zookeeper介绍
官网:https://zookeeper.apache.org/doc/r3.9.1/index.html
ZooKeeper是一个高性能的分布式协调服务。它提供了一些常见服务:命名、配置管理、同步、组服务等
1 设计目标
1.1 简单
分布式系统各进程之间可通过共享的类似于文件系统树形结构的形式实现各进程之间的互相协调。zookeeper中每个树形结构上的非叶子节点称之为namespace命名空间。叶子节点称之为znode。命名空间由znode组成。与文件系统不同的是,zookeeper数据存储于内存中,因此能够实现高吞吐量低延迟。
zookeeper在实现方面非常注重高性能、高可用、严格有序。因此其可用于大型分布式系统、不会成为单点故障。
1.2 分布式
zookeeper本身是分布式的。

只要大多数节点存活,zookeeper就会正常提供服务。
客户端连接其中一个zookeeper节点,维持心跳。当该节点挂了,会自动切换到其他节点。
1.3 有序
zookeeper可保证数据被有序处理
2 数据模型-树形命名空间

树中的每个znode维护着该节点的数据更新版本、ACL变更和时间戳。每次数据发生变化版本号就会增加。当客户端从该节点获取数据时,也会携带版本号给客户端。
3 特性
zookeeper给出了一些承诺
- 顺序一致性——来自客户端的更新将按照它们被发送的顺序应用。
- 原子性——更新要么成功要么失败。没有部分结果。
- 单一系统映像——客户端将看到服务的相同视图,而不管它连接到哪个服务器。
- 可靠性——一旦应用了更新,它将从那时起持续存在,直到客户端覆盖更新。
- 及时性——保证系统的客户端视图在一定的时间范围内是最新的。
4 简单的api
zookeeper只提供了如下几个api
- create : creates a node at a location in the tree
- delete : deletes a node
- exists : tests if a node exists at a location
- get data : reads the data from a node
- set data : writes data to a node
- get children : retrieves a list of children of a node
- sync : waits for data to be propagated
5 实现
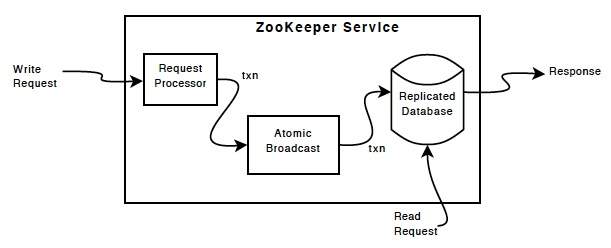
上图的replicated database是内存数据库,当有一个更新到达时,首先会写入日志,当日志成功写盘后,更新才会写到内存数据库。
每个zookeeper节点都会提供服务,但是写操作只会写到主节点,然后主节点会同步信息到其他从节点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号