hadoop官方文档解读
Hadoop是一个分布式计算框架,用于存储和处理大规模数据集。
首先搞清楚为什么需要使用Hadoop
Hadoop进行数据处理可以充分利用分布式计算和存储的优势,适用于大规模数据的批处理和分布式计算场景。
裸机上进行数据处理则更适合小规模数据或需要实时处理的场景。
在裸机上进行数据处理和使用Hadoop进行数据处理有以下区别:
-
分布式处理能力:Hadoop是一个分布式计算框架,可以将数据分布在多台计算机上进行并行处理。相比之下,裸机上的数据处理通常是在单台计算机上进行,无法充分利用多台计算机的处理能力。
-
数据存储和处理:Hadoop使用Hadoop分布式文件系统(HDFS)来存储数据,数据被分割成多个块并分布在集群中的多个节点上。而在裸机上进行数据处理时,数据通常存储在本地磁盘上。
-
容错性:Hadoop具有高度的容错性,当集群中的某个节点发生故障时,任务可以自动重新分配到其他可用节点上继续执行。而在裸机上进行数据处理时,如果计算机发生故障,可能会导致任务中断或数据丢失。
-
扩展性:Hadoop可以通过添加更多的计算节点来扩展集群的处理能力,以适应不断增长的数据量和计算需求。而在裸机上进行数据处理时,扩展性受限于单台计算机的处理能力和存储容量。
-
数据处理模型:Hadoop使用MapReduce编程模型进行数据处理,将任务分为Map和Reduce两个阶段,适用于大规模数据的批处理。而在裸机上进行数据处理时,可以使用各种编程语言和工具进行数据处理,包括实时处理和交互式查询等。
1 安装
部署可分为单节点部署、伪分布式部署、集群部署
1.1 单节点部署
先到合适的路径下面,比如/data/software
下载
[szj@localhost software]$ wget wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz --no-check-certificate
解压
[szj@localhost software]$ tar -zxvf hadoop-3.3.6.tar.gz [szj@localhost software]$ cd hadoop-3.3.6/
修改etc/hadoop/hadoop-env.sh
vi etc/hadoop/hadoop-env.sh
内容如下
export JAVA_HOME=/data/software/jdk1.8.0_251
创建input目录
[szj@localhost software]$ mkdir input [szj@localhost software]$ cp etc/hadoop/*.xml input
执行hadoop命令
[szj@localhost software]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar grep input output 'dfs[a-z.]+'
将会生成output文件夹
[szj@localhost hadoop-3.3.6]$ ll output/ total 4 -rw-r--r--. 1 szj szj 29 Oct 20 00:05 part-r-00000 -rw-r--r--. 1 szj szj 0 Oct 20 00:05 _SUCCESS [szj@localhost hadoop-3.3.6]$
这里没有启动hdfs文件系统。与其说是单节点部署,不如说是在本地文件系统下运行了一个hadoop的示例程序。
1.2 伪分布式
1.2.1 配置和执行
修改etc/hadoop/core-site.xml
[szj@localhost hadoop-3.3.6]$ vi etc/hadoop/core-site.xml
内容
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
修改etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
配置各节点之间免密登陆
$ ssh localhost
如果提示输入密码则执行如下操作
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
格式化文件系统
$ bin/hdfs namenode -format
启动NameNode和DataNode守护进程
[szj@localhost hadoop-3.3.6]$ sbin/start-dfs.sh Starting namenodes on [localhost] Starting datanodes Starting secondary namenodes [localhost.localdomain] [szj@localhost hadoop-3.3.6]$
然后我们就可以在浏览器中查看部署运行情况了http://xxxx:9870/
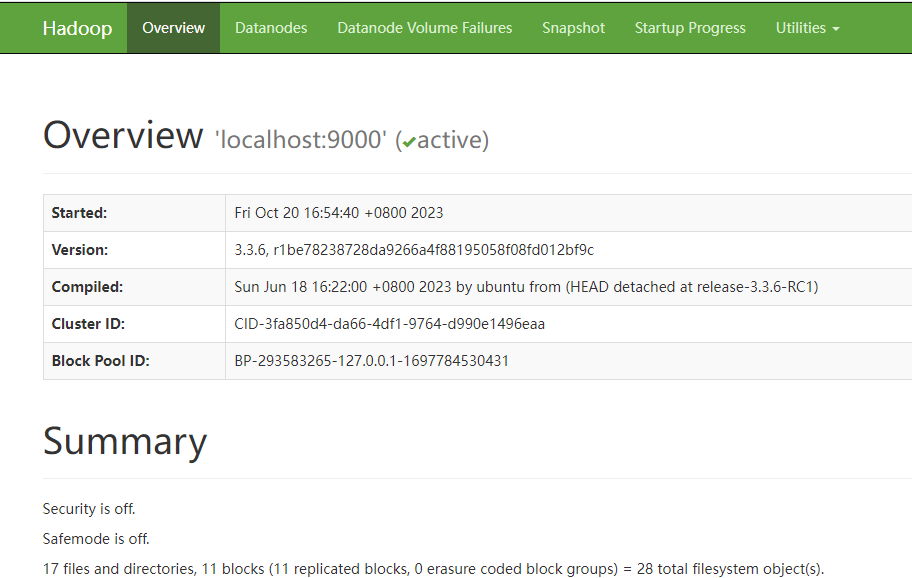
在hdfs中创建用户目录
$ bin/hdfs dfs -mkdir -p /user/szj
拷贝本地文件路径input下的文件到hdfs
$ bin/hdfs dfs -mkdir input $ bin/hdfs dfs -put etc/hadoop/*.xml input
运行自带的示例
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar grep input output 'dfs[a-z.]+'
把hdfs中的输出拷贝到本地文件系统
$ bin/hdfs dfs -get output output
然后我们就可以在本地查看了
[szj@localhost hadoop-3.3.6]$ cat output/* 1 dfsadmin 1 dfs.replication [szj@localhost hadoop-3.3.6]$
或者我们可以直接在hdfs文件系统下面查看输出
[szj@localhost hadoop-3.3.6]$ bin/hdfs dfs -cat output/* 1 dfsadmin 1 dfs.replication [szj@localhost hadoop-3.3.6]$
如果不使用了,我们也可以停止hadoop服务
$ sbin/stop-dfs.sh
1.2.2 使用yarn
我们看看如何使用yarn运行一个MapReduce作业。
etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value> </property> </configuration>
etc/hadoop/yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value> </property> </configuration>
启动yarn
[szj@localhost hadoop-3.3.6]$ sbin/start-yarn.sh Starting resourcemanager Starting nodemanagers [szj@localhost hadoop-3.3.6]$
管理页面
http://xxxx:8088/
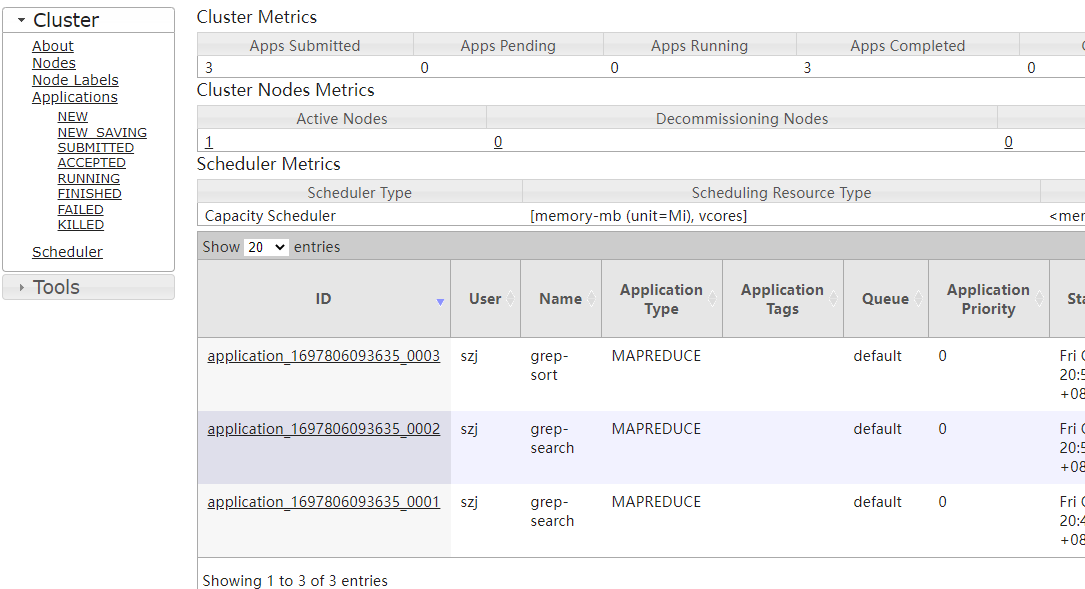
运行MapReduce工作
[szj@localhost hadoop-3.3.6]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar grep -Dmapreduce.map.memory.mb=1999 -Dmapreduce.reduce.memory.mb=1024 input output1 'dfs[a-z.]+'
如果没有报错,说明运行成功,我们可以在页面上查看运行成功的任务,也可以使用命令行在hdfs文件系统下查看输出。
[szj@localhost hadoop-3.3.6]$ bin/hdfs dfs -cat output1/* 1 dfsadmin 1 dfs.replication [szj@localhost hadoop-3.3.6]$

 浙公网安备 33010602011771号
浙公网安备 33010602011771号