智能推荐算法演变及学习笔记(三):CTR预估模型综述
【说在前面】本人博客新手一枚,象牙塔的老白,职业场的小白。以下内容仅为个人见解,欢迎批评指正,不喜勿喷![握手][握手]
【再啰嗦一下】如果你对智能推荐感兴趣,欢迎先浏览我的另一篇随笔:智能推荐算法演变及学习笔记
【最后再说一下】本文只对智能推荐算法中的CTR预估模型演变进行具体介绍!
一、传统CTR预估模型演变
1. LR
即逻辑回归。LR模型先求得各特征的加权和,再添加sigmoid函数。
- 使用各特征的加权和,是为了考虑不同特征的重要程度
- 使用sigmoid函数,是为了将值映射到 [0, 1] 区间
LR模型的优点在于:
- 易于并行化、模型简单、训练开销小
- 可解释性强、可拓展性强
LR模型的缺点在于:
- 只使用单一特征,无法利用高维信息,表达能力有限
- 特征工程需要耗费大量的精力
2. POLY2
POLY2对所有特征进行“暴力”组合(即两两交叉),并对所有的特征组合赋予了权重。
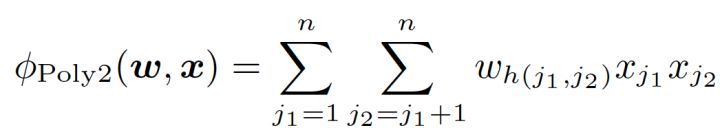
一定程度上解决了LR缺乏特征组合的问题,但是“暴力行为”带来了一些问题:
- 特征维度爆炸,特征数据过于稀疏,特征权重不易收敛
3. FM
相比于POLY2,FM为每个特征学习了一个隐权重向量 w。在特征交叉时,使用两个特征隐向量w的内积作为交叉特征的权重。

将原先n^2级别的权重数量降低到n*k(k为隐向量w的维度,n>>k),极大降低了训练开销。
4. FFM
在FM模型基础上,FFM模型引入了Field-aware。在特征交叉时,使用特征在对方特征域上的隐向量内积作为交叉特征的权重。
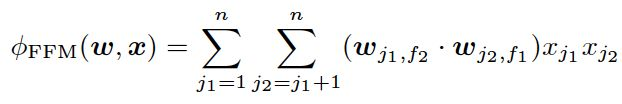
FFM模型的权重数量共n*k*f个,计算复杂度上升到k*n^2,远远大于FM模型的k*n。
5. GBDT/xgboost/lightgbm
直接使用机器学习算法中的集成学习方法。
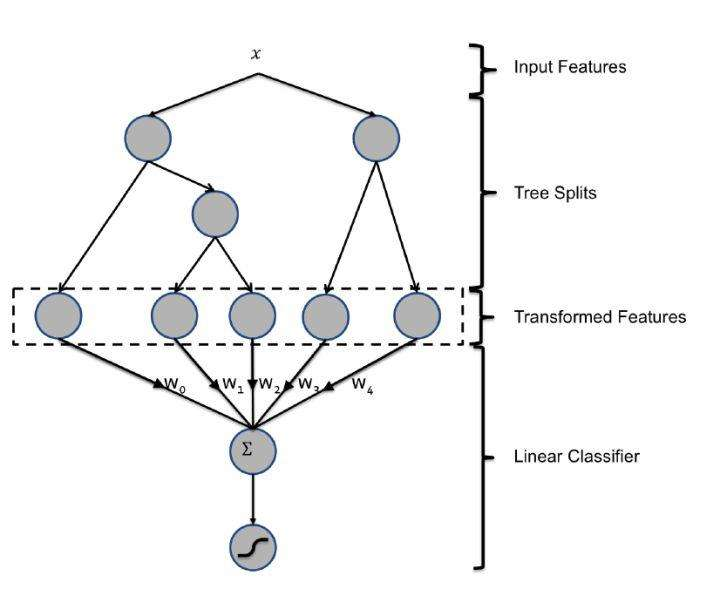
6. GBDT+LR/FM/FFM
利用GBDT自动进行特征筛选和组合,进而生成新的离散特征向量,再把该特征向量当作LR模型的输入。
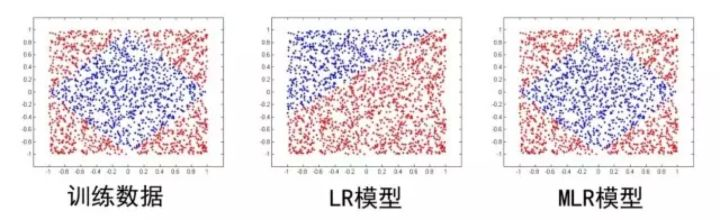
7. MLR
在LR的基础上采用分而治之的思路,先对样本进行分片,再在样本分片中应用LR进行CTR预估。
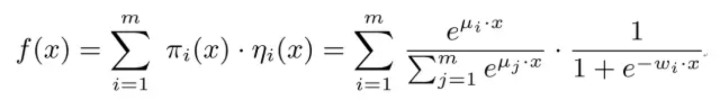
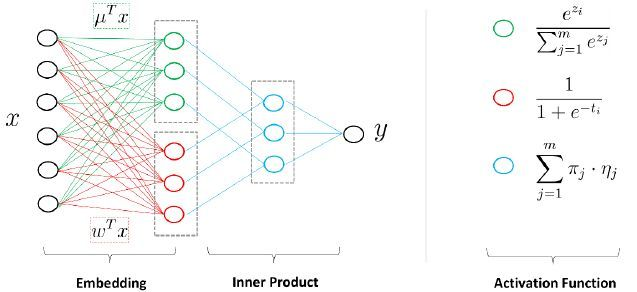
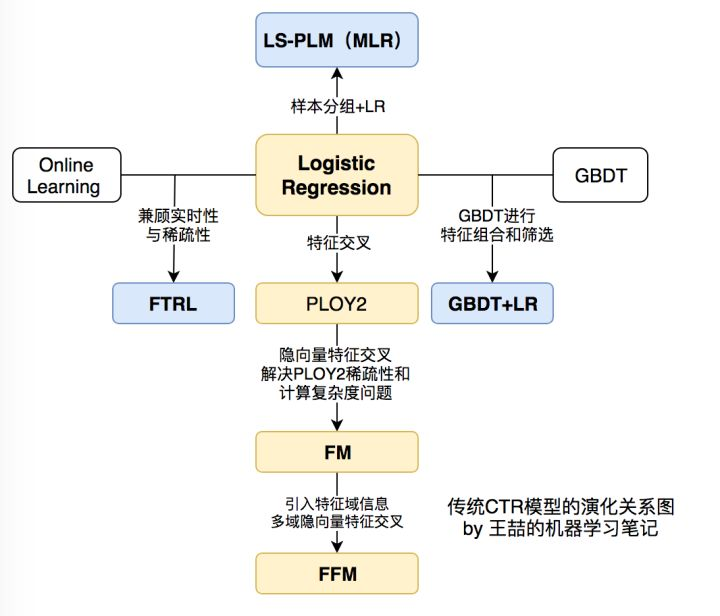
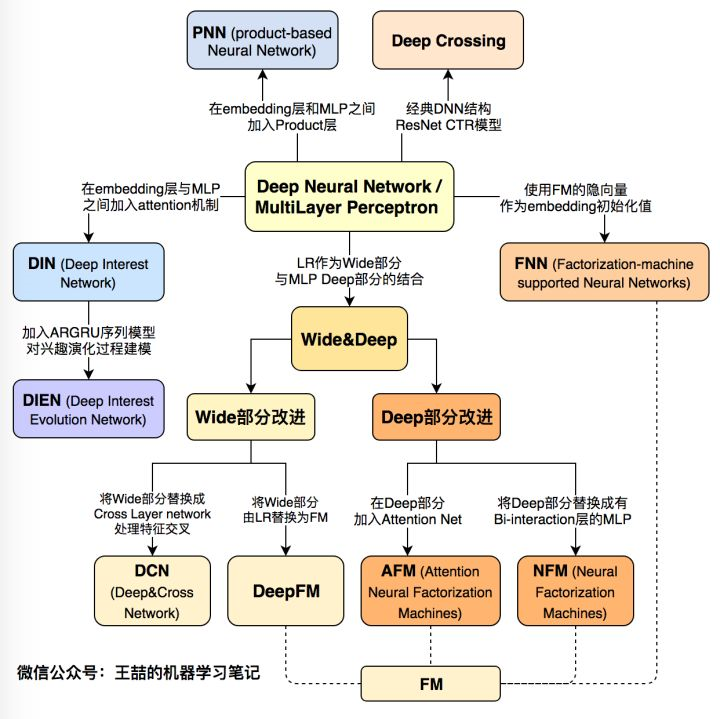
以上1-7部分可以总结为传统的CTR预估模型演变,这里分享一下大佬的关系图谱:
二、引入深度学习的CTR预估模型演变
1. Deep Crossing
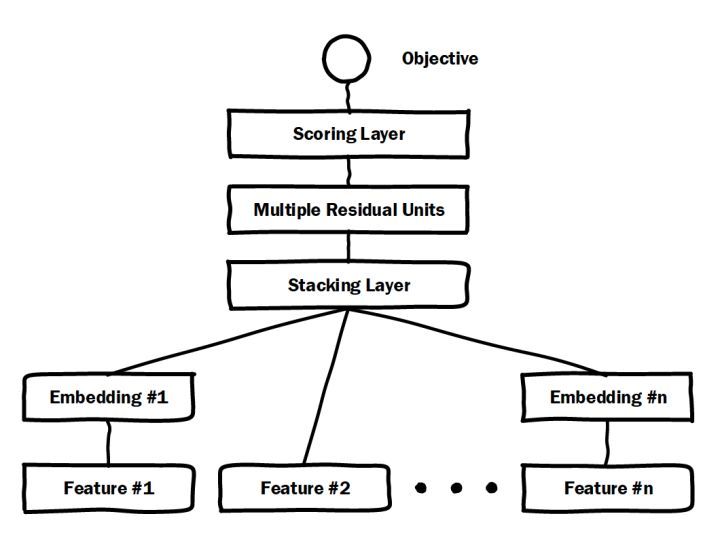
通过加入embedding层将稀疏特征转化为低维稠密特征,用stacking层连接分段的特征向量,再通过多层神经网络完成特征组合/转换。
跟经典DNN有所不同的是,Deep crossing采用的multilayer perceptron是由残差网络组成的。
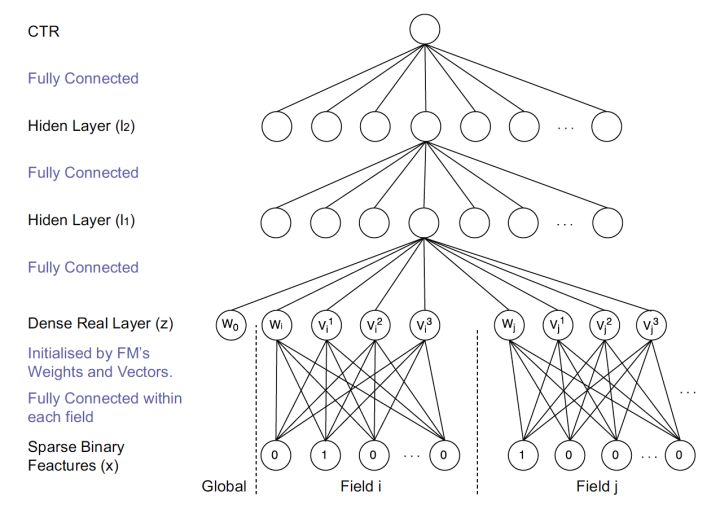
2. FNN
相比于Deep Crossing,FNN使用FM的隐层向量作为user和item的Embedding,从而避免了完全从随机状态训练Embedding。
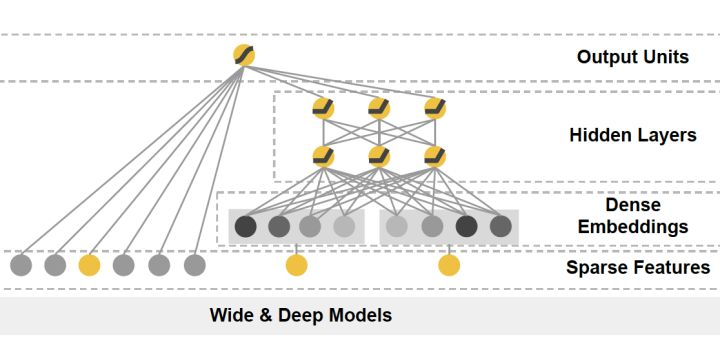
3. Wide & Deep
把单输入层的Wide部分和经过多层感知机的Deep部分连接起来,一起输入最终的输出层。
- wide部分:高维特征+特征组合的LR
- deep部分:deep learning
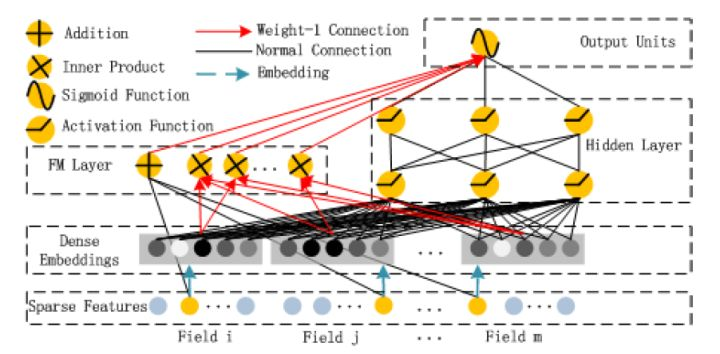
4. DeepFM
DeepFM对Wide & Deep的改进之处在于,用FM替换掉了原来的Wide部分,加强了浅层网络部分特征组合的能力。
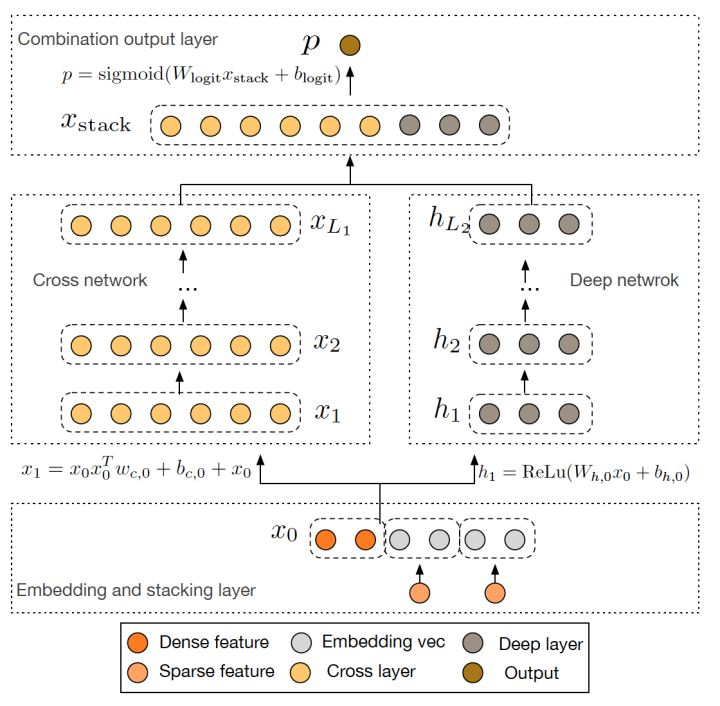
5. Deep & Cross (DCN)
使用Cross网络替代了原来的Wide部分。Cross网络使用多层cross layer对输入向量进行特征交叉,增加特征之间的交互。
6. NFM
相对于DeepFM和DCN对于Wide&Deep Wide部分的改进,NFM可以看作是对Deep部分的改进。
NFM用一个带Bi-interaction Pooling层的DNN替换了FM的特征交叉部分。
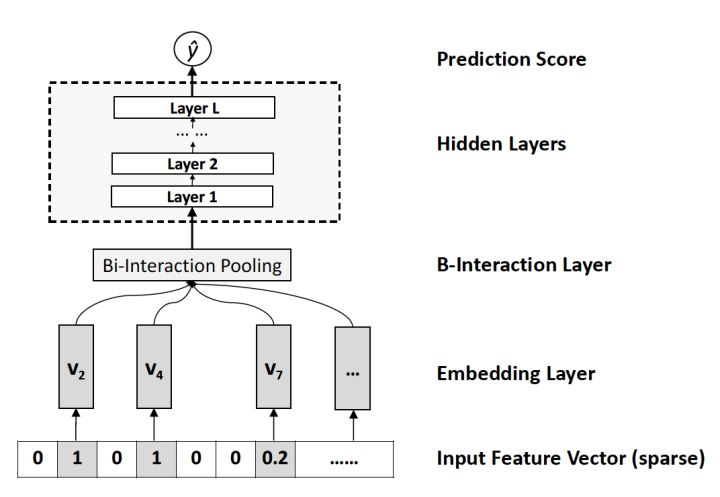
7. Deep Interest Network (DIN)
在模型的embedding layer和concatenate layer之间加入了attention unit,使模型能够根据候选商品的不同,调整不同特征的权重。

以上1-7部分可以总结为引入深度学习的CTR预估模型演变,这里分享一下大佬的关系图谱:
三、深度学习推荐模型的上线问题
对于深度学习推荐模型的离线训练自然不是问题,一般可以采用比较成熟的离线并行训练环境。
对于深度学习推荐模型的上线问题,其线上时效性至关重要。
1. “特征实时性”
这里分享一下大佬画的智能推荐系统主流技术架构图,博主认知有限,就不展开介绍了。

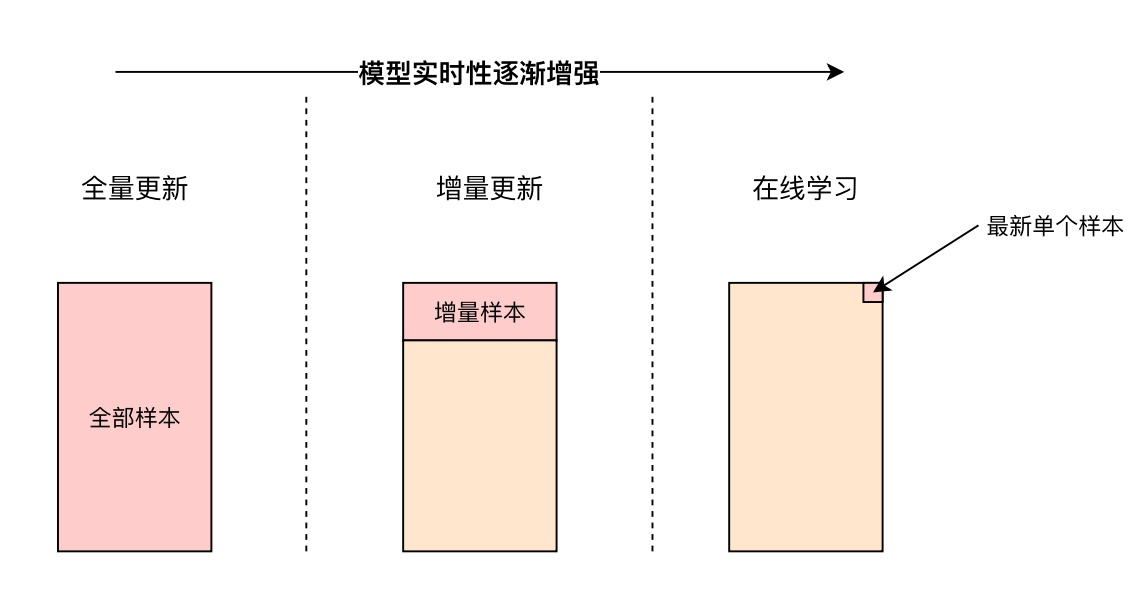
2. “模型实时性”
与“特征实时性”相比,推荐系统模型的实时性往往是从更全局的角度考虑问题,博主认知有限,就不展开介绍了。
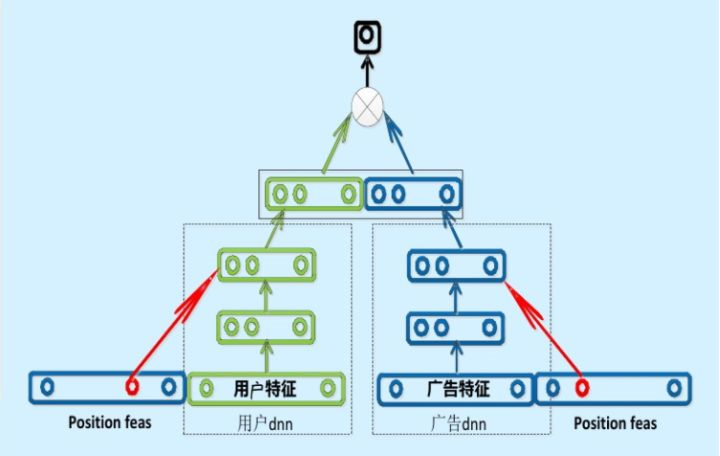
3. “服务实时性”:双塔模型
很多公司采用“复杂网络离线训练,生成embedding存入内存数据库,线上实现LR或浅层NN等轻量级模型拟合优化目标”的上线方式。
以百度的双塔模型举例说明:
(1)分别用复杂网络对“用户特征”和“广告特征”进行embedding,这就形成了两个独立的“塔”,因此称为双塔模型。
(2)在完成双塔模型的训练后,可以把最终的用户embedding和广告embedding存入内存数据库。
(3)线上推理时,只需要实现最后一层的逻辑,从内存数据库中取出用户/广告的embedding,通过简单计算即可得到预估结果。
最后感叹一句,深度学习CTR模型的发展实在是太迅速了,很多新模型就不继续介绍了,要保持学习啊!
【更新】介绍比较新的一些深度学习推荐模型改进方向:
- 引入用户行为序列建模(例如TDM/TransRec等)
- 将用户历史行为看做一个无序集合,对所有embedding取sum、max和各种attention等
- 将用户历史行为看做一个时间序列,采用RNN/LSTN/GRU等建模
- 抽取/聚类出用户的多峰兴趣,方法有Capsule等(阿里MIND提出)
- 根据业务场景的特殊需求,采用其他方法
- 引入NLP领域知识建模(例如Transformer/BERT等)
- 多目标优化/多任务学习(例如阿里ESMM/Google MMoE等)
- 多模态信息融合
- 长期/短期兴趣分离(例如SDM等)
- 结合深度强化学习(例如YouTube推荐/今日头条广告推荐DEAR等)
- 图神经网络的预训练(即引入迁移学习的思路)
- ......
本文参考了大佬的知乎专栏:https://zhuanlan.zhihu.com/p/51117616
如果你对智能推荐感兴趣,欢迎先浏览我的另一篇随笔:智能推荐算法演变及学习笔记
如果您对数据挖掘感兴趣,欢迎浏览我的另一篇博客:数据挖掘比赛/项目全流程介绍
如果您对人工智能算法感兴趣,欢迎浏览我的另一篇博客:人工智能新手入门学习路线和学习资源合集(含AI综述/python/机器学习/深度学习/tensorflow)
如果你是计算机专业的应届毕业生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的应届生,你如何准备求职面试?
如果你是计算机专业的本科生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的本科生,你可以选择学习什么?
如果你是计算机专业的研究生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的研究生,你可以选择学习什么?
如果你对金融科技感兴趣,欢迎浏览我的另一篇博客:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
之后博主将持续分享各大算法的学习思路和学习笔记:hello world: 我的博客写作思路

 浙公网安备 33010602011771号
浙公网安备 33010602011771号