

浏览器原理与应用
2 BOM和DOM
转载自:https://blog.csdn.net/qq877507054/article/details/51395830
2.1 BOM和DOM关系结构图
首先,BOM和DOM是XX对象模型,是js里面的概念,js使用这两个模型来操作浏览器和文档。BOM是浏览器对象模型,DOM是文档对象模型。
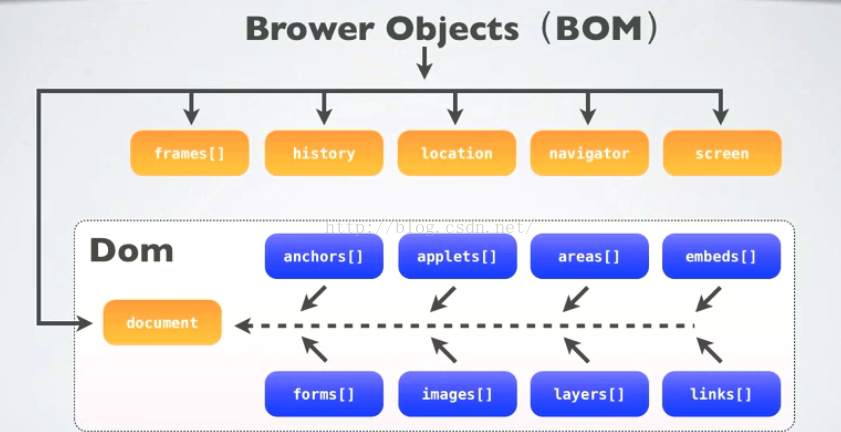
BOM的顶层对象是window,window下面包含了DOM(document)、frames、history、location、navigator、screen
DOM(document)是BOM的下层对象,DOM用于操作文档节点。
下图中,归DOM管的:E区
归BOM管的:ABCDE区。
3 动态支持
浏览器本质上是一个应用程序,其用于呈现html文档。
大部分html文档都是静态的,为了实现交互,html定义了一个特殊的标签--form,每次form可以设置请求方式、提交到哪个url,提交之后,浏览器发起一次http请求,接收http响应,其响应也是html,刷新整个页面。因此通过html的form标签还是不够动态。
为了能够实现更为动态的效果,js就被采用了,js是浏览器上执行的脚本,浏览器可以执行很多脚本,比如js、java、等。需要在浏览器中设置是否允许该类型的脚本在浏览器这个沙箱中运行。主流只默认支持js。通常使用js在浏览器中操作dom实现页面的动态效果,还有另外一个用途就是通过浏览器发送http请求。这是ajax的前提。
如果仔细观察一个form的提交,你会发现,一旦用户点击"submit"按钮,表单开始提交,浏览器会刷新页面,然后在新页面里操作是成了还是失败了,这就是原生form的运行原理,一个form请求会使用浏览器底层的网络功能发送和接收数据,并会刷新整个页面。
如果要让用户留在当前页,同时发送http请求,就必须用javascript发送请求和刷新dom。做的比较好的一个方案就是ajax(Asynchronous JavaScript and XML)
3.1 ajax
ajax和fetch都是用于支持异步发送http请求的方式。
ajax是通过XMLHttpRequest实现的,其底层使用了浏览器的网络栈发送http请求。
fetch是一种比ajax新的技术,其底层是通过Promise机制实现的。
示例

function success(text) { console.log('------------------success') } function fail(code) { console.log('------------------status:'+code) } var request = new XMLHttpRequest(); // 新建XMLHttpRequest对象 request.onreadystatechange = function () { // 状态发生变化时,函数被回调 if (request.readyState === 0) {console.log('------------------0')} if (request.readyState === 1) {console.log('------------------1')} if (request.readyState === 2) {console.log('------------------2')} if (request.readyState === 3) {console.log('------------------3')} if (request.readyState === 4) { // 成功完成 console.log('------------------4') // 判断响应结果: if (request.status === 200) { // 成功,通过responseText拿到响应的文本: return success(request.responseText); } else { // 失败,根据响应码判断失败原因: return fail(request.status); } } else { // HTTP请求还在继续... } } // 发送请求: request.open('GET', '/api/categories'); request.send();
运行结果
------------------1 undefined VM107:30 GET https://blog.csdn.net/api/categories 404 (Not Found) (匿名) @ VM107:30 VM107:11 ------------------2 VM107:12 ------------------3 VM107:14 ------------------4 VM107:5 ------------------status:404
ajax各个状态readyState的说明
- (0)未初始化:此阶段确认XMLHttpRequest对象是否创建,并为调用open()方法进行未初始化作好准备。值为0表示对象已经存在,否则浏览器会报错--对象不存在。
- (1)载入:此阶段对XMLHttpRequest对象进行初始化,即调用open()方法,根据参数(method,url,true)完成对象状态的设置。并调用send()方法开始向服务端发送请求。值为1表示正在向服务端发送请求。
- (2)载入完成:此阶段接收服务器端的响应数据。但获得的还只是服务端响应的原始数据,并不能直接在客户端使用。值为2表示已经接收完全部响应数据。并为下一阶段对数据解析作好准备。
- (3)交互:此阶段解析接收到的服务器端响应数据。即根据服务器端响应头部返回的MIME类型把数据转换成能通过responseBody、responseText或responseXML属性存取的格式,为在客户端调用作好准备。状态3表示正在解析数据。
- (4)完成:此阶段确认全部数据都已经解析为客户端可用的格式,解析已经完成。值为4表示数据解析完毕,可以通过XMLHttpRequest对象的相应属性取得数据。
4 window对象
在浏览器中window对象表示浏览器窗口。
window对象是在浏览器环境中的一个对象,它并不是js语言本身的一部分,在非浏览器环境中(比如nodejs)就没有这个对象
4.1 window.document
表示当前页面的dom结构
4.2 window.navigator
存储浏览器的一些信息、比如浏览器名称、版本、操作系统等等
4.3 window.screen
表示屏幕信息
4.4 window.location
页面的url信息
location.protocol; // 'http'
location.host; // 'www.example.com'
location.port; // '8080'
location.pathname; // '/path/index.html'
location.search; // '?a=1&b=2'
location.hash; // 'TOP'4.5 window.history
浏览器的历史记录。可以调用history对象的back()或forward (),相当于用户点击了浏览器的“后退”或“前进”按钮。由于目前页面大量使用ajax或者fetch进行页面交互,history的作用没那么大了。
附1 浏览器原理
参考:
https://web.dev/howbrowserswork/
http://taligarsiel.com/Projects/howbrowserswork1.htm
https://www.cnblogs.com/zhuanzhuruyi/p/6496276.html
1.1 浏览器的作用
浏览器的主要作用是呈现web资源,而这些web资源是通过请求一个服务器获得。web资源可以是html文档、pdf、图片或者其他类型的资源。资源的地址使用URI来指定。
浏览器解释和显示HTML文件的方式在HTML和CSS规范中指定。这些规范是由W3C(World Wide Web Consortium)组织维护的,它是网络的标准组织。但是各个浏览器产品不完全遵守W3C制定的规范,它们都有定制各自的扩展,这也导致了各个浏览器之间的兼容问题。
浏览器的界面一般都有固定的形式:
1 地址栏
2 前进和后退按钮
3 书签
但是W3C规范并没有规定浏览器界面应该长啥样,之所以目前主流浏览器都有这些界面主要是因为多年经验的良好实践和各个浏览器产品之间的互相模仿。
1.2 浏览器的结构
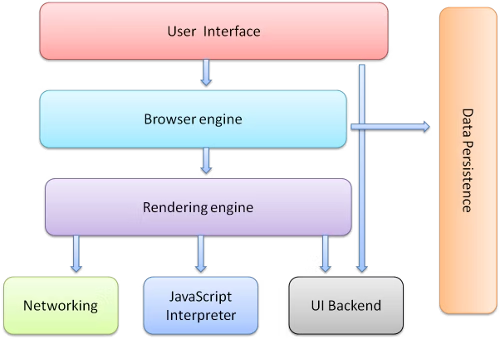
浏览器的主要组件包括:
- 用户界面:除了浏览器主窗口显示的你请求的页面外,其他显示的各个部分都属于用户界面。
- 浏览器引擎:在用户界面和渲染引擎之间传送指令。
- 渲染引擎:负责显示请求的内容。
- 网络:用于网络调用,比如 HTTP 请求。其接口与平台无关,并为所有平台提供底层实现。
- 用户界面后端:用于绘制基本的窗口小部件,比如组合框和窗口。其公开了与平台无关的通用接口,而在底层使用操作系统的用户界面方法。
- JavaScript 解释器:用于解析和执行 JavaScript 代码。
- 数据存储:这是持久层。浏览器需要在硬盘上保存各种数据,例如 Cookie。
1.2.1 rending engine
渲染引擎rending engine的职责是渲染,即在浏览器屏幕上显示所请求的内容。
默认情况下,rending engine可以显示HTML、XML文档和图片。如果要显式其他数据类型需要通过插件或者扩展。比如显式pdf文档需要pdf插件来支持。
不同的浏览器使用不同的rending engine,比如IE使用Trident,FireFox使用Gecko,Chrome使用Blink(WebKit)
1.2.1.1 渲染过程

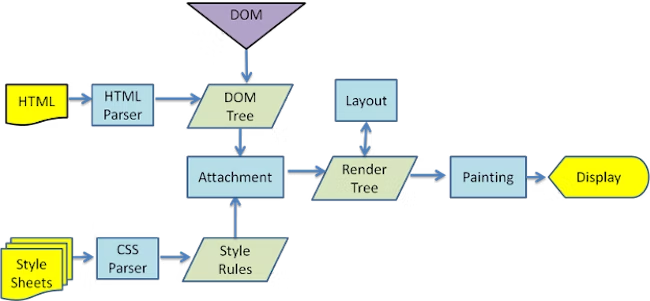
1 解析HTML文档(html解析器,下面会讲),并将文档中的标签转化为dom节点树,即”内容树”。同时,它也会解析外部CSS文件以及style标签中的样式数据。这些样式信息连同HTML中的”可见内容”一道,被用于构建另一棵树——”渲染树(Render树)”。
2 渲染树由一些带有视觉属性(如颜色、大小等)的矩形组成,这些矩形将按照正确的顺序显示在频幕上
3 渲染树构建完毕之后,将会进入”布局”处理阶段,即为每一个节点分配一个屏幕坐标。再下一步就是绘制(painting),即遍历render树,并使用UI后端层绘制每个节点。
4 这个过程是逐步完成的,为了更好的用户体验,渲染引擎将会尽可能早的将内容呈现到屏幕上,并不会等到所有的html都解析完成之后再去构建和布局render树。它是解析完一部分内容就显示一部分内容,同时,可能还在通过网络下载其余内容(每次下载8K的块)。
下图显式的是Webkit的渲染过程(Gecko或其他引擎可能略有不同):
1.2.1.1.1 HTML Parser
HTML解析器的作用是将HTML标记解析成DOM Tree。
HTML语法是W3C组织定义的规范。
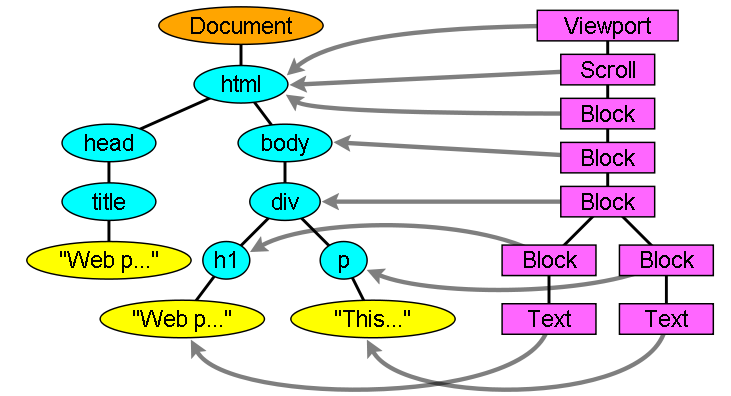
解析的输出是DOM树,即文档对象模型(Document Object Model),它是HTML文档的对象表示,同时也是外部内容(例如javascript)与HTML元素之间的接口。
解析树的根节点是Document对象。
解析算法
解析由两个过程组成:符号化和构建树
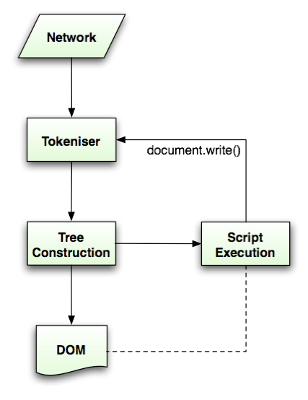
符号化是指将输入内容解析成多个标记:比如起始标记、结束标记、属性名称和属性值。对应下图中的Tokeniser,也就是说符号化把html分割成一个个小部分(标记)。
Tokeniser(标记生成器)把生成的标记传递给Tree Construcation(树构造器),产生一个DOM节点放入DOM树中
如果有需要执行的js脚本,则Script Execution(脚本执行器)执行脚本,产生document.write()动作作用在Tokeniser,再次产生一个标记放入DOM树中,也就是说js脚本可以修改DOM结构。
如此往复循环最终生成一个DOM树
1 Tokeniser
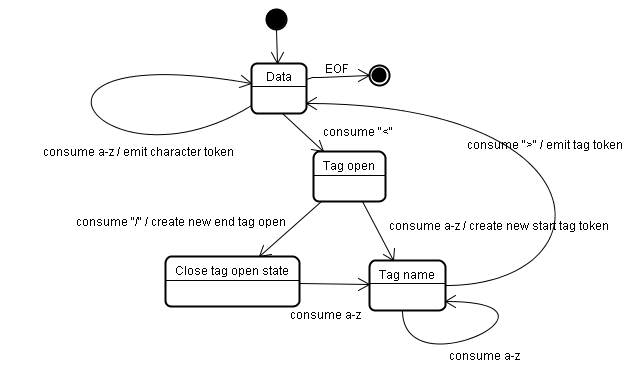
Tokeniser的输出是一个html token(标记)。其工作过程是一个状态机。每个状态使用输入流的一个或多个字符,并根据这些字符更新下一个状态,状态机的输出受当前状态和Tree Construction的影响。也就是说同样的字符输入,其输出根据当前状态的不同会有很大不同。其算法太过复杂,我们举一个简单的例子说明其原理。
<html> <body> Hello world </body> </html>
初始状态是“Data”状态,当遇到“<”字符时,状态变为“Tag open”状态,然后接收并消费“a-z”字符,并创建一个“Start tag”标记,状态变为“Tag name”状态。接下来会一直处于这个状态直到“>”字符被接收并消费。在以上过程中消费的所有字符会被追加到新的token(标记)。在我们的例子中,创建的token(标记)是一个“html”标记。然后,将发送当前token(标记)到Tree Construcation(树构造器)进行DOM节点的构建,并将状态更改回“Data”状态。"<body>"标记将按相同的步骤处理。
到目前为止,发出了"html"和"body"标记。我们现在又回到了“Data”状态。消费"Hello world"的"H"字符将导致创建并发送一个字符token到Tree Construcation(树构造器),这个过程将一直进行,直到到达"</body>"的"<"。
当我们遇到"</body>"的"<",我们再次到达“Tag open”状态,接下来消费"/"将会导致创建“end tag token”,并且状态移动到“Tag name”状态。然后我们接收a-z字符并一直处于这个状态直到我们接收到一个“>”,然后这个新的tag token(这里是</bdoy>)发送到Tree Construcation(树构造器)。</html>标签将会做同样的处理
2 Tree construction
在创建解析器的同时,也会创建Document对象。在DOM树构建过程中,以Document为根节点的DOM树也会不断进行修改,向其中添加各种元素。
Tree construction的输入是Tokeniser发送过来的token(标记)
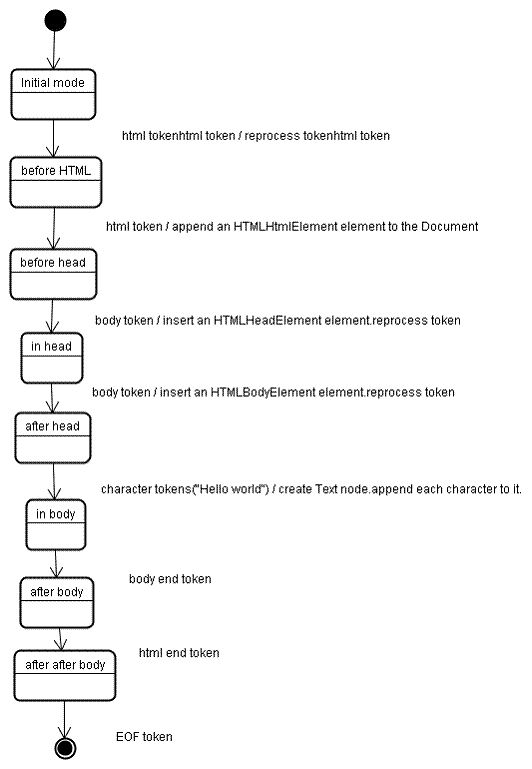
initial mode,接收<html>标签生成的html标记后转到before html mode,在这里,将会创建一个HTMLHtmlElement 元素,并将其追加到 Document 根对象上。
然后状态将改为“before head”。此时我们接收“body”标记。即使我们的示例中没有“head”标记,系统也会隐式创建一个 HTMLHeadElement,并将其添加到DOM树中。
现在我们进入了“in head”模式,然后转入“after head”模式。系统对 body 标记进行重新处理,创建并插入 HTMLBodyElement,同时模式转变为“body”。
现在,接收由“Hello world”字符串生成的一系列字符标记。接收第一个字符时会创建并插入“Text”节点,而其他字符也将附加到该节点。
接收 body 结束标记会触发“after body”模式。现在我们将接收 HTML 结束标记,然后进入“after after body”模式。接收到文件结束标记后,解析过程就此结束。
当解析结束后,浏览器会将文档标注为交互状态,并开始解析那些处于“deferred”模式的脚本,也就是那些应在文档解析完成后才执行的脚本。然后,文档状态将设置为“complete”,一个“load”事件将随之触发。
1.2.1.1.2 CSS Parser
和HTML不同,CSS是上下文无关的语法,可以使用简介中描述的各种解析器进行解析
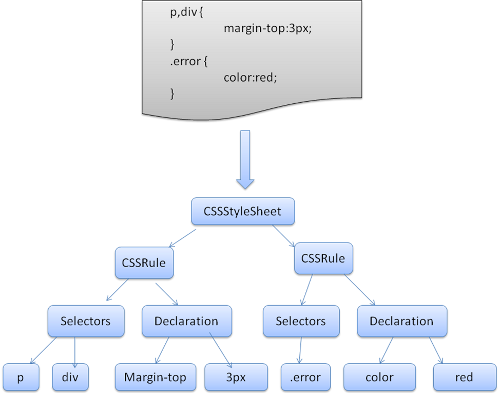
我们说明一下Webkit CSS解析器的解析过程。解析器将 CSS 文件解析成 StyleSheet 对象,且每个对象都包含 CSS Rules。CSS Rule对象则包含选Selectors和声明对象,以及其他与 CSS 语法对应的对象。
1.2.1.1.3 Script Execution
将在后续补充,或者在javascript中讲解
1.2.1.1.4 脚本执行和样式表的顺序
解析器遇到 <script> 标记时,html文档的解析将会暂停,转而去解析 <script> 脚本并执行该脚本。也就是说网络模型时同步的。
可以将 <script> 标签标注为defer,这样script脚本的执行将会被延后到html文档解析完后进行。
Webkit对需要通过网络加载的资源做了优化,会另起一个线程对外部资源进行预加载。
对于样式表,理论上来说,应用样式表不会修改 DOM 树,因此似乎没有必要等待样式表并停止文档解析。但有些情况下,脚本在文档解析阶段会请求样式信息。如果当时还没有加载和解析样式,脚本就会获得错误的回复。因此,Firefox 在样式表加载和解析的过程中,会禁止所有脚本。而对于 Webkit 而言,仅当脚本尝试访问的样式属性可能受尚未加载的样式表影响时,它才会禁止该脚本。
1.2.1.1.5 Render Tree
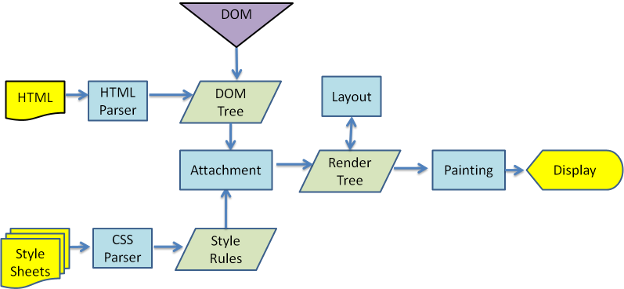
在DOM树构建的同时,浏览器还会构建另一棵树,Render Tree(渲染树)。这是由DOM树中可视化元素按照其显示顺序而组成的树,也是文档的可视化表示,他的作用是按照正确的顺序绘制内容。
Render Tree中每个Renderer表示一个矩形区域,通常对应于节点的CSS框。
Render Tree和DOM Tree的关系
Renderer和DOM元素相对应,但不是一一对应。非可视化的DOM元素不会插入Render树中(例如head元素)
DOM树和Style Role合并的过程,就是Style Rule附加到DOM Tree的过程。
1.2.1.1.6 Layout
Renderer被创建并加载到Render Tree后,其大小和位置信息并没有指定,计算Renderer大小和位置的过程称为layout或reflow(布局或重排)
布局是一个递归的过程,它从Render Tree的root renderer开始,递归遍历部分或者所有树节点,计算每一个节点renderer的几何信息。
root renderer的坐标是(0,0),大小是整个视口(也就是浏览器窗口的可见区域)。
然后,root renderer对其需要布局的子节点进行布局,以此类推。
全局布局和增量布局
全局布局指的是触发了整个Render Tree的布局,触发原因可能是:全局样式更改,屏幕大小调整等。
增量布局,只对dirty 的renderer进行布局。(如果某个renderer发生更改,会将自身或其子节点标记为dirty)
全局布局是同步的,增量布局是异步的。
对于增量布局,各个浏览器实现方式不一样,firefox维护一个队列,当有renderer需要进行增量布局时,将会把reflow命令放入队列,然后调度程序将会批量处理;Webkit有一个定时器,定时扫描Render Tree,并对dirty renderer进行重新布局。
布局过程
- 父renderer确定自己的宽度(高度由子renderer的累加高度和边距补白确定)
- 父renderer依次处理子renderer,设置子renderer的坐标
- 如果有必要,调用子renderer的布局(比如子renderer是dirty的,或者这时全局布局)
- 父renderer根据子renderer的累加高度以及边距和补白高度设置自身高度,此值也供父renderer的父renderer使用。
- 将dirty位设置为false
宽度计算
renderer的宽度是通过如下方式确定的:容器的宽度、renderer的样式中的width属性、margins和borders
1.2.1.1.7 Painting
在绘制阶段,系统会遍历Render Tree,并调用renderer的paint方法,将呈现器(renderer)的内容显示在屏幕上,绘制工作是使用UI(User Interface)基础结构组件。见本文的UI小节
和布局一样,绘制也分为全局(绘制整个渲染树)和增量两种。在增量绘制中,部分renderer(呈现器)发生了更改,但是不会影响整个树。更改后的呈现器将其在屏幕上对应的矩形区域设为无效,这导致 OS (这里是否指的是linux或者windows操作系统?)将其视为一块“dirty 区域”,并生成“paint”事件。
绘制顺序
CSS2定义了绘制顺序https://www.w3.org/TR/CSS21/zindex.html,这实例上是元素在堆叠上下文中的堆叠顺序。一个块renderer的堆叠顺序为
- 背景色
- 背景图片
- border
- children
- outline
在DOM树发生变化时,浏览器会尽可能做出最小的响应。例如,元素的颜色改变后,只会对该元素进行重绘。元素的位置改变后,只会对该元素进行布局和重绘。添加 DOM 节点后,会对该节点进行布局和重绘。
也有一些重大变化(例如增大“html”元素的字体)会导致缓存无效,使得整个渲染树都会进行重新布局和绘制
1.2.1.2 渲染线程
rending engine是单线程的。在firefox中是浏览器进程的主线程;在Chrome中是Tab进程的住线程。
主线程是一个无限死循环,在这个循环中等待事件发生并处理。
1.3 CSS2可视化模型
canvas在每个方向上都是无限的,但是浏览器根据viewport(视口)的尺寸选择一个初始宽度。参考:https://www.w3.org/TR/CSS21/intro.html#processing-model
canvas如果包含在其他canvas中,它就是透明的;否则,会由浏览器指定一种颜色。参考:https://www.w3.org/TR/CSS2/zindex.html
1.3.1 CSS框模型
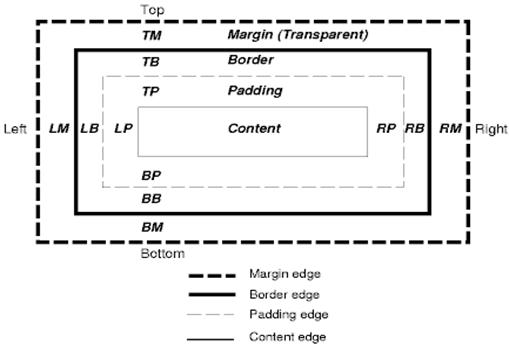
css box是一个矩形框,这个矩形框描述的是文档树中的某一个元素,并根据可视格式模型进行布局。
每个矩形框都有一个Content区域(例如文本、图片),还有可选的周围补白,边框和边距区域。
每个节点产生0-n个这样的框,所有元素含有一个display属性,该属性决定了矩形框的类型,默认是inline。但是也有某些元素的默认值不是inline,这是由浏览器设定的,而浏览器的设定遵守了W3C标准,参考https://www.w3.org/TR/CSS2/sample.html
html, address, blockquote, body, dd, div, dl, dt, fieldset, form, frame, frameset, h1, h2, h3, h4, h5, h6, noframes, ol, p, ul, center, dir, hr, menu, pre { display: block; unicode-bidi: embed } li { display: list-item } head { display: none } table { display: table } tr { display: table-row } thead { display: table-header-group } tbody { display: table-row-group } tfoot { display: table-footer-group } col { display: table-column } colgroup { display: table-column-group } td, th { display: table-cell } caption { display: table-caption } th { font-weight: bolder; text-align: center } caption { text-align: center } body { margin: 8px } h1 { font-size: 2em; margin: .67em 0 } h2 { font-size: 1.5em; margin: .75em 0 } h3 { font-size: 1.17em; margin: .83em 0 } h4, p, blockquote, ul, fieldset, form, ol, dl, dir, menu { margin: 1.12em 0 } h5 { font-size: .83em; margin: 1.5em 0 } h6 { font-size: .75em; margin: 1.67em 0 } h1, h2, h3, h4, h5, h6, b, strong { font-weight: bolder } blockquote { margin-left: 40px; margin-right: 40px } i, cite, em, var, address { font-style: italic } pre, tt, code, kbd, samp { font-family: monospace } pre { white-space: pre } button, textarea, input, select { display: inline-block } big { font-size: 1.17em } small, sub, sup { font-size: .83em } sub { vertical-align: sub } sup { vertical-align: super } table { border-spacing: 2px; } thead, tbody, tfoot { vertical-align: middle } td, th, tr { vertical-align: inherit } s, strike, del { text-decoration: line-through } hr { border: 1px inset } ol, ul, dir, menu, dd { margin-left: 40px } ol { list-style-type: decimal } ol ul, ul ol, ul ul, ol ol { margin-top: 0; margin-bottom: 0 } u, ins { text-decoration: underline } br:before { content: "\A"; white-space: pre-line } center { text-align: center } :link, :visited { text-decoration: underline } :focus { outline: thin dotted invert } /* Begin bidirectionality settings (do not change) */ BDO[DIR="ltr"] { direction: ltr; unicode-bidi: bidi-override } BDO[DIR="rtl"] { direction: rtl; unicode-bidi: bidi-override } *[DIR="ltr"] { direction: ltr; unicode-bidi: embed } *[DIR="rtl"] { direction: rtl; unicode-bidi: embed } @media print { h1 { page-break-before: always } h1, h2, h3, h4, h5, h6 { page-break-after: avoid } ul, ol, dl { page-break-before: avoid } }
1.3.2 position方案
有3种方案:
- 普通:根据对象在文档中的位置进行定位,也就是说对象在Rending Tree中的位置和它在 DOM 树中的位置相似,并根据其框类型和尺寸进行布局
- Float:对象先按照1中描述的普通模式布局,然后尽可能的向左或者向右移动。
- Absolute:对象在Rending Tree中的位置和它在DOM树中的位置不同。
我们使用元素的position属性或者loat属性设定元素的position
- 如果值是static或者relative,就是普通布局
- 如果值是absolute或者fixed,就是Absolute布局
static定位无需定义位置,而是使用默认位置。对于其他方案,需要指定位置:top、bottom、left、right
框的布局方式是由以下因素决定的
- box类型,分为Block box、Inline box
- box尺寸
- 定位方案
- 外部信息,比如图片大小或者屏幕大小
1.3.3 box类型
Block box:形成一个block块,在浏览器窗口中拥有其自己的矩形区域
Inline box:没有自己的block块,但是在一个容器block块内部。
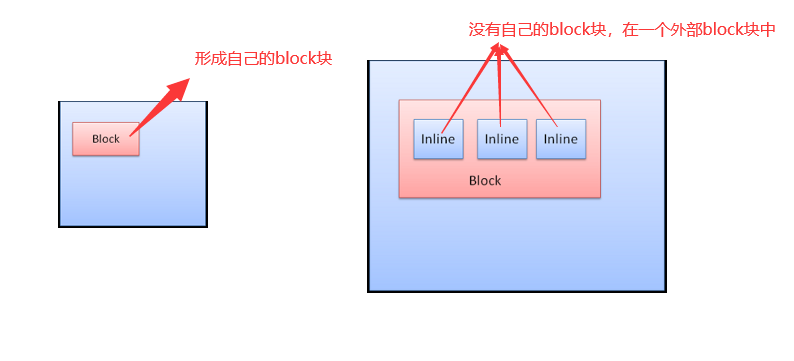
block类型的box是垂直布局的,inline类型的box是水平分布的
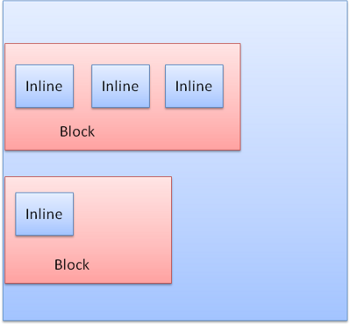
1.3.4 定位
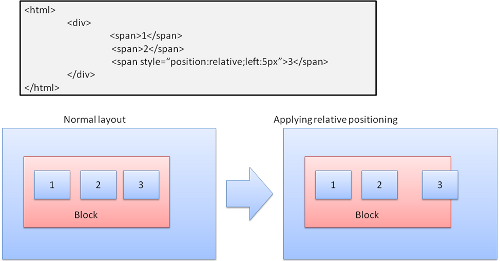
1.3.4.1 Relative
相对定位:首先按照普通方式定位,然后根据所需偏移量进行移动。
1.3.4.2 Floats
浮动框会移动到行的左边或右边。有趣的特征在于,其他框会浮动在它的周围
例子
<p> <img style="float:right" src="images/image.gif" width="100" height="100">Lorem ipsum dolor sit amet, consectetuer... </p>
将会看起来是这样

1.3.4.3 Absolute和Fixed
这种布局的容器就是可视区域,在固定的位置。元素不参与普通flow。
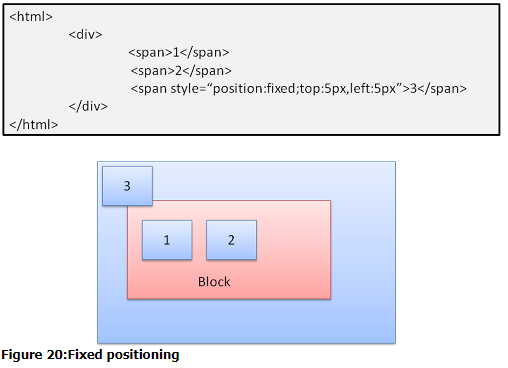
1.3.4.4 分层展示
页面元素的堆叠规则如下所示
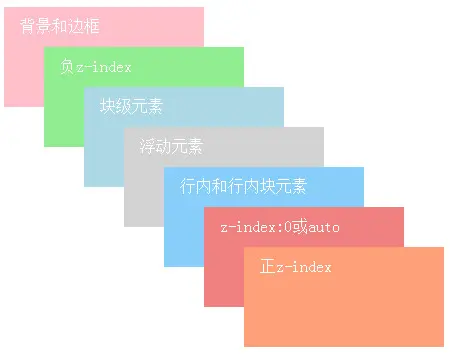
z-index代表了box框的第三个维度,也就是沿“z 轴”方向的位置。
例子
<style type="text/css"> div { position: absolute; left: 2in; top: 2in; } </style> <P> <div style="z-index: 3;background-color:red; width: 1in; height: 1in; "></div> <div style="z-index: 1;background-color:green;width: 2in; height: 2in;"></div> </p>



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix