
第二周、神经网络基础
2.1、二分分类
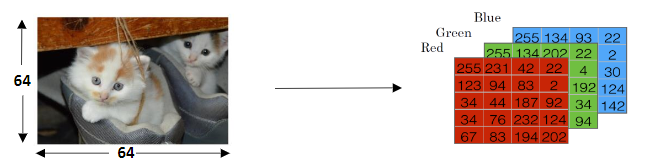
在计算机中保存一张图片,需要保存三个独立矩阵,分别对应图片中的红、绿、蓝三个颜色通道。如果输入图片是64x64像素的,就有三个64x64的矩阵,分别对应图片中的红、绿、蓝三种像素的亮度。要把这些像素亮度值(按红、绿、蓝顺序)放进一个特征向量x中,如果图片是64x64的,那么向量x的总维度是nx=64x64x3=12288。
logistic回归是一个用于二分分类的算法。在二分分类问题中,目标是训练出一个分类器:它以图片的特征向量x作为输入,预测输出的结果标签是1还是0。
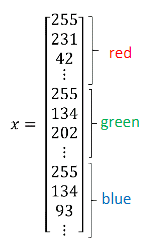
构建神经网络时,以x作为列向量,然后把(m个)训练样本(x(1),x(2),,,,x(m))作为列向量进行堆叠,组成矩阵X(nxxm矩阵,在python中为x.shape=(nx,m)),会让构建过程简单得多。
而输出标签y也是将y标签放到列中,Y=[y(1),y(2),,,,y(m)],Y是一个1xm矩阵(Y.shape=(1,m))。
2.2、logistic回归(regression)
logistics回归输出的参数(parameters):
𝑦̂=𝜎(𝑤𝑇𝑥+𝑏)
其中:x是nx维的向量,参数w和b,w(权重weight)也是nx维的向量,b是实数,𝑦̂(y hat)是输出。sigmoid函数使输出𝑦̂介于0和1之间。
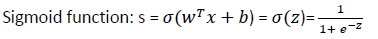
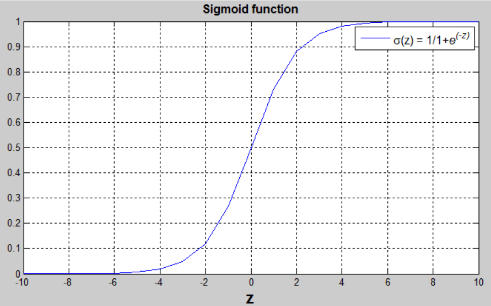
由图可知:
1.当z是一个很大的正数时,𝜎(𝑧) = 1;
2.当z是一个很小的数或很大的负数时,𝜎(𝑧) = 0;
3.当z为0时,𝜎(𝑧) = 0.5。
2.3、logistic 回归损失函数(logistic regression loss(error) function)
损失函数(loss function),又叫误差函数(error function):可以用来衡量算法的运行情况。
定义为:𝑦̂和y的差的平方或者𝑦̂和y差的平方的1/2,即L(𝑦̂,y)=(1/2)(𝑦̂-y)2。但是在 logistic回归中并不这么做。因为你会发现之后讨论的优化问题会变成非凸的,最后会得到很多个局部最优解,梯度下降法可能找不到全局最优值。
所以在logistic回归中会定义一个不同的损失函数,它起着与误差平方相似的作用,会给我们一个凸的优化问题,这样就很容易去做优化:
L(𝑦̂,y) = -(ylog𝑦̂+(1-y)log(1-𝑦̂))
当y=1时,L(𝑦̂,y) = -log𝑦̂,想要让损失函数(带负号)小,那么log𝑦̂就要大,即𝑦̂尽可能大,由上面的公式知𝑦̂最大是1。
当y=0时,L(𝑦̂,y) = -log(1-𝑦̂),想要让损失函数(带负号)小,那么log(1-𝑦̂)就要大 ,即𝑦̂尽可能小,由上面的公式知𝑦̂最小是0。
损失函数是在单个训练样本中定义的,它衡量了在单个训练样本上的表现。
成本函数(logistic regression cost function):它衡量的是在全体训练样本上的表现。成本函数衡量了参数w和b在训练集上的效果。
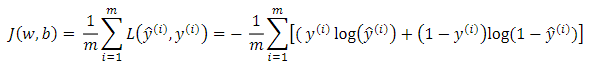
即所有训练样本的损失函数和。所以在训练logistic回归模型时,我们要找到合适的参数w和b使成本函数J尽可能小。
2.4、梯度下降法(gradient descent)
我们想找到使得成本函数J(w,b)尽可能小的w和b。来看看梯度下降法:
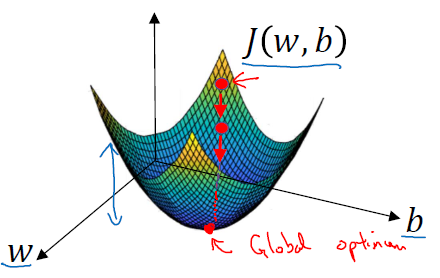
这个图中的横轴表示空间参数w和b,在实践中,w可以是更高维的,但是为了绘图方便,我们让w是一个实数,b也是一个实数。成本函数J(w,b)是在水平轴w和b上的曲面,曲面的高度表示了J(w,b)在某一点的值。我们所想要做的就是找到这样的w和b使其对应的成本函数J值是最小值。可以看到成本函数J是一个凸函数,凸函数这性质是我们使用logistic回归的这个特定成本函数J的重要原因之一。
为了找到更好地参数值,我们要做的就是用某初始值初始化w和b,用小红点表示。对于logistic回归而言,几乎是任意的初始化方法都有效,通常用0来初始化。但是对于logistic回归,我们通常不这么做,但因为函数是凸的,无论从哪里初始化,都应该到达同一点或大致相同的点。
梯度下降法所做的就是从初始点开始朝最陡的下坡方向走一步,在梯度下降一步后,或许在那里停下来,因为它正试图沿着最快下降的方法往下走,这是梯度下降的一次迭代。一直迭代到(或接近)全局最优解那里。
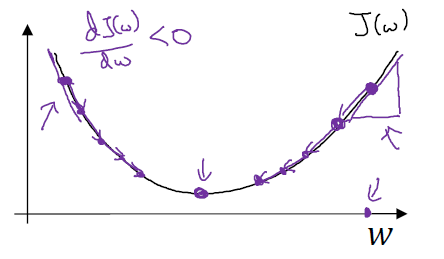
为了方便画,先忽略掉b。仅仅是用一维曲线来代替多维曲线。梯度下降法将重复执行以下更新操作:更新w的值
使用:=表示更新w,即w:=w - αdJ(w)/dw,α表示学习率(学习率可以控制每一次迭代或者梯度下降法中的步长),dJ(w)/dw是导数,这是对参数w的更新或者变化量。代码中这样写w:=w-αdw。假设w点在右边,导数是函数在这个点的斜率(高除以宽),右边的导数是正的,新的w值等于w自身减去学习率乘导数,由于导数是正的,即从w中减去这个乘积,则点向左走一步。同理,如果w点在左边,新的w值则是w自身减去学习率乘以导数,由于导数是负的,即从w中加上这个乘积,则点向右走一步。
无论你初始化的位置在哪里(左边还是右边),梯度下降法会朝着全局最小值方向移动。
在logistic回归中,你的成本函数是一个含有w和b的函数,这时通过w:=w - αdJ(w)/dw来更新w,通过b:=b - αdJ(b)/db来更新b,实际上由于有两个参数,应该用偏导数符号。
