深度学习中的序列模型演变及学习笔记(含RNN/LSTM/GRU/Seq2Seq/Attention机制)
【说在前面】本人博客新手一枚,象牙塔的老白,职业场的小白。以下内容仅为个人见解,欢迎批评指正,不喜勿喷![认真看图][认真看图]
【补充说明】深度学习中的序列模型已经广泛应用于自然语言处理(例如机器翻译等)、语音识别、序列生成、序列分析等众多领域!
【再说一句】本文主要介绍深度学习中序列模型的演变路径,和往常一样,不会详细介绍各算法的具体实现,望理解!
一、循环神经网络RNN
1. RNN标准结构
传统神经网络的前一个输入和后一个输入是完全没有关系的,不能处理序列信息(即前一个输入和后一个输入是有关系的)。
循环神经网络RNN解决了以上问题,整体结构如图所示:
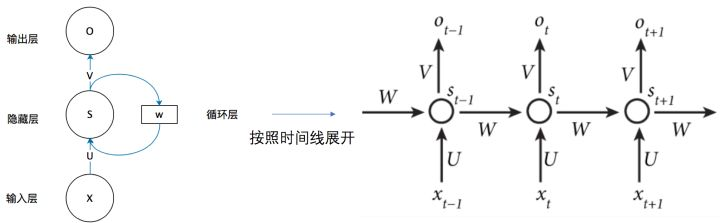
2. RNN系列结构
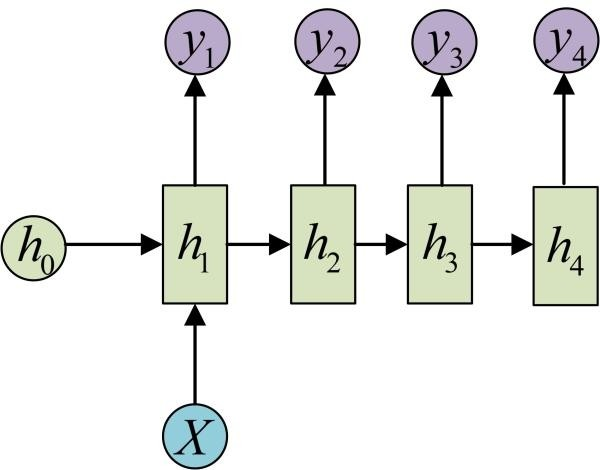
多对一:例如情感分析,需要多个时间步长的输入,但是只需要单个输出(即实现分类)。整体结构如图所示:

一对多:例如音乐生成,只需要单个输入(即输入类别),但是需要输出整个序列。整体结构如图所示:
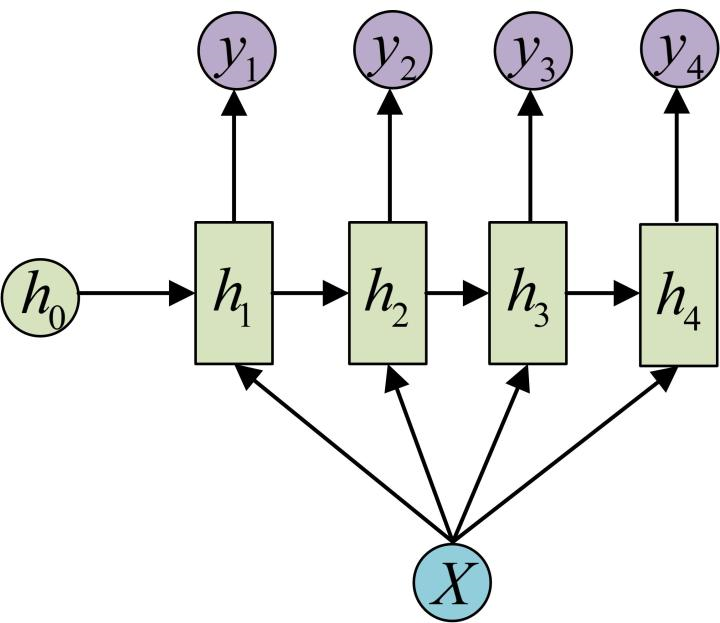
多对多:例如实时分类,输入序列与输出序列的长度是一样的。整体结构如图所示:
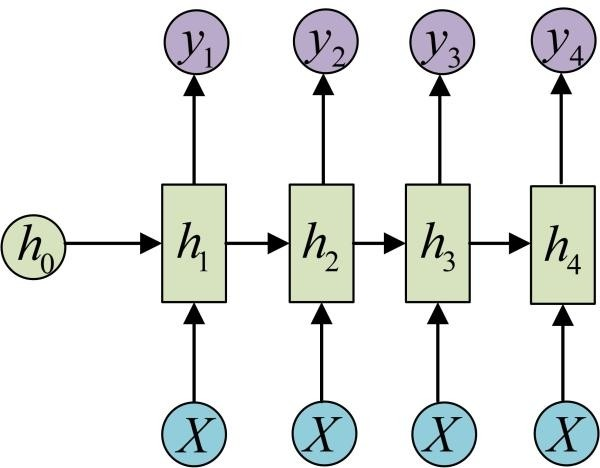
多对多:例如机器翻译,输入序列与输出序列的长度是不一样的。整体结构如图所示:

二、长短期记忆网络LSTM
LSTM是RNN的一种变体,RNN由于梯度消失只有短期记忆,而LSTM网络通过精妙的门控制,一定程度上缓解了梯度消失的问题。


三、GRU
GRU是LSTM的一种变体,也是为了解决梯度消失(即长期记忆问题)而提出来的。相较于LSTM,GRU的网络结构更加简单,且效果很好。
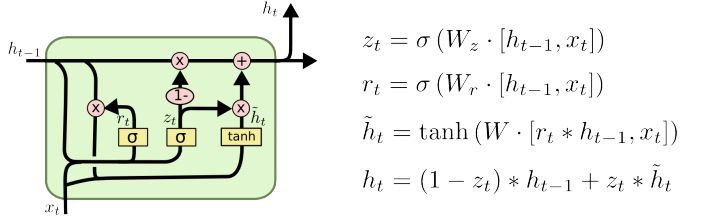
四、RNN/LSTM/GRU的变体结构
1. 双向循环神经网络
例如命名实体识别:判断句子中Teddy是否是人名,如果只从前面几个词是无法得知Teddy是否是人名,如果能有后面的信息就很好判断了。
双向循环神经网络中的网络单元可以是RNN、LSTM和GRU,均适用这种变体结构。
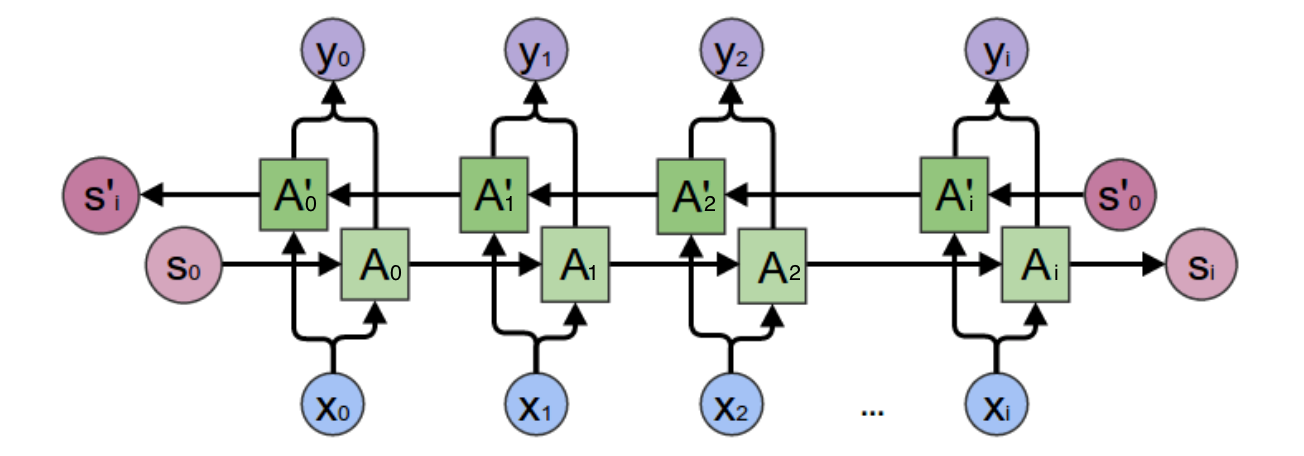
2. 深层循环神经网络
顾名思义,就是多个循环神经网络的堆叠,循环神经网络可以采用RNN、LSTM和GRU,均适用这种变体结构。

3. Seq2Seq架构:非常火热
又叫Encoder-Decoder模型,适用于输入与输出个数不一样相等的情况(即多对多的循环神经网络,适用于机器翻译等场景)。
其中,Encoder编码器和Decoder解码器可以使用RNN、LSTM和GRU,均适用这种变体结构。
同时,这种结构也可以与双向、深层的变体结构同时使用,不冲突的。
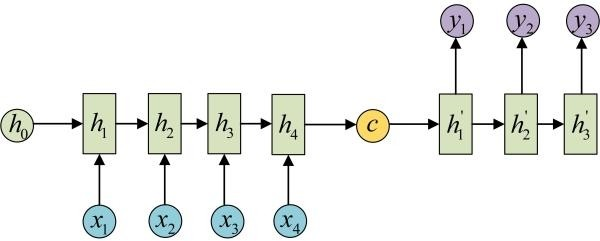

这里多提一句,例如给图像添加描述这样的应用场景,图中对应的描述为“一只猫站在椅子上”,同样可以采用Encoder-Decoder模型。
五、注意力机制
1. Seq2Seq + Attention机制介绍
需要注意到,LSTM、GRU、双向变体结构、深层变体结构和Seq2Seq变体结构,只能说一定程度上缓解了梯度消失问题。
提出问题:在做机器翻译时,专家学者们发现,在Seq2Seq结构中,Encoder把所有的输入序列都编码成一个统一的语义向量context,然后再由Decoder解码。其中,context自然也就成了限制模型性能的瓶颈,当要翻译的句子较长时,一个 context 可能存不下那么多信息。同时,只使用编码器的最后一个隐藏层状态,似乎不是很合理。
解决方案:因此,引入了Attention机制(将有限的认知资源集中到最重要的地方)。在生成 Target 序列的每个词时,用到的中间语义向量 context 是 Source 序列通过Encoder的隐藏层的加权和,而不是只用Encoder最后一个时刻的输出作为context,这样就能保证在解码不同词的时候,Source 序列对现在解码词的贡献是不一样的。例如,Decoder 在解码"machine"时,"机"和"器"提供的权重要更大一些,同样,在解码"learning"时,"学"和"习"提供的权重相应的会更大一些。
实现步骤:(1)衡量编码中第 j 阶段的隐含层状态和解码时第 i 阶段的相关性(有很多种打分方式,这里不细讲);(2)通过相关性的打分为编码中的不同阶段分配不同的权重;(3)解码中第 i 阶段输入的语义向量context就来自于编码中不同阶段的隐含层状态的加权和。

补充说明一下,衡量相关性的打分方式主要包括以下几种,具体不展开了:



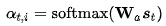

2. 层次注意力机制Hierarchical Attention
能够反映文档的层次结构。模型在单词和句子级别分别设计了两个注意力机制,这样做能够在构建文档表示时区别地对待这些内容。

3. 自注意力机制Self-Attention:只有一个Seq
是关联单个序列中不同位置的注意力机制,从而计算序列的交互表示。已被证明在很多领域十分有效,例如机器阅读、图像描述生成等。
以机器阅读为例,当前单词为红色,蓝色阴影的大小表示激活程度,自注意力机制使得能够学习当前单词和句子前一部分词之间的相关性:

补充说明,以图像描述生成为例,注意力权重的可视化清楚地表明了模型关注的图像的哪些区域以便输出某个单词:

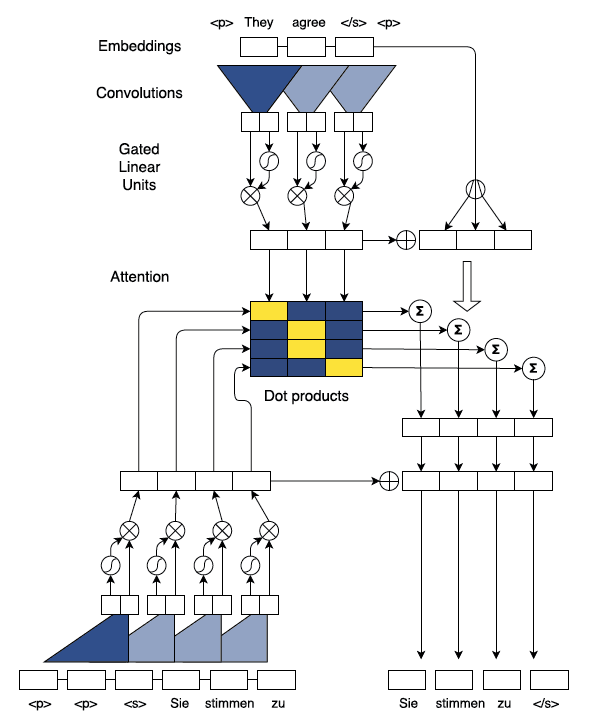
4. Fairseq:基于卷积神经网络的Seq2Seq + Attention机制
Facebook人工智能实验室提出基于卷积神经网络的Seq2Seq架构,将RNN替换为带有门控单元的CNN(相较于RNN,CNN工作不依赖于上一时间步的结果,所以可以做到最大程度的并行计算,提升训练速度),提升效果的同时大幅加快了模型训练速度。
5. Transformer:使用self-attention代替原有的RNN及CNN
以上Attention model虽然解决了输入seq仅有一个context vector的缺点,但仍存在一些问题:
- context vector计算的是输入seq、目标seq间的关联,却忽略了输入seq中文字间的关联、目标seq中文字间的关联性。
- Attention model中使用的RNN无法平行化处理,导致训练时间长,使用的CNN实际上是透过大量的layer去解决局部信息的问题。
Google提出一种叫做”transformer”的模型,透过self-attention、multi-head的概念去解决上述缺点,完全舍弃了RNN、CNN的构架。

值得一提的是,Google后续提出了BERT模型,在11个任务中取得了最好的效果,是深度学习在nlp领域又一个里程碑式的工作。
6. Memory-based Attention
在 NLP 的一些任务上,比如问答匹配任务,答案往往与问题间接相关。因此,基本的注意力技术就显得很无力了,这时候就体现了Memory-based Attention的强大之处。例如可以通过迭代内存更新(也称为多跳)来模拟时间推理过程,以逐步引导注意到答案的正确位置。
7. Soft/Hard Attention
简单说就是Soft Attention打分之后分配的权重取值在0到1之间,而Hard Attention取值为0或者1。
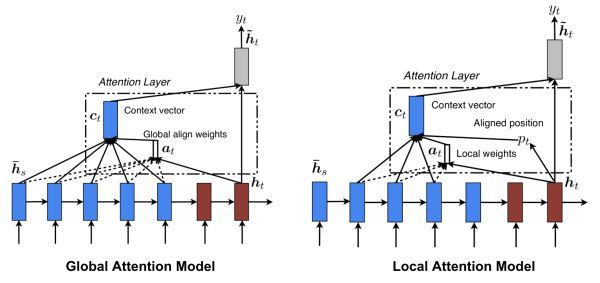
8. Global/Local Attention
这个也很好理解,就是采用全局或者局部的注意力机制。
六、应用
1. 自然语言处理
例如机器翻译、问答系统、文本分类、情绪分析、命名实体识别、创作乐曲等。
2. 图像处理
例如多媒体描述、局部图像补全、通过低分辨率的图像还原高分辨率图像等。
3. 智能推荐
例如用于用户行为分析,即将注意力权重分配给用户的交互项目,以更有效地捕捉长期和短期的兴趣。
4. 其他
本文参考大佬:https://github.com/yuquanle/Attention-Mechanisms-paper/blob/master/Attention-mechanisms-paper.md
如果你对智能推荐感兴趣,欢迎先浏览我的另几篇随笔:智能推荐算法演变及学习笔记
如果您对数据挖掘感兴趣,欢迎浏览我的另几篇博客:数据挖掘比赛/项目全流程介绍
如果您对人工智能算法感兴趣,欢迎浏览我的另一篇博客:人工智能新手入门学习路线和学习资源合集(含AI综述/python/机器学习/深度学习/tensorflow)
如果你是计算机专业的应届毕业生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的应届生,你如何准备求职面试?
如果你是计算机专业的本科生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的本科生,你可以选择学习什么?
如果你是计算机专业的研究生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的研究生,你可以选择学习什么?
如果你对金融科技感兴趣,欢迎浏览我的另一篇博客:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
之后博主将持续分享各大算法的学习思路和学习笔记:hello world: 我的博客写作思路

 浙公网安备 33010602011771号
浙公网安备 33010602011771号