
HTTP1.0、HTTP1.1和HTTP2.0的区别
HTTP
http建立初期,主要是为了将超文本标记语言(HTML)文档从web服务器传送到客户端的浏览器。也就是说HTML页面放web服务器上,用户通过浏览器访问URL地址来获取网页显示的内容,但是到了现在,页面变得复杂,不仅仅是一些简单的文字和图片,同时我们的HTML页面有了CSS、JavaScript来丰富我们的页面展示,当ajax的出现我们又多了一种向服务器端获取数据的方法,这些都是基于HTTP协议的。
HTTP的基本优化
影响一个HTTP网络请求的因素主要由两个:带宽和延迟。
- 带宽:带宽可能会成为一个比较严重影响请求的问题,但是现在网络基础建设已经使得带宽得到极大的提升,我们不再会担心带宽而影响网速。
- 延迟:
- 浏览器阻塞(HOL blocking):浏览器会因为一些原因阻塞请求。浏览器对于同一个域名,同时只能有4个连接(这个根据浏览器内核不同可能会有所差异),超过浏览器最大连接数限制,后续请求就会被阻塞。
- DNS查询(DNS Lookup):浏览器需要知道目标服务器的IP才能建立连接。将域名解析为IP的这个系统就是DNS。这个通常可以利用DNS缓存结果来达到减少时间的目的。
- 建立连接(Initial connection):HTTP是基于TCP协议的,浏览器最快也要在第三次握手时才能捎带HTTP请求报文,达到真正的建立连接,但是这些连接无法复用会导致每次请求都经历三次握手和慢启动。三次握手在高延迟的场景下影响较明显,慢启动则对文件类大请求影响较大。
HTTP1.0和HTTP1.1的一些区别
- 缓存处理:在HTTP1.0终是要使用Header里面的If-Modified-Since、Expires来作为缓存结果的标准;HTTP1.1则引入了更多的缓存控制策略。如:Entity tag、If-Unmodified-Since、If-Match、If-None-Match等更多可供选择的缓存头来控制缓存策略。
- 带宽优化及网络连接的使用:在HTTP1.0中存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传的功能;HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
- 错误通知的管理:HTTP1.1中新增了24个错误状态响应码,如:409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
- Host头处理:在HTTP1.0中认为每台服务器都绑定唯一的IP地址,因此请求消息中的URL并没有传递主机名(hostname)。但是随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址;在HTTP1.1的请求消息和响应消息都应支持host头域,且请求消息中如果没有host头域会报告一个错误(400 Bad Request)。
- 长连接:HTTP1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立连接和关闭连接的消耗和延迟;在HTTP1.1中默认开启了connection:keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。
SPDY:HTTP1.x的优化
2012年Google提出了SPDY的方案,优化了HTTP1.x的请求延迟,解决了HTTP1.x的安全性,具体如下:
- 降低延迟:针对HTTP高延迟的问题,SPDY优雅的采用了多路复用(multiplexing)。多路复用通过多个请求stream共享一个tcp连接的方式,解决了HOLblocking的问题,降低了延迟同时提高了宽带的利用率。
- 请求优先级(request prioritization):多路复用带来了一个新问题是在连接共享的基础上有可能会导致关键请求被阻塞。SPDY允许给每个request设置优先级,这样重要的请求就会优先得到响应。比如浏览器加载首页,首页的HTML内容应该优先展示,之后才是各种静态资源文件,脚本文件等加载,这样可以保证用户能第一时间看到网页的内容。
- Header压缩:前面提到HTTP1.x的Header很多时候都是重复多余的。选择合适的压缩算法可以减少报文的大小和数量。
- 基于HTTPS的加密协议传输:大大提高了传输数据的可靠性。
- 服务端推送(server push):采用了SPDY的网页,例如网页有一个style.css的请求,在客户端收到style.css数据的同时,服务端会将style.js文件推送给客户端,当客户端再次尝试获取style.js时就可以直接从缓存中获取到,不用再发送请求。
HTTP2.0:SPDY的升级版
HTTP2.0可以说是SPDY的升级版(其实原本也是基于SPDY设计的),但是HTTP2.0和SPDY仍有不同的地方,如下:
- HTTP2.0支持明文的HTTP传输,而SPDY强制使用HTTPS。
- HTTP2.0消息头的压缩算法采用HPACK;SPDY采用的是DEFLATE。
HTTP2.0和HTTP1.x相比的新特性
- 新的二进制格式(Binary Format):HTTP1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
- 多路复用(multiplexing):即连接共享,即每一个request都是用作连接共享机制的。一个request对应一个id,这样一个连接上可以有多个request,每个连接的request可以随机的混杂在一起,接收方可以根据request的id将request再归属到各自不同的服务端请求里面。
- Header压缩:如上文中所言,对前面提到过HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
- 服务端推送(server push):同SPDY一样,HTTP2.0也具有server push功能。
HTTP2.0的多路复用和HTTP1.X中的长连接复用有什么区别?
-
HTTP/1.* 一次请求-响应,建立一个连接,用完关闭;每一个请求都要建立一个连接;
-
HTTP/1.1 Pipeling解决方式为,若干个请求排队串行化单线程处理,后面的请求等待前面请求的返回才能获得执行机会,一旦有某请求超时等,后续请求只能被阻塞,毫无办法,也就是人们常说的线头阻塞;
-
HTTP/2多个请求可同时在一个连接上并行执行。某个请求任务耗时严重,不会影响到其它连接的正常执行;
服务器推送到底是什么?
服务端推送能把客户端所需要的资源伴随着index.html一起发送到客户端,省去了客户端重复请求的步骤。正因为没有发起请求,建立连接等操作,所以静态资源通过服务端推送的方式可以极大地提升速度。具体如下:
-
普通的客户端请求过程:
-
服务端推送的过程:
为什么需要头部压缩?
假定一个页面有100个资源需要加载(这个数量对于今天的Web而言还是挺保守的), 而每一次请求都有1kb的消息头(这同样也并不少见,因为Cookie和引用等东西的存在), 则至少需要多消耗100kb来获取这些消息头。HTTP2.0可以维护一个字典,差量更新HTTP头部,大大降低因头部传输产生的流量。
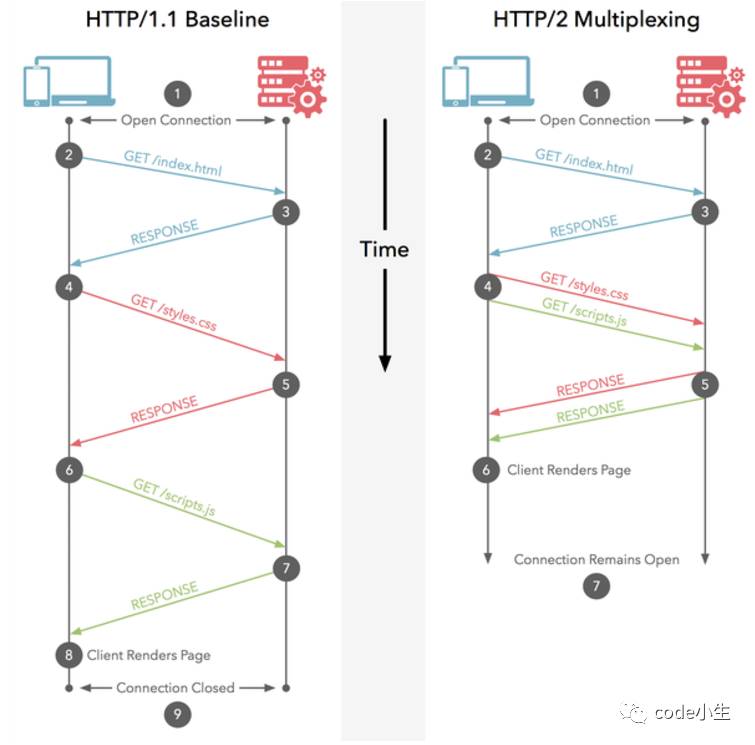
HTTP2.0多路复用有多好?
HTTP 性能优化的关键并不在于高带宽,而是低延迟。TCP 连接会随着时间进行自我「调谐」,起初会限制连接的最大速度,如果数据成功传输,会随着时间的推移提高传输的速度。这种调谐则被称为 TCP 慢启动。由于这种原因,让原本就具有突发性和短时性的 HTTP 连接变的十分低效。
HTTP/2 通过让所有数据流共用同一个连接,可以更有效地使用 TCP 连接,让高带宽也能真正的服务于 HTTP 的性能提升。
网上资料搜索总结,如果帮助请感谢作者
https://www.jianshu.com/p/be29d679cbff
https://www.nihaoshijie.com.cn/index.php/archives/630/
