行业知识图谱的构建及应用
【说在前面】本人博客新手一枚,象牙塔的老白,职业场的小白。以下内容仅为个人见解,欢迎批评指正,不喜勿喷![认真看图][认真看图]
【补充说明】如果你对知识图谱感兴趣,欢迎先浏览我的另一篇随笔:基于图模型的智能推荐算法学习笔记
一、知识图谱的机遇与挑战
分享一下肖仰华教授的报告。报告深度剖析知识图谱的发展进程,系统整理知识图谱上半场的主要成果,分析知识图谱下半场的挑战与机遇,以期为各行业的认知智能实践带来有益的参考。
▌知识图谱上半场
1. 传统知识工程

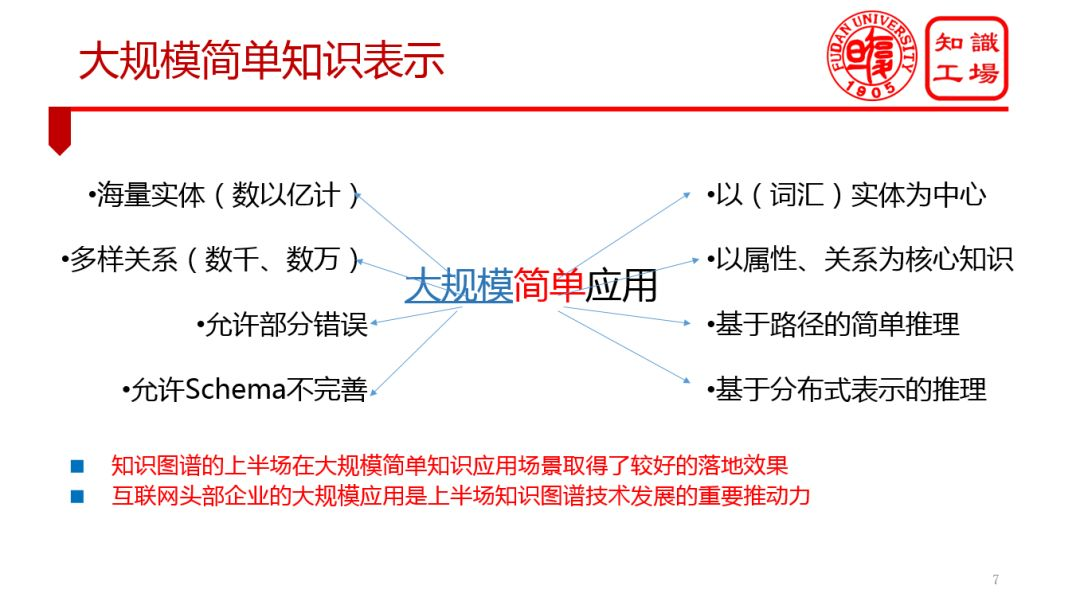
2. 大数据知识工程
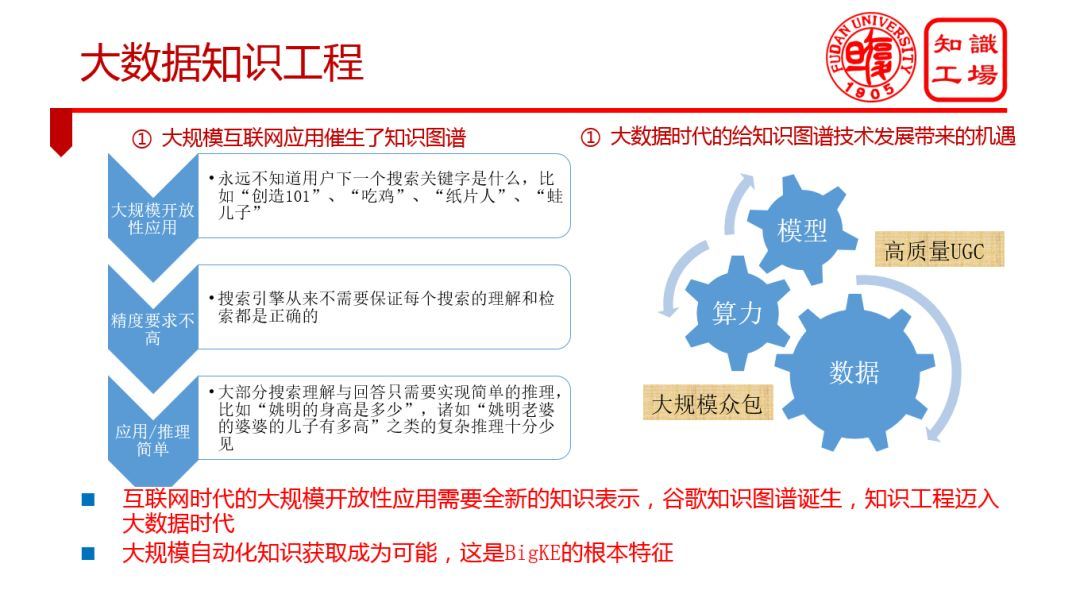
① 大规模简单知识表示
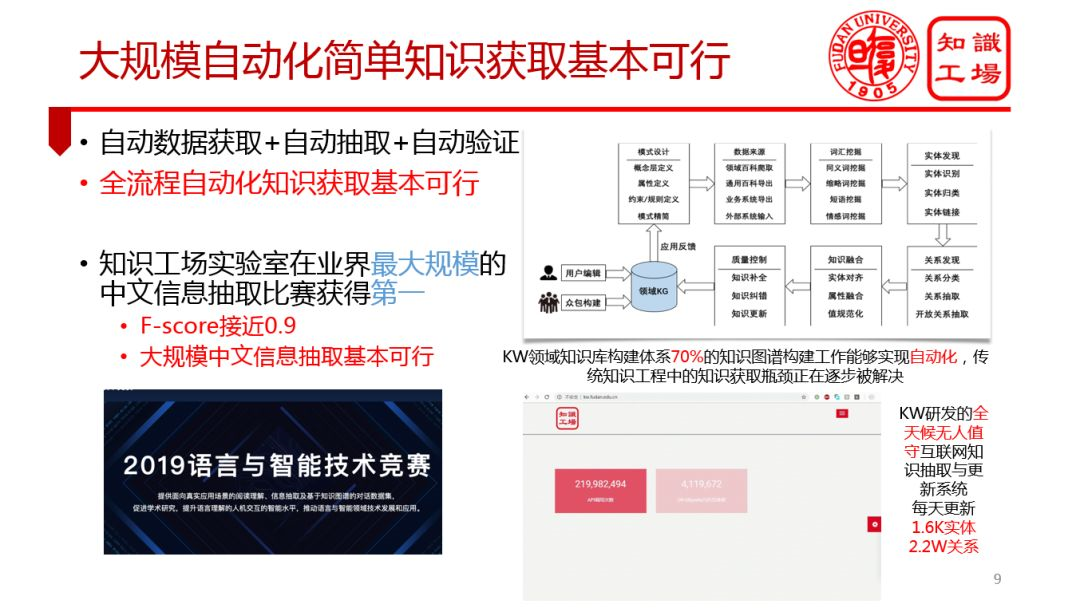
② 知识获取

③ 基于知识图谱的简单推理

3. 大数据知识工程到底解决了哪些问题?
① 语言表达鸿沟

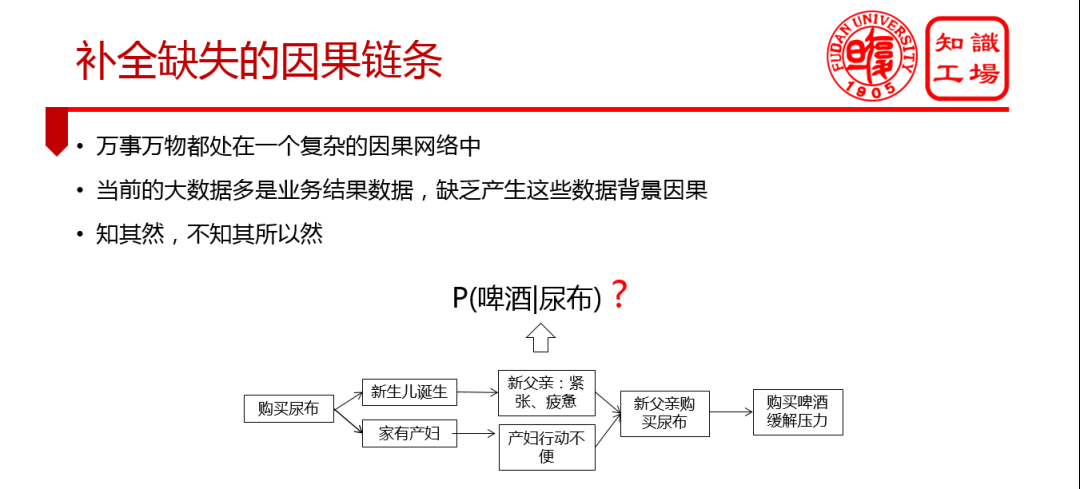
② 缺失的因果链条
③ 碎片化数据的关联与融合
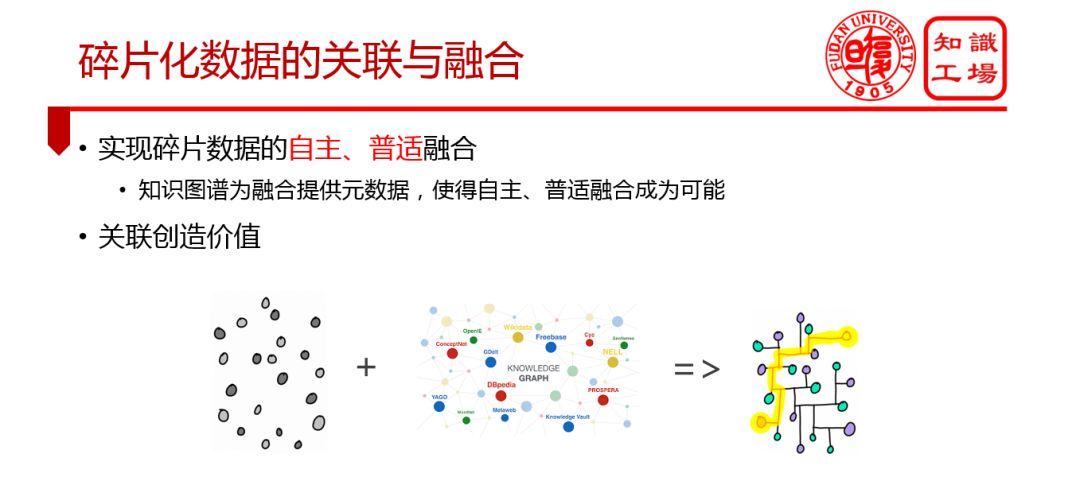
④ 深化行业数据的理解与洞察
⑤ 显著提升了机器的自然语言理解水平

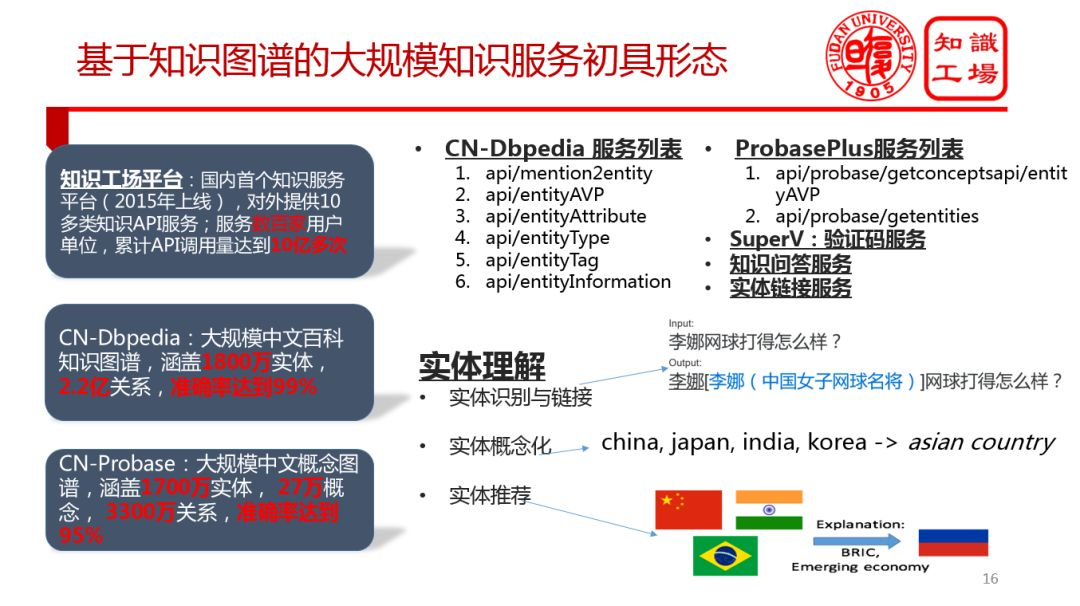
⑥ 基于知识图谱的大规模知识服务
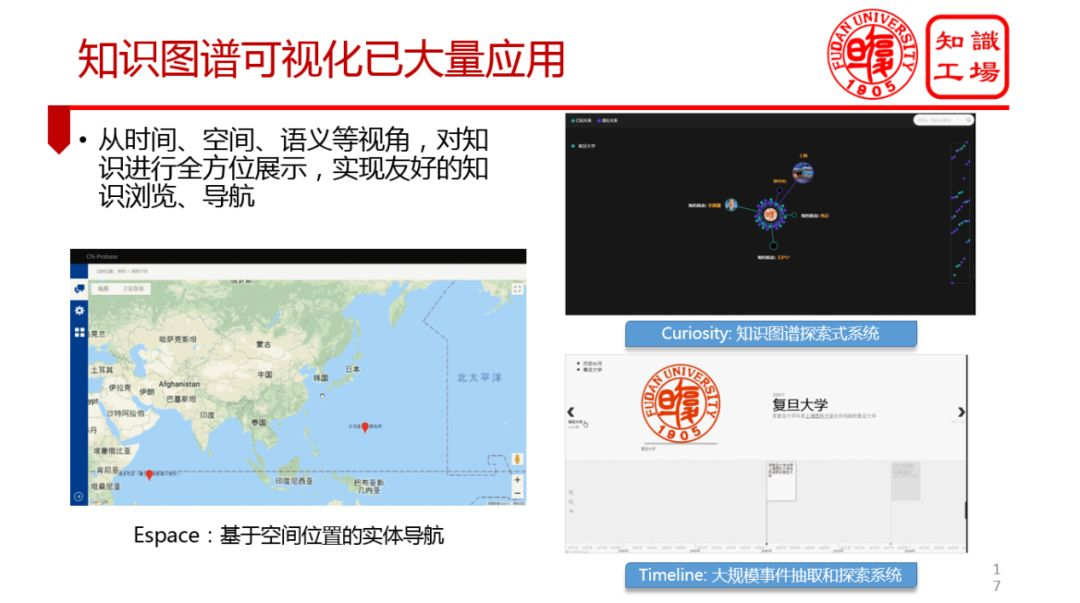
⑦ 知识图谱可视化已大量应用
⑧ 大数据知识工程理论体系日趋完善

▌知识图谱下半场
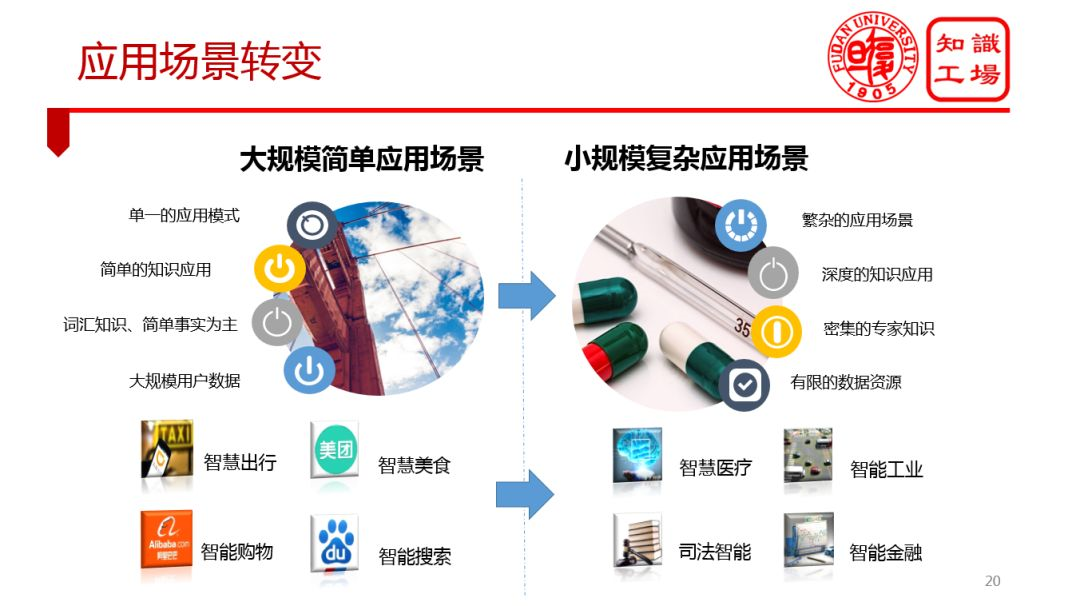
1. 应用场景转变
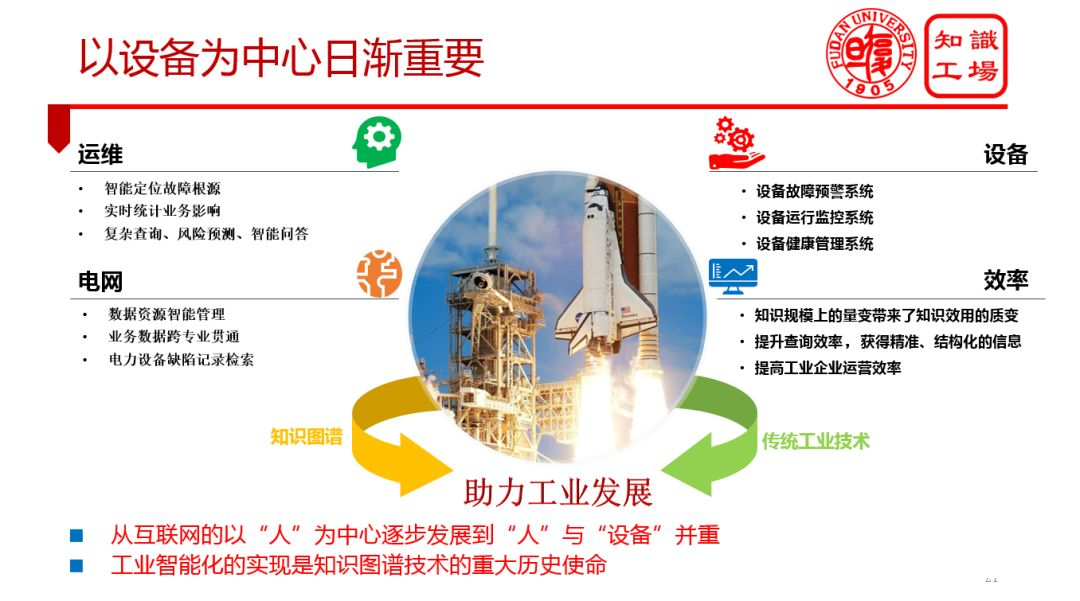
2. 新的趋势
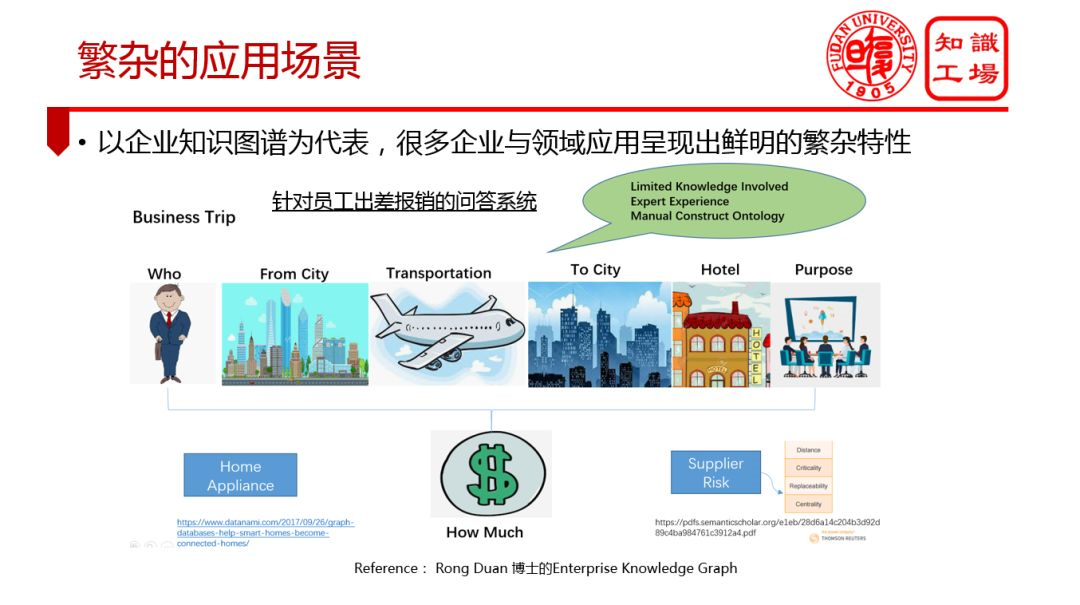
① 繁杂的应用场景
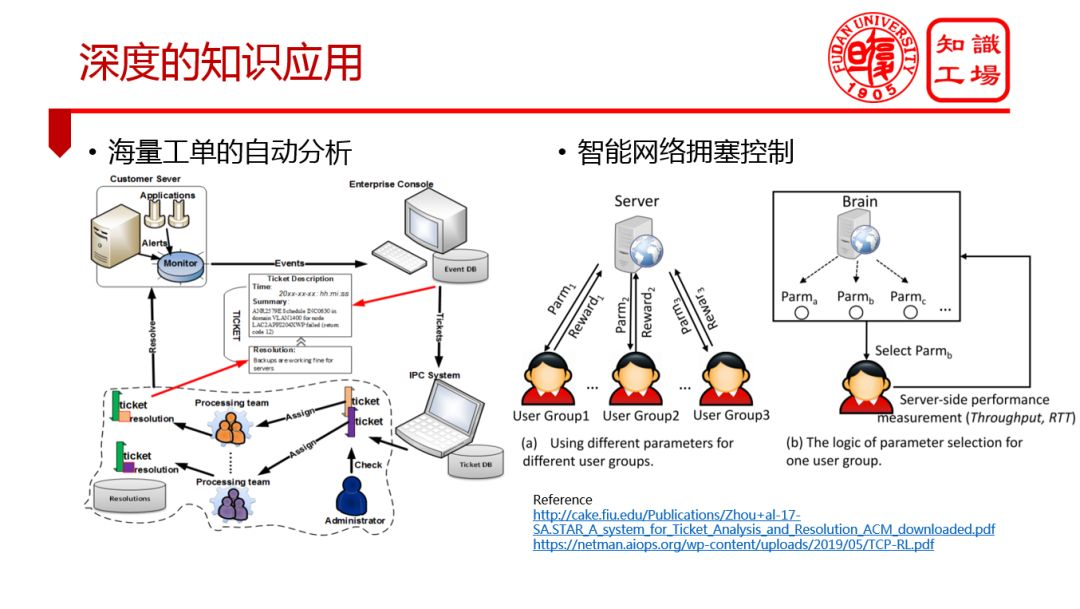
② 深度的知识应用
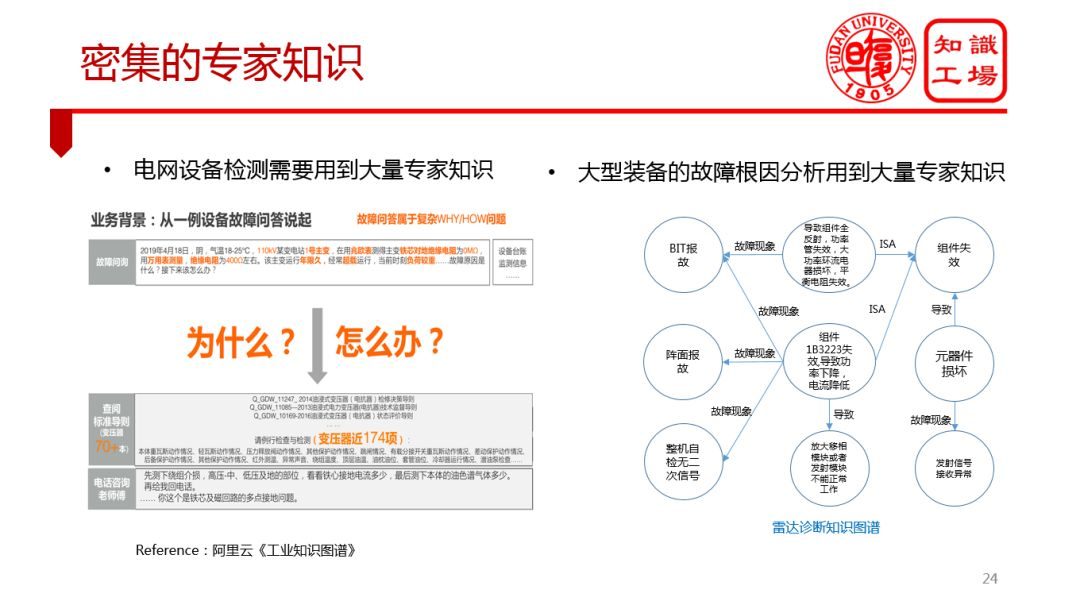
③ 密集的专家知识
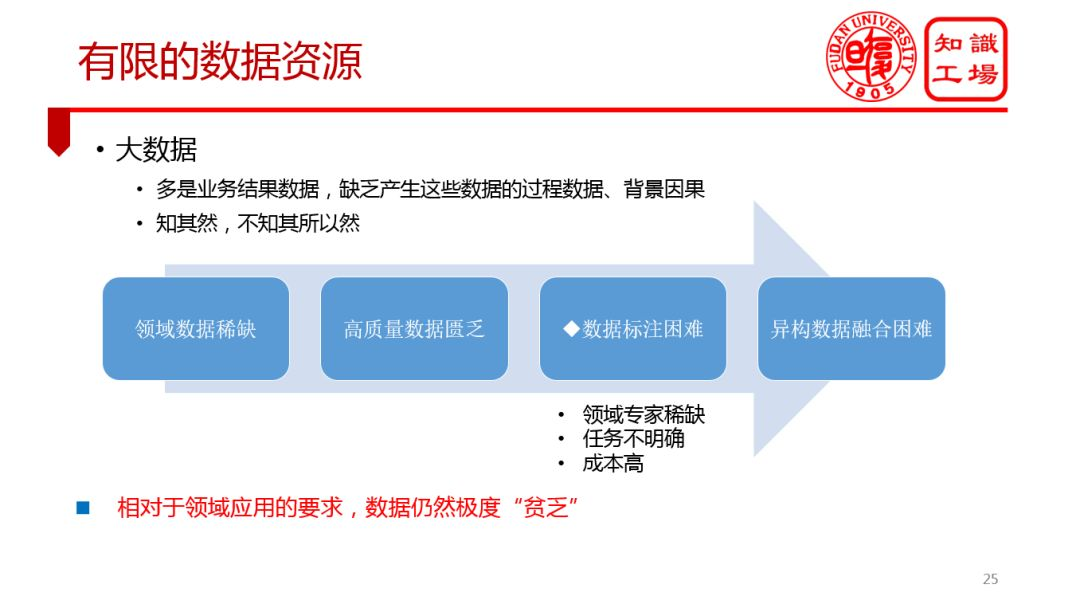
④ 有限的数据资源
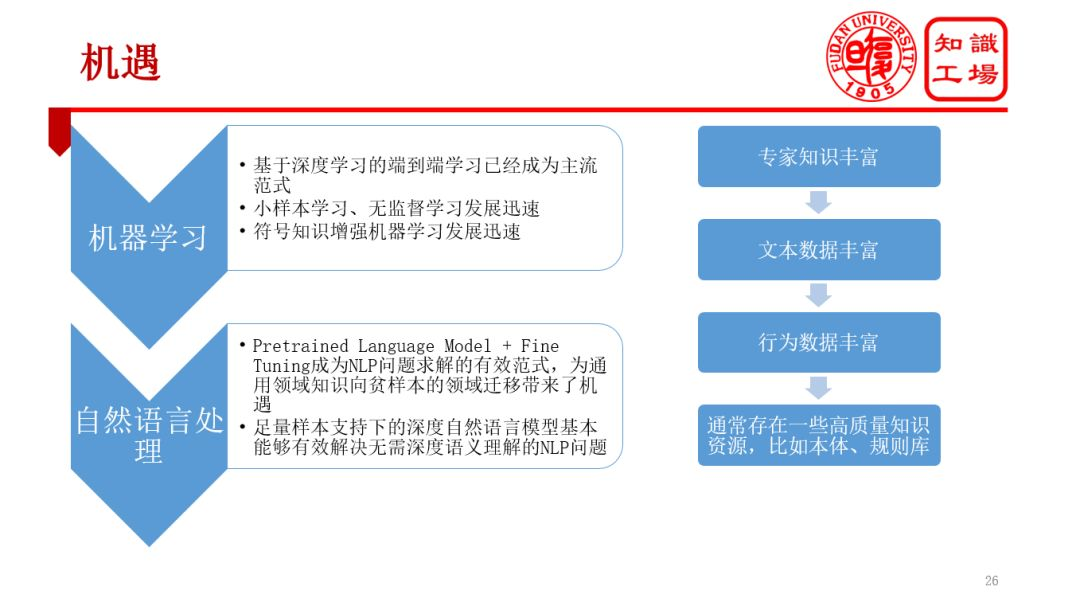
3. 机遇
4. 应对策略
知识表示方面:
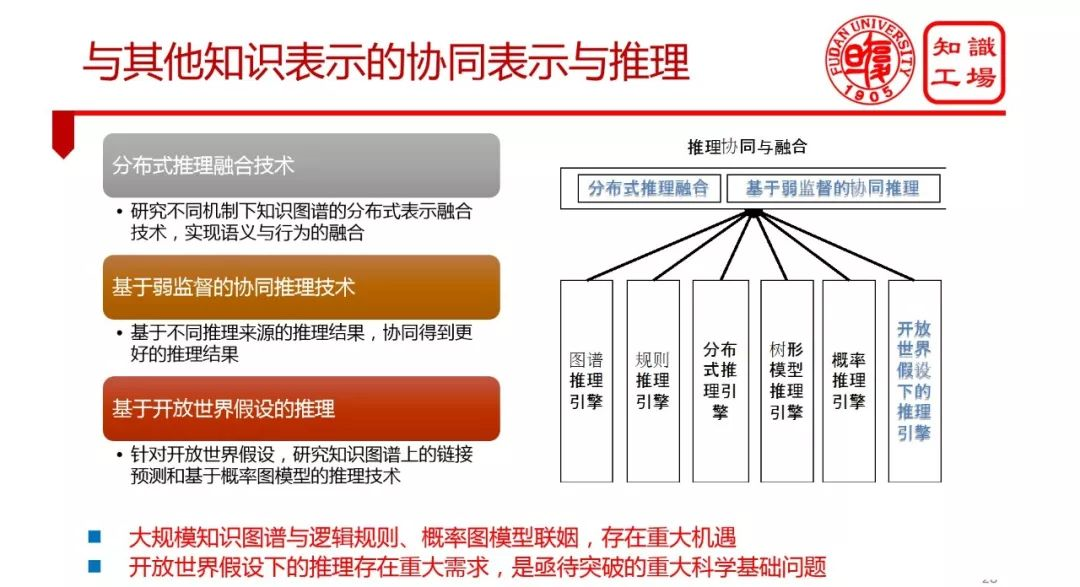
① 与其他知识表示的协同表示与推理
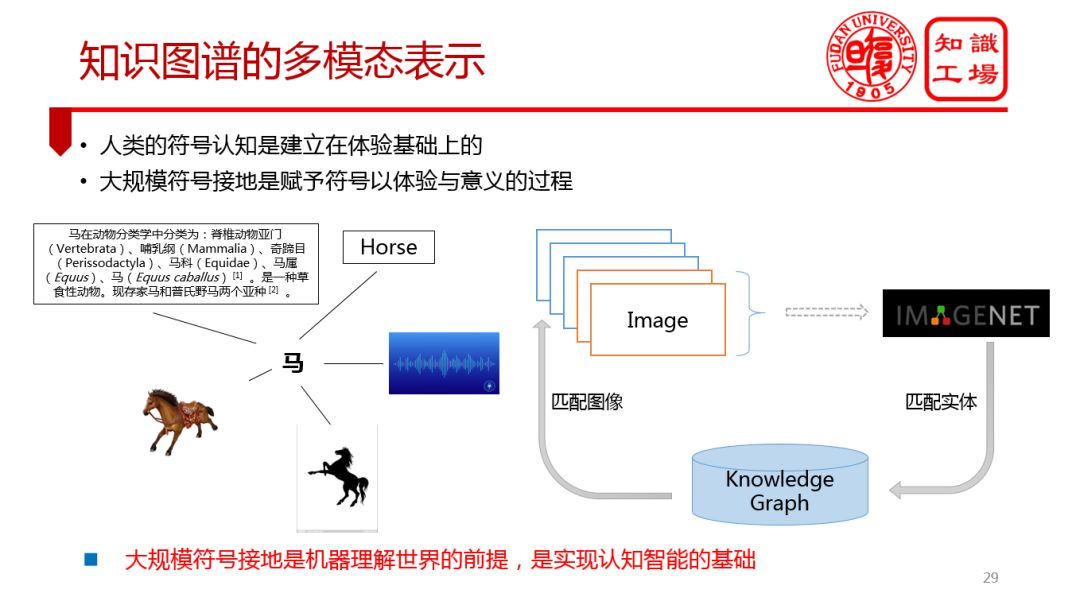
② 知识图谱的多模态表示
③ 知识图谱的个性化表示
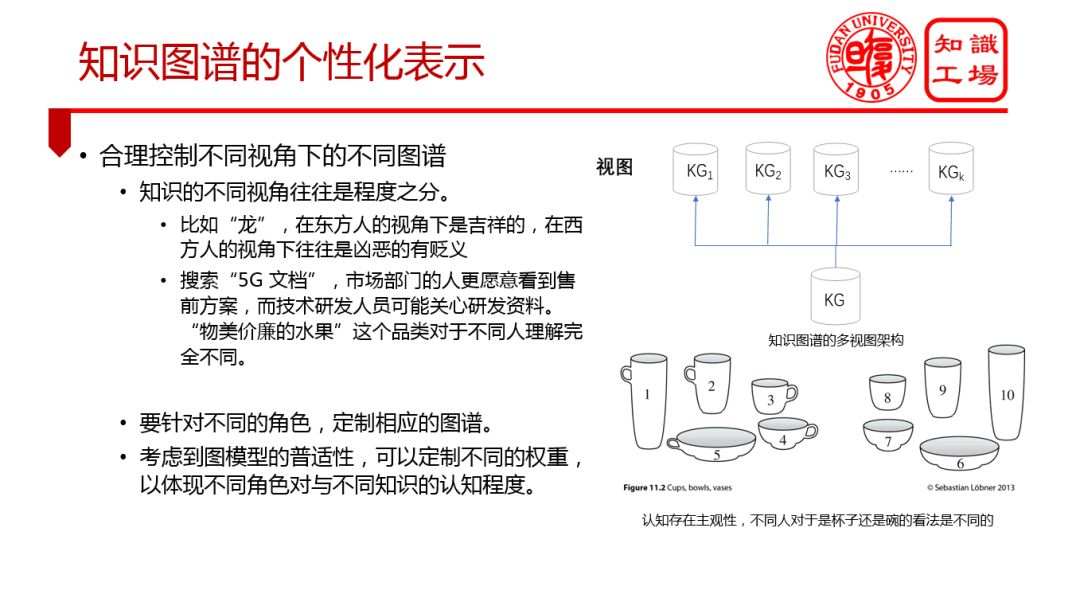
知识获取方面:
① 发展低成本知识获取方法

② 注重多粒度知识获取
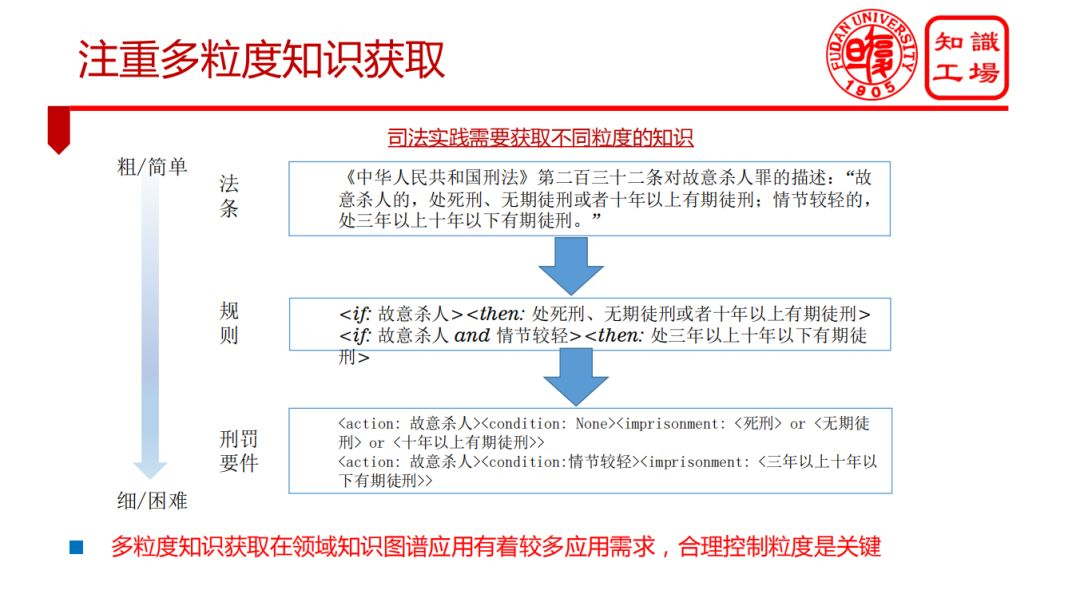
③ 发展大规模常识知识获取
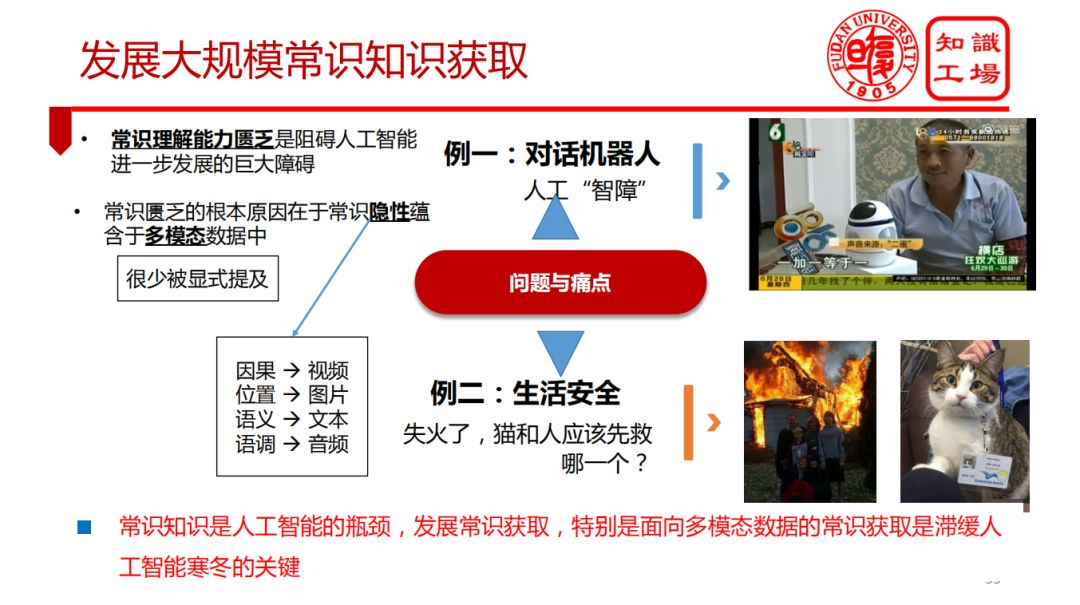
④ 复杂知识获取机制与方法


知识应用方面:
① 知识图谱应用透明化
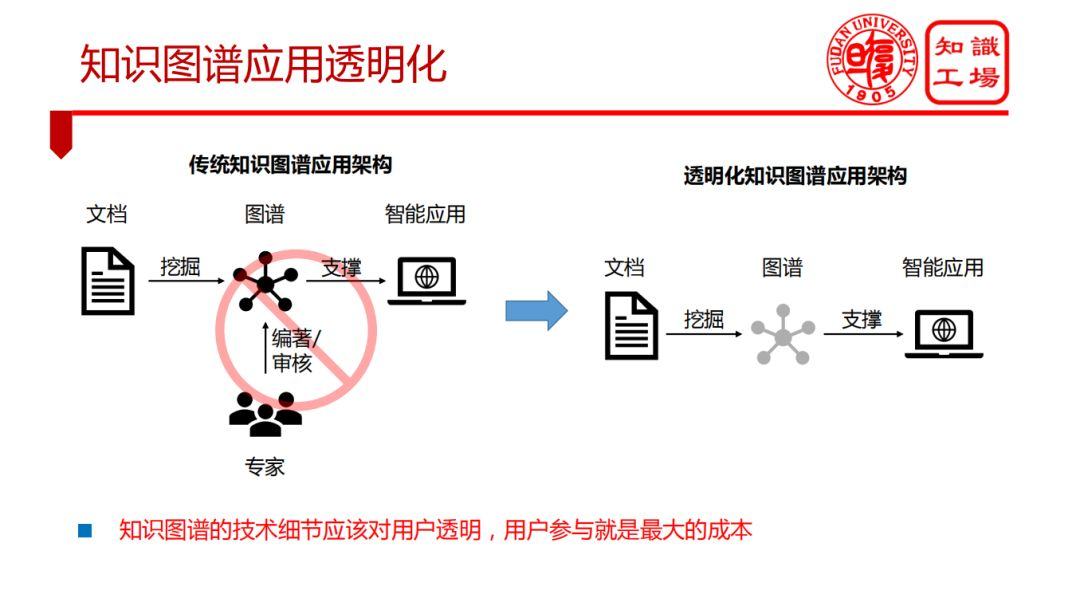
② 基于知识图谱的可解释人工智能

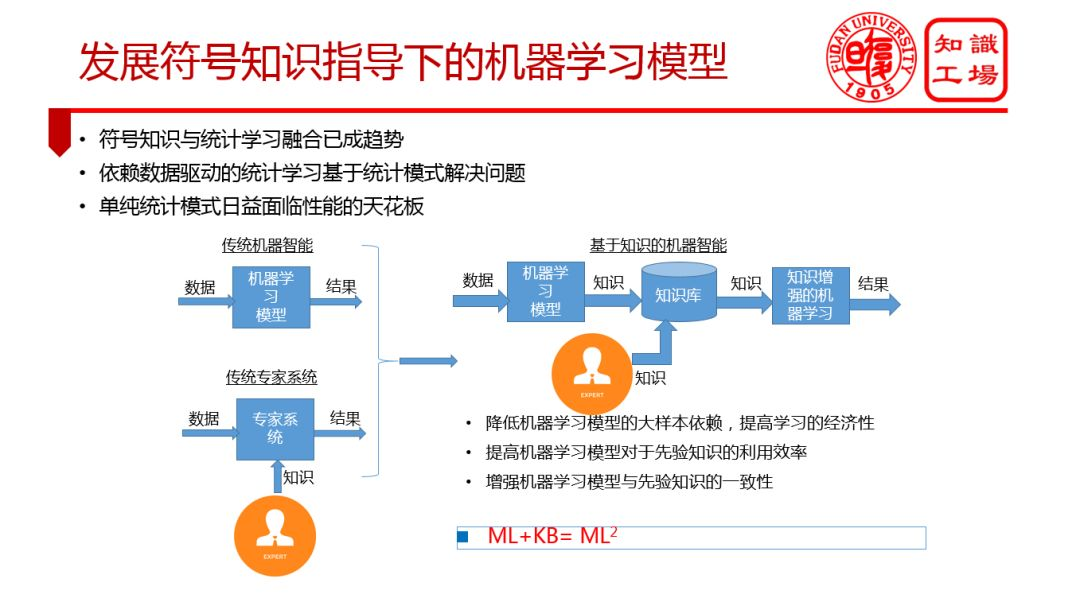
③ 发展符号知识指导下的机器学习模型
▌总结
二、行业知识图谱的构建与应用
分享一下PlantData的文章:行业知识图谱构建与应用。
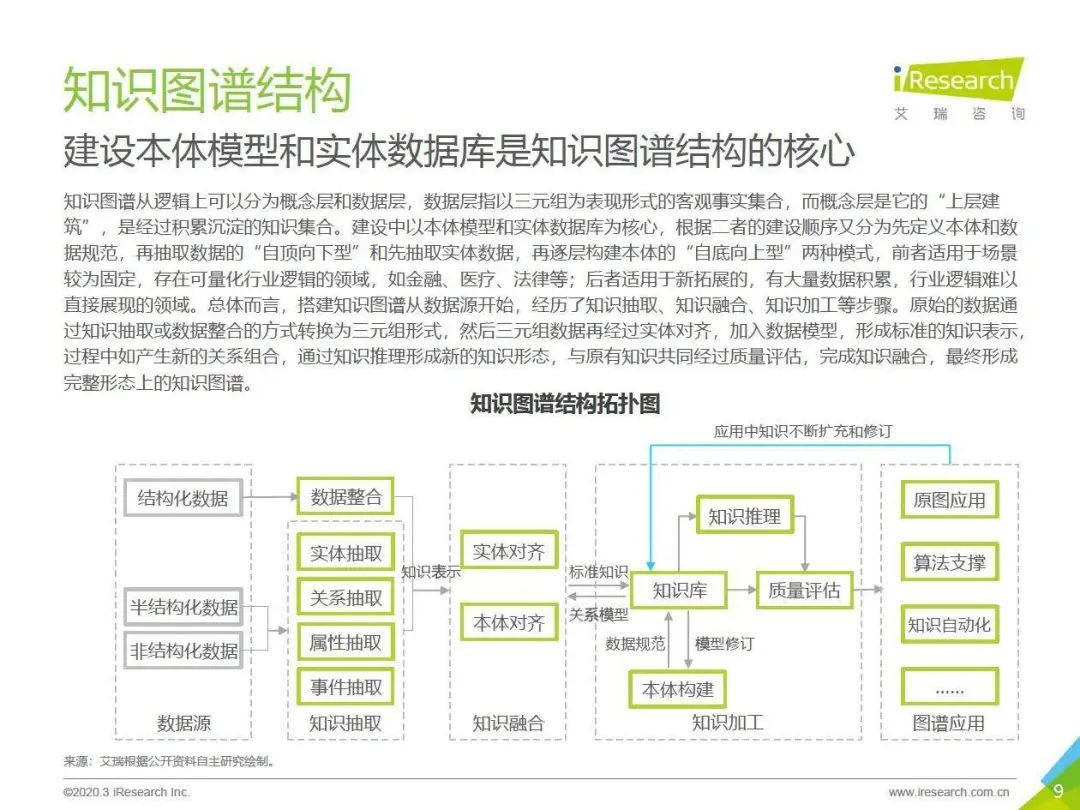
1. 知识图谱整体结构描述
知识图谱结构拓扑图如图所示:
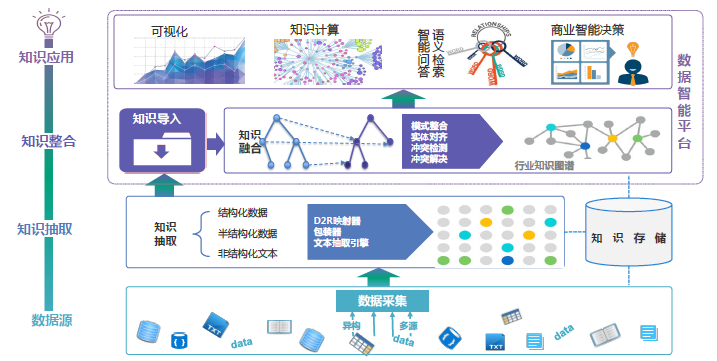
企业全量数据应用挑战及应对策略:
(1)多源异构数据难以融合
使用知识图谱(本体)对各类数据建模,基于可动态变化的数据模型(概念-实体-属性-关系),实现统一建模。
(2)数据模式动态变迁困难
使用可支持数据模式动态变化的知识图谱的数据存储。
(3)非结构化数据计算机难以理解
利用信息抽取技术。
(4)数据使用专业程度过高
(5)分散的数据难以统一消费利用
在知识融合的基础上,基于语义检索、知识问答、图计算、推理、可视化等技术,提供数据检索/分析/利用,统一平台。
2. 知识建模
(1)以实体为主体目标,实现对不同来源的数据进行映射与合并。(实体抽取与合并)
(2)利用属性来表示不同数据源中针对实体的描述,形成对实体的全方位描述。(属性映射与归并)
(3)利用关系来描述各类抽象建模成实体的数据之间的关联关系,从而支持关联分析。(关系抽取)
(4)通过实体链接技术,实现围绕实体的多种类型数据的关联存储。(实体链接)
(5)使用事件机制描述客观世界中动态发展,体现事件与实体间的关联;并利用时序描述事件的发展状况。(动态事件描述)
知识建模工具:Protégé(本体编辑器,较局限)
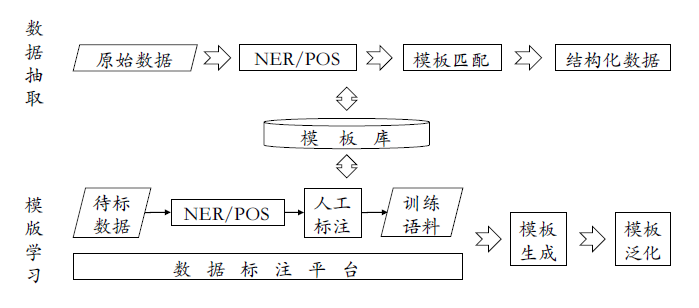
3. 知识抽取
知识抽取的主要策略如图所示(针对结构化、半结构化、非结构化数据的处理方式不同):
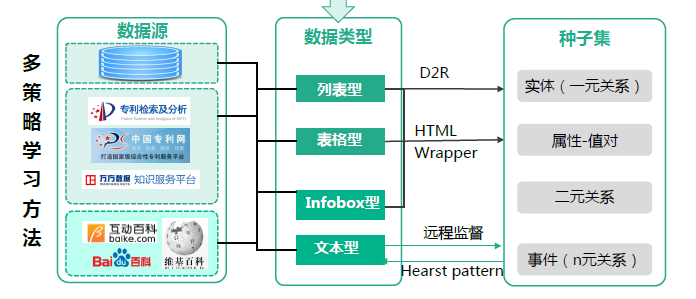

知识抽取中的文本信息抽取,主要包括:实体识别、关系抽取、事件抽取、概念抽取。信息抽取主要有两大类工具:
- OpenIE:面向开放领域抽取信息、关系类型事先未知、基于语言学模式进行抽取、规模大、精度相对较低。典型工具:ReVerb、TextRunner(准确率低,实用性不强,一般不用)
- CloseIE:面向特定领域抽取信息、预先定义好抽取的关系类型、基于领域专业知识抽取、规模小、精度比较高。典型工具:DeepDive(主要是针对实体识别,缺乏对关系/事件/概念的抽取)
非结构化文本数据的处理包括以下步骤:
- 分词、词性标注、语法解析、依存分析
- NER命名实体识别、实体链接
- 关系抽取、事件抽取
其中,事件抽取可以分为预定义事件抽取和开放域事件抽取,行业知识图谱中主要为预定义事件抽取。采用模式匹配方法,包括三个步骤:
- 准备事件触发词表
- 候选事件抽取:寻找含有触发词的句子
- 事件元素识别:根据事件模版抽取相应的元素
还有基于机器学习模型的抽取:SVM、逻辑回归、CRF、LSTM等:
补充说明,关于知识表示,欢迎先浏览我的另一篇随笔:基于图模型的智能推荐算法学习笔记,这里不再赘述。
- 基于数理逻辑的知识表示:RDF(资源描述框架)、OWL(RDF Schema 的扩展)、SPARQL(RDF查询语言)
- 基于向量空间学习的分布式知识表示:Rescal、NTN、TransE(Embedding)
4. 知识融合
(1)数据层融合:实体链接技术
即等同性判断:给定不同数据源中的实体,判断其是否指向同一个真实世界实体(实体属性与关系的合并)。
- 基于实体知识的链接
- 基于篇章主题的链接
- 融合实体知识和篇章主题的链接
实体链接工具:Wikipedia Miner、DBpedia Spotlight等,大部分都是针对百科类的知识库工作的,基本不支持中文的处理。
(2)语义描述层融合:Schema Mapping
- 概念上下位关系合并
- 概念的属性定义合并
当然还有一些别的需要考虑,例如多源知识融合、冲突检测与解决、跨语言融合、知识验证等。
例如,通过人机交互接口对错误信息进行人工纠正,并以此作为种子案例,通过强化学习加强模型的识别精度和鲁棒性。
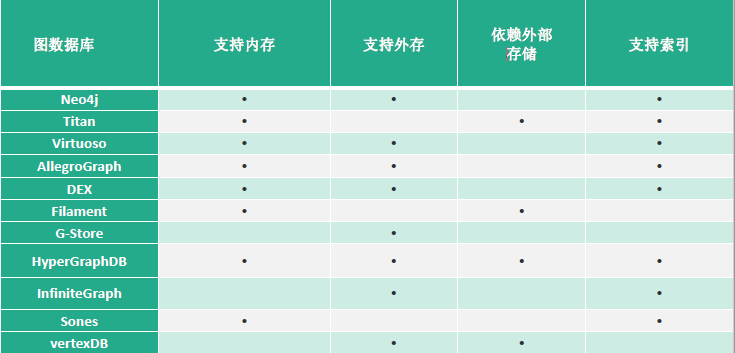
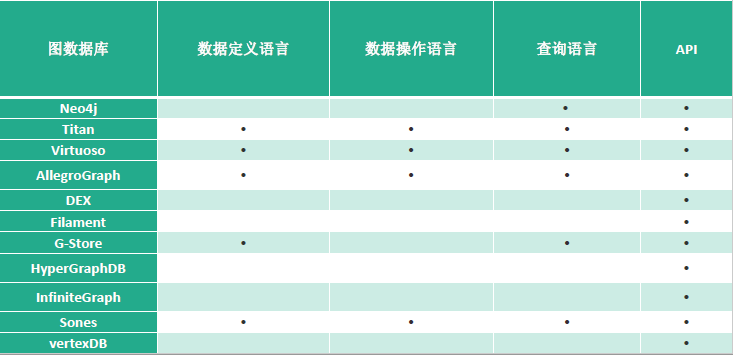
5. 知识存储
知识图谱是基于图的数据结构,其存储方式主要有两种方式:RDF存储和图数据库。
- 基于关系数据库的存储
- 基于原生图的存储
- 基于混合存储
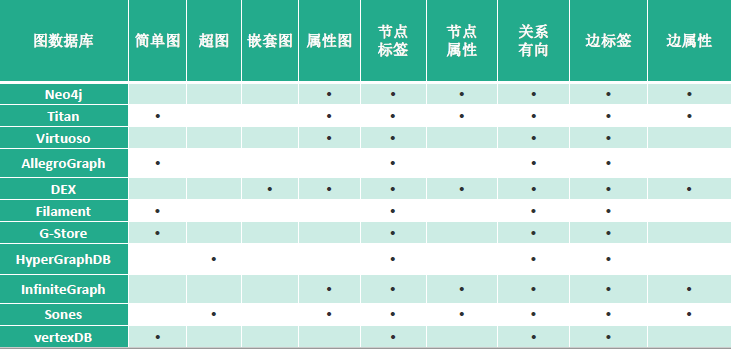
下面展示各大图数据库的对比:



6. 知识计算
(1)基于图论的相关算法:
- 图遍历:广度优先遍历、深度优先遍历
- 最短路径查询: Dijkstra(迪杰斯特拉算法)、Floyd(弗洛伊德算法)
- 路径探寻:给定两个或多个节点,发现它们之间的关联关系
- 权威节点分析:PageRank算法
- 族群发现:最大流算法
- 相似节点发现:基于节点属性、关系的相似度算法
(2)本体推理:使用本体推理进行新知识发现或冲突检测。
- 基于表运算及改进的方法:FaCT++、Racer、Pellet Hermit等
- 基于一阶查询重写的方法(Ontology based data access,基于本体的数据访问)
- 基于产生式规则的算法(如rete):Jena 、Sesame、OWLIM等
- 基于Datalog转换的方法:KAON、RDFox等
- 回答集程序Answer set programming
本体知识推理工具:RDFox。
(3)基于规则的推理:使用规则引擎,编写相应的业务规则,通过推理辅助业务决策。
- 在知识图谱基础知识的基础上,专家依据行业应用的业务特征进行规则的定义。
- 引擎基于基础知识与所定义的规则,执行推理过程给出推理结果。
基于规则推理工具:Drools 规则定义。
7. 知识应用
智能问答(基于语义解析的方法+基于信息检索的方法)、语义搜索(基于实体链接)、可视化决策支持(D3.js、ECharts)等。
举例金融业的基于知识图谱的风险管理:
- 知识获取部分:需要内部+外部,需要特别注意完整性原则(信息不对称是很多风险的根源)
- 知识融合部分:需要内部+外部,需要特别注意准确性原则(本体一致性、数据标准统一性、本地表现状态一致性)
- 知识计算部分:需要特别注意适用性原则
- 知识应用部分:人机交互接口
- 贷款全流程:有效控制贷款准入、提升贷款决策有效性
- 审批额度时:防止多头授信、规避关联企业互相担保
- 贷后监控中:检测资金流入关联企业、参与民间借贷
- 保金过程中:识别企业的关联资产、弥补损失
8. 知识图谱的自动构建
可构建的图谱:例如公司图谱、产品图谱、⼈物图谱、智能预警等。在行业应用中使用知识图谱,大致有如下几种方式:
- 可以使用现有的套装工具,在现有套装工具的基础上进行扩充:LOD2、Stardog
- 可以使用各生命周期过程中的相应工具进行组合使用,针对性开发或扩展生命周期中特定工具
如果您对异常检测感兴趣,欢迎浏览我的另一篇博客:异常检测算法演变及学习笔记
如果您对智能推荐感兴趣,欢迎浏览我的另一篇博客:智能推荐算法演变及学习笔记 、CTR预估模型演变及学习笔记
如果您对时间序列分析感兴趣,欢迎浏览我的另一篇博客:时间序列分析中预测类问题下的建模方案 、深度学习中的序列模型演变及学习笔记
如果您对数据挖掘感兴趣,欢迎浏览我的另一篇博客:数据挖掘比赛/项目全流程介绍 、机器学习中的聚类算法演变及学习笔记
如果您对人工智能算法感兴趣,欢迎浏览我的另一篇博客:人工智能新手入门学习路线和学习资源合集(含AI综述/python/机器学习/深度学习/tensorflow)、人工智能领域常用的开源框架和库(含机器学习/深度学习/强化学习/知识图谱/图神经网络)
如果你是计算机专业的应届毕业生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的应届生,你如何准备求职面试?
如果你是计算机专业的本科生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的本科生,你可以选择学习什么?
如果你是计算机专业的研究生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的研究生,你可以选择学习什么?
如果你对金融科技感兴趣,欢迎浏览我的另一篇博客:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
之后博主将持续分享各大算法的学习思路和学习笔记:hello world: 我的博客写作思路

