
深入理解linux内核第三版(二)进程
进程是程序的执行的一个实例。从内核的角度看,进程的目的就是担当分配系统资源(CPU时间片和内存)的实体。
1 普通线程和轻量级进程
普通线程,指的是,在一个应用中,有多个线程在执行。但是CPU对该应用的调度是以进程为单位进行调度的,这个进程中的多个线程不能够并发的执行。
轻量级进程实现多线程,情况则不一样,在CPU分配时间片时,各个轻量级进程和其他进程一样,都有相同的机会获得CPU时间片。这样一个进程中的多个线程才能够真正实现并发执行。
Linux使用轻量级进程对多线程应用提供支持。每一个线程(轻量级进程)都可以由内核独立调度。
2 内核线程和用户线程
内核线程:线程切换由内核控制。线程参与CPU时间片的分配,windows系统就是内核线程。
用户线程:线程切换由进程自己控制,不需要内核的参与,内核感知不到多线程的存在,只能感知到进程,所以CPU时间片切换是按照进程来切换的。一个线程的阻塞将导致整个进程的阻塞。
用户线程运行在一个中间系统上,也就是说运行在一个进程上。比如python中的线程就是用户级线程,它运行在python进程中,操作系统只能感知到python进程的存在,感知不到线程的存在,所以python线程不能充分利用多核cpu的优势。而java则不一样,java天然支持多线程,因为java创建线程的时候,实际上是调用内核clone()函数,传递特定参数使其创建的是轻量级进程,因此,java多线程直接参与CPU时间片的分配,且能充分利用多核CPU的优势
3 进程描述符
为了描述和控制进程的运行,我们引入PCB(进程控制块)。它是进程管理和控制最重要的数据结构。每一个进程均有一个PCB,在创建进程时,创建PCB,并伴随着进程的整个生命周期。在Linux中我们用结构体task_struct来表示PCB,也叫进程描述符。进程描述符包含了进程所有相关信息,所以它相当复杂,见下图
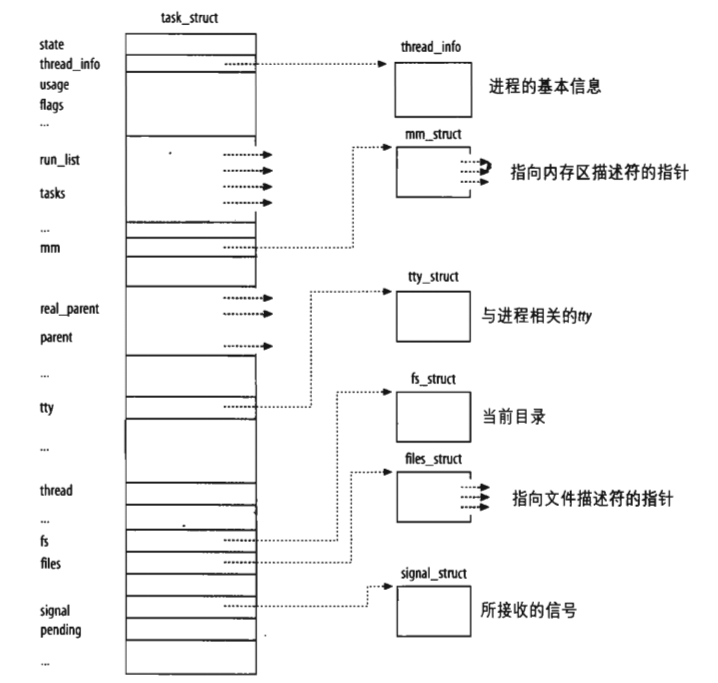
3.1 进程状态state
进程描述符的state字段描述了进程当前所处的状态。
可运行状态(TASK_RUNNING):进程要么在CPU上运行,要么等待获取CPU执行
可中断等待状态(TASK_INTERRUPTIBLE):进程被挂起,等待某个条件为真
不可中断等待状态(TASK_UNINTERRUPTIBLE):与可中断等待状态类似,但是有一个例外,把信号传递到睡眠进程不能改变它的状态。
暂停状态(TASK_STOPPED):进程的执行被暂停
跟踪状态(TASK_TRACED):比如进程受到debugger进程的监控,则处于跟踪状态
僵死状态(EXIT_ZOMBIE):进程的执行被终止,但是还要等父进程返回一些信息
死亡状态(EXIT_DEAD):僵死状态中,父进程处理完,进程被标记为EXIT_DEAD状态。
3.2 PID标识一个进程
在task_struct中pid字段描述了进程的id。当我们创建新的进程时,其pid为最大的进程pid+1,也就是说进程的pid是递增的。当进程的pid达到设置的最大值时,将会从1开始循环使用未被占用的编号作为新的进程的pid。
linux中线程组,在一个线程组中,所有线程使用同一个pid,也就是该组中第一个轻量级进程的pid,它被存入进程描述符task_struct的tgid字段中。getpid系统调用返回当前进程的tgid值而不是pid的值。因此,一个多线程应用的所有线程共享相同的pid。
绝大多数进程都单独属于一个线程组,也就是说线程组中只有这个进程本身,线程组的领头线程其tgid的值和pid的值相同。
3.3 thread_info和内核栈
进程描述符中有个thread_info字段,叫做线程描述符,这个字段比较特殊,因为linux把会分配2页(8192字节)的存储空间存储thread_info和内核栈。如下图所示
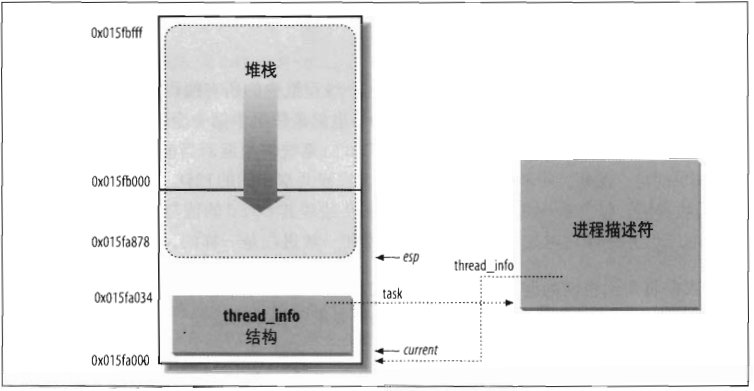
这8kb存储空间,下部分存储thread_info。上部分存储内核栈。thread_info大小是52个字节,所以内核栈最大可以达到8140字节。
说到这里,很多同学会问,内核栈是个什么东东?看下面3.3.1小节的介绍。
3.3.1 进程中的内核栈
参考:http://t.zoukankan.com/johnnyflute-p-3764421.html
所有的进程(包括内核进程和普通进程)都有一个内核栈,内核栈的大小为8kb。操作系统为每个进程都会创建一个内核栈用于陷入内核时保存上下文信息。其作用有两个:
1 当进程陷入内核时,即内核代表进程执行系统调用时,系统调用的参数就放在内核栈上,内核栈记录着进程在内核进程中的调用链
2 当中断服务程序中断当前进程时,它将使用当前被中断进程的内核栈。
对于用户进程,既有用户地址空间中的栈,也有它自己的内核栈。而内核进程只有内核栈。
内核在创建进程的时候,在创建task_struct的同事,会为进程创建相应的堆栈。每个进程会有两个栈,一个用户栈,存在于用户空间,一个内核栈,存在于内核空间。当进程在用户空间运行时,cpu堆栈指针寄存器里面的内容是用户堆栈地址,使用用户栈;当进程在内核空间时,cpu堆栈指针寄存器里面的内容是内核栈空间地址,使用内核栈。
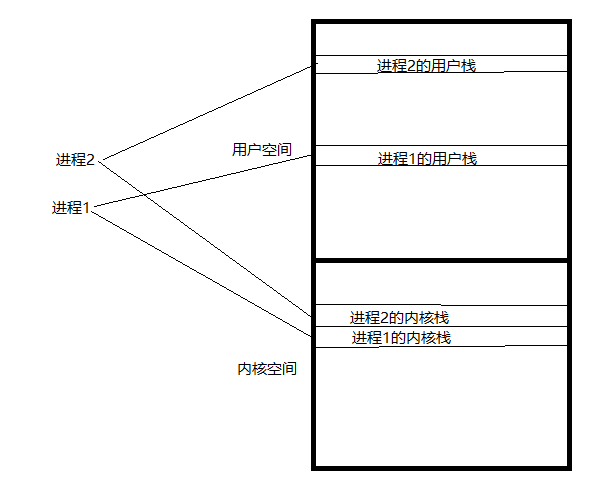
进程用户栈和内核栈的切换
当进程因为中断或者系统调用而陷入内核态之行时,进程所使用的堆栈也要从用户栈转到内核栈
进程陷入内核态后,先把用户态堆栈的地址保存在内核栈之中,然后设置堆栈指针寄存器的内容为内核栈的地址,这样就完成了用户栈向内核栈的转换。
当进程从内核态恢复到用户态执行时,在内核态执行的最后将保存在内核栈里面的用户栈的地址恢复到堆栈指针寄存器即可。这样就实现了内核栈和用户栈的互转。
3.4 进程链表
每个task_struct结构都包含一个tasks字段,表示一个进程链表。进程链表把所有的进程描述符链接起来。进程链表的头是init_task描述符,即所谓的0号进程。
3.5 组织进程
3.5.1 可运行链表
运行队列链表把处于TASK_RUNNING状态的所有进程组织在一起。
3.5.2 等待队列
进程的TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE状态表示的是进程处于等待状态,等待某个事件的发生,然后才会进入就绪队列。linux为处于这两种状态的进程创建了专门的等待队列。
等待队列的结构:等待队列由等待队列头和等待队列链表组成。
等待队列头
struct __wait_queue_head { spinlock_t lock; struct list_head task_list; }; typedef struct __wait_queue_head wait_queue_head_t;
等待队列链表中的元素
struct __wait_queue { unsigned int flags; struct task_struct * task;//进程描述符的地址 wait_queue_func_t func;//表示该进程用什么方式唤醒 struct list_head task_list;//等待相同事件进程的一个链表 }; typedef struct __wait_queue wait_queue_t;
等待队列的同步是由等待队列头中的lock自旋锁实现的。
等待队列链表中的每个元素表示一个睡眠进程,该进程等待某个事件的发生。
3.5.3 等待队列操作
创建新的等待队列头
使用 DECLARE_WAIT_QUEUE_HEAD(name) 宏创建一个新的等待队列头,它声明一个名叫name的等待队列头变量,并对lock和task_list字段进行初始化。
也可以使用 init_waitqueue_head() 初始化动态分配的等待队列头变量
创建新的等待队列链表元素
使用 init_waitqueue_entry(q,p) 初始化链表中的元素。其代码为
q->flags = 0; q->task = p; q->func = default_wake_function;
进程p将由default_wake_function唤醒。
也可以使用DEFAULT_WAIT宏声明一个wait_queue_t类型的新变量,并用当前进程初始化这个新变量。
把新元素插入等待队列
1 直接调用函数 add_wait_queue() 把一个进程插入等待队列。
2 调用 sleep_on() 把当前进程插入等待队列,其定义如下

void sleep_on(wait_queue_head_t *wq) { wait_queue_t wait; init_waitqueue_entry(&wait, current); current->state = TASK_UNINTERRUPTIBLE; add_wait_queue(wq, &wait); schedule(); remove_wait_queue(wq, &wait); }
该函数把当前进程的状态设置为TASK_UNINTERRUPTIBLE,并把它插入到特定的等待队列。然后,调用schedule()重新进行调度。当睡眠进程被唤醒时,将继续从此处往下执行,调用remove_wait_queue(wq, &wait)把该进程从等待队列中删除。
3 调用interruptible_sleep_on()把当前进程插入等待队列。
这个函数和sleep_on()函数类似,唯一的区别是,把当前进程的状态设置为TASK_INTERRUPTIBLE状态。因此,接受一个信号就可以唤醒当前进程。
4 sleep_on_timeout()和interruptible_sleep_on_timeout()
与前面函数定义类似,不同的是设置了超时时间
等待队列中进程的唤醒
内核通过下面定义的宏唤醒等待队列中的进程,并把他们状态置为TASK_RUNNING
wake_up,wake_up_nr,wake_up_all,wake_up_interruptible,wake_up_interruptible_nr,wake_up_interruptible_all,wake_up_interruptible_sync,wake_up_locked
要注意的是各个宏都是有区别的。比如wake_up可以唤醒所有类型的进程,但是wake_up_interruptible只能唤醒TASK_INTERRUPTIBLE状态的进程。
void wake_up(wait_queue_head_t *q) { struct list_head *tmp; wait_queue_t *curr; list_for_each(tmp, &q->task_list) { curr = list_entry(tmp, wait_queue_t, task_list); if(curr->func(curr, TASK_INTERRUPTIBLE|TASK_UNINTERRUPTIBLE, 0, NULL) && curr->flags) break; } }
3.6 创建进程
传统的Unix系统在创建进程时,拷贝父进程的所有资源,导致创建进程非常的慢和效率低。Linux系统通过引入3种机制来解决这个问题
1 写时复制技术。创建进程时,只复制必要信息到子进程中,父进程的页目录表和页表复制到子进程中,也就是说父进程和子进程共享代码段和数据段,所以说当发生读取操作时,父进程和子进程读取相同的物理页。但是如果父进程或者子进程试图写一个物理页,内核就会把这个页的内容拷贝到一个新的物理页,这就是写时复制技术
2 轻量级进程允许父子进程共享进程在内核的很多数据结构,如页表、打开文件表及信号处理
3 vfork()系统调用创建的进程能共享其父进程的内存地址空间。
内核使用下面三个函数实现进程创建clone()、fork()、vfork()
3.7 进程调度


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义