup宏。这些Early参数被parse_early_params进行处理。
需要注意的是在2.6版本之后__setup宏被__obsolete_setup宏替代。但是,不论是__setup还是__obsolete_setup还是early_param宏,他们都统一被包装成__setup_param例程,如下图所示:
两次初始化示意图见7-2
4 设备注册和初始化
5 帧的发送和接收
5.1 帧的接收
帧的接收是指,从网卡驱动到内核的过程。
帧的接收方式有如下几种:
- polling(轮询):这种方式会定期读取驱动寄存器中的值,以此判断是否有帧到来,显然,此种方式浪费了大量的cpu时间
- interrupt:这种方式在网卡设备有流量到来时,驱动产生硬件中断,然后相应地处理程序将会被执行,处理程序会将帧排队到某个地方并通知内核。但是在高流量场景下,接收到的每一个帧都产生一个硬件中断,CPU很容易把时间都用在处理中断上。
- 一次中断处理多个帧:也就是中断发生时,中断处理程序源源不断的读取设备驱动缓冲区中的帧,直到达到一次处理的上限。
- 定时器驱动的中断:比如,驱动中含有定时器,且该定时器每100ms触发一次中断,然后一次性处理所有设备驱动缓冲队列中的帧,这种方式的问题是有一定的延迟。
- 混合polling和interrupt方式:也就是在低负载时,使用中断方式,而负载升高时,则使用定时器方式。
5.1.1 中断处理程序
中断处理程序分为两类,即上半部处理程序和下半部处理程序。
在网络设备中断处理程序中,为什么我们需要下半部呢?如果一个CPU正忙于处理一个中断,它就不能接收其他中断,无论是同类型的中断还是不同类型的中断。CPU也不能执行任何其他进程:它完全属于中断处理程序,并且不能被抢占。因此在帧到达时,硬件中断必须尽快完成,这些需要尽快完成的事情放到了硬件中断中处理,在这个时间窗期间,中断处理程序必须尽快存储发送过来的帧的内容以及一些其他必要的事情,然后对于该帧的处理则放到稍后的软中断中完成。
5.1.2 内核2.2版本下半部处理函数的调度
BH的分类在如下枚举中定义
enum { TIMER_BH = 0, CONSOLE_BH, TQUEUE_BH, DIGI_BH, SERIAL_BH, RISCOM8_BH, SPECIALIX_BH, AURORA_BH, ESP_BH, NET_BH, SCSI_BH, IMMEDIATE_BH, KEYBOARD_BH, CYCLADES_BH, CM206_BH, JS_BH, MACSERIAL_BH, ISICOM_BH };
这里我们只关心网络相关的NET_BH。
每个BH对应一个处理函数,其中NET_BH与其处理函数的关联在net_dev_init中进行的。
_ _initfunc(int net_dev_init(void)) { ... ... ... init_bh(NET_BH, net_bh); ... ... ... }
当中断处理程序想要触发一个BH处理程序时,它会调用mark_bh函数,这个函数会简单的设置全局bitmap bh_active中的特定bit
extern inline void mark_bh(int nr) { set_bit(nr, &bh_active); };
然后,后续步骤会检查bitmap中的这个位,继而触发net_bh的执行。那么内核会在哪些地方检查这个bitmap呢?下面列出
- do_IRQ执行结束后
- 从中断或异常返回时
- schedule函数,schedule调度函数会检查是否有BH处理函数在等待,如果有,它会给它更高的执行优先权
5.1.3 内核2.4版本下半部处理函数的调度
2.4版本引入了software interrupts (softirqs)。不仅可以多个softirqs并发执行,而且相同类型的softirqs可以在不同CPU中并行执行。唯一的约束是一个CPU中不能同时执行相同类型的softirq实例
softirqs的种类
enum { HI_SOFTIRQ=0, TIMER_SOFTIRQ, NET_TX_SOFTIRQ, NET_RX_SOFTIRQ, SCSI_SOFTIRQ, TASKLET_SOFTIRQ };
和网络相关的softirq是NET_TX_SOFTIRQ 和 NET_RX_SOFTIRQ
2.2版本中使用的BH类型被重新封装为了HI_SOFTIRQ,比其他softirq有更高的优先级
softirq和其handler是通过open_softirq函数注册的
static struct softirq_action softirq_vec[32] _ _cacheline_aligned_in_smp; void open_softirq(int nr, void (*action)(struct softirq_action*)) { softirq_vec[nr].action = action; }
softirq的调度
和2.2版本一样,softirq会设置bitmap中的特定位来调度一个softirq。然后会在schedule中检查这个bitmap,然后执行do_softirq函数执行softirq处理函数。
和2.2版本的区别是,新版本每个CPU都有一个bitmap位图
asmlinkage void schedule(void) { /* Do "administrative" work here while we don't hold any locks */ if (softirq_active(this_cpu) & softirq_mask(this_cpu)) goto handle_softirq; handle_softirq_back: ... ... ... handle_softirq: do_softirq( ); goto handle_softirq_back; ... ... ... }
softirq的初始化
NET_RX_SOFTIRQ 和 NET_TX_SOFTIRQ的初始化是在net_dev_init中进行的
static int __init net_dev_init(void) { ... // 注册软中断处理函数 open_softirq(NET_TX_SOFTIRQ, net_tx_action); open_softirq(NET_RX_SOFTIRQ, net_rx_action); ... return 0; }
TASKLET_SOFTIRQ 和 HI_SOFTIRQ的初始化是在softirq_init中进行的
void _ _init softirq_init( ) { open_softirq(TASKLET_SOFTIRQ, tasklet_action, NULL); open_softirq(HI_SOFTIRQ, tasklet_hi_action, NULL); }
另外两个,SCSI_SOFTIRQ 在 drivers/scsi/scsi.c, TIMER_SOFTIRQ 在 kernel/timer.c
5.1.4 处理帧接收的两种方式(上半部)
旧方式 netif_rx 和新方式NAPI
举例:下面是Intel 的 Vortex 网络驱动如何处理帧的接收的相关代码(使用netif_rx):
skb = dev_alloc_skb(pkt_len + 5);//分配sk_buff数据结构内存单元,帧将被拷贝到skb中 ... ... ... if (skb != NULL) { skb->dev = dev; skb_reserve(skb, 2); /* Align IP on 16 byte boundaries */ ... ... ... /* copy the DATA into the sk_buff structure */ ... ... ... skb->protocol = eth_type_trans(skb, dev);//解析并存储3层网络所使用的协议 netif_rx(skb);//该函数将skb传送到内核 dev->last_rx = jiffies; ... ... ... }
NAPI和netif_rx处理帧方式的区别:NAPI采用interrupt和polling相结合的方式接收来自网卡的帧,当有帧到达网卡从而引发中断时,如果在处理这个帧时又有新的帧到达网卡,网卡驱动没有必要再触发中断,只是一个简单的轮询就可以,轮询设备input queue直到队列为空,再重新打开中断以便接收新的帧;而netif_rx只采用中断的方式,在高流量的情况下CPU使用率会过高
netif_rx函数有一个重要步骤是将当前设备添加到当前CPU的softnet_data->poll_list中去,在下半部分处理函数net_rx_action中将会遍历这个poll_list,然后对在这个列表中的设备的缓冲队列进行处理(比如polling方式,直到所有帧都处理完或者到达限额)
int netif_rx(struct sk_buff *skb) { ... netif_rx_schedule(&queue->backlog_dev); ... }
其中netif_rx_schedule定义如下
static inline void netif_rx_schedule(struct net_device *dev) { ... ... list_add_tail(&dev->poll_list, &__get_cpu_var(softnet_data).poll_list);//将当前设备加到当前CPU的softnet_data->poll_list中 ... ... __raise_softirq_irqoff(NET_RX_SOFTIRQ);//禁用中断的情况下触发NET_RX_SOFTIRQ软中断 local_irq_restore(flags);//恢复中断 }
在这里我们看到使用netif_rx_schedule函数进行NET_RX_SOFTIRQ软中断的调度
5.1.5 下半部处理函数net_rx_action
- 对于Non-NAPI设备,在上半部分中断处理函数netif_rx把帧存储在了与每个CPU相关联的softnet_data->input_pkt_queue中
- 对于NAPI设备,poll函数直接从设备的缓冲队列中获取帧
然后内核会触发软中断NET_RX_SOFTIRQ,其处理函数为net_rx_action,接下来这些帧将被net_rx_action处理
net_rx_action定义在net/core/dev.c中。其作用为:
- 从内核的数据结构中取出数据包,并分发到相应的网络协议层进行处理。
- 它首先会检查是否有设备在准备等待轮询(即poll_list不为空)。
- 接着,net_rx_action会遍历poll_list,对每个设备调用其poll方法(在NAPI情况下)或process_backlog(非NAPI情况下)来读取和处理数据包。
- 在处理过程中,net_rx_action会调用netif_receive_skb、netif_rx等函数来进一步处理数据包。这些函数会将数据包分发到本地套接字或相应的网络协议层。
5.2 帧的发送
当设备驱动意识到其没有空间容纳一个MTU大小的帧时,将会关闭egress queue,以便不浪费系统资源进行帧的发送。
dev_kfree_skb (skb); if (inw(ioaddr + TxFree) > 1536) { netif_start_queue (dev); /* AKPM: redundant? */ } else { /* Interrupt us when the FIFO has room for max-sized packet. */ netif_stop_queue(dev);//关闭egress队列 outw(SetTxThreshold + (1536>>2), ioaddr + EL3_CMD); }
当设备驱动剩余空间恢复到MTU大小时,如何恢复数据发送呢?以Vortex driver为例,当剩余空间足够时,其会发送一个中断,在对应的中断处理程序中恢复egress队列
static void vortex_interrupt(int irq, void *dev_id, struct pt_regs *regs) { ... ... ... if (status & TxAvailable) { outw(AckIntr | TxAvailable, ioaddr + EL3_CMD); netif_wake_queue (dev);//唤醒egress队列 } ... ... ... }
帧发送流程:
- 当网络协议栈构造完成一个数据包,并准备将其发送到网络时,比如http报文会封装成tcp报文,然后在数据链路层会对tcp报文进行分片拆分,构造成帧。
- 判断设备驱动的发送队列是否已满(或其他原因不能立即发送这个帧)
- 如果网卡驱动发送队列未满,则调用dev_queue_xmit函数进行帧的发送;
- 如果网卡驱动发送队列已满,则会执行调度函数_netif_schedule,将设备添加到output_queue列表(对应于接收情况下的poll_list)并触发NET_TX_SOFTIRQ软中断。output_queue列表每个CPU对应一个。
- 在NET_TX_SOFTIRQ软中断的处理函数中(如net_tx_action),会遍历output_queue列表,并调用dev_queue_xmit函数来发送队列中的数据包,如果发送成功则将该设备从output_queue列表删除,如果发送失败则下次再尝试发送
6 协议处理函数
在网络栈中,我们可以看到有很多层,比如数据链路层、网络层、传输层等。每一层都对应很多网络协议,比如ip、arp协议等待。每个协议都对应一个协议处理函数,这些协议处理函数是在系统初始化或者组件加载的时候被设置。
这些协议处理函数的作用是处理流入到当前网络栈的网络流量。
举例,一个网卡驱动(L2)如何调起L3层协议
当网卡驱动接收到一个帧,会初始化一个sk_buff对象来存储这个帧,然后从frame header中读取相关信息来设置sk_buff->protocol字段的值。
struct sk_buff { ... ... ... unsigned short protocol; ... ... ... };
下半部处理函数net_rx_action会调用netif_receive_skb处理数据包,而netif_receive_skb会读取sk_buff->protocol字段以决定使用什么协议处理函数进行处理。
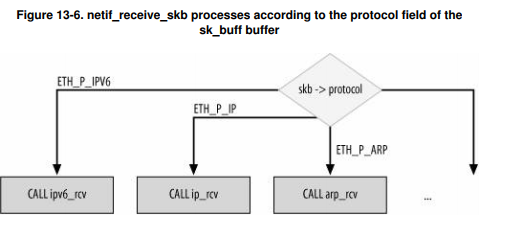
protocol和协议处理函数有时不是一一对应的,比如当存在数据包嗅探器时,一个数据包可能会发给多个协议处理函数(即所谓的混杂模式)。这种类型的处理程序通常不用于处理收到的数据包,而只是为了调试或收集统计数据而窥探给定的设备。
6.1 协议处理函数的注册
在系统启动时,IPv4协议会被初始化,此时ip_init函数会被调用,在这个函数中将会初始化IPv4协议的处理函数,如下是packet_type类型的数据结构,其封装了协议和处理函数对应关系
static struct packet_type ip_packet_type = { .type = _ _constant_htons(ETH_P_IP), .func = ip_rcv, }
ip_init代码
void _ _init ip_init(void) { dev_add_pack(&ip_packet_type); ... }
经过协议处理函数的初始化后,后续协议类型为ETH_P_IP类型的网络数据包将会被ip_rcv处理
7 桥接
以太网是一种局域网技术,以太网的组网可以通过下面几种方式
- 使用一根同轴电缆连接所有计算机。同轴电缆中间是一根粗铜线,线的外面有一层塑胶围拢,绝缘体外面又有一层薄的网状导电体,然后导电体外面是最外层的绝缘物料作为外皮。这是最基本的组网方式,工作在物理层,所有计算机共享这根总线,采用CDMA/CD技术进行载波监听并在总线空闲时发送帧,帧的发送方式是广播的方式。
- 使用集线器,集线器工作在物理层,其采用广播的方式将物理帧发送到其他端口。概念上可以视为所有连接在其上的节点都连接在一个公共总线上。因此可看做总线型组网方式。
- 使用桥接设备,桥接设备是在二层网络下进行数据包路由的设备,通过MAC地址进行路由,由于目前交换机无论在性能和可用性方面都优于传统意义上的网桥。因此桥接设备一般指的是交换机。
- 使用路由设备,路由设备是工作在三层网络进行数据包路由的设备,通过IP地址进行路由
中继器、桥接设备、路由设备概念和比较
- 中继器有两个端口,工作在物理层,它以bit为单位,只简单的将收到的1bit信号从一个端口发送到另一个端口。多个端口的中继器也叫hub(集线器)。中继器有两个主要作用:转发bit和放大信号。中继器可引入一定的网络延时
- 桥接设备工作在数据链路层,它理解数据链路层协议,以frame为单位进行数据转发。可存储MAC路由表,以MAC地址进行路由。因为以frame为单位进行数据转发所以每个端口都有至少1个frame大小的缓存。
- 路由设备工作在网络层,它理解网络层协议(比如IP),以IP报文为单位进行数据转发。可存储IP路由表,以ip地址进行路由
7.1 使用bridge合并LANs
我们可以使用桥接设备合并两个局域网,使他们看起来像是一个局域网。也就是说连接在同一个交换机下的所有主机处在一个局域网里面。
局域网上传输的任何帧都会被所有其他主机接收。比如,当主机A发送帧时,LAN1的其他主机和网桥都会接收到它,接着网桥将该帧转发到网桥的其他端口。因此,最后,LAN1和LAN2的所有主机都会收到主机A生成的帧的副本。
由于网桥的存在,从LAN1和LAN2的主机的角度来看,只有一个大LAN
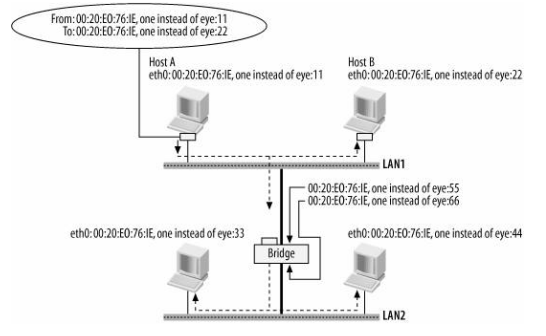
7.2 Address Learning
如果没有L2路由表,LAN中的一个节点发送了一个帧之后,桥接设备将使用广播的方式将该帧发送到LAN中的所有主机,这明显浪费了带宽和其他主机的CPU资源。庆幸的是,桥接设备可以学习主机的L2地址,存储起来,进行帧的转发时根据这个路由表转发到特定的主机。除非路由表中没有,才会以广播的方式发送该帧。
因为LAN中的网络拓扑可能会有变化,桥接设备学习到的路由表可能会过期。因此,桥接设备使用一个定时器定期清理路由表,其过程如下:
- 定时器在首次进行地址学习后启动
- 定时器跟踪每个MAC地址,如果在老化时间(默认5min)之内没有收到该MAC地址的数据包,则将该MAC地址清除出路由表
- 如果MAC地址已经被清除出路由表,当又有新的数据包到达时,重新将该MAC地址写入路由表
老化时间设置的越低,桥接设备学习拓扑变化的越快,同时也会增加找不到路由时使用洪泛的概率
7.3 传输桥的无环结构
在一个LAN中使用多个桥是有好处的,可以增加网络可靠性,如果一个桥坏了,另一个桥仍然起作用,不至于网络中断。
总体而言,网桥的透明性是有益的,因为它能让位于不同局域网(LAN)的主机仿佛处于同一个公共局域网中一样被透明地合并。然而,透明性也存在危险,因为网桥不知道入口帧(ingress frame)的来源。网桥的工作是从ingress frame的数据包中学习主机的位置,构建一个地址数据库,并基于这个数据库将ingress frame复制到正确的端口。
但是同一局域网中使用多个网桥也很容易引入环状结构,从而导致网络的崩溃,举例说明
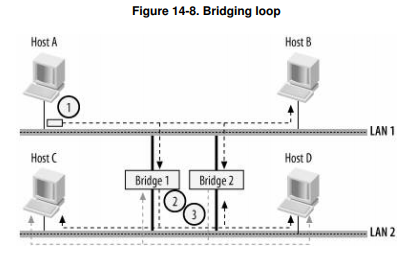
- 当主机A发送一个数据包,而Bridge1和Bridge2的数据库都为空(即尚未学习任何地址)时。两个桥接器都会接收到帧,意识到主机A位于LAN1,并将帧复制到LAN2。
- 假设它们几乎同时进行了复制。因此,这两个桥接器将在LAN2的接口上接收到帧的副本,并认为主机A已移动到LAN2(请记住,它们在LAN2上接收到的帧是主机A在LAN1上发送的原始帧的精确副本)。
- 此时,两个桥接器都会将帧复制到LAN1(我们假设目标主机尚未回复,因此桥接器不知道它位于何处)。它们将再次接收到彼此的副本,改变对主机A位置的认识,并将帧复制到LAN2。
- 这是一个循环,它将使两个局域网充斥着不断循环的相同帧,导致两个局域网上的任何其他传输都无法进行。局域网中其他主机的CPU也将忙于接收和丢弃大量相同的帧副本,如果接口层没有通过某种速率限制手段进行保护,它们将会崩溃。
这个简单的场景告诉我们一个重要的规则:不能在循环拓扑上使用透明桥接
7.4 生成树协议STP
如果一个以太网环境中使用了桥接设备,要解决的一个重要问题是环路问题。STP的作用正是去除网络中的环路。
根桥,每棵树只有一个root桥
每个LAN有一个designated桥,LAN中其他主机和桥通过这个designated桥连接到root桥
7.5 桥接设备的端口的角色
有两种角色
- root port:每个桥,其中离根桥最近的端口称之为根端口。
- Designated port:在每个局域网上,到根桥的路径成本最小的端口称为Designated端口。
LAN的Designated桥:Designated端口所属的桥称为LAN的Designated网桥。
root port通向树根,而Designated port通向叶子。
7.6 桥ID和port ID
每个桥都会分配一个ID,占8字节,低6字节为某个端口的MAC地址,高2字节为桥优先级
port ID:桥中每个端口都会分配一个ID,这个ID只在这个桥中有意义
7.7 BPDU
BPDU(Bridge Protocol Data Unit,桥接协议数据单元)
BPDU报文主要有两种类型:
- 配置BPDU(Configuration BPDU):
配置BPDU主要用于在网络初始化或拓扑结构变化时,向其他设备传达网络的配置信息。
它由根桥每Hello时间发出,以确保网络中所有交换机都了解当前的配置状态。
配置BPDU中的Flag字段包含了多个重要的状态标志,如TCA(Topology Change Acknowledgment,拓扑变化确认)和TC(Topology Change,拓扑变化)等。
当根桥感知到拓扑变化时,会发送TC置位的配置BPDU,通知全网拓扑发生了变更,并要求所有交换机将MAC表的老化时间改为15秒,以加速收敛过程。
- 拓扑变化通知BPDU(Topology Change Notification BPDU,TCN BPDU):
拓扑变化通知BPDU用于在拓扑结构发生变化时,及时向其他设备发送通知。
它由感知到拓扑发生变更的网桥从根端口发送出去,以告知上游交换机发生了拓扑变化。
TCN BPDU中的BPDU类型值被设置为0x80,以区别于配置BPDU。
当上游交换机收到TCN BPDU后,会回应一个TCA置位的配置BPDU,确认知道拓扑发生了改变,并继续向上游传播,直至到达根桥。
配置BPDU何时被传输?
- 在网络初始化过程中,每个桥都会主动发送配置BPDU。这是为了建立和维护一个无环的生成树拓扑。
- 在网络拓扑稳定后,只有根桥会主动发送配置BPDU。其他桥(非根桥)在收到上游传来的配置BPDU后,会触发发送自己的配置BPDU。这确保了网络中所有桥都保持最新的配置信息。
- 当桥接收到一个比自己差的配置BPDU时(即优先级较低的BPDU),会立刻向下游设备发送自己的配置BPDU。这是为了确保网络中始终传播最优的配置信息。
- 当桥检测到网络拓扑发生变化时(如链路故障、端口状态变化等),会触发发送TCN(Topology Change Notification)BPDU。在TCN BPDU被根桥接收并处理后,根桥会发送带有TC(Topology Change)标志的配置BPDU,通知全网拓扑发生了变更。此时,所有桥都会根据收到的TC配置BPDU更新自己的状态和信息。
8 IPv4
IPv4协议是L3层协议。ip协议的目的:数据包的完整性检查;数据包通过防火墙的过滤;分片和重组;接收传输和转发
ip数据包大小可达到64kb,但是实际应用中,一般都会先检查通信链路上的MTU(PMTU),实际ip数据报不会超过这个最小mtu。原因:经过每个路由器时路由器将会接受这个数据包,并根据这个路由器端口的网卡驱动的MTU进行数据包的拆分,以便通过网卡发送到下一跳,到达下一跳后还要对这些帧进行重组,这引入了传输的复杂性,因此一般都会先获取到通信链路上的PMTU,然后设置IP数据包不超过这个PMTU大小。
8.1 ip头
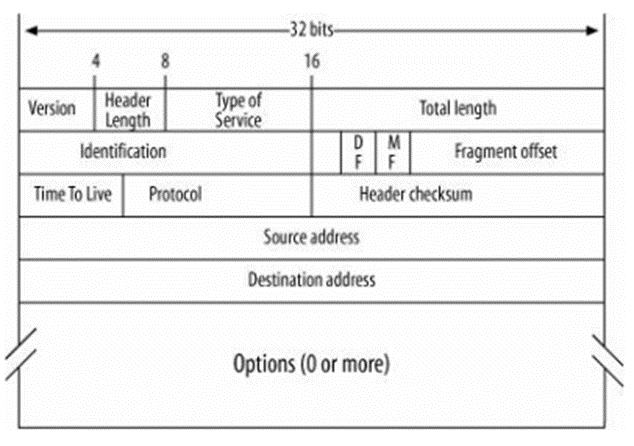
- Version:4bit,目前分两种IPV4和IPV6
- Header Length:4bit,头部长度
- Type of Service (TOS):
- Total Length:数据包总长
- Identification:
- DF (Don't Fragment):
- MF (More Fragments):
- Fragment Offset:以上这三个字段与Identification一起由IP协议的分片/重组分片功能使用。
- Time To Live (TTL):默认是64,每经过一个路由器减1,当减到0时将丢弃这个数据包,并向源发送ICMP报警信息
- Protocol:L4层所使用的协议,比如常见的协议及其编号如下
1 ICMP
6 TCP
17 UDP
- Header Checksum:IP头部的正确性检测,不包含数据部分。 因为每个路由器要改变TTL的值,所以路由器会为每个通过的数据包重新计算这个值。每种协议计算校验和的算法不同,对于IP协议,其计算IP头的一个hash值作为校验和。且此校验和被认为非常不可靠。因为大多数L2和L4协议都提供校验和,所以在L3也没有严格的必要。正是出于这个原因,校验和已从IPv6中删除。
- Source Address:
- Destination Address:
- Options:很少使用,一般没有这一项
如果Options为空,则基本的IP头占用20字节。
8.2 包的分片与重组
包的分片与重组是IP协议的主要任务之一。IP协议定义了一个数据包的最大大小为64KB,然而,并非所有网卡接口类型都能发送大小达到64KB的数据包。
当IP层需要传输一个大小超过出口接口MTU(最大传输单元)的数据包时,它需要将数据包分割成更小的片段。
分片过程会创建一系列大小相等的数据片段。
一个被分片的IP数据包通常由目的主机进行重组,但那些需要查看整个IP数据包的中间设备可能也不得不进行重组。防火墙和网络地址转换(NAT)路由器就是这类设备的两个例子。
8.3 PMTU discovery
路径MTU发现,是如何工作的:
- 发送方设置DF标志:发送方在发送IP数据包时,会在IP报头中设置DF(Don't Fragment)标志,表示该数据包不允许分片。
- 数据包传输与检查:数据包在传输过程中,会经过多个网络设备(如路由器)。每个网络设备都会检查到达的数据包大小是否超过其自身的MTU。
- ICMP消息反馈:如果某个网络设备发现接收到的数据包大小超过了其MTU,并且该数据包设置了DF标志,那么该设备会向发送方发送一个ICMP(Internet Control Message Protocol)消息,类型为3(Destination Unreachable),代码为4(Fragmentation Needed and DF Set)。这个ICMP消息中包含了该设备可接受的MTU值。
- 发送方调整MTU:发送方收到ICMP消息后,会缓存接收到的MTU值,并据此调整后续发送的数据包大小,以避免分片。这个过程可能会重复多次,直到发送方找到一个不会引发分片且能够成功传输的MTU值,即PMTU。

